Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver vad datauppsättningar är, hur de definieras i JSON-format och hur de används i Azure Data Factory- och Synapse-pipelines.
Om du inte har använt Data Factory tidigare kan du läsa Introduktion till Azure Data Factory för en översikt. Mer information om Azure Synapse finns i Vad är Azure Synapse
Översikt
En Azure Data Factory- eller Synapse-arbetsyta kan ha en eller flera pipelines. En pipeline är en logisk gruppering av aktiviteter som tillsammans utför en uppgift. Aktiviteterna i en pipeline definierar åtgärder som ska utföras på dina data. Nu är en datauppsättning en namngiven vy över data som bara pekar eller refererar till de data som du vill använda i dina aktiviteter som indata och utdata. Datauppsättningar identifierar data inom olika datalager, till exempel tabeller, filer, mappar och dokument. En Azure Blob-datauppsättning anger till exempel blobcontainern och mappen i Blob Storage som aktiviteten ska läsa data från.
Innan du skapar en datauppsättning måste du skapa en länkad tjänst för att länka datalagret till tjänsten. Länkade tjänster liknar anslutningssträng, som definierar den anslutningsinformation som krävs för att tjänsten ska kunna ansluta till externa resurser. Tänk på det så här; datauppsättningen representerar strukturen för data i de länkade datalager och den länkade tjänsten definierar anslutningen till datakällan. En länkad Azure Storage-tjänst länkar till exempel ett lagringskonto. En Azure Blob-datauppsättning representerar blobcontainern och mappen i det Azure Storage-konto som innehåller de indatablobar som ska bearbetas.
Här är ett exempelscenario. Om du vill kopiera data från Blob Storage till en SQL Database skapar du två länkade tjänster: Azure Blob Storage och Azure SQL Database. Skapa sedan två datauppsättningar: Avgränsad textdatauppsättning (som refererar till den länkade Azure Blob Storage-tjänsten, förutsatt att du har textfiler som källa) och Azure SQL Table-datauppsättningen (som refererar till den länkade Azure SQL Database-tjänsten). Azure Blob Storage- och Azure SQL Database-länkade tjänster innehåller anslutningssträng som tjänsten använder vid körning för att ansluta till din Azure Storage respektive Azure SQL Database. Datauppsättningen Avgränsad text anger blobcontainern och blobmappen som innehåller indatablobbarna i Blob Storage, tillsammans med formatrelaterade inställningar. Azure SQL Table-datauppsättningen anger SQL-tabellen i din SQL Database som data ska kopieras till.
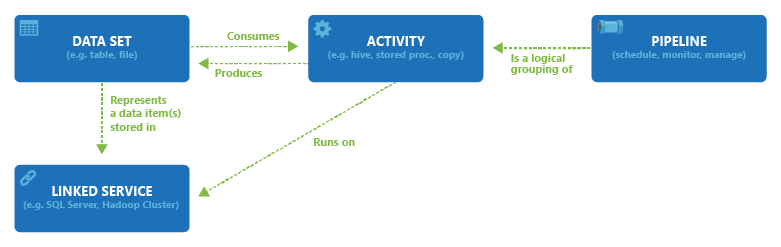
Följande diagram visar relationerna mellan pipeline, aktivitet, datauppsättning och länkade tjänster:
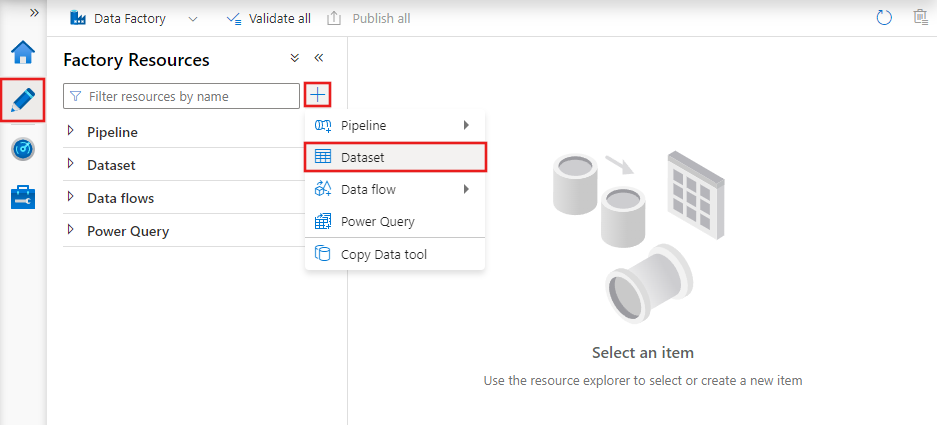
Skapa en datauppsättning med användargränssnittet
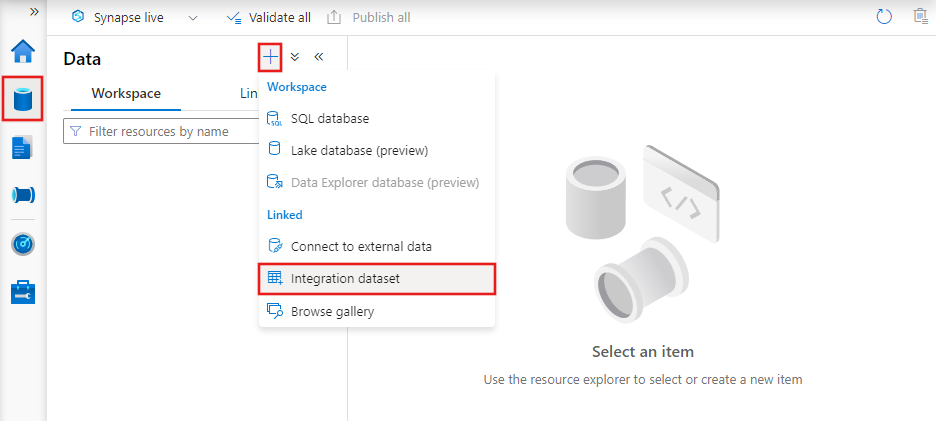
Om du vill skapa en datauppsättning med Azure Data Factory Studio väljer du fliken Författare (med pennikonen) och sedan plustecknet för att välja Datauppsättning.
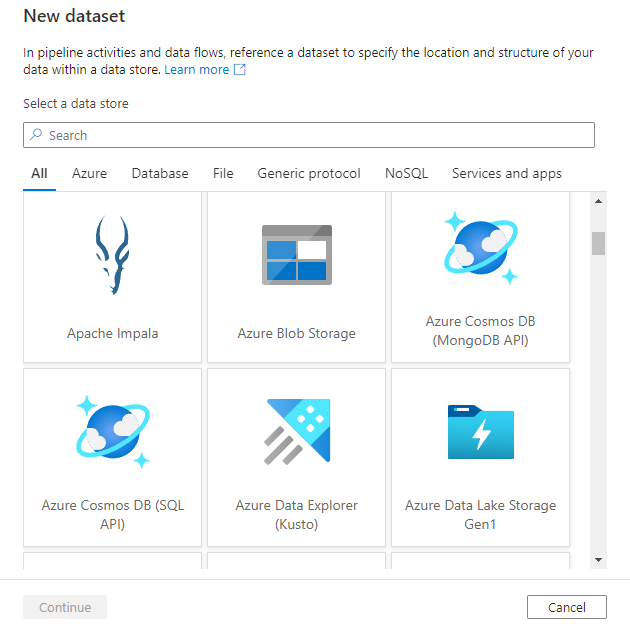
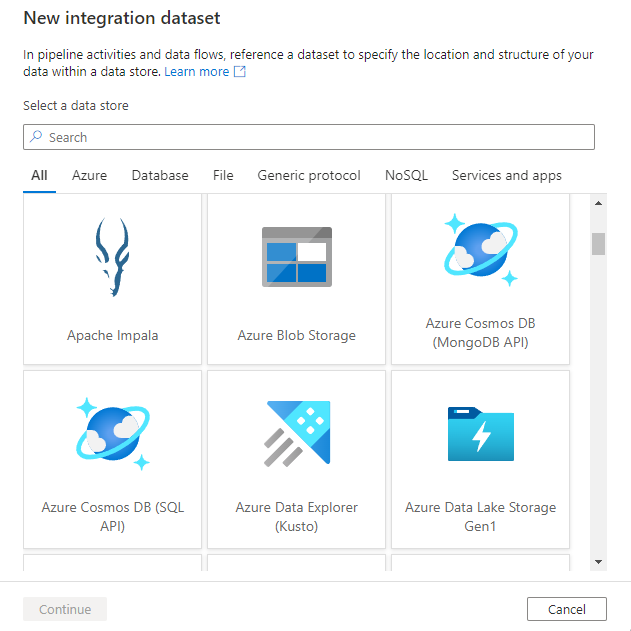
Du ser det nya datamängdsfönstret för att välja någon av de anslutningsappar som är tillgängliga i Azure Data Factory för att konfigurera en befintlig eller ny länkad tjänst.
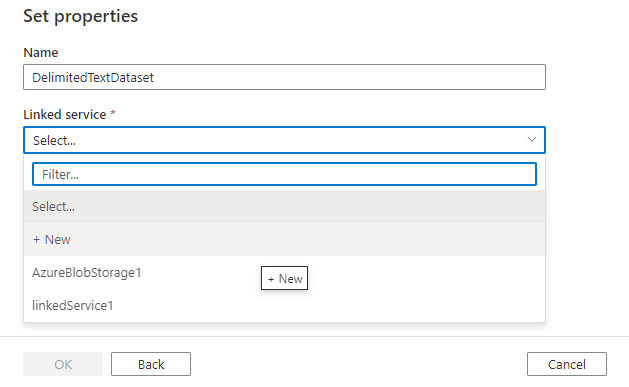
Därefter uppmanas du att välja datamängdsformatet.

Slutligen kan du välja en befintlig länkad tjänst av den typ som du har valt för datauppsättningen eller skapa en ny om en inte redan har definierats.
När du har skapat datauppsättningen kan du använda den i alla pipelines i Azure Data Factory.
JSON för datauppsättning
En datauppsättning definieras i följande JSON-format:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
I följande tabell beskrivs egenskaper i ovanstående JSON:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| name | Namnet på datauppsättningen. Se Namngivningsregler. | Ja |
| type | Typ av datauppsättning. Ange en av de typer som stöds av Data Factory (till exempel: DelimitedText, AzureSqlTable). Mer information finns i Datauppsättningstyper. |
Ja |
| schema | Schemat för datamängden representerar den fysiska datatypen och formen. | Nej |
| typeProperties | Typegenskaperna är olika för varje typ. Mer information om vilka typer som stöds och deras egenskaper finns i Datauppsättningstyp. | Ja |
När du importerar schemat för datamängden väljer du knappen Importera schema och väljer att importera från källan eller från en lokal fil. I de flesta fall importerar du schemat direkt från källan. Men om du redan har en lokal schemafil (en Parquet-fil eller CSV med rubriker) kan du dirigera tjänsten att basera schemat på den filen.
I kopieringsaktivitet används datauppsättningar i källa och mottagare. Schemat som definieras i datamängden är valfritt som referens. Om du vill använda kolumn-/fältmappning mellan källa och mottagare läser du Schema och typmappning.
I Dataflöde används datauppsättningar i käll- och mottagartransformeringar. Datauppsättningarna definierar grundläggande datascheman. Om dina data inte har något schema kan du använda schemaavvikelse för källan och mottagaren. Metadata från datauppsättningarna visas i källtransformeringen som källprojektion. Projektionen i källtransformeringen representerar Dataflöde data med definierade namn och typer.
Datamängdstyp
Tjänsten stöder många olika typer av datauppsättningar, beroende på vilka datalager du använder. Du hittar listan över datalager som stöds i översiktsartikeln Anslutningsprogram. Välj ett datalager för att lära dig hur du skapar en länkad tjänst och en datauppsättning för den.
För en avgränsad textdatauppsättning anges till exempel datamängdstypen Till AvgränsadText enligt följande JSON-exempel:
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
Kommentar
Schemavärdet definieras med JSON-syntax. Mer detaljerad information om schemamappning och datatypsmappning finns i dokumentationen för Azure Data Factory-kopieringsaktivitetsschema och typmappning .
Skapa datauppsättningar
Du kan skapa datauppsättningar med något av följande verktyg eller SDK:er: .NET API, PowerShell, REST API, Azure Resource Manager-mall och Azure Portal
Aktuell version jämfört med datauppsättningar i version 1
Här följer några skillnader mellan datauppsättningar i Den aktuella versionen av Data Factory (och Azure Synapse) och den äldre Data Factory version 1:
- Den externa egenskapen stöds inte i den aktuella versionen. Den ersätts av en utlösare.
- Princip- och tillgänglighetsegenskaperna stöds inte i den aktuella versionen. Starttiden för en pipeline beror på utlösare.
- Begränsade datamängder (datauppsättningar som definierats i en pipeline) stöds inte i den aktuella versionen.
Relaterat innehåll
Snabbstarter
I följande självstudie finns stegvisa instruktioner för hur du skapar pipelines och datauppsättningar med hjälp av något av dessa verktyg eller SDK:er.
- Snabbstart: skapa en datafabrik med hjälp av .NET
- Snabbstart: Skapa en datafabrik med PowerShell
- Snabbstart: Skapa en datafabrik med hjälp av REST API
- Snabbstart: Skapa en datafabrik med hjälp av Azure Portal