Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur Kopieringsaktiviteten i Azure Data Factory utför schemamappning och datatypsmappning från källdata till mottagardata.
Schemakoppling
Standardinställning
Som standardinställning mappar kopieringsaktivitet källdata till mottagare efter kolumnnamn på skiftlägeskänsligt sätt. Om mottagaren inte finns, till exempel om du skriver till filer, sparas källfältnamnen som mottagarnamn. Om mottagaren redan finns måste den innehålla alla kolumner som kopieras från källan. Sådan standardmappning stöder flexibla scheman och schemaavvikelser, vilket gör det möjligt för data att flyttas från källa till mottagare och från en körning till nästa – alla data som returneras av källdatalagret kan kopieras till mottagaren.
Om källan är textfil utan rubrikrad krävs explicit mappning eftersom källan inte innehåller kolumnnamn.
Explicit kartläggning
Du kan också ange explicit mappning för att anpassa kolumn-/fältmappningen från källa till mottagare baserat på dina behov. Med explicit mappning kan du bara kopiera partiella källdata till mottagare eller mappa källdata till mottagare med olika namn eller omforma tabell-/hierarkiska data. Kopieringsaktivitet:
- Läser data från källan och fastställer källschemat.
- Tillämpar din definierade mappning.
- Skriver data till mottagare.
Läs mer om:
- Tabellkälla till tabellmottagare
- Hierarkisk källa till tabellbuffert
- Tabulär eller hierarkisk källa till hierarkisk mottagare
Du kan konfigurera mappningen i användargränssnittet för redigering –> kopieringsaktivitet –> mappningsfliken eller programmatiskt ange mappningen i kopieringsaktiviteten –>translator egenskap. Följande egenskaper stöds i translator ->mappings matris -> objekt ->source och sink, som pekar på den specifika kolumnen/fältet för att mappa data.
| Egendom | Beskrivning | Obligatoriskt |
|---|---|---|
| namn | Namnet på källan eller mottagarkolumnen/fältet. Ansök om tabellär källa och avlopp. | Ja |
| Ordinal | Kolumnindex. Börja från 1. Används och krävs när du arbetar med avgränsad text utan rubrikrad. |
Nej |
| väg | JSON-sökvägsuttryck för varje fält som ska extraheras eller mappas. Använd för hierarkisk källa och mottagare, till exempel Azure Cosmos DB, MongoDB eller REST-anslutningsappar. För fält under rotobjektet börjar JSON-sökvägen med roten $. För fält i matrisen som valts av collectionReference egenskapen startar JSON-sökvägen från matriselementet utan $. |
Nej |
| typ | Interimdatatyp för käll- eller mottagarkolumnen. I allmänhet behöver du inte ange eller ändra den här egenskapen. Läs mer om datatypsmappning. | Nej |
| kultur | Kultur för käll- eller mottagarkolumnen. Använd när typen är Datetime eller Datetimeoffset. Standardvärdet är en-us.I allmänhet behöver du inte ange eller ändra den här egenskapen. Läs mer om datatypsmappning. |
Nej |
| format | Formatera sträng som ska användas när typen är Datetime eller Datetimeoffset.
Se Anpassade datum- och tidsformatsträngar för hur du formaterar datum och tid. I allmänhet behöver du inte ange eller ändra den här egenskapen. Läs mer om datatypsmappning. |
Nej |
Följande egenskaper stöds under translator utöver mappings:
| Egendom / Fastighet | Beskrivning | Obligatoriskt |
|---|---|---|
| samlingReferens | Använd när du kopierar data från en hierarkisk källa, till exempel Azure Cosmos DB, MongoDB eller REST-anslutningsappar. Om du vill iterera och extrahera data från objekten i ett matrisfält enligt samma mönster och konvertera varje objekt till en separat rad, specificera JSON-sökvägen för den matrisen för att använda cross-apply. |
Nej |
Tabellkälla till tabellmottagare
Om du till exempel vill kopiera data från Salesforce till Azure SQL Database och uttryckligen mappa tre kolumner:
Vid kopieringsaktivitet –> mappningsfliken klickar du på knappen Importera scheman för att importera både käll- och mottagarscheman.
Mappa de fält som behövs och exkludera/ta bort resten.

Samma mappning kan konfigureras som följande i kopieringsaktivitetens nyttolast (se translator):
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "SalesforceSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "name": "Id" },
"sink": { "name": "CustomerID" }
},
{
"source": { "name": "Name" },
"sink": { "name": "LastName" }
},
{
"source": { "name": "LastModifiedDate" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Om du vill kopiera data från avgränsade textfiler utan rubrikrad representeras kolumnerna av ordningstal i stället för namn.
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "DelimitedTextSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "ordinal": "1" },
"sink": { "name": "CustomerID" }
},
{
"source": { "ordinal": "2" },
"sink": { "name": "LastName" }
},
{
"source": { "ordinal": "3" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Hierarkisk källa till tabellmottagare
När du kopierar data från hierarkisk källa till tabellmottagare stöder kopieringsaktiviteten följande funktioner:
- Extrahera data från objekt och matriser.
- Kors tillämpa flera objekt med samma mönster från en matris, i vilket fall för att konvertera ett JSON-objekt till flera poster i tabellresultatet.
För mer avancerad hierarkisk-till-tabelltransformering kan du använda Dataflöde.
Om du till exempel har MongoDB-källdokumentet med följande innehåll:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
Och du vill kopiera den till en textfil i följande format med rubrikrad genom att platta ut data i matrisen (order_pd och order_price) och korskoppling med den gemensamma rotinformationen (nummer, datum och stad):
| ordernummer | beställningsdatum | beställning_pd | order_price | stad |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Du kan definiera en sådan mappning i användargränssnittet för Data Factory-redigering:
Vid kopieringsaktivitet –> mappningsfliken klickar du på knappen Importera scheman för att importera både käll- och mottagarscheman. När tjänsten tar exempel på de översta objekten när du importerar schemat, om något fält inte visas, kan du lägga till det i rätt lager i hierarkin – hovra på ett befintligt fältnamn och välja att lägga till en nod, ett objekt eller en matris.
Välj den matris som du vill iterera och extrahera data från. Den fylls i automatiskt som samlingsreferens. Observera att endast en enskild matris stöds för en sådan åtgärd.
Mappa de nödvändiga fälten till mål. Tjänsten avgör automatiskt motsvarande JSON-sökvägar för den hierarkiska sidan.
Kommentar
För poster där matrisen som markerats som samlingsreferens är tom och kryssrutan är markerad hoppas hela posten över.
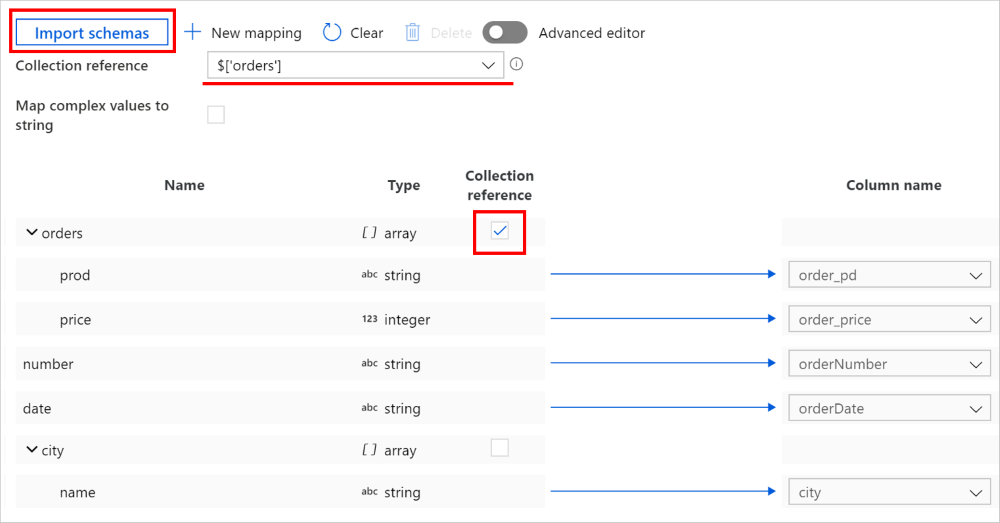
Du kan också växla till Avancerad redigerare, i vilket fall du kan se och redigera fältens JSON-sökvägar direkt. Om du väljer att lägga till ny mappning i den här vyn anger du JSON-sökvägen.
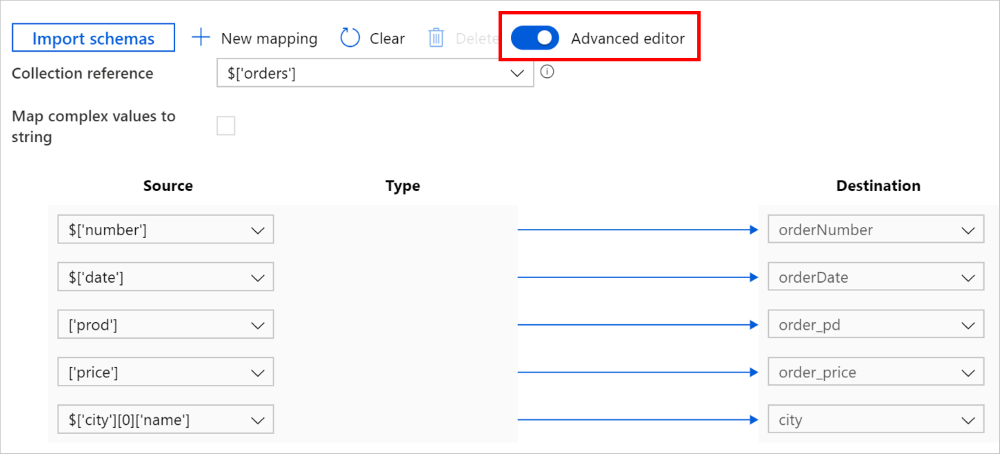
Samma mappning kan konfigureras som följande i kopieringsaktivitetens nyttolast (se translator):
{
"name": "CopyActivityHierarchicalToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "MongoDbV2Source" },
"sink": { "type": "DelimitedTextSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "path": "$['number']" },
"sink": { "name": "orderNumber" }
},
{
"source": { "path": "$['date']" },
"sink": { "name": "orderDate" }
},
{
"source": { "path": "['prod']" },
"sink": { "name": "order_pd" }
},
{
"source": { "path": "['price']" },
"sink": { "name": "order_price" }
},
{
"source": { "path": "$['city'][0]['name']" },
"sink": { "name": "city" }
}
],
"collectionReference": "$['orders']"
}
},
...
}
Tabell-/hierarkisk källa till hierarkisk mottagare
Användarupplevelsens flöde liknar hierarkisk källa till tabellmottagare.
När du kopierar data från tabellkälla till hierarkisk mottagare stöds inte skrivning till matris inuti objekt.
När du kopierar data från hierarkisk källa till hierarkisk mottagare kan du dessutom bevara hela lagrets hierarki genom att välja objektet/matrisen och kartan som ska sjunka utan att röra de inre fälten.
För mer avancerad transformering av data kan du använda Dataflöde.
Parameterisera mappning
Om du vill skapa en templaterad pipeline för att kopiera ett stort antal objekt dynamiskt kan du avgöra om du kan använda standardmappningen eller om du behöver definiera explicit mappning för respektive objekt.
Om explicit mappning behövs kan du:
Definiera en parameter med objekttyp på pipelinenivå, till exempel
mapping.Parametrisera mappningen: vid kopieringsaktivitet –> mappningsfliken väljer du att lägga till dynamiskt innehåll och väljer parametern ovan. Aktivitetsnyttolasten kommer vara följande:
{ "name": "CopyActivityHierarchicalToTabular", "type": "Copy", "typeProperties": { "source": {...}, "sink": {...}, "translator": { "value": "@pipeline().parameters.mapping", "type": "Expression" }, ... } }Konstruera värdet som ska skickas till mappningsparametern. Det bör vara hela definitionsobjektet
translator, se exemplen i avsnittet explicit mappning . För t.ex. tabellkälla till tabellmottagare ska värdet vara{"type":"TabularTranslator","mappings":[{"source":{"name":"Id"},"sink":{"name":"CustomerID"}},{"source":{"name":"Name"},"sink":{"name":"LastName"}},{"source":{"name":"LastModifiedDate"},"sink":{"name":"ModifiedDate"}}]}.
Mappningar av datatyp
Kopieringsaktiviteten utför en mappning från källtyper till mottagartyper enligt följande flöde:
- Konvertera från källbaserade datatyper till mellanliggande datatyper som används av Azure Data Factory- och Synapse-pipelines.
- Konvertera tillfällig datatyp automatiskt vid behov för att matcha motsvarande måldatatyper, gäller för både standard- och explicit mappning.
- Konvertera från mellanliggande datatyper till inbyggda datatyper.
Aktiviteten Kopiera stöder för närvarande följande temporära datatyper: Boolean, Byte, Byte-array, Datumtid, Datumtidsoffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, Tidsintervall, UInt16, UInt32 och UInt64.
Följande datatypkonverteringar stöds mellan interimstyperna från källa till mottagare.
| Källa\Mottagare | Boolean | Bytematris | Datum/tid | Decimal | Flyttalspunkt | GUID | Integer | Sträng | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Boolean | ✓ | ✓ | ✓ | ✓ | |||||
| Bytematris | ✓ | ✓ | |||||||
| Datum/tid | ✓ | ✓ | |||||||
| Decimal | ✓ | ✓ | ✓ | ✓ | |||||
| Flyttalspunkt | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| Integer | ✓ | ✓ | ✓ | ✓ | |||||
| Sträng | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) Datum/tid inkluderar DateTime, DateTimeOffset, Datum och tid.
(2) Float-point innehåller enkel och dubbel.
(3) Heltal innefattar SByte, Byte, Int16, UInt16, Int32, UInt32, Int64 och UInt64.
Kommentar
- För närvarande stöds sådan datatypkonvertering vid kopiering mellan tabelldata. Hierarkiska källor/mottagare stöds inte, vilket innebär att det inte finns någon systemdefinierad datatypkonvertering mellan käll- och mottagar interimstyper.
- Den här funktionen fungerar med den senaste datamängdsmodellen. Om du inte ser det här alternativet från användargränssnittet kan du prova att skapa en ny datauppsättning.
Följande egenskaper stöds i kopieringsaktivitet för datatypskonvertering (under translator avsnittet för programmatisk redigering):
| Egendom | Beskrivning | Obligatoriskt |
|---|---|---|
| typeConversion | Aktivera den nya datatypskonverteringsupplevelsen. Standardvärdet är falskt på grund av bakåtkompatibilitet. För nya kopieringsaktiviteter som skapats via Data Factory-redigeringsgränssnittet sedan slutet av juni 2020 aktiveras den här datatypskonverteringen som standard för bästa möjliga upplevelse, och du kan se följande typkonverteringsinställningar för kopieringsaktivitet –> mappningsfliken för tillämpliga scenarier. Om du vill skapa pipeline programmatiskt måste du uttryckligen ange typeConversion egenskapen till true för att aktivera den.För befintliga kopieringsaktiviteter som skapats innan den här funktionen släpps visas inte alternativ för typkonvertering i redigeringsgränssnittet för bakåtkompatibilitet. |
Nej |
| Typomvandlingsinställningar | En grupp av typkonverteringsinställningar. Använd när typeConversion är inställt på true. Följande egenskaper finns under den här gruppen. |
Nej |
Under typeConversionSettings |
||
| allowDataTruncation | Tillåt datatrunkering när du konverterar källdata till mottagare med annan typ under kopiering, till exempel från decimal till heltal, från DatetimeOffset till Datetime. Standardvärdet är sant. |
Nej |
| HanteraBooleanSomNummer | Behandla booleska värden som tal, till exempel sant som 1. Standardvärdet är "falsk". |
Nej |
| datumformat | Formatera sträng när du konverterar mellan datum och strängar, t.ex. yyyy-MM-dd.
Mer information finns i Anpassade datum- och tidsformatsträngar. |
Nej |
| datum- och tidsformat | Formatera sträng vid konvertering mellan datum utan tidszonsförskjutning och strängar, till exempel yyyy-MM-dd HH:mm:ss.fff.
Mer information finns i Anpassade datum- och tidsformatsträngar. |
Nej |
| dateTimeOffsetFormat | Formatera en sträng för att konvertera mellan datum med tidszonsförskjutning och strängar, till exempel yyyy-MM-dd HH:mm:ss.fff zzz.
Mer information finns i Anpassade datum- och tidsformatsträngar. |
Nej |
| tidsspannformat | Formatera sträng vid konvertering mellan tidsperioder och strängar, till exempel dd\.hh\:mm.
Mer information finns i Formatsträngar för anpassad tidsspann. |
Nej |
| tidsformat | Formatera sträng när du konverterar mellan tid och strängar, t.ex. HH:mm:ss.fff.
Mer information finns i Anpassade datum- och tidsformatsträngar. |
Nej |
| kultur | Kulturinformation som ska användas när du konverterar typer, en-us till exempel eller fr-fr. |
Nej |
Exempel:
{
"name": "CopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ParquetSource"
},
"sink": {
"type": "SqlSink"
},
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": true,
"dateTimeFormat": "yyyy-MM-dd HH:mm:ss.fff",
"dateTimeOffsetFormat": "yyyy-MM-dd HH:mm:ss.fff zzz",
"timeSpanFormat": "dd\.hh\:mm",
"culture": "en-gb"
}
}
},
...
}
Äldre modeller
Anmärkning
Följande modeller för att mappa källkolumner/fält till mottagare stöds fortfarande som de är för att säkerställa bakåtkompatibilitet. Vi föreslår att du använder den nya modellen som nämns i schemamappningen. Redigeringsgränssnittet har växlat till att generera den nya modellen.
Alternativ kolumnmappning (äldre modell)
Du kan ange kopieringsaktivitet –>translator –>columnMappings för att mappa mellan tabellformade data. I det här fallet krävs avsnittet "struktur" för både indata- och utdatauppsättningar. Kolumnmappning stöder mappning av alla eller delmängder av kolumner i källdatamängdens "struktur" till alla kolumner i mottagardatauppsättningens "struktur". Följande är felvillkor som resulterar i ett undantag:
- Frågeresultatet för källdatalager har inget kolumnnamn som anges i avsnittet "struktur" för indatauppsättningen.
- Mottagarens datalager (om med fördefinierat schema) har inte ett kolumnnamn som anges i avsnittet "struktur" för utdatauppsättningen.
- Antingen färre eller fler kolumner i mottagardatasetets "struktur" än vad som anges i mappningen.
- Duplicerad mappning.
I följande exempel har indatauppsättningen en struktur och pekar på en tabell i en lokal Oracle-databas.
{
"name": "OracleDataset",
"properties": {
"structure":
[
{ "name": "UserId"},
{ "name": "Name"},
{ "name": "Group"}
],
"type": "OracleTable",
"linkedServiceName": {
"referenceName": "OracleLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SourceTable"
}
}
}
I det här exemplet har utdatauppsättningen en struktur och pekar på en tabell i Salesforce.
{
"name": "SalesforceDataset",
"properties": {
"structure":
[
{ "name": "MyUserId"},
{ "name": "MyName" },
{ "name": "MyGroup"}
],
"type": "SalesforceObject",
"linkedServiceName": {
"referenceName": "SalesforceLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SinkTable"
}
}
}
Följande JSON definierar en kopieringsaktivitet i en pipeline. Kolumnerna från källan mappas till kolumner i målet med hjälp av egenskapen columnMappings i translator ->.
{
"name": "CopyActivity",
"type": "Copy",
"inputs": [
{
"referenceName": "OracleDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "SalesforceDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": { "type": "OracleSource" },
"sink": { "type": "SalesforceSink" },
"translator":
{
"type": "TabularTranslator",
"columnMappings":
{
"UserId": "MyUserId",
"Group": "MyGroup",
"Name": "MyName"
}
}
}
}
Om du använder syntaxen "columnMappings": "UserId: MyUserId, Group: MyGroup, Name: MyName" för för att ange kolumnmappning stöds den fortfarande som den är.
Alternativ schemamappning (äldre modell)
Du kan ange kopieringsaktivitet –>translator –>schemaMapping för att mappa mellan hierarkisk-formade data och tabellformade data, till exempel kopiera från MongoDB/REST till textfil och kopiera från Oracle till Azure Cosmos DB för MongoDB. Följande egenskaper stöds i avsnittet kopieringsaktivitet translator :
| Egendom | Beskrivning | Obligatoriskt |
|---|---|---|
| typ | Typegenskapen för kopieringsaktivitetsöversättaren måste anges till: TabularTranslator | Ja |
| schemaMappning | En samling nyckel/värde-par som representerar mappningsrelationen från källsidan till mottagarsidan. - Nyckel: representerar källan. För tabellkälla anger du kolumnnamnet enligt definitionen i datamängdsstrukturen. För hierarkisk källa anger du JSON-sökvägsuttrycket för varje fält som ska extraheras och mappas. - Värde: representerar mottagare. För tabellmottagare anger du kolumnnamnet enligt definitionen i datamängdsstrukturen. För hierarkisk mottagare anger du JSON-sökvägsuttrycket för varje fält som ska extraheras och mappas. När det gäller hierarkiska data, för fält under rotobjekt, börjar JSON-sökvägen med roten $; för fält i matrisen som valts av collectionReference egenskapen startar JSON-sökvägen från matriselementet. |
Ja |
| samlingsreferens | Om du vill iterera och extrahera data från objekten i ett arrayfält med samma mönster och konvertera till ett objekt per rad, anger du JSON-sökvägen för den arrayen för att använda cross-apply. Den här egenskapen stöds endast när hierarkiska data är källa. | Nej |
Exempel: kopiera från MongoDB till Oracle:
Om du till exempel har MongoDB-dokument med följande innehåll:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
och du vill kopiera dem till en Azure SQL-tabell i följande format genom att platta ut data i matrisen (order_pd och order_price) och korskoppling med den gemensamma rotinformationen (nummer, datum och ort):
| ordernummer | orderdatum | order_pd | order_price | stad |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Konfigurera schemamappningsregeln som följande JSON-exempel för kopieringsaktivitet:
{
"name": "CopyFromMongoDBToOracle",
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbV2Source"
},
"sink": {
"type": "OracleSink"
},
"translator": {
"type": "TabularTranslator",
"schemaMapping": {
"$.number": "orderNumber",
"$.date": "orderDate",
"prod": "order_pd",
"price": "order_price",
"$.city[0].name": "city"
},
"collectionReference": "$.orders"
}
}
}
Relaterat innehåll
Se de andra artiklarna om kopieringsaktivitet: