Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Integration Runtime (IR) är den beräkningsinfrastruktur som används av Azure Data Factory- och Azure Synapse-pipelines för att tillhandahålla följande dataintegreringsfunktioner i olika nätverksmiljöer:
- Dataflöde: Kör en Dataflöde i en hanterad Azure-beräkningsmiljö.
- Dataflytt: Kopiera data mellan datalager i ett offentligt eller privat nätverk (för både lokala eller virtuella privata nätverk). Tjänsten har stöd för inbyggda anslutningsappar, formatkonvertering, kolumnmappning och högpresterande och skalbar dataöverföring.
- Aktivitetsutskick: Skicka och övervaka transformeringsaktiviteter som körs på olika beräkningstjänster, till exempel Azure Databricks, Azure HDInsight, ML Studio (klassisk), Azure SQL Database, SQL Server med mera.
- SSIS paketkörning: Internt köra SQL Server Integration Services-paket (SSIS) i en hanterad Azure-beräkningsmiljö.
I Data Factory- och Synapse-pipelines definierar en aktivitet den åtgärd som ska utföras. En länkad tjänst definierar ett datalager som mål eller en beräkningstjänst. En "integration runtime" utgör bryggan mellan aktiviteter och länkade tjänster. Den länkade tjänsten eller aktiviteten refererar till och tillhandahåller beräkningsmiljön där aktiviteten antingen körs direkt eller skickas. Den här associationen gör att aktiviteten kan utföras i närmaste möjliga region till måldatalagret eller beräkningstjänsten för att maximera prestanda samtidigt som flexibiliteten kan uppfylla säkerhets- och efterlevnadskrav.
Integreringskörningar kan skapas i Användargränssnittet för Azure Data Factory och Azure Synapse via hanteringshubben direkt och från aktiviteter, datauppsättningar eller dataflöden som refererar till dem.
Typer av integration runtime
Data Factory erbjuder tre typer av Integration Runtime (IR) och du bör välja den typ som bäst hanterar dina dataintegreringsfunktioner och nätverksmiljökrav. De tre typerna av IR är:
- Azure
- Lokalt installerad
- Azure-SSIS
Kommentar
Synapse-pipelines stöder för närvarande endast Azure- eller lokalt installerade integrationskörningar.
I följande tabell beskrivs funktioner och nätverksstöd för varje Integration Runtime-typ:
| IR-typ | Stöd för offentligt nätverk | Stöd för Private Link |
|---|---|---|
| Azure | Dataflöde Dataflytt Aktivitetssändning |
Dataflöde Dataflytt Aktivitetssändning |
| Lokalt installerad | Dataflytt Aktivitetssändning |
Dataflytt Aktivitetssändning |
| Azure-SSIS | Körning av SSIS-paket | Körning av SSIS-paket |
Kommentar
Utgående kontroller varierar beroende på vilken tjänst som används i Azure IR. I Synapse har arbetsytor alternativ för att begränsa utgående trafik från det hanterade virtuella nätverket när du använder Azure IR. I Data Factory öppnas alla portar för utgående kommunikation vid användning av Azure IR. Azure-SSIS IR kan integreras med ditt virtuella nätverk för att tillhandahålla utgående kommunikationskontroller .
Azure integreringskörning
En Azure-integreringskörning kan:
- Köra Dataflöde i Azure
- Köra kopieringsaktiviteter mellan molndatalager
- Skicka följande transformeringsaktiviteter i ett offentligt nätverk:
- .NET-anpassad aktivitet
- Azure-funktionsaktivitet
- Databricks Notebook/Jar/Python-aktivitet
- Data Lake Analytics U-SQL-aktivitet
- Hämta metadata-aktivitet
- HDInsight Hive-aktivitet
- HDInsight Pig-aktivitet
- HDInsight MapReduce-aktivitet
- HDInsight Spark-aktivitet
- HDInsight Streaming-aktivitet
- Sökningsaktivitet
- Batch-körningsaktivitet i Machine Learning Studio (klassisk)
- Uppdatera resursaktivitet i Machine Learning Studio (klassisk)
- Aktivitet för lagrad procedur
- Valideringsaktivitet
- Webbaktivitet
Azure IR-nätverksmiljö
Azure Integration Runtime stöder anslutning till datalager och beräkningstjänster med offentliga slutpunkter. När du aktiverar Hanterat virtuellt nätverk stöder Azure Integration Runtime anslutning till datalager med hjälp av private link-tjänsten i en privat nätverksmiljö. I Synapse har arbetsytor alternativ för att begränsa utgående trafik från det IR-hanterade virtuella nätverket. I Data Factory öppnas alla portar för utgående kommunikation. Azure-SSIS IR kan integreras med ditt virtuella nätverk för att tillhandahålla utgående kommunikationskontroller .
Beräkningsresurs och skalning i Azure IR
Med Azure Integration Runtime får du en helt hanterad, serverlös beräkning i Azure. Du behöver inte bekymra dig om infrastrukturetablering, programvaruinstallation, korrigering eller kapacitetsskalning. Dessutom betalar du bara under den faktiska användningen.
Med Azure Integration Runtime får du interna beräkningsfunktioner för att flytta data mellan molndatalager på ett säkert, pålitligt sätt med höga prestanda. Du kan ange hur många dataintegreringsenheter som ska användas för kopieringsaktiviteten och beräkningsstorleken för Azure IR skalas elastiskt upp i enlighet med detta utan att du uttryckligen behöver justera storleken på Azure Integration Runtime.
Aktivitetssändning är en enkel åtgärd för att dirigera aktiviteten till målberäkningstjänsten, så det finns inget behov av att skala upp beräkningsstorleken för det här scenariot.
Information om hur du skapar och konfigurerar en Azure IR finns i Skapa och konfigurera Azure Integration Runtime.
Kommentar
Azure Integration Runtime har egenskaper relaterade till Dataflöde-runtime, som definierar den underliggande beräkningsinfrastrukturen som ska användas för att exekvera dataflödena.
Lokal Integration Runtime
En IR med egen värd kan:
- Köra kopieringsaktivitet mellan molndatalager och ett datalager i privat nätverk.
- Skicka följande transformeringsaktiviteter mot beräkningsresurser i lokalt eller Azure Virtual Network:
- Azure-funktionsaktivitet
- Anpassad aktivitet (körs på Azure Batch)
- Data Lake Analytics U-SQL-aktivitet
- Hämta metadata-aktivitet
- HDInsight Hive-aktivitet (BYOC-Bring Your Own Cluster)
- HDInsight Pig-aktivitet (BYOC)
- HDInsight MapReduce-aktivitet (BYOC)
- HDInsight Spark-aktivitet (BYOC)
- HDInsight Streaming-aktivitet (BYOC)
- Sökningsaktivitet
- Batch-körningsaktivitet i Machine Learning Studio (klassisk)
- Uppdatera resursaktivitet i Machine Learning Studio (klassisk)
- Machine Learning Exekvering av pipelineaktivitet
- Aktivitet för lagrad procedur
- Valideringsaktivitet
- Webbaktivitet
Kommentar
Använd lokalt installerad integrationskörning för att stödja datalager som kräver en egen drivrutin, till exempel SAP Hana, MySQL osv. Mer information finns i Datalager som stöds.
Kommentar
Java Runtime Environment (JRE) är ett beroende av lokalt installerad IR. Kontrollera att JRE är installerat på samma värd.
IR-nätverksmiljö med egen värd
Om du vill utföra dataintegrering på ett säkert sätt i en privat nätverksmiljö som inte har en direkt siktlinje från den offentliga molnmiljön kan du installera en lokalt installerad IR i din lokala miljö bakom en brandvägg eller i ett virtuellt privat nätverk. Den självhostade integrationskörningen gör bara utgående HTTP-baserade anslutningar till internet.
Beräkningsresurs och skalning i IR med egen värd
Installera en lokalt installerad IR på en lokal dator eller en virtuell dator i ett privat nätverk. För närvarande stöds den lokalt installerade IR:en endast i ett Windows-operativsystem. För hög tillgänglighet och skalbarhet kan du skala ut IR med egen värd genom att associera den logiska instansen med flera lokala datorer i aktiv/aktiv-läge. Mer information finns i artikeln om hur du skapar och konfigurerar en lokalt installerad IR för mer information.
Azure-SSIS Integration Runtime
Om du vill lyfta och skifta befintlig SSIS-arbetsbelastning kan du skapa en Azure-SSIS IR för att köra SSIS-paket internt.
Azure-SSIS IR-nätverksmiljö
Azure-SSIS IR kan etableras i antingen offentligt nätverk eller privat nätverk. Lokal dataåtkomst stöds genom att ansluta Azure-SSIS IR till ett virtuellt nätverk som är anslutet till ditt lokala nätverk.
Beräkningsresurs och skalning i Azure-SSIS IR
Azure-SSIS IR är ett fullständigt hanterat kluster med virtuella Azure-datorer som är dedikerade för att köra dina SSIS-paket. Du kan ta med din egen Azure SQL Database eller SQL Managed Instance för katalogen med SSIS-projekt/-paket (SSISDB). Du kan skala upp kraften i beräkningen genom att ange nodstorlek och skala ut den genom att ange antalet noder i klustret. Du kan hantera kostnaden för att köra Azure-SSIS Integration Runtime genom att stoppa och starta den som dina behov kräver.
Mer information finns i Skapa och konfigurera Azure-SSIS IR. När du har skapat det kan du distribuera och hantera dina befintliga SSIS-paket med små eller inga ändringar med hjälp av välbekanta verktyg som SQL Server Data Tools (SSDT) och SQL Server Management Studio (SSMS), precis som att använda SSIS lokalt.
Mer information om Azure-SSIS-körningen finns i följande artiklar:
- Självstudie: distribuera SSIS-paket till Azure. Den här artikeln innehåller stegvisa instruktioner för att skapa en Azure-SSIS IR och använder en Azure SQL Database som värd för SSIS-katalogen.
- Så här skapar du en Azure-SSIS Integration Runtime. Den här artikeln går vidare med självstudien och innehåller instruktioner om hur du använder SQL Managed Instance och ansluter IR till ett virtuellt nätverk.
- Övervaka en Azure-SSIS IR. Den här artikeln visar hur du hämtar information om en Azure-SSIS IR och ger beskrivningar av statusar i den returnerade informationen.
- Hantera en Azure-SSIS IR. Den här artikeln visar hur du stoppar, startar eller tar bort en Azure-SSIS IR. Den visar också hur du skalar ut Azure-SSIS IR genom att lägga till fler noder i IR.
- Anslut Azure-SSIS IR till ett virtuellt nätverk. Den här artikeln innehåller begreppsrelaterad information om att ansluta Azure-SSIS IR till ett virtuellt Azure-nätverk. Den innehåller också steg för att använda Azure Portal för att konfigurera ett virtuellt nätverk och ansluta en Azure-SSIS IR till det.
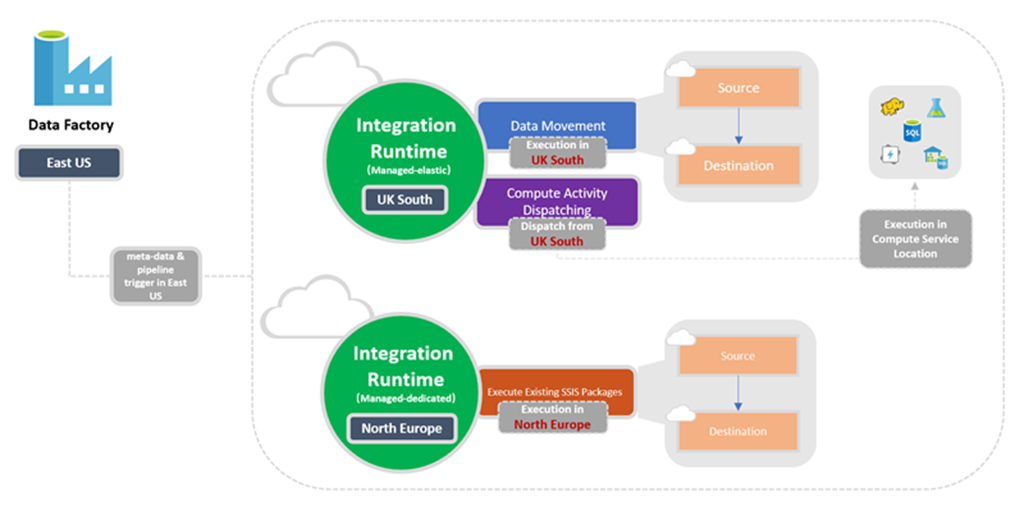
Integration Runtime-plats
Relation mellan fabriksplats och IR-plats
När du skapar en instans av Data Factory eller en Synapse-arbetsyta måste du ange dess plats. Metadata för instansen lagras här, och pipelinen triggas härifrån. Metadata lagras bara i den valda regionen och lagras inte i andra regioner.
Under tiden kan en pipeline komma åt datalager och beräkningstjänster i andra Azure-regioner för att flytta data mellan datalager eller bearbeta data med hjälp av beräkningstjänster. Det här beteende realiseras via globalt tillgängligt IR för att säkerställa dataefterlevnad, effektivitet och minskade kostnader för nätverksegress.
IR-platsen definierar platsen för dess bakändsberäkning, och var datatransport, aktivitetshantering och SSIS-paketkörning utförs. IR-platsen kan skilja sig från platsen för datafabriken som den tillhör.
Azure IR-plats
Du kan ange regionen för en Azure IR, i vilket fall aktiviteten körs eller skickas i den valda regionen.
Standardvärdet är att automatiskt bestämma Azure IR i det offentliga nätverket. Med det här alternativet:
För kopieringsaktivitet görs ett bästa försök att automatiskt identifiera platsen för ditt mottagardatalager och sedan använda IR i samma region, om det är tillgängligt, eller den närmaste i samma geografiska område, annars. Om datalagrets region för mottagare inte kan identifieras används IR i instansens region i stället.
Till exempel skapades en Data Factory eller Synapse-arbetsyta i östra USA.
- När du kopierar data till en Azure Blob i västra USA, körs kopieringsaktiviteten på IR i västra USA om blobben identifieras som vara i den regionen. Om regionidentifieringen misslyckas körs kopieringsaktiviteten på IR i östra USA.
- När du kopierar data till Salesforce, för vilken regionen inte kan identifieras, körs kopieringsaktiviteten på IR i östra USA.
Tips
Om du har strikta krav på dataefterlevnad och behöver se till att data inte lämnar ett visst geografiskt område kan du uttryckligen skapa en Azure IR i en viss region och peka den länkade tjänsten till denna IR med hjälp av egenskapen ConnectVia. Om du till exempel vill kopiera data från en blob i Södra Storbritannien till en Azure Synapse-arbetsyta i Södra Storbritannien och vill säkerställa att data inte lämnar Storbritannien, skapar du en Azure IR i Södra Storbritannien och länkar båda de länkade tjänsterna till denna IR.
För uppslag/GetMetadata/Ta bort aktivitetsutförande (pipelineaktiviteter), transformeringsaktivitetssändning (externa aktiviteter) och redigeringsåtgärder (anslutningstest, bläddra i mapplista och tabellista samt förhandsgranska data) används IR inom samma region som Data Factory eller Synapse-arbetsytan.
För Dataflöde används IR i datafabriken eller Synapse-arbetsytan.
Tips
Bästa praxis är att se till att dataflöden körs i samma region som motsvarande datalager när det är möjligt. Du kan antingen uppnå detta med automatisk lösning för Azure IR (om datalagringsplatsen är samma som Data Factory- eller Synapse Workspace-platsen) eller genom att skapa en ny Azure IR-instans i samma region som dina datalager och sedan köra dataflödena på den.
Om du aktiverar Hanterat virtuellt nätverk med automatisk lösning för Azure IR används IR i datafabriken eller Synapse-arbetsytan.
Du kan övervaka vilken IR-plats som börjar gälla under aktivitetskörningen i övervakningsvyn för pipelineaktivitet i Data Factory Studio eller Synapse Studio eller i nyttolasten för aktivitetsövervakning.
Plats för självhostad IR
Den lokalt installerade IR:en är logiskt registrerad på Data Factory- eller Synapse-arbetsytan och den beräkning som används för att stödja dess funktioner tillhandahålls av dig. Därför finns det ingen explicit platsegenskap för lokalt installerad IR.
När IR med egen värd används för att utföra dataflyttning extraherar den data från källan och skriver dem till målet.
Azure-SSIS IR-plats
Kommentar
Azure-SSIS-integreringskörningar stöds för närvarande inte i Synapse-pipelines.
Att välja rätt plats för Azure-SSIS IR är viktigt för att uppnå höga prestanda i dina arbetsflöden för extrahering, transformering och laddning (ETL).
- Platsen för din Azure-SSIS IR behöver inte vara samma som platsen för din Data Factory, men den bör vara samma som platsen för din egen Azure SQL Database eller SQL Managed Instance där SSISDB finns. På så sätt kan din Azure-SSIS Integration Runtime enkelt komma åt SSISDB utan att orsaka överdriven trafik mellan olika platser.
- Om du inte har någon befintlig SQL Database eller SQL Managed Instance, men du har lokala datakällor/mål, bör du skapa en ny Azure SQL Database eller SQL Managed Instance på samma plats som ett virtuellt nätverk som är anslutet till ditt lokala nätverk. På så sätt kan du skapa din Azure-SSIS IR med hjälp av den nya Azure SQL Database eller SQL Managed Instance och ansluta till det virtuella nätverket. Allt finns på samma plats, vilket minimerar dataflytten och tillhörande kostnader, samtidigt som prestandan maximeras.
- Om platsen för din befintliga Azure SQL Database eller SQL Managed Instance inte är samma som platsen för ett virtuellt nätverk som är anslutet till ditt lokala nätverk skapar du först din Azure-SSIS IR med hjälp av en befintlig Azure SQL Database eller SQL Managed Instance och ansluter till ett annat virtuellt nätverk på samma plats. Konfigurera sedan ett virtuellt nätverk till en virtuell nätverksanslutning mellan de olika platserna.
Följande diagram visar platsinställningarna för Data Factory och dess integreringskörningar:
Bestämma vilken IR som ska användas
Om en aktivitet associeras med mer än en typ av integrationskörning matchas den med en av dem. Den lokalt installerade integrationskörningen har företräde framför Azure Integration Runtime i Azure Data Factory eller Synapse Workspace-instanser med hjälp av ett hanterat virtuellt nätverk. Och det senare har företräde framför den globala Azure-integreringskörningen.
En kopieringsaktivitet används till exempel för att kopiera data från källa till mottagare. Den globala Azure-integreringskörningen är associerad med den länkade tjänsten till källan och en Azure-integreringskörning i ett hanterat virtuellt Azure Data Factory-nätverk associeras med den länkade tjänsten för mottagare. Resultatet är att både käll- och mottagarlänkade tjänster använder Azure-integreringskörningen i det hanterade virtuella Azure Data Factory-nätverket. Men om en lokalt installerad integrationskörning är associerad med den länkade tjänsten för källan använder både käll- och mottagarlänkad tjänst den lokalt installerade integrationskörningen.
Kopieringsaktivitet
Aktiviteten Kopiera kräver att både käll- och mottagarlänkade tjänster definierar dataflödets riktning. Följande logik används till att bestämma vilken Integration Runtime-instans som används för att utföra kopieringen:
- Kopiering mellan två molndatakällor: om både käll- och mottagarlänkade tjänster använder Azure IR används den regionala Azure IR om den har angetts, eller om platsen för Azure IR automatiskt bestäms om alternativet autoresolve IR (standard) valdes enligt beskrivningen i avsnittet Integration runtime location (Plats för integreringskörning).
- Kopiering mellan en molndatakälla och en datakälla i ett privat nätverk: om antingen den länkade källtjänsten eller mottagaren pekar på en lokalt installerad IR körs kopieringsaktiviteten på den lokalt installerade IR:n.
- Kopiering mellan två datakällor i ett privat nätverk: både den länkade käll- och mottagartjänsten måste peka på samma instans av integrationskörningen och att IR används för att köra kopieringsaktiviteten.
Lookup och GetMetadata-aktivitet
Aktiviteterna Lookup och GetMetadata har körts på integreringskörningsmiljön som är associerad med den länkade datalagringstjänsten.
Extern transformeringsaktivitet
Varje extern transformeringsaktivitet som använder en extern beräkningsmotor har en länkad måldatortjänst som pekar på en integrationskörning. Den här IR-instansen avgör var den externa handkodade transformeringsaktiviteten skickas.
Dataflödesaktivitet
Dataflödesaktiviteter körs på deras associerade Azure-integreringskörningar. Dataflödesegenskaperna i din Azure IR avgör vilken Spark-beräkning som används och hanteras fullständigt av tjänsten.
Integration Runtime i CI/CD
Integreringskörningar ändras inte ofta och är lika över alla stadier i din CI/CD. Data Factory kräver att du har samma namn och typ av integreringskörning i alla faser av CI/CD. Om du vill dela integreringskörningar i alla steg kan du överväga att använda en dedikerad fabrik bara för att innehålla de delade integrationskörningarna. Du kan sedan använda det här delade systemet i alla dina miljöer som en länkad typ av integrationskörning.
Relaterat innehåll
Mer information finns i följande artiklar:
- Skapa Azure Integration Runtime
- Skapa Integration Runtime med egen värd
- Skapa en Azure-SSIS Integration Runtime. Den här artikeln går vidare med självstudien och innehåller instruktioner om hur du använder SQL Managed Instance och ansluter IR till ett virtuellt nätverk.