Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Tips
- Om du vill jämföra mappning av dataflödesomvandlingar med deras Motsvarigheter till Dataflöde Gen2 läser du En guide till Dataflöde Gen2 för mappning av dataflödesanvändare.
- Information om datatransformeringar i Microsoft Fabric finns i översikten Dataflow Gen2.
Vad är kartläggningsdataflöden?
Mappning av dataflöden är visuellt utformade datatransformeringar i Azure Data Factory. Med dataflöden kan datatekniker utveckla datatransformeringslogik utan att skriva kod. De resulterande dataflödena körs som aktiviteter i Azure Data Factory pipelines som använder utskalade Apache Spark-kluster. Dataflödesaktiviteter kan operationaliseras med befintliga Azure Data Factory funktioner för schemaläggning, kontroll, flöde och övervakning.
Mappning av dataflöden ger en helt visuell upplevelse utan att kodning krävs. Dina dataflöden körs i ADF-hanterade körningskluster för utskalad databearbetning. Azure Data Factory hanterar all kodöversättning, sökvägsoptimering och körning av dina dataflödesjobb.
Komma igång
Dataflöden skapas från resurspanelen i fabriken, såsom pipelines och datauppsättningar. Om du vill skapa en data flow väljer du plustecknet bredvid Faktorresurser och väljer sedan Data Flow.
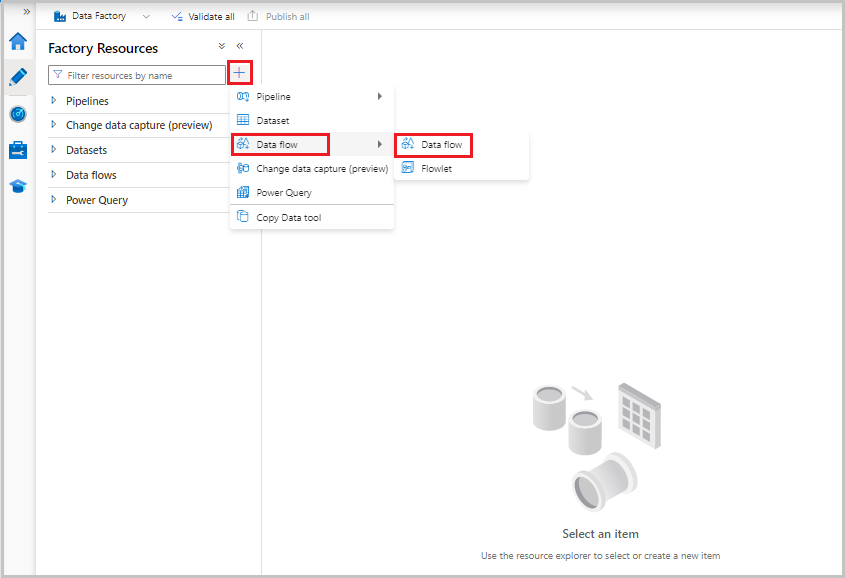 Den här åtgärden tar dig till dataflödesarbetsytan, där du kan skapa din omvandlingslogik. Välj Lägg till källa för att börja konfigurera källtransformeringen. Mer information finns i Källtransformering.
Den här åtgärden tar dig till dataflödesarbetsytan, där du kan skapa din omvandlingslogik. Välj Lägg till källa för att börja konfigurera källtransformeringen. Mer information finns i Källtransformering.
Redigera dataflöden
Mappning av dataflöde har en unik redigeringsarbetsyta som är utformad för att göra det enkelt att skapa transformeringslogik. Dataflödesarbetsytan är uppdelad i tre delar: det övre fältet, diagrammet och konfigurationspanelen.
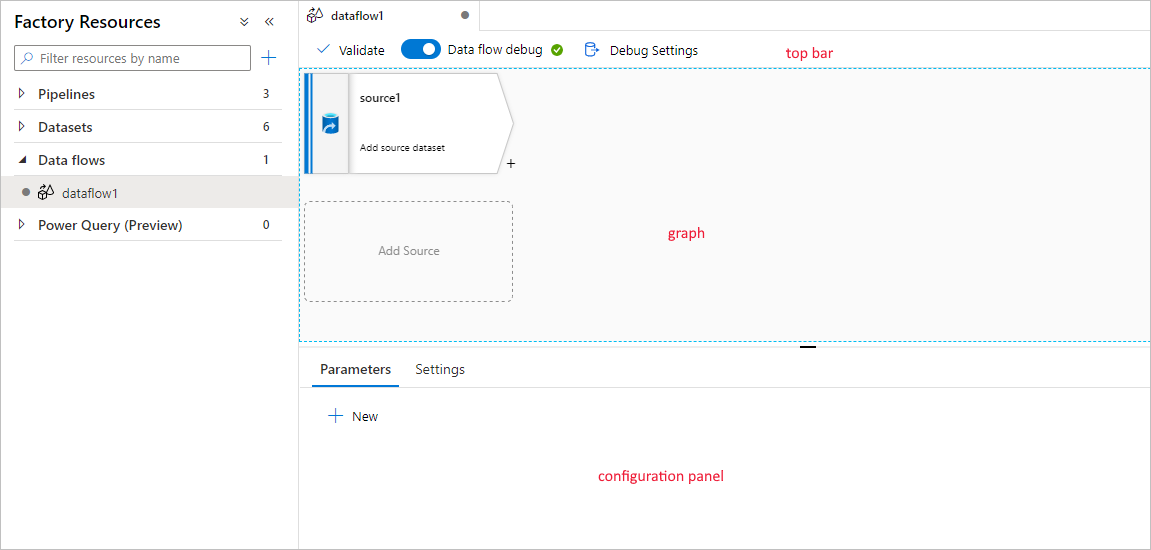
Graf
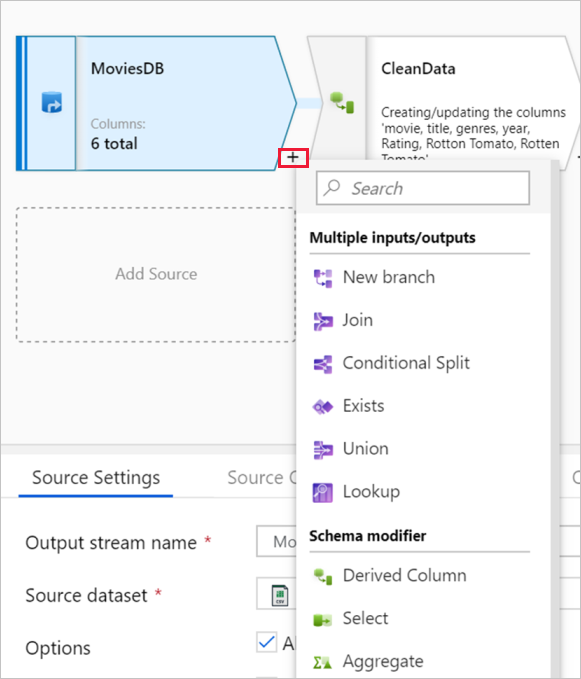
Diagrammet visar transformeringsströmmen. Den visar ursprunget för källdata när de flödar till en eller flera mottagare. Mottagningspunkter kan vara alla målplatser för datakällor där du vill flytta resultatet av dina transformerade data. Om du vill lägga till en ny källa väljer du Lägg till källa. Om du vill lägga till en ny transformering väljer du plustecknet längst ned till höger i en befintlig transformering. Läs mer om hur du hanterar dataflödesdiagrammet.
Konfigurationspanel
Konfigurationspanelen visar de inställningar som är specifika för den aktuella transformeringen. Om ingen transformering har valts visas dataflödet. I den övergripande dataflödeskonfigurationen kan du lägga till parametrar via fliken Parametrar . Mer information finns i Mappa dataflödesparametrar.
Varje transformering innehåller minst fyra konfigurationsflikar.
Transformeringsinställningar
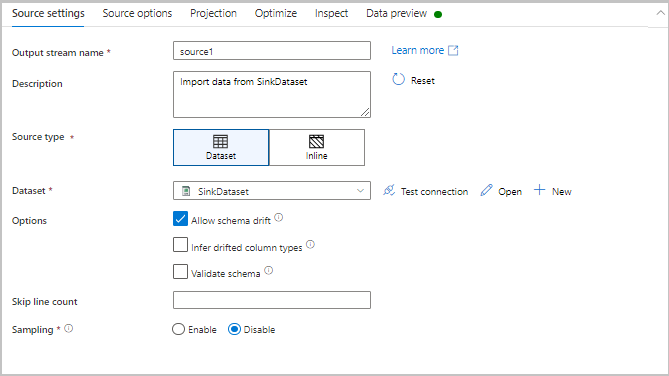
Den första fliken i konfigurationsfönstret för varje transformering innehåller de inställningar som är specifika för omvandlingen. Mer information finns på dokumentationssidan för omvandlingen.
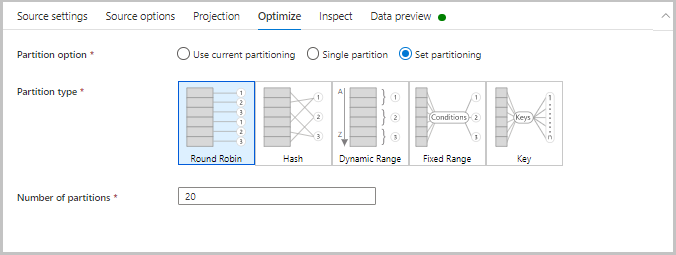
Optimera
Fliken Optimera innehåller inställningar för att konfigurera partitioneringsscheman. Mer information om hur du optimerar dina dataflöden finns i prestandaguiden för dataflödesmappning.
Undersöka
Fliken Inspektera visar metadata för dataströmmen som du transformerar. Du kan se kolumnantal, ändrade kolumner, tillagda kolumner, datatyper, kolumnordning och kolumnreferenser. Granska är en skrivskyddad vy över dina metadata. Du behöver inte ha felsökningsläget aktiverat för att se metadata i fönstret Inspektera .
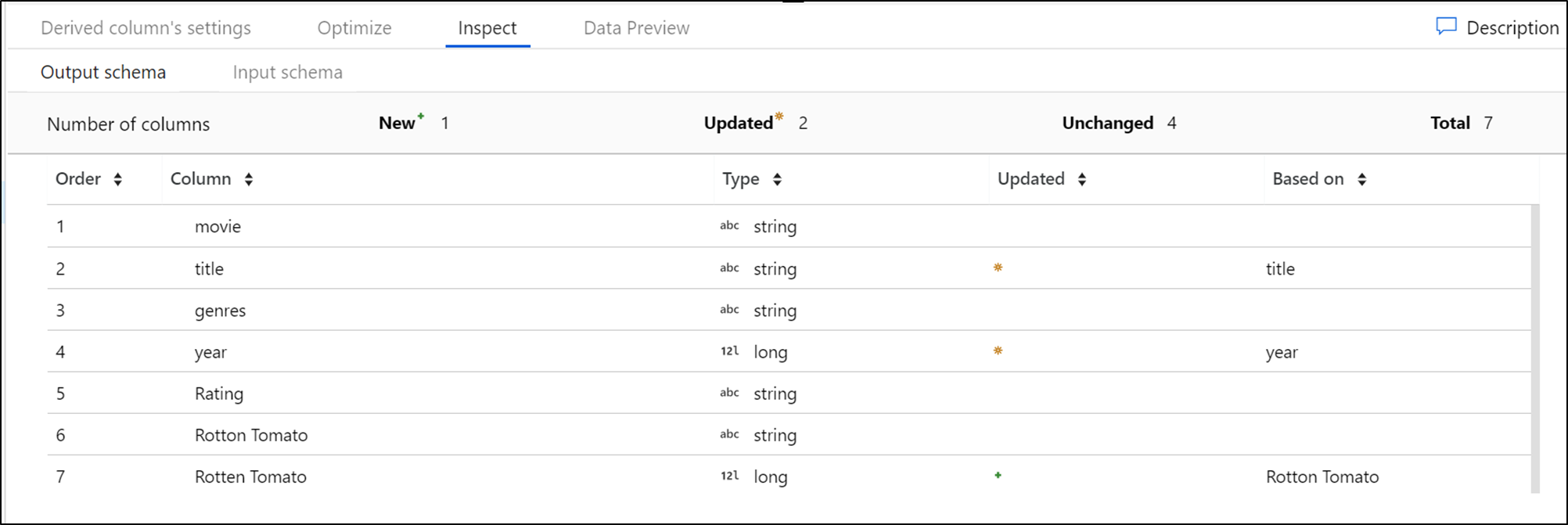
När du ändrar formen på dina data genom transformeringar kan du se flödet för metadataändringar i fönstret Inspektera . Om det inte finns något definierat schema i källtransformeringen visas inte metadata i fönstret Inspektera . Brist på metadata är vanligt i scenarier med schemaavvikelser.
Förhandsgranskning av data
Om felsökningsläget är aktiverat ger fliken Förhandsgranskning av data en interaktiv ögonblicksbild av data vid varje transformering. Mer information finns i Dataförhandsgranskning i felsökningsläge.
Övre stapel
Det övre fältet innehåller åtgärder som påverkar hela dataflödet, till exempel sparande och validering. Du kan också visa den underliggande JSON-koden och dataflödesskriptet för din omvandlingslogik. Mer information finns i avsnittet om dataflödesskriptet.
Tillgängliga transformeringar
Visa översikten över dataflödesmappningstransformering för att hämta en lista över tillgängliga transformeringar.
Dataflödesdatatyper
- array
- binär
- boolean
- komplex
- decimaltal (inkluderar precision)
- datum
- flyttal
- integer
- lång
- karta
- kort
- sträng
- tidsstämpel
Dataflödesaktivitet
Mappning av dataflöden operationaliseras i ADF-pipelines med hjälp av dataflödesaktiviteten. Allt en användare behöver göra är att ange vilken integrationskörning som ska användas och skicka in parametervärden. Mer information finns i Azure integration runtime.
Felsökningsläge
Med felsökningsläget kan du interaktivt se resultatet av varje transformeringssteg medan du skapar och felsöker dina dataflöden. Felsökningssessionen kan användas både när du skapar dataflödeslogik och när du kör pipeline-felsökningskörningar med dataflödesaktiviteter. Mer information finns i dokumentationen för felsökningsläge.
Övervaka dataflöden
Mappning av dataflöde integreras med befintliga Azure Data Factory övervakningsfunktioner. Information om hur du förstår dataflödesövervakningsutdata finns i övervaka mappning av dataflöden.
Azure Data Factory-teamet har skapat en performance tuning guide som hjälper dig att optimera körningstiden för dina dataflöden när du har skapat din affärslogik.
Relaterat innehåll
- Lär dig hur du skapar en källtransformering.
- Lär dig hur du skapar dina dataflöden i felsökningsläge.