Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Data Lake Storage är en mycket skalbar och kostnadseffektiv datasjölösning för stordataanalys. Den kombinerar kraften i ett högpresterande filsystem med massiv skala och ekonomi som hjälper dig att minska din tid till insikt. Data Lake Storage Gen2 utökar Azure Blob Storage funktioner och är optimerad för analysarbetsbelastningar.
Azure Data Explorer integreras med Azure Blob Storage och Azure Data Lake Storage (Gen1 och Gen2), vilket ger snabb, cachelagrad och indexerad åtkomst till data som lagras i extern lagring. Du kan analysera och köra frågor mot data utan föregående inmatning i Azure Data Explorer. Du kan också köra frågor mot inmatade och ej inmatade externa data samtidigt. Mer information finns i skapa en extern tabell med hjälp av guiden Azure Data Explorer webbgränssnitt. En kort översikt finns i externa tabeller.
Tips/Råd
Den bästa frågeprestandan kräver datainmatning i Azure Data Explorer. Möjligheten att fråga externa data utan tidigare inmatning bör endast användas för historiska data eller data som sällan efterfrågas. Optimera prestanda för externa datafrågor för bästa resultat.
Skapa en extern tabell
Anta att du har många CSV-filer som innehåller historisk information om produkter som lagras i ett lager, och du vill göra en snabb analys för att hitta de fem mest populära produkterna från förra året. I det här exemplet ser CSV-filerna ut så här:
| Tidsstämpel | Produkt-ID | Produktbeskrivning |
|---|---|---|
| 2019-01-01 11:21:00 | TO6050 | 3,5 tum DS/HD-diskett |
| 2019-01-01 11:30:55 | YDX1 | Yamaha DX1 Synthesizer |
| ... | ... | ... |
Filerna lagras i Azure Blob Storage mycompanystorage under en container med namnet archivedproducts, partitionerad efter datum:
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00000-7e967c99-cf2b-4dbb-8c53-ce388389470d.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00001-ba356fa4-f85f-430a-8b5a-afd64f128ca4.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00002-acb644dc-2fc6-467c-ab80-d1590b23fc31.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/01/part-00003-cd5fad16-a45e-4f8c-a2d0-5ea5de2f4e02.csv.gz
https://mycompanystorage.blob.core.windows.net/archivedproducts/2019/01/02/part-00000-ffc72d50-ff98-423c-913b-75482ba9ec86.csv.gz
...
Om du vill köra en KQL-fråga direkt på dessa CSV-filer använder du kommandot .create external table för att definiera en extern tabell i Azure Data Explorer. Mer information om kommandoalternativ för att skapa externa tabeller finns i kommandon för externa tabeller.
.create external table ArchivedProducts(Timestamp:datetime, ProductId:string, ProductDescription:string)
kind=blob
partition by (Date:datetime = bin(Timestamp, 1d))
dataformat=csv
(
h@'https://mycompanystorage.blob.core.windows.net/archivedproducts;StorageSecretKey'
)
Den externa tabellen visas nu i den vänstra rutan i Azure Data Explorer webbgränssnitt:
Behörigheter för extern tabell
Granska följande tabellbehörigheter:
- Databasanvändaren kan skapa en extern tabell. Tabellskapare blir automatiskt tabelladministratör.
- Kluster-, databas- eller tabelladministratören kan redigera en befintlig tabell.
- Alla databasanvändare eller läsare kan köra frågor mot en extern tabell.
Utföra frågor mot en extern tabell
När en extern tabell har definierats external_table() kan funktionen användas för att referera till den. Resten av frågan är kusto-standardfrågespråket.
external_table("ArchivedProducts")
| where Timestamp > ago(365d)
| summarize Count=count() by ProductId,
| top 5 by Count
Köra frågor mot externa och inmatade data tillsammans
Du kan fråga både externa tabeller och inmatade datatabeller i samma fråga. Du kan join eller union den externa tabellen med andra data från Azure Data Explorer, SQL-servrar eller andra källor. Använd a let( ) statement för att tilldela ett kortfattat namn till en extern tabellreferens.
I exemplet nedan är Produkter en inmatad datatabell och ArchivedProducts är en extern tabell som vi har definierat:
let T1 = external_table("ArchivedProducts") | where TimeStamp > ago(100d);
let T = Products; //T is an internal table
T1 | join T on ProductId | take 10
Köra frågor mot hierarkiska dataformat
Azure Data Explorer tillåter frågor mot hierarkiska format, till exempel JSON, Parquet, Avro och ORC. Om du vill mappa hierarkiskt dataschema till ett externt tabellschema (om det är annorlunda) använder du kommandon för extern tabellmappning. Om du till exempel vill köra frågor mot JSON-loggfiler med följande format:
{
"timestamp": "2019-01-01 10:00:00.238521",
"data": {
"tenant": "aaaabbbb-0000-cccc-1111-dddd2222eeee",
"method": "RefreshTableMetadata"
}
}
{
"timestamp": "2019-01-01 10:00:01.845423",
"data": {
"tenant": "bbbbcccc-1111-dddd-2222-eeee3333ffff",
"method": "GetFileList"
}
}
...
Den externa tabelldefinitionen ser ut så här:
.create external table ApiCalls(Timestamp: datetime, TenantId: guid, MethodName: string)
kind=blob
dataformat=multijson
(
h@'https://storageaccount.blob.core.windows.net/container1;StorageSecretKey'
)
Definiera en JSON-mappning som mappar datafält till externa tabelldefinitionsfält:
.create external table ApiCalls json mapping 'MyMapping' '[{"Column":"Timestamp","Properties":{"Path":"$.timestamp"}},{"Column":"TenantId","Properties":{"Path":"$.data.tenant"}},{"Column":"MethodName","Properties":{"Path":"$.data.method"}}]'
När du frågar den externa tabellen anropas mappningen och relevanta data mappas till de externa tabellkolumnerna:
external_table('ApiCalls') | take 10
Mer information om mappningssyntax finns i datamappningar.
Fråga TaxiRides extern tabell i hjälpklustret
Använd testklustret med namnet help för att prova olika Azure Data Explorer funktioner. Hjälpklustret innehåller en extern tabelldefinition för en taxidatauppsättning i New York City som innehåller miljarder taxiresor.
Skapa extern tabell TaxiRides
Det här avsnittet visar frågan som används för att skapa den externa tabellen TaxiRides i hjälpklustret . Eftersom du redan har skapat den här tabellen kan du hoppa över det här avsnittet och gå direkt till fråga TaxiRides externa tabelldata.
.create external table TaxiRides
(
trip_id: long,
vendor_id: string,
pickup_datetime: datetime,
dropoff_datetime: datetime,
store_and_fwd_flag: string,
rate_code_id: int,
pickup_longitude: real,
pickup_latitude: real,
dropoff_longitude: real,
dropoff_latitude: real,
passenger_count: int,
trip_distance: real,
fare_amount: real,
extra: real,
mta_tax: real,
tip_amount: real,
tolls_amount: real,
ehail_fee: real,
improvement_surcharge: real,
total_amount: real,
payment_type: string,
trip_type: int,
pickup: string,
dropoff: string,
cab_type: string,
precipitation: int,
snow_depth: int,
snowfall: int,
max_temperature: int,
min_temperature: int,
average_wind_speed: int,
pickup_nyct2010_gid: int,
pickup_ctlabel: string,
pickup_borocode: int,
pickup_boroname: string,
pickup_ct2010: string,
pickup_boroct2010: string,
pickup_cdeligibil: string,
pickup_ntacode: string,
pickup_ntaname: string,
pickup_puma: string,
dropoff_nyct2010_gid: int,
dropoff_ctlabel: string,
dropoff_borocode: int,
dropoff_boroname: string,
dropoff_ct2010: string,
dropoff_boroct2010: string,
dropoff_cdeligibil: string,
dropoff_ntacode: string,
dropoff_ntaname: string,
dropoff_puma: string
)
kind=blob
partition by (Date:datetime = bin(pickup_datetime, 1d))
dataformat=csv
(
h@'https://storageaccount.blob.core.windows.net/container1;secretKey'
)
Du hittar den skapade tabellen TaxiRides genom att titta på den vänstra rutan i Azure Data Explorer webbgränssnittet.
Utforska data från extern TaxiRides-tabell
Logga in på https://dataexplorer.azure.com/clusters/help/databases/Samples.
Fråga TaxiRides extern tabell utan partitionering
Kör den här frågan i den externa tabellen TaxiRides för att visa turer för varje dag i veckan, över hela datamängden.
external_table("TaxiRides")
| summarize count() by dayofweek(pickup_datetime)
| render columnchart
Den här frågan visar den mest trafikerade dagen i veckan. Eftersom data inte är partitionerade kan det ta upp till flera minuter för frågan att returnera resultat.
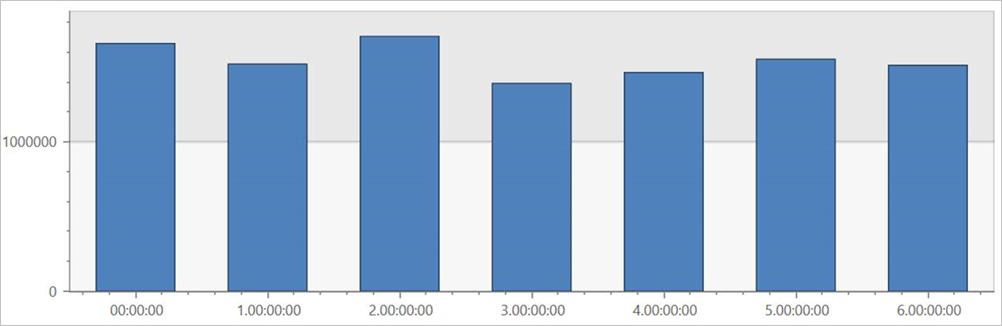
Fråga taxiRides extern tabell med partitionering
Kör den här frågan i den externa tabellen TaxiRides för att visa taxibilar (gula eller gröna) som användes i januari 2017.
external_table("TaxiRides")
| where pickup_datetime between (datetime(2017-01-01) .. datetime(2017-02-01))
| summarize count() by cab_type
| render piechart
Den här frågan använder partitionering, vilket optimerar frågetid och prestanda. Frågan filtrerar på en partitionerad kolumn (pickup_datetime) och returnerar resultat om några sekunder.
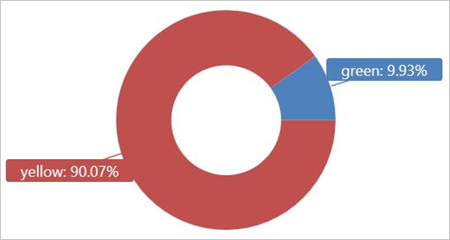
Du kan skriva andra frågor som ska köras i den externa tabellen TaxiRides och lära dig mer om data.
Optimera frågeprestanda
Optimera frågeprestandan i sjön med hjälp av följande metodtips för att köra frågor mot externa data.
Dataformat
- Använd ett kolumnformat för analysfrågor av följande skäl:
- Endast de kolumner som är relevanta för en fråga kan läsas.
- Kolumnkodningstekniker kan minska datastorleken avsevärt.
- Azure Data Explorer stöder Parquet- och ORC-kolumnformat. Parquet-format föreslås på grund av optimerad implementering.
Azure region
Kontrollera att externa data finns i samma Azure region som ditt Azure Data Explorer kluster. Den här konfigurationen minskar kostnaden och datahämtningstiden.
Filstorlek
Den optimala filstorleken är hundratals Mb (upp till 1 GB) per fil. Undvik många små filer som kräver onödiga omkostnader, till exempel långsammare filuppräkningsprocess och begränsad användning av kolumnformat. Antalet filer ska vara större än antalet CPU-kärnor i ditt Azure Data Explorer kluster.
Komprimering
Använd komprimering för att minska mängden data som hämtas från fjärrlagringen. För Parquet-format använder du den interna Parquet-komprimeringsmekanismen som komprimerar kolumngrupper separat, så att du kan läsa dem separat. Kontrollera att filerna har följande namn för att verifiera användningen av komprimeringsmekanismen: <filnamn>.gz.parquet eller <filename.snappy.parquet> och inte <filnamn>.parquet.gz.
Partitionering
Organisera dina data med hjälp av "mapp"-partitioner som gör att frågan kan hoppa över irrelevanta sökvägar. När du planerar partitionering bör du överväga filstorlek och vanliga filter i dina frågor, till exempel tidsstämpel eller klient-ID.
VM-storlek
Välj VM-SKU:er med fler kärnor och högre nätverksdataflöde (minne är mindre viktigt). Mer information finns i Välj rätt VM SKU för ditt Azure Data Explorer-kluster.