Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tips
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Kontinuerlig integrering är en metod för att testa varje ändring som görs i din kodbas automatiskt och så tidigt som möjligt. Kontinuerlig leverans följer testerna som utförs vid den kontinuerliga integreringen och skickar ändringarna till ett mellanlagrings- eller produktionssystem.
I Azure Data Factory innebär kontinuerlig integrering och leverans (CI/CD) flytt av Data Factory-pipelines från en miljö (utveckling, testning, produktion) till en annan. Azure Data Factory använder Azure Resource Manager-mallar för att lagra konfigurationen av dina olika ADF-entiteter (pipelines, datauppsättningar, dataflöden och så vidare). Det finns två föreslagna metoder för att flytta upp en datafabrik till en annan miljö:
- Automatiserad distribution genom Datafabrikens integrering med Azure Pipelines
- Ladda upp en Resource Manager-mall manuellt med hjälp av Data Factory UX-integrering med Azure Resource Manager.
Kommentar
Vi rekommenderar att du använder Azure Az PowerShell-modulen för att interagera med Azure. Se Installera Azure PowerShell för att komma igång. Information om hur du migrerar till Az PowerShell-modulen finns i artikeln om att migrera Azure PowerShell från AzureRM till Az.
CI/CD-livscykel
Anteckning
För mer information, se Förbättringar inom kontinuerlig distribution.
Nedan visas en exempelöversikt över CI/CD-livscykeln i en Azure-datafabrik som har konfigurerats med Azure Repos Git. Mer information om hur du konfigurerar en Git-lagringsplats finns i Källkontroll i Azure Data Factory.
En utvecklingsdatafabrik skapas och konfigureras med Azure Repos Git. Alla utvecklare bör ha behörighet att skapa Data Factory-resurser som pipelines och datauppsättningar.
En utvecklare skapar en funktionsgren för att göra en ändring. Signerade commits stöds inte i Data Factory. De felsöker sina pipelinekörningar med de senaste ändringarna. Mer information om hur du felsöker en pipelinekörning finns i Iterativ utveckling och felsökning med Azure Data Factory.
När en utvecklare är nöjd med sina ändringar skapar de en pull-förfrågan från sin funktionsgren till huvud- eller samarbetsgrenen för att få dem granskade av kollegor.
När en pull request har godkänts och ändringarna har sammanfogats i huvudgrenen, publiceras ändringarna till utvecklingsmiljön.
När teamet är redo att distribuera ändringarna till en test- eller UAT-fabrik (User Acceptance Testing) går teamet till sin Azure Pipelines-version och distribuerar den önskade versionen av utvecklingsfabriken till UAT. Den här distributionen sker som en del av en Azure Pipelines-uppgift och använder Resource Manager-mallparametrar för att tillämpa lämplig konfiguration.
När ändringarna har verifierats i testfabriken distribuerar du till produktionsfabriken med hjälp av nästa uppgift i pipelineversionen.
Kommentar
Endast utvecklingsfabriken är associerad med en git-lagringsplats. Test- och produktionsfabrikerna bör inte ha en git-lagringsplats som är associerad med dem och bör endast uppdateras via en Azure DevOps-pipeline eller via en resource management-mall.
Bilden nedan visar de olika stegen i den här livscykeln.
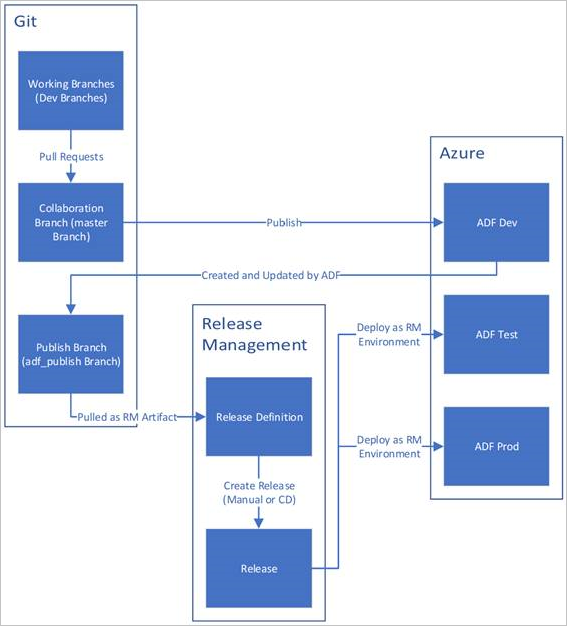
Bästa praxis för CI/CD
Om du använder Git-integrering med din datafabrik och har en CI/CD-pipeline som flyttar dina ändringar från utveckling till test och sedan till produktion rekommenderar vi följande metodtips:
Git-integrering. Konfigurera endast din utvecklingsdatafabrik med Git-integrering. Ändringar i test och produktion distribueras via CI/CD och behöver inte Git-integrering.
Skript före och efter distribution. Innan distributionssteget för Resource Manager i CI/CD måste du utföra vissa uppgifter, till exempel att stoppa och starta om utlösare och utföra rensning. Vi rekommenderar att du använder PowerShell-skript före och efter distributionsuppgiften. Mer information finns i Uppdatera aktiva utlösare. Datafabriksteamet har angett ett skript som ska användas längst ned på den här sidan.
Kommentar
Använd PrePostDeploymentScript.Ver2.ps1 om du vill slå av/på endast de utlösare som har ändrats istället för att slå av/på alla utlösare under CI/CD.
Varning
Se till att använda PowerShell Core i ADO-uppgiften för att köra skriptet.
Varning
Om du inte använder de senaste versionerna av PowerShell- och Data Factory-modulen kan du stöta på deserialiseringsfel när du kör kommandona.
Integreringskörningar och delning. Integreringskörningar ändras inte ofta och är liknande över alla faser i din CI/CD. Data Factory förväntar sig att du har samma namn, typ och undertyp av integrationsmiljö i alla faser av CI/CD. Om du vill dela integreringskörningar i alla faser bör du överväga att använda en ternary-fabrik bara för att innehålla de delade integrationskörningarna. Du kan använda den här delade fabriken i alla dina miljöer som en länkad integrationskörningstyp.
Anteckning
Integreringskörningsdelningen är endast tillgänglig för lokalt installerade integrationskörningar. Azure-SSIS-integreringskörningar stöder inte delning.
Utplacering av hanterade privata slutpunkter. Om det redan finns en privat slutpunkt i en fabrik och du försöker distribuera en ARM-mall som innehåller en privat slutpunkt med samma namn, men med ändrade egenskaper, misslyckas distributionen. Med andra ord kan du distribuera en privat slutpunkt så länge den har samma egenskaper som den som redan finns i fabriken. Om någon egenskap skiljer sig åt mellan miljöerna kan du åsidosätta den genom att parametrisera den egenskapen och ange respektive värde under distributionen.
Key Vault. När du använder länkade tjänster vars anslutningsinformation lagras i Azure Key Vault rekommenderar vi att du behåller separata nyckelvalv för olika miljöer. Du kan också konfigurera separata behörighetsnivåer för varje nyckelvalv. Du kanske till exempel inte vill att dina teammedlemmar ska ha behörighet till produktionshemligheter. Om du följer den här metoden rekommenderar vi att du behåller samma hemliga namn i alla steg. Om du behåller samma hemliga namn behöver du inte parameterisera varje anslutningssträng i CI/CD-miljöer eftersom det enda som ändras är nyckelvalvets namn, vilket är en separat parameter.
Namngivning av resurser. På grund av begränsningar för ARM-mallar kan problem i distributionen uppstå om resurserna innehåller blanksteg i namnet. Azure Data Factory-teamet rekommenderar att du använder "_" eller "-" tecken i stället för blanksteg för resurser. Till exempel skulle "Pipeline_1" vara ett bättre namn än "Pipeline 1".
Ändrar lagringsplats. ADF hanterar GIT-lagringsplatsinnehåll automatiskt. Om du ändrar eller lägger till manuellt orelaterade filer eller mappar var som helst i ADF Git-lagringsplatsens datamapp kan det orsaka resursinläsningsfel. Förekomsten av .bak filer kan till exempel orsaka ADF CI/CD-fel, så de bör tas bort för att ADF ska läsas in.
Exponeringskontroll och funktionsflaggor. När du arbetar i ett team finns det instanser där du kan sammanfoga ändringar, men inte vill att de ska köras i upphöjda miljöer som PROD och QA. För att hantera det här scenariot rekommenderar ADF-teamet DevOps-konceptet att använda funktionsflaggor. I ADF kan du kombinera globala parametrar och if-villkorsaktiviteten för att dölja uppsättningar av logik baserat på dessa miljöflaggor.
Information om hur du konfigurerar en funktionsflagga finns i självstudiekursen nedan:
Funktioner som inte stöds
Data Factory är utformad för att inte tillåta selektivt val av incheckningar eller selektiv publicering av resurser. Publiceringar innehåller alla ändringar som görs i datafabriken.
- Datafabrikentiteter är beroende av varandra. Utlösare beror till exempel på pipelines och pipelines är beroende av datauppsättningar och andra pipelines. Selektiv publicering av en delmängd av resurser kan leda till oväntade beteenden och fel.
- I sällsynta fall när du behöver selektiv publicering bör du överväga att använda en snabbkorrigering. Mer information finns i Produktionsmiljön för snabbkorrigeringar.
Azure Data Factory-teamet rekommenderar inte att du tilldelar Azure RBAC-kontroller till enskilda entiteter (pipelines, datauppsättningar osv.) i en datafabrik. Om en utvecklare till exempel har åtkomst till en pipeline eller en datamängd ska utvecklaren kunna ha åtkomst till alla pipelines eller datamängder i datafabriken. Om du känner att du behöver tillämpa många Azure-roller i en datafabrik kan du överväga att distribuera en andra datafabrik.
Det går inte att publicera från privata grenar.
Du kan för närvarande inte vara värd för projekt på Bitbucket.
Du kan för närvarande inte exportera och importera aviseringar och matriser som parametrar.
Partiella ARM-mallar i publiceringsgrenen stöds inte längre från och med den 1 november 2021. Om projektet använde den här funktionen växlar du till en mekanism som stöds för distributioner med hjälp av:
ARMTemplateForFactory.jsonellerlinkedTemplatesfiler.
Relaterat innehåll
- Förbättringar av kontinuerlig distribution
- Automatisera kontinuerlig integrering med Azure Pipelines-versioner
- Manuellt höja upp en Resource Manager-mall till varje miljö
- Använda anpassade parametrar med en Resource Manager-mall
- Länkade Resource Manager-mallar
- Använda en produktionsmiljö för snabbkorrigering
- Exempelskript före och efter distribution