Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Dataflöden är tillgängliga i både Azure Data Factory pipelines och Azure Synapse Analytics pipelines. Den här artikeln gäller för mappning av dataflöden. Om du inte har använt transformeringar tidigare läser du introduktionsartikeln Transformera data med hjälp av mappning av dataflöden.
Tips
För motsvarande transformering (gruppera efter) i Dataflöde Gen2, se En guide till Dataflöde Gen2 för mappning av dataflödesanvändare.
Aggregeringstransformeringen definierar sammansättningar av kolumner i dina dataströmmar. Med Expression Builder kan du definiera olika typer av sammansättningar, till exempel SUM, MIN, MAX och COUNT grupperade efter befintliga eller beräknade kolumner.
Gruppera efter
Välj en befintlig kolumn eller skapa en ny beräknad kolumn att använda som gruppera efter-sats för att aggregera dina data. Om du vill använda en befintlig kolumn väljer du den i listrutan. Om du vill skapa en ny beräknad kolumn hovra över satsen och klicka på Beräknad kolumn. Då öppnas dataflödesuttrycksbyggaren. När du har skapat den beräknade kolumnen anger du namnet på utdatakolumnen under fältet Namn som . Om du vill lägga till ytterligare en grupp efter-sats hovra över en befintlig sats och klicka på plusikonen.

En GROUP BY-sats är valfri i en Aggregate-transformation.
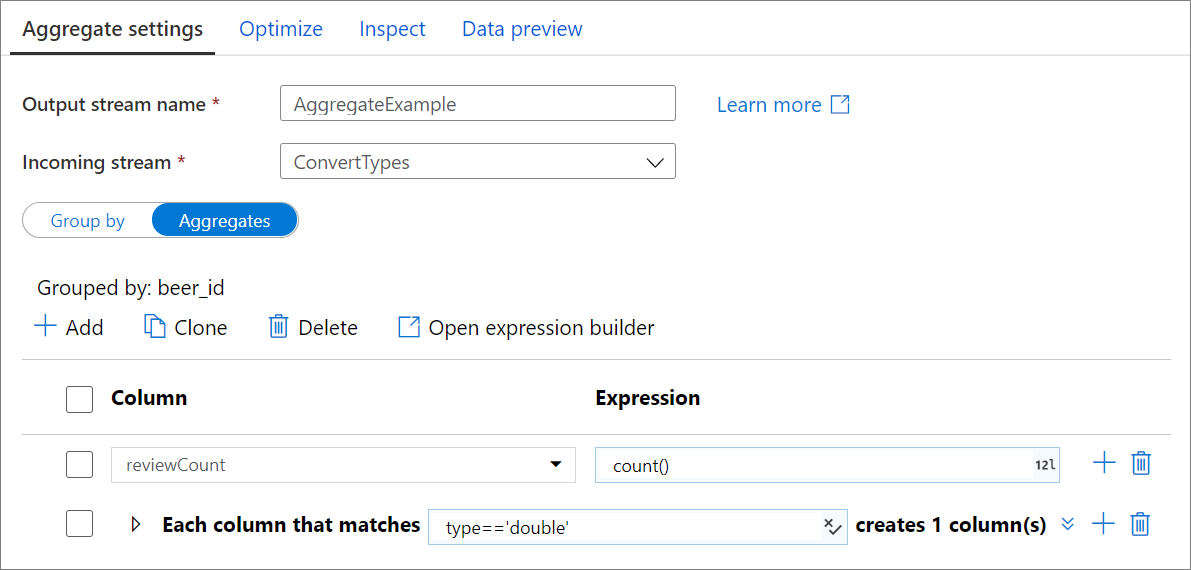
Sammanställa kolumner
Gå till fliken Aggregeringar för att skapa aggregeringsuttryck. Du kan antingen skriva över en befintlig kolumn med en aggregering eller skapa ett nytt fält med ett nytt namn. Sammansättningsuttrycket anges i den högra rutan bredvid kolumnnamnsväljaren. Om du vill redigera uttrycket klickar du på textrutan och öppnar uttrycksverktyget. Om du vill lägga till fler aggregeringskolumner klickar du på Lägg till ovanför kolumnlistan eller plusikonen bredvid en befintlig aggregeringskolumn. Välj antingen Lägg till kolumn eller Lägg till kolumnmönster. Varje sammansättningsuttryck måste innehålla minst en mängdfunktion.
Kommentar
I felsökningsläge kan uttrycksverktyget inte skapa dataförhandsgranskningar med aggregerade funktioner. Om du vill visa dataförhandsgranskningar för aggregerade transformeringar stänger du uttrycksverktyget och visar data via fliken Dataförhandsgranskning.
Kolumnmönster
Använd kolumnmönster för att tillämpa samma aggregering på en uppsättning kolumner. Det här är användbart om du vill spara många kolumner från indataschemat eftersom de tas bort som standard. Använd en heuristisk som till exempel first() för att bevara indatakolumner via aggregeringen.
Återansluta rader och kolumner
Aggregerade transformeringar liknar SQL-aggregerade urvalsfrågor. Kolumner som inte ingår i din GROUP BY-klausul eller aggregeringsfunktioner kommer inte att flöda igenom till utdata från din aggregerade transformation. Om du vill inkludera andra kolumner i dina aggregerade utdata gör du någon av följande metoder:
- Använd en mängdfunktion som
last()ellerfirst()för att inkludera den ytterligare kolumnen. - Återanslut kolumnerna till utdataströmmen med hjälp av självkopplingsmönstret.
Ta bort dubbelrader
En vanlig användning av aggregeringstransformeringen är att ta bort eller identifiera duplicerade poster i källdata. Den här processen kallas för deduplicering. Baserat på en uppsättning grupperingsnycklar, använd en vald heuristik för att avgöra vilken dubblettrad som ska behållas. Vanliga heuristiker är first(), last(), max()och min(). Använd kolumnmönster för att tillämpa regeln på varje kolumn utom för gruppen efter kolumner.
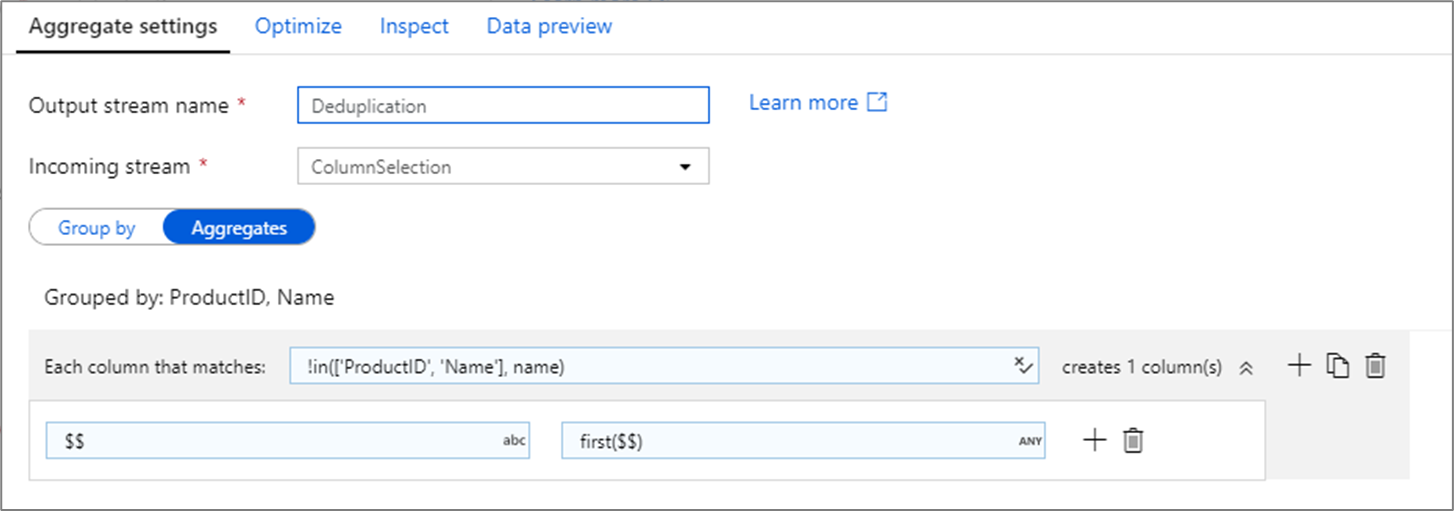
I exemplet ovan används kolumner ProductID och Name för gruppering. Om två rader har samma värden för dessa två kolumner betraktas de som dubbletter. I den här aggregeringstransformeringen behålls värdena för den första matchade raden och alla andra tas bort. Med kolumnmönstersyntaxen mappas alla kolumner vars namn inte är ProductID eller Name till deras befintliga kolumnnamn och får värdet från de första matchade raderna. Utdataschemat är detsamma som indataschemat.
För dataverifieringsscenarier count() kan funktionen användas för att räkna hur många dubbletter det finns.
Dataflödesskript
Syntax
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
Exempel
Exemplet nedan tar en inkommande ström MoviesYear och grupperar rader efter kolumn year. Omvandlingen skapar en aggregeringskolumn avgrating som utvärderas till genomsnittet av kolumnen Rating. Den här aggregerade omvandlingen heter AvgComedyRatingsByYear.
I användargränssnittet ser den här omvandlingen ut som bilden nedan:
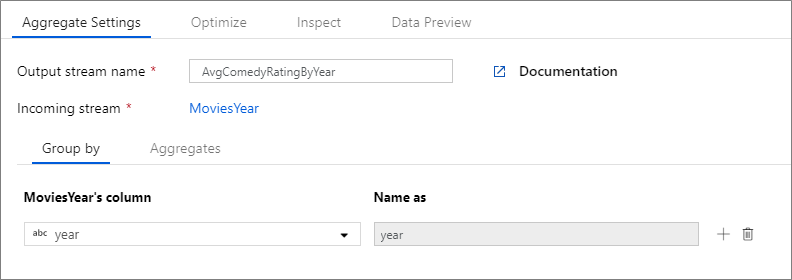
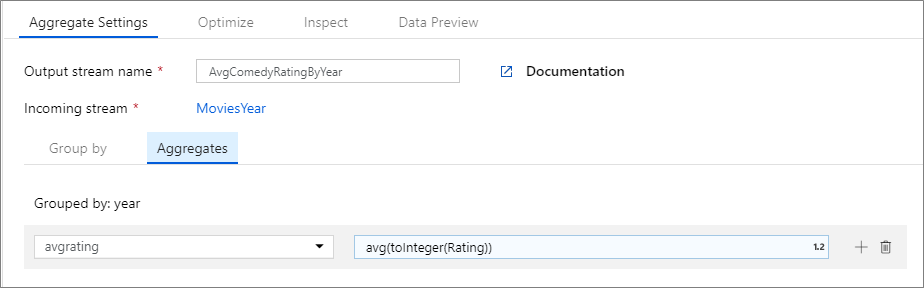
Dataflödesskriptet för den här omvandlingen finns i kodfragmentet nedan.
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
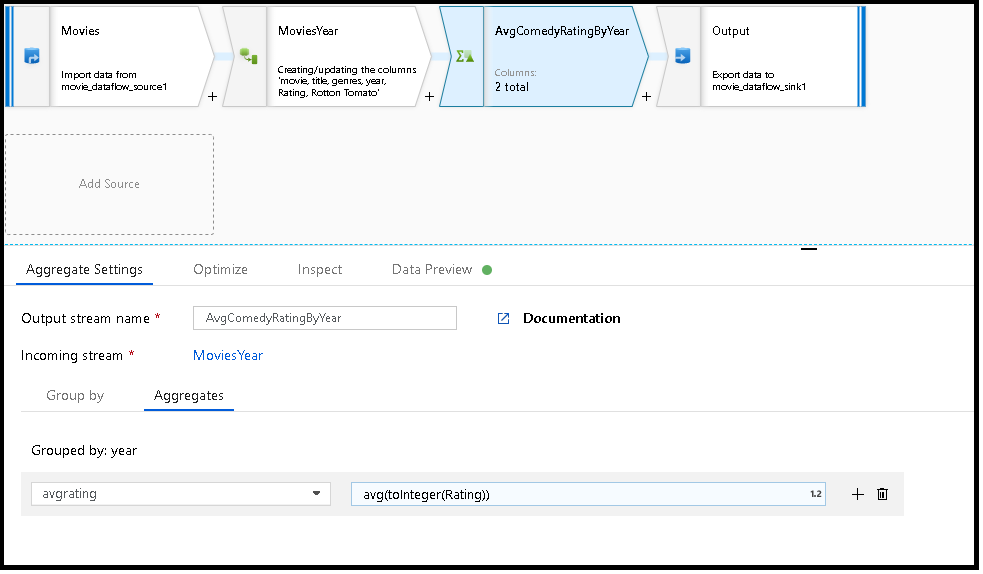
MoviesYear: Härledd kolumn som definierar kolumner för år och rubrik AvgComedyRatingByYear: Aggregerad transformering för genomsnittlig klassificering av komedier grupperade efter år avgrating: Namn på ny kolumn som skapas för att lagra det aggregerade värdet
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
Relaterat innehåll
- Definiera fönsterbaserad aggregering med hjälp av fönstertransformeringen