Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Med flera omvandlingar av mappningsdataflöden kan du referera till mallkolumner baserat på mönster i stället för hårdkodade kolumnnamn. Den här matchningen kallas kolumnmönster. Du kan definiera mönster för att matcha kolumner baserat på namn, datatyp, dataström, ursprung eller position i stället för att kräva exakta fältnamn. Det finns två scenarier där kolumnmönster är användbara:
- Om inkommande källfält ändras ofta, till exempel vid ändring av kolumner i textfiler eller NoSQL databaser. Det här scenariot kallas schemaavvikelse.
- Om du vill utföra en gemensam åtgärd för en stor grupp kolumner. Om du till exempel vill omvandla varje kolumn som har "total" i sitt kolumnnamn till en dubbel kolumn.
Kolumnmönster i deriverad kolumn och aggregering
Om du vill lägga till ett kolumnmönster i en härledd kolumn, aggregering eller fönstertransformering klickar du på Lägg till ovanför kolumnlistan eller plusikonen bredvid en befintlig härledd kolumn. Välj Lägg till kolumnmönster.
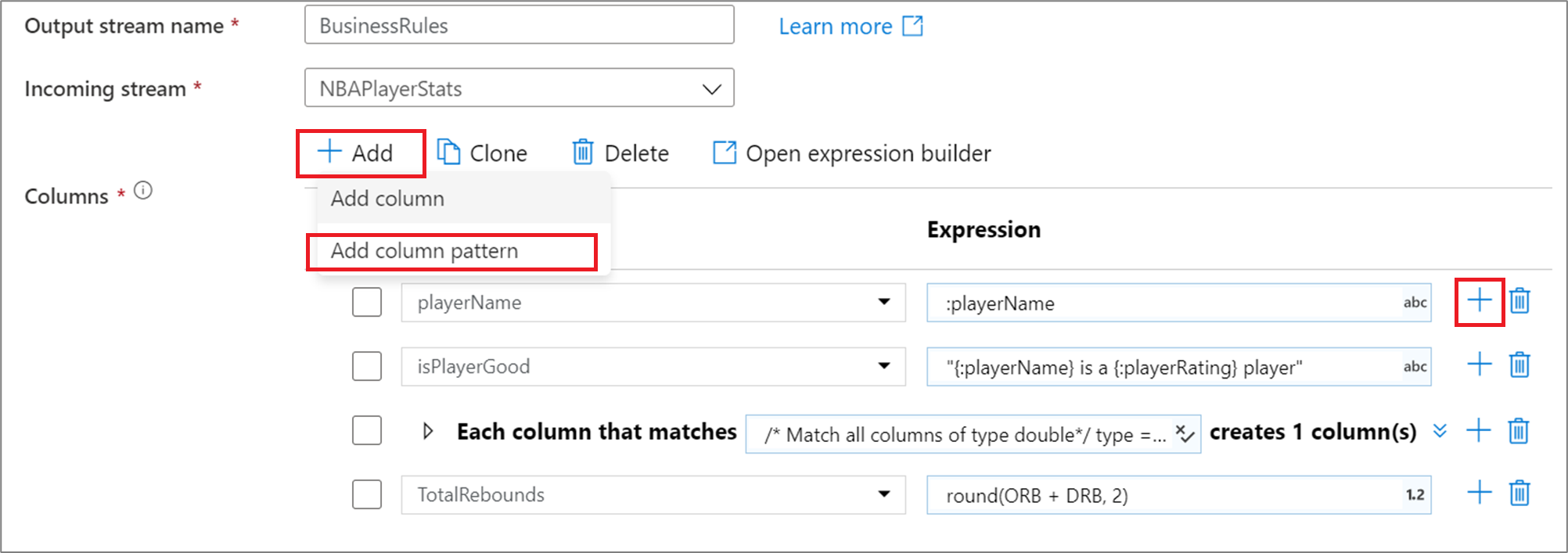
Använd uttrycksverktyget för att ange matchningsvillkoret. Skapa ett booleskt uttryck som matchar kolumner baserat på name, type, stream, origin och position. Mönstret kommer att påverka alla kolumner, driftade eller definierade, där villkoret returnerar sant.
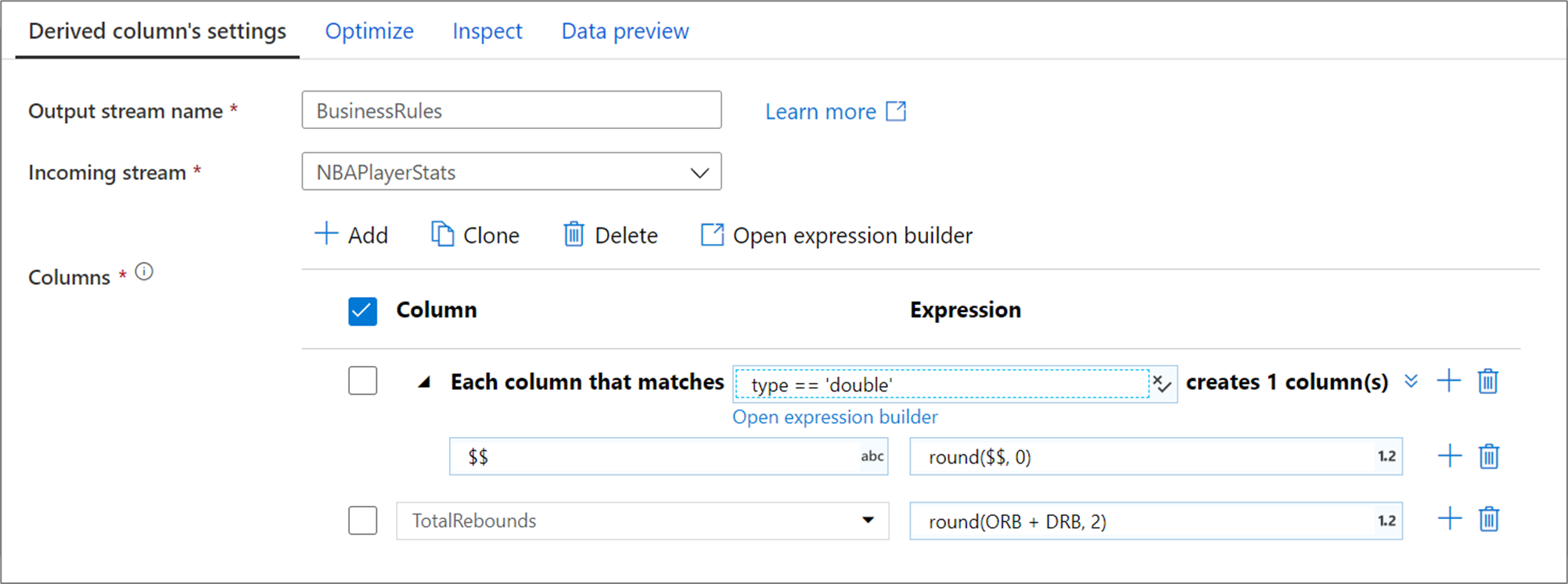
Kolumnmönstret ovan matchar varje kolumn av typen double och skapar en härledd kolumn per matchning. Genom att ange $$ som kolumnnamnsfält uppdateras varje matchad kolumn med samma namn. Värdet för varje kolumn är det befintliga värdet avrundat till två decimaler.
Om du vill kontrollera att matchningsvillkoret är korrekt kan du verifiera utdataschemat för definierade kolumner på fliken Inspektera eller hämta en ögonblicksbild av data på fliken Dataförhandsgranskning .
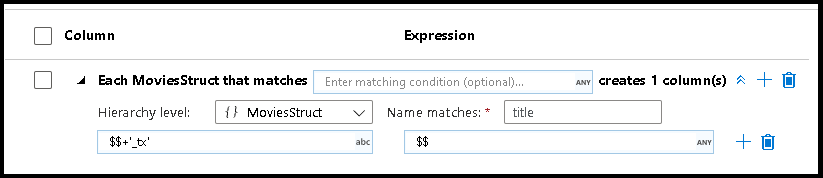
Hierarkisk mönstermatchning
Du kan även skapa mönstermatchning i komplexa hierarkiska strukturer. Expandera avsnittet Each MoviesStruct that matches där du uppmanas att ange varje hierarki i dataströmmen. Du kan sedan skapa matchande mönster för egenskaper i den valda hierarkin.
Utjämna strukturer
När ditt data har komplexa strukturer som matriser, hierarkiska strukturer och hashmappar kan du använda transformeringen Platta ut-transformation för att expandera matriser och avnormalisera ditt data. För strukturer och kartor använder du den härledda kolumntransformeringen med kolumnmönster för att bilda en utplattad relationstabell från hierarkierna. Du kan använda de kolumnmönster som skulle se ut som det här exemplet, vilket förenklar geografihierarkin till ett relationstabellformulär:
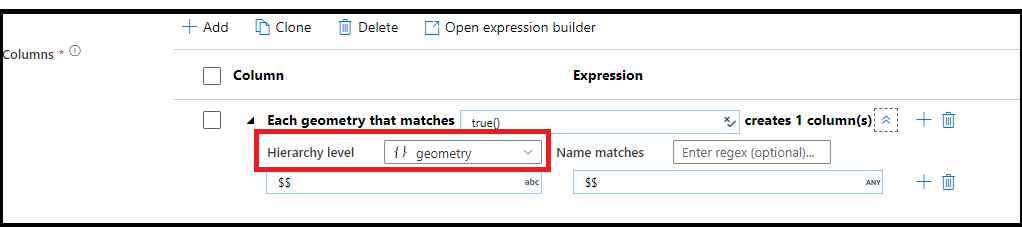
Regelbaserad mappning i select och sink
När du mappar kolumner i källan och väljer transformeringar kan du lägga till antingen fast mappning eller regelbaserade mappningar. Matcha baserat på kolumnerna name, type, stream, originoch position . Du kan ha valfri kombination av fasta och regelbaserade mappningar. Som standard kommer alla projektioner med större än 50 kolumner som standard att vara en regelbaserad mappning som matchar varje kolumn och matar ut det inmatade namnet.
Om du vill lägga till en regelbaserad mappning klickar du på Lägg till mappning och väljer Regelbaserad mappning.

Varje regelbaserad mappning kräver två indata: villkoret som matchas mot och vad varje mappad kolumn ska namnges. Båda värdena matas in via uttrycksverktyget. I den vänstra uttrycksrutan anger du ditt booleska matchningsvillkor. I den högra uttrycksrutan anger du vilken matchningskolumn som ska mappas till.

Använd $$ syntax för att referera till indatanamnet för en matchad kolumn. Anta att en användare vill matcha alla strängkolumner vars namn är kortare än sex tecken med hjälp av bilden ovan som exempel. Om en inkommande kolumn heter testbyter uttrycket $$ + '_short' namn på kolumnen test_short. Om det är den enda mappningen som finns kommer alla kolumner som inte uppfyller villkoret att tas bort från utdata.
Mönster matchar både glidande och definierade kolumner. Om du vill se vilka definierade kolumner som mappas av en regel klickar du på glasögonikonen bredvid regeln. Verifiera dina utdata med hjälp av förhandsversionen av data.
Regex-mappning
Om du klickar på sparrikonen nedåt kan du ange ett regex-mappningsvillkor. Ett regex-mappningsvillkor matchar alla kolumnnamn som matchar det angivna regex-villkoret. Detta kan användas i kombination med standardregelbaserade mappningar.

Exemplet ovan matchar på reguljärt uttryck (regex) (r) eller vilket kolumnnamn som helst som innehåller ett litet r. På samma sätt som standardregelbaserad mappning ändras alla matchade kolumner enligt villkoret på höger sida med $$-syntaxen.
Regelbaserade hierarkier
Om din definierade projektion har en hierarki kan du använda regelbaserad mappning för att mappa hierarkiernas underkolumner. Ange ett matchande villkor och den komplexa kolumn vars underkolumner du vill mappa. Varje matchad underkolumn matas ut med hjälp av regeln "Namn som" som anges till höger.
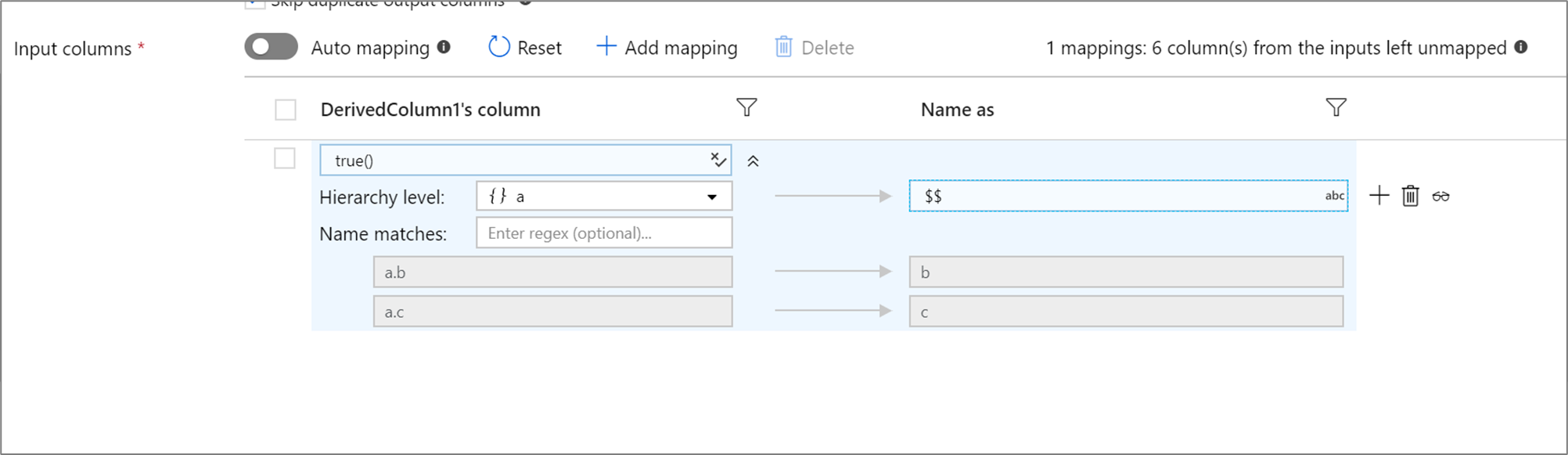
Exemplet ovan matchar alla underkolumner i den komplexa kolumnen a.
a innehåller två underkolumner b och c. Utdataschemat innehåller två kolumner b och c, eftersom villkoret "Namn som" är $$.
Mönstermatchningsuttrycksvärden
-
$$översätts till namnet eller värdet för varje matchning vid körtid. Tänk på$$som likvärdigt medthis -
$0översätts till den aktuella kolumnnamnsmatchningen vid körning för skalärtyper. För hierarkiska typer$0representerar den aktuella matchade kolumnhierarkisökvägen. -
namerepresenterar namnet på varje inkommande kolumn -
typerepresenterar datatypen för varje inkommande kolumn. Listan över datatyper i dataflödestypsystemet finns här. -
streamrepresenterar namnet som är associerat med varje ström eller transformering i ditt flöde -
positionär ordningspositionen för kolumner i ditt dataflöde -
originär omvandlingen där en kolumn har sitt ursprung eller senast uppdaterades
Relaterat innehåll
- Läs mer om uttrycksspråket för mappning av dataflöden för datatransformeringar
- Använd kolumnmönster i mottagartransformeringen och välj transformering med regelbaserad mappning