Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Verktyget Kopiera data underlättar och optimerar processen för att mata in data i en datasjö, vilket vanligtvis är ett första steg i ett scenario för dataintegrering från slutpunkt till slutpunkt. Det sparar tid, särskilt när du använder tjänsten för att mata in data från en datakälla för första gången. Några av fördelarna med att använda det här verktyget är:
- När du använder verktyget Kopiera data behöver du inte förstå tjänstdefinitioner för länkade tjänster, datauppsättningar, pipelines, aktiviteter och utlösare.
- Verktyget Kopiera datas flöde är intuitivt för att ladda in data i en datasjö. Verktyget skapar automatiskt alla nödvändiga resurser för att kopiera data från det valda källdatalagret till det valda datalagret för mål/mottagare.
- Verktyget Kopiera data hjälper dig att verifiera de data som matas in vid tidpunkten för redigeringen, vilket hjälper dig att undvika eventuella fel i början.
- Om du behöver implementera komplex affärslogik för att läsa in data till en datasjö kan du fortfarande redigera de resurser som skapas av verktyget Kopiera data med redigering per aktivitet i användargränssnittet.
Följande tabell innehåller vägledning om när du ska använda verktyget Kopiera data jämfört med redigering per aktivitet i användargränssnittet:
| Kopiera dataverktyg | Redigering per enskild aktivitet (kopieringsaktivitet) |
|---|---|
| Du vill enkelt skapa en datainläsningsuppgift utan att lära dig om entiteter (länkade tjänster, datauppsättningar, pipelines osv.) | Du vill implementera komplex och flexibel logik för att läsa in data i sjön. |
| Du vill snabbt ladda ett stort antal dataartefakter i en datasjö. | Du vill länka Copy activity med efterföljande aktiviteter för rensning eller bearbetning av data. |
Starta verktyget Kopiera data genom att välja panelen Ingest på startsidan för datafabriken eller Synapse Studio användargränssnittet.
Efter att du har startat verktyget kopiera data ser du två typer av uppgifter: den ena är inbyggd kopieringsaktivitet och den andra är metadatadriven kopieringsaktivitet. Den inbyggda kopieringsaktiviteten gör att du kan skapa en pipeline inom fem minuter för att replikera data utan att lära dig mer om entiteter. Den metadatadrivna kopieringsuppgiften underlättar din resa med att skapa parametriserade pipelines och en extern kontrolltabell för att kunna hantera kopiering av stora mängder objekt (till exempel tusentals tabeller) i stor skala. Du kan se mer information i metadatadrivna kopieringsdata.
Intuitivt flöde för att läsa in data i en datasjö
Med det här verktyget kan du enkelt flytta data från en mängd olika källor till destinationer på några minuter med ett intuitivt flöde:
Konfigurera inställningar för källan.
Konfigurera inställningar för målet.
Konfigurera avancerade inställningar för kopieringsåtgärden, till exempel kolumnmappning, prestandainställningar och feltoleransinställningar.
Ange ett schema för datainläsningsaktiviteten.
Granska sammanfattningen av entiteter som ska skapas.
Redigera pipelinen för att uppdatera inställningarna för kopieringsaktiviteten efter behov.
Verktyget är utformat med stordata i åtanke från början, med stöd för olika data- och objekttyper. Du kan använda den för att flytta hundratals mappar, filer eller tabeller. Verktyget stöder automatisk dataförhandsgranskning, schemainsamling och automatisk mappning samt datafiltrering.
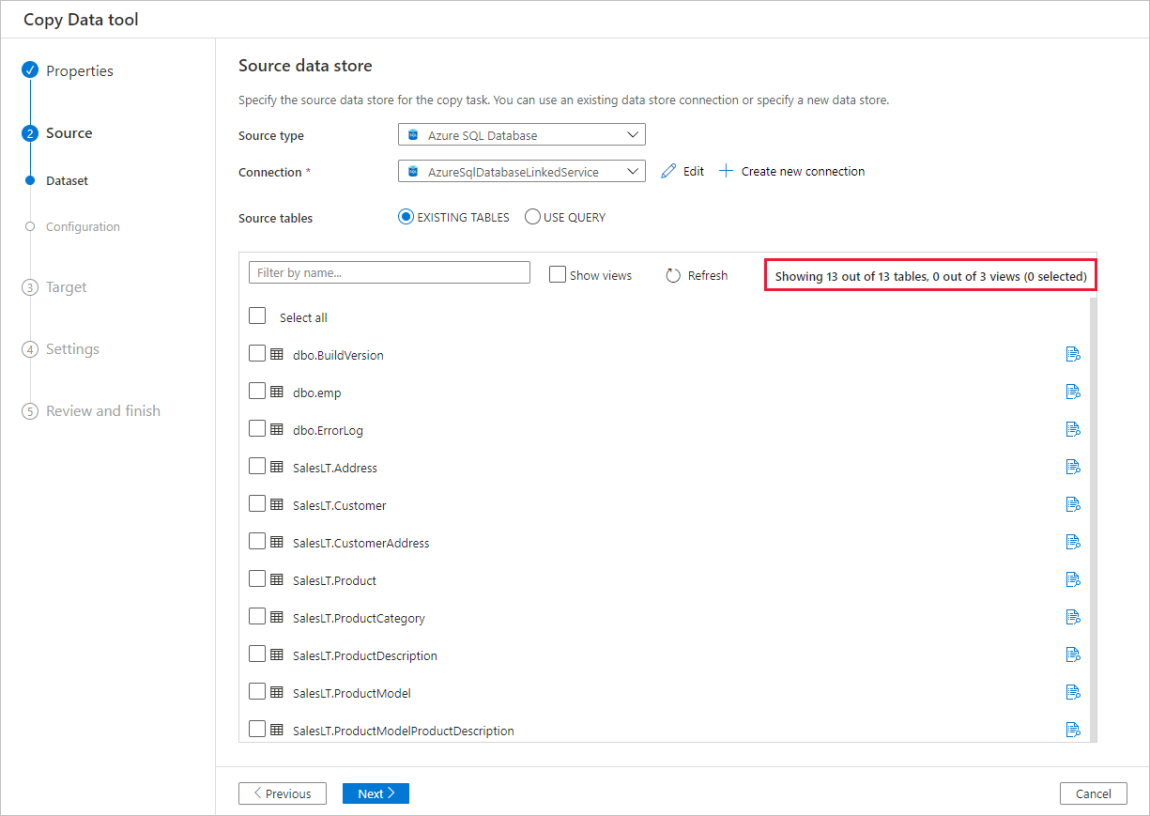
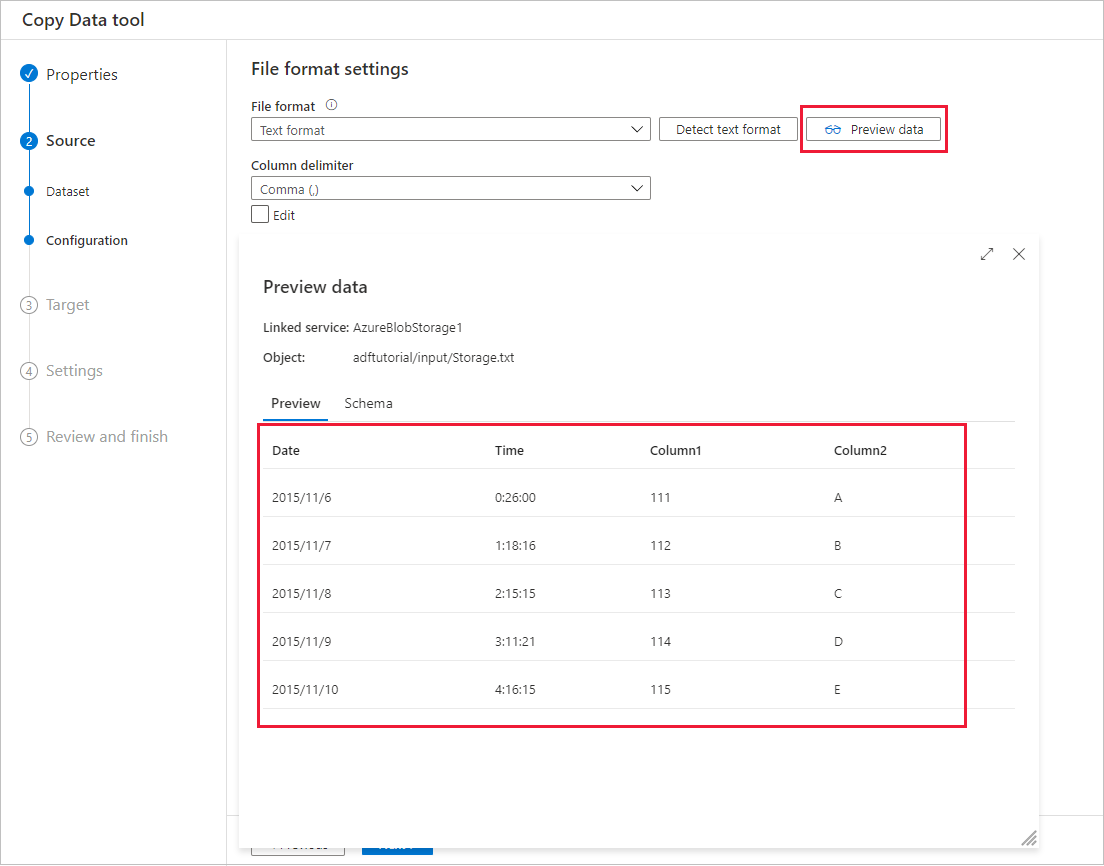
Automatisk förhandsgranskning av data
Du kan förhandsgranska en del av data från det valda källdatalagret, vilket gör att du kan verifiera de data som kopieras. Om källdata dessutom finns i en textfil parsar verktyget Kopiera data textfilen för att automatiskt identifiera rad- och kolumnavgränsare och schema.
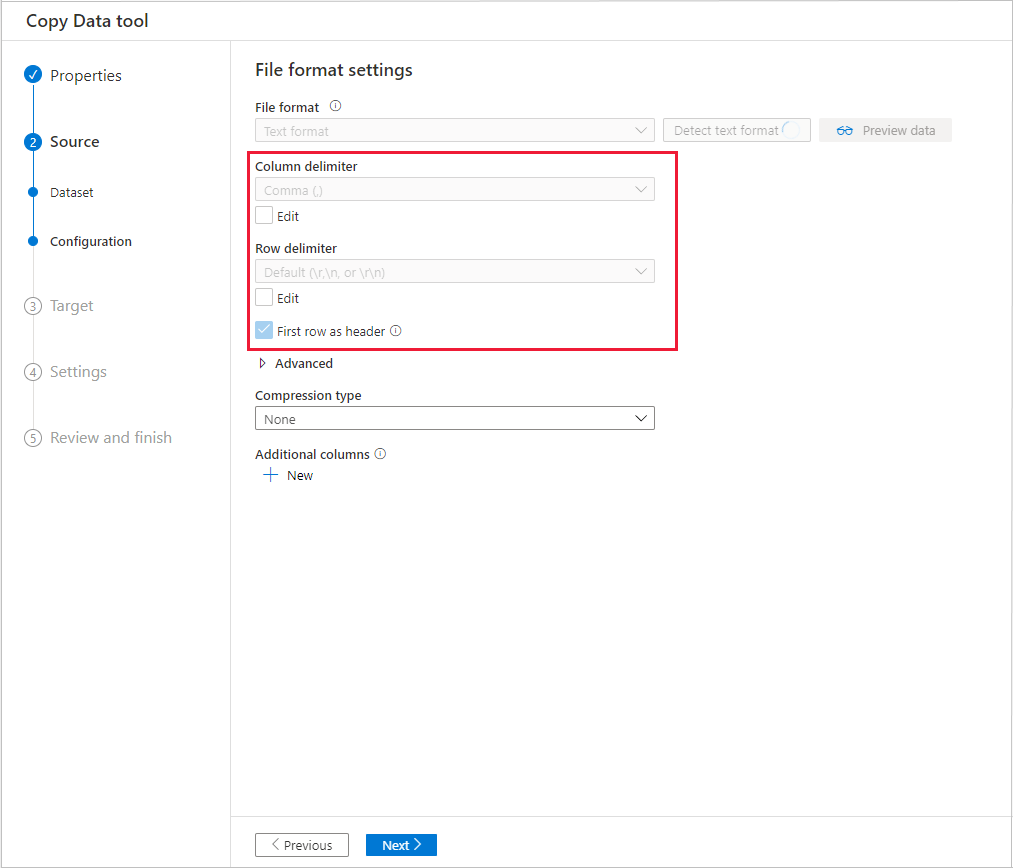
Efter identifieringen väljer du Förhandsgranska data:
Schemainsamling och automatisk mappning
Schemat för datakällan kanske inte är samma som schemat för datamål i många fall. I det här scenariot måste du mappa kolumner från källschemat till kolumner från målschemat.
Verktyget Kopiera data övervakar och lär dig ditt beteende när du mappar kolumner mellan käll- och mållager. När du har valt en eller några kolumner från källdatalagret och mappar dem till målschemat börjar verktyget Kopiera data analysera mönstret för kolumnpar som du valde från båda sidor. Sedan tillämpas samma mönster på resten av kolumnerna. Därför ser du att alla kolumner har mappats till målet på ett sätt som du vill ha precis efter flera klick. Om du inte är nöjd med valet av kolumnmappning som tillhandahålls av verktyget Kopiera data kan du ignorera det och fortsätta med att mappa kolumnerna manuellt. Under tiden lär sig och uppdaterar verktyget Kopiera data hela tiden mönstret och når slutligen rätt mönster för den kolumnmappning som du vill uppnå.
Kommentar
När du kopierar data från SQL Server eller Azure SQL Database till Azure Synapse Analytics, om tabellen inte finns i mållagret, stöder verktyget Kopiera data att tabellen skapas automatiskt med hjälp av källschemat.
Filtrera data
Du kan filtrera källdata för att endast välja de data som behöver kopieras till datalagret för mottagare. Filtrering minskar mängden data som ska kopieras till mottagardatalagret och förbättrar därför kopieringsoperationens dataflöde. Verktyget Kopiera data är ett flexibelt sätt att filtrera data i en relationsdatabas med hjälp av SQL-frågespråket eller filer i en Azure blobmapp.
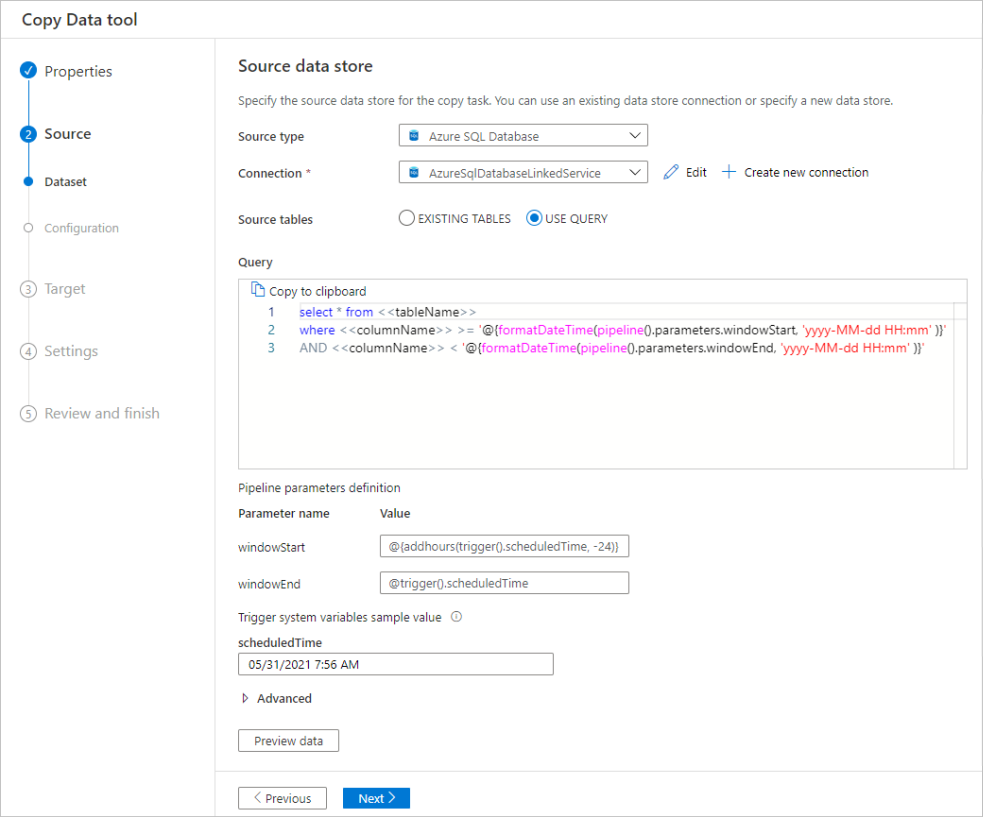
Filtrera data i en databas
Följande skärmbild visar en SQL-fråga för att filtrera data.
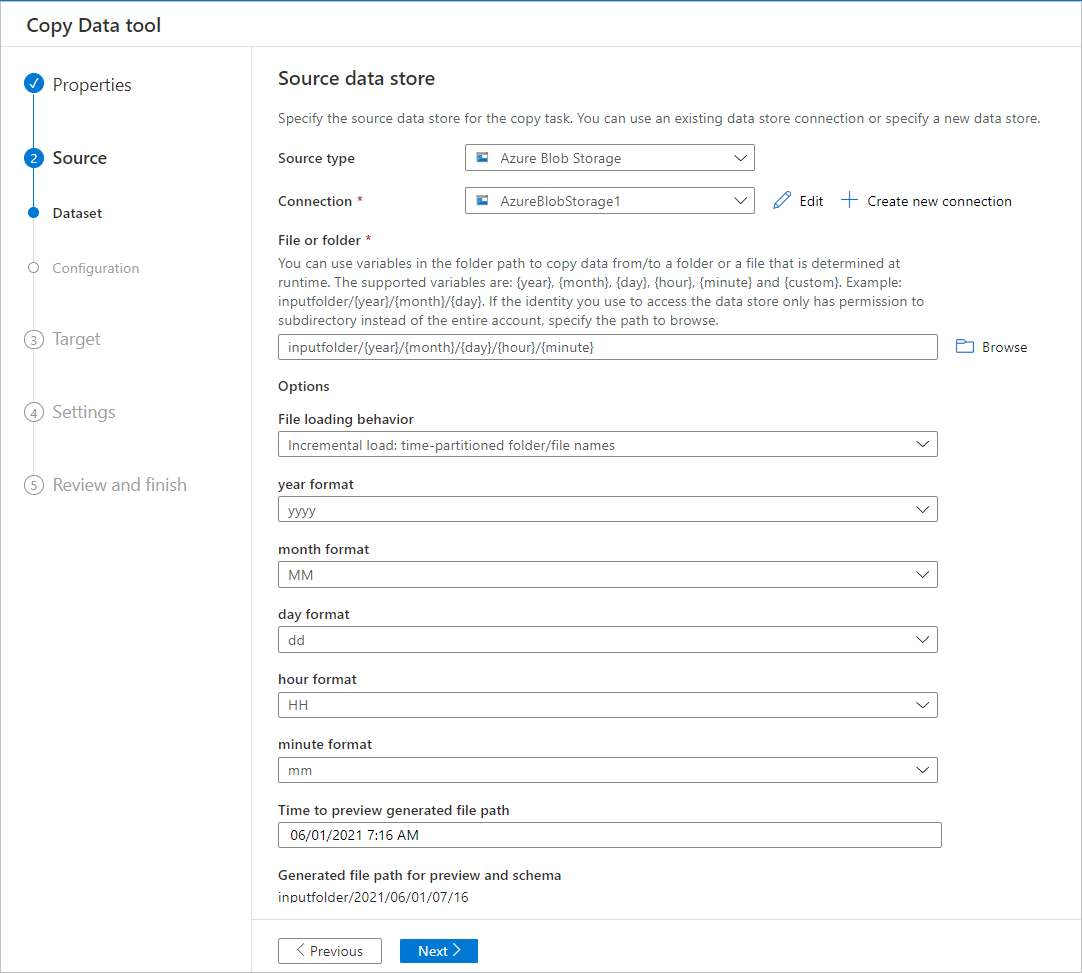
Filtrera data i en Azure blob-mapp
Du kan använda variabler i mappsökvägen för att kopiera data från en mapp. Variablerna som stöds är: {year}, {month}, {day}, {hour} och {minute}. Till exempel: inputfolder/{year}/{month}/{day}.
Anta att du har indatamappar i följande format:
2016/03/01/01
2016/03/01/02
2016/03/01/03
...
Välj knappen Bläddra för Fil eller mapp, bläddra till någon av dessa mappar (till exempel 2016-03-01-02>>>) och välj Välj. Du bör se 2016/03/01/02 i textrutan.
Ersätt sedan 2016 med {year}, 03 med {month}, 01 med {day} och 02 med {hour}, och tryck på tabbtangenten. När du väljer Inkrementell belastning: tidspartitionerade mapp-/filnamn i avsnittet Beteende för filinläsning och du väljer Schema ellerRullande fönster på sidan Egenskaper bör du se listrutor för att välja format för dessa fyra variabler:
Verktyget Kopiera data genererar parametrar med uttryck, funktioner och systemvariabler som kan användas för att representera {year}, {month}, {day}, {hour} och {minute} när du skapar pipeline.
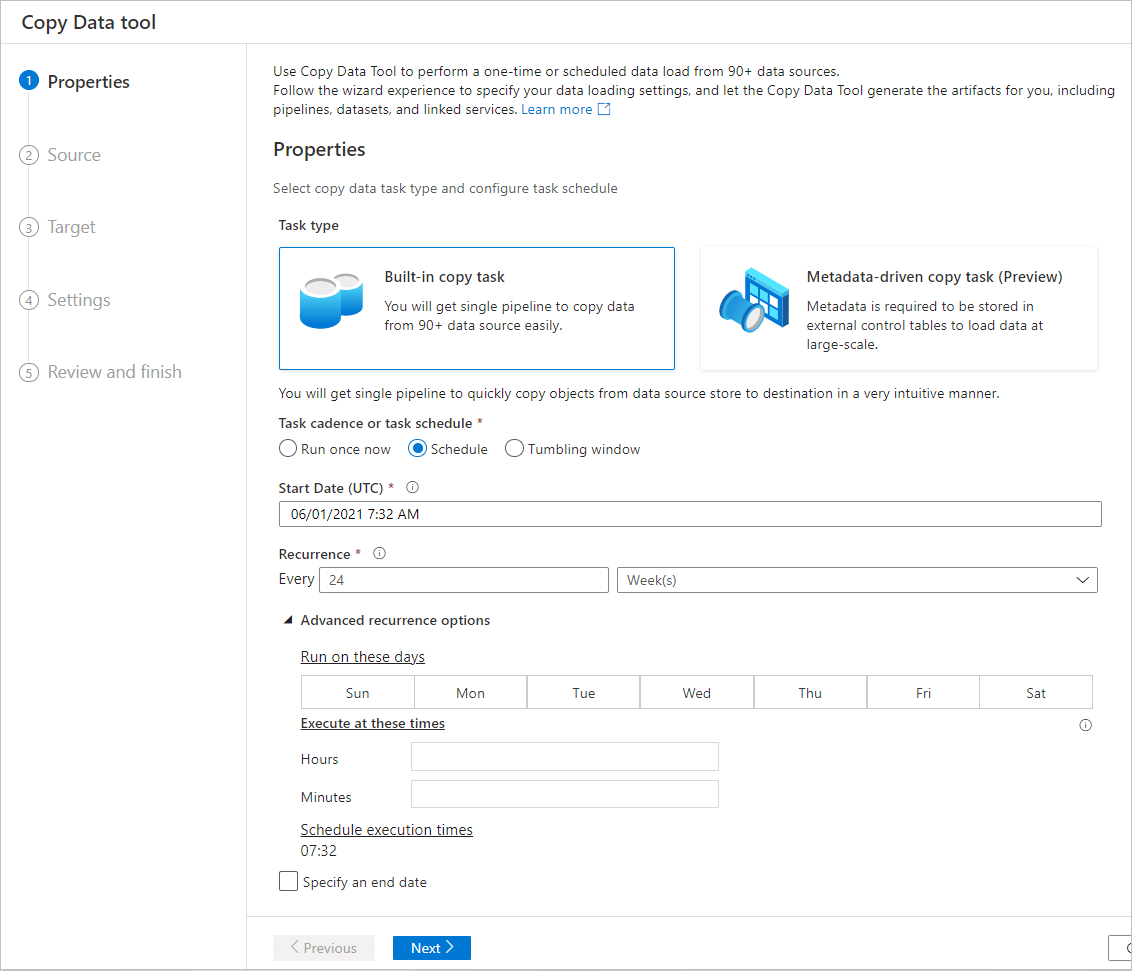
Planeringsalternativ
Du kan köra kopieringsåtgärden en gång eller enligt ett schema (varje timme, varje dag och så vidare). Dessa alternativ kan användas för anslutningar i olika miljöer, inklusive på plats, i molnet och på den lokala skrivbordsmiljön.
En engångskopieringsåtgärd möjliggör dataflytt från en källa till ett mål bara en gång. Den gäller för data av valfri storlek och alla format som stöds. Med den schemalagda kopian kan du kopiera data vid en upprepning som du anger. Du kan använda omfattande inställningar (till exempel återförsök, timeout och aviseringar) för att konfigurera den schemalagda kopian.
Relaterat innehåll
Prova dessa handledningar som använder verktyget Kopiera data: