Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här artikeln beskrivs de utlösare för lagringshändelser som du kan skapa i dina Azure Data Factory- eller Azure Synapse Analytics-pipelines.
Händelsedriven arkitektur är ett vanligt dataintegreringsmönster som omfattar produktion, identifiering, förbrukning och reaktion på händelser. Scenarier för dataintegrering kräver ofta att kunder utlöser pipelines som utlöses från händelser på ett Azure Storage-konto, till exempel ankomst eller borttagning av en fil i Azure Blob Storage-kontot. Data Factory- och Azure Synapse Analytics-pipelines integreras internt med Azure Event Grid, vilket gör att du kan utlösa pipelines på sådana händelser.
Överväganden för lagringshändelseutlösare
Tänk på följande när du använder utlösare för lagringshändelser:
- Integreringen som beskrivs i den här artikeln beror på Azure Event Grid. Kontrollera att din prenumeration är registrerad hos Event Grid-resursprovidern. Mer information finns i Resursproviders och typer. Du måste kunna utföra åtgärden
Microsoft.EventGrid/eventSubscriptions/. Den här åtgärden är en del av denEventGrid EventSubscription Contributorinbyggda rollen. - Om du använder den här funktionen i Azure Synapse Analytics kontrollerar du att du även registrerar din prenumeration hos Data Factory-resursprovidern. Annars får du ett meddelande om att "det gick inte att skapa en händelseprenumeration".
- Om Blob Storage-kontot finns bakom en privat slutpunkt och blockerar åtkomst till offentliga nätverk måste du konfigurera nätverksregler för att tillåta kommunikation från Blob Storage till Event Grid. Du kan antingen bevilja lagringsåtkomst till betrodda Azure-tjänster, till exempel Event Grid, följa lagringsdokumentationen eller konfigurera privata slutpunkter för Event Grid som mappas till ett virtuellt nätverksadressutrymme enligt Event Grid-dokumentationen.
- Utlösaren för lagringshändelsen stöder för närvarande endast Azure Data Lake Storage Gen2 och allmänna ändamål version 2-lagringskonton. Om du arbetar med SFTP-lagringshändelser (Secure File Transfer Protocol) måste du också ange SFTP-data-API:et under filtreringsavsnittet. På grund av en Event Grid-begränsning stöder Data Factory endast högst 500 utlösare för lagringshändelser per lagringskonto.
- Om du vill skapa en ny utlösare för lagringshändelser eller ändra en befintlig måste det Azure-konto som du använder för att logga in på tjänsten och publicera utlösaren för lagringshändelsen ha lämplig rollbaserad åtkomstkontroll (Azure RBAC) behörighet för lagringskontot. Inga andra behörigheter krävs. Serviceprincipal för Azure Data Factory och Azure Synapse Analytics behöver inte särskild behörighet för lagringskontot eller Event Grid. Mer information om åtkomstkontroll finns i avsnittet Rollbaserad åtkomstkontroll .
- Om du har tillämpat ett Azure Resource Manager-lås på ditt lagringskonto kan det påverka blobutlösarens möjlighet att skapa eller ta bort blobar. Ett
ReadOnlylås förhindrar både skapande och borttagning, medan ettDoNotDeletelås förhindrar borttagning. Se till att du tar hänsyn till dessa begränsningar för att undvika problem med dina utlösare. - Vi rekommenderar inte utlösare för filinmatning som en utlösande mekanism från dataflödesmottagare. Dataflöden utför ett antal aktiviteter för filnamnbyte och omblandning av partitionsfiler i målmappen, vilket oavsiktligt kan utlösa en händelse för filinkomst före den fullständiga bearbetningen av dina data.
Skapa en utlösare med användargränssnittet
Det här avsnittet visar hur du skapar en utlösare för lagringshändelser i användargränssnittet för Azure Data Factory och Azure Synapse Analytics pipeline.
Växla till fliken Redigera i Data Factory eller fliken Integrera i Azure Synapse Analytics.
På menyn väljer du Utlösare och sedan Ny/Redigera.
På sidan Lägg till utlösare väljer du Välj utlösare och sedan + Ny.
Välj utlösartypen Lagringshändelser.
Välj ditt lagringskonto från listrutan med Azure-prenumerationer eller välj manuellt med dess resurs-ID för lagringskontot. Välj den container där du vill att händelserna ska inträffa. Val av container krävs, men om du väljer alla containrar kan det leda till ett stort antal händelser.
Med
Blob path begins withegenskaperna ochBlob path ends withkan du ange de containrar, mappar och blobnamn som du vill ta emot händelser för. Utlösaren för lagringshändelsen kräver att minst en av dessa egenskaper definieras. Du kan använda olika mönster för bådeBlob path begins withochBlob path ends withegenskaper, som du ser i exemplen senare i den här artikeln.-
Blob path begins with: Sökvägen för blob måste börja med en mapp. Giltiga värden inkluderar2018/och2018/april/shoes.csv. Det går inte att välja det här fältet om en container inte är markerad. -
Blob path ends with: Blobsökvägen måste avslutas med ett filnamn eller filnamnstillägg. Giltiga värden inkluderarshoes.csvoch.csv. Container- och mappnamn, när de anges, måste avgränsas med ett/blobs/segment. En container med namnetorderskan till exempel ha värdet/orders/blobs/2018/april/shoes.csv. Om du vill ange en mapp i en container utelämnar du inledande/tecken. Till exempelapril/shoes.csvutlöser en händelse på en fil med namnetshoes.csvi en mapp som heteraprili valfri container.
Observera att
Blob path begins withochBlob path ends withär den enda mönstermatchning som tillåts i en utlösare för lagringshändelser. Andra typer av jokerteckenmatchning stöds inte för triggertypen.-
Välj om utlösaren svarar på en Blob skapad händelse, en Blob borttagen händelse, eller båda. På den angivna lagringsplatsen utlöser varje händelse de Data Factory- och Azure Synapse Analytics-pipelines som är associerade med utlösaren.
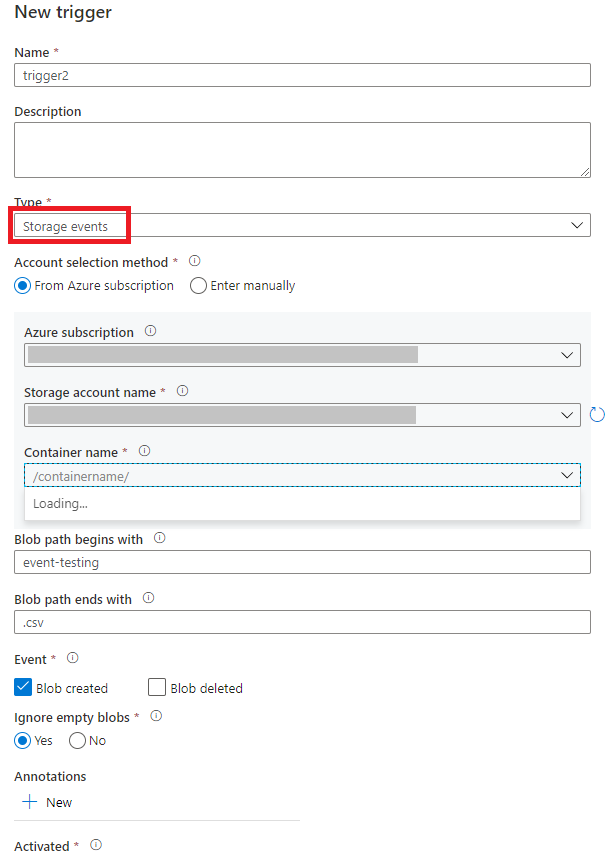
Välj om utlösaren ska ignorera blobar med noll byte.
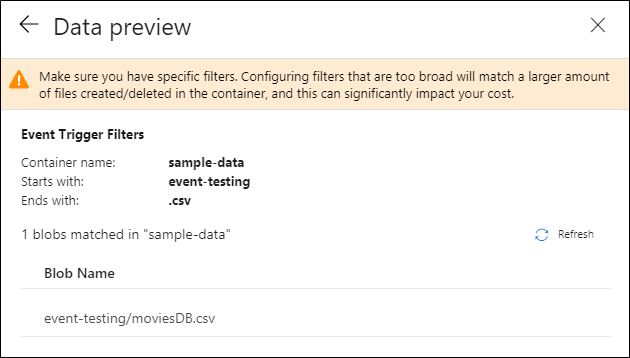
När du har konfigurerat utlösaren väljer du Nästa: Förhandsgranska data. Den här vyn visar de befintliga blobar som matchas av utlösarkonfigurationen för lagringshändelser. Kontrollera att du har specifika filter. Att konfigurera filter som är för breda kan matcha ett stort antal filer som har skapats eller tagits bort och kan påverka kostnaden avsevärt. När filtervillkoren har verifierats väljer du Slutför.
Om du vill koppla en pipeline till den här utlösaren går du till pipelinearbetsytan och väljer Utlösare>Ny/redigera. När sidofönstret visas väljer du listrutan Välj utlösare och väljer den utlösare som du skapade. Välj Nästa: Dataförhandsgranskning för att bekräfta att konfigurationen är korrekt. Välj sedan Nästa för att verifiera att dataförhandsgranskningen är korrekt.
Om din pipeline har parametrar kan du ange dem i sidofönstret Utlösarkörningsparametrar . Lagringshändelseutlösaren fångar upp mappsökvägen och filnamnet för bloben i egenskaperna
@triggerBody().folderPathoch@triggerBody().fileName. Om du vill använda värdena för dessa egenskaper i en pipeline måste du mappa egenskaperna till pipelineparametrar. När du har mappat egenskaperna till parametrar kan du komma åt de värden som samlas in av utlösaren via@pipeline().parameters.parameterNameuttrycket i hela pipelinen. En detaljerad förklaring finns i Referensutlösarmetadata i pipelines.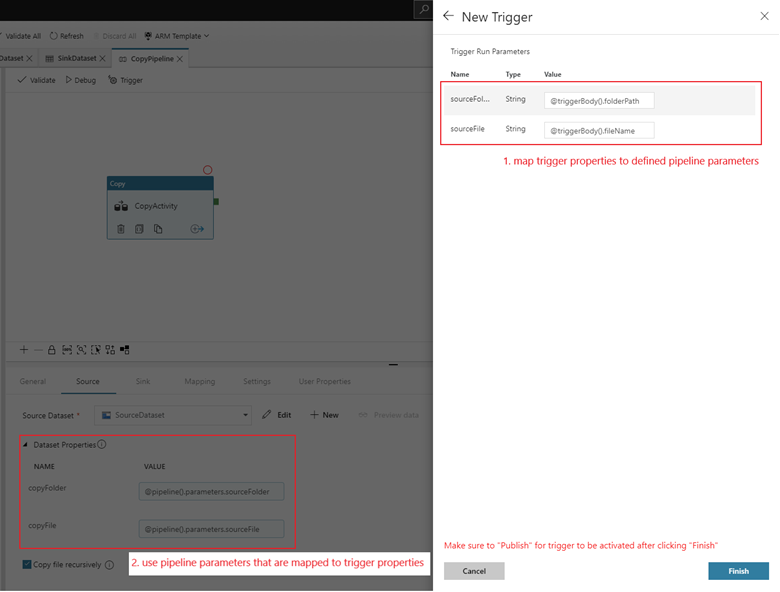
I föregående exempel konfigureras utlösaren att triggas när en sökväg som slutar på .csv skapas i mappen händelsetestning i containern sample-data. Egenskaperna
folderPathochfileNameavbildar platsen för den nya bloben. När MoviesDB.csv till exempel läggs till i sökvägen sample-data/event-testing,@triggerBody().folderPathhar värdetsample-data/event-testingoch@triggerBody().fileNamehar värdetmoviesDB.csv. Dessa värden mappas i exemplet till pipelineparametrarnasourceFolderochsourceFile, som kan användas i hela pipelinen som@pipeline().parameters.sourceFolder@pipeline().parameters.sourceFilerespektive .När du är klar väljer du Slutför.


JSON-schema
Följande tabell innehåller en översikt över de schemaelement som är relaterade till utlösare för lagringshändelser.
| JSON-element | beskrivning | Typ | Tillåtna värden | Obligatoriskt |
|---|---|---|---|---|
| omfattning | Azure Resource Manager-resurs-ID för lagringskontot. | Sträng | Azure Resource Manager ID | Ja. |
| händelser | Den typ av händelser som gör att utlösaren utlöses. | Samling |
Microsoft.Storage.BlobCreated, Microsoft.Storage.BlobDeleted |
Ja, alla kombinationer av dessa värden. |
blobPathBeginsWith |
Blobsökvägen måste börja med det angivna mönstret för att utlösaren ska aktiveras. Till exempel, utlöses endast utlösaren för blobbar i mappen /records/blobs/december/ under containern december. |
Sträng | Ange ett värde för minst en av dessa egenskaper: blobPathBeginsWith eller blobPathEndsWith. |
|
blobPathEndsWith |
Blobsökvägen måste sluta med det mönster som anges för att utlösaren ska utlösas. Till exempel aktiveras bara utlösaren för blobar med namnet december/boxes.csv i en boxes mapp. |
Sträng | Ange ett värde för minst en av dessa egenskaper: blobPathBeginsWith eller blobPathEndsWith. |
|
ignoreEmptyBlobs |
Om blobbar med noll byte utlöser en pipelinekörning eller inte. Som standard är detta inställt på true. |
Boolesk | sant eller falskt | Nej. |
Exempel på utlösare för lagringshändelser
Det här avsnittet innehåller exempel på inställningar för utlösare för lagringshändelser.
Viktigt!
Du måste inkludera segmentet /blobs/ av sökvägen, som visas i följande exempel, när du specificerar container och mapp, container och fil, eller container, mapp och fil. För blobPathBeginsWithlägger användargränssnittet automatiskt till /blobs/ mellan mappen och containernamnet i utlösarens JSON.
| Egendom | Exempel | beskrivning |
|---|---|---|
Blob path begins with |
/containername/ |
Tar emot händelser för varje blob i behållaren. |
Blob path begins with |
/containername/blobs/foldername/ |
Tar emot händelser för alla blobar i containern containername och foldername mappen. |
Blob path begins with |
/containername/blobs/foldername/subfoldername/ |
Du kan också hänvisa till en undermapp. |
Blob path begins with |
/containername/blobs/foldername/file.txt |
Tar emot händelser för en blob med namnet file.txt i foldername mappen under containern containername . |
Blob path ends with |
file.txt |
Tar emot händelser för en blob med namnet file.txt i valfri sökväg. |
Blob path ends with |
/containername/blobs/file.txt |
Tar emot händelser för en blob med namnet file.txt under containern containername. |
Blob path ends with |
foldername/file.txt |
Tar emot händelser för en blob med namnet file.txt i foldername mappen under valfri container. |
Rollbaserad åtkomstkontroll
Data Factory- och Azure Synapse Analytics-pipelines använder rollbaserad åtkomstkontroll i Azure (Azure RBAC) för att säkerställa att obehörig åtkomst att lyssna på, prenumerera på uppdateringar från och utlösa pipelines som är länkade till blobhändelser är strängt förbjudna.
- För att kunna skapa en ny utlösare för lagringshändelser eller uppdatera en befintlig måste Azure-kontot som loggas in på tjänsten ha lämplig åtkomst till det relevanta lagringskontot. Annars misslyckas åtgärden med meddelandet "Åtkomst nekad".
- Data Factory och Azure Synapse Analytics behöver ingen särskild behörighet till din Event Grid-instans och du behöver inte tilldela särskild RBAC-behörighet till tjänstens huvudnamn för Data Factory eller Azure Synapse Analytics för denna operation.
Någon av följande RBAC-inställningar fungerar för utlösare för lagringshändelser:
- Ägarroll till lagringskontot
- Deltagarroll för lagringskontot
-
Microsoft.EventGrid/EventSubscriptions/Writebehörighet till lagringskontot/subscriptions/####/resourceGroups/####/providers/Microsoft.Storage/storageAccounts/storageAccountName
Specifikt:
- När du skapar i datafabriken (till exempel i utvecklingsmiljön) måste det Azure-konto som loggas in ha föregående behörighet.
- När du publicerar genom kontinuerlig integrering och kontinuerlig leverans måste det konto som används för att publicera Azure Resource Manager-mallen i test- eller produktionsfabriken ha föregående behörighet.
För att förstå hur tjänsten levererar de två löftena ska vi ta ett steg tillbaka och titta bakom kulisserna. Här är de övergripande arbetsflödena för integrering mellan Data Factory/Azure Synapse Analytics, Storage och Event Grid.
Skapa en ny utlösare för lagringshändelser
Det här arbetsflödet på hög nivå beskriver hur Data Factory interagerar med Event Grid för att skapa en utlösare för lagringshändelser. Dataflödet är detsamma i Azure Synapse Analytics, där Azure Synapse Analytics-pipelines tar rollen som datafabrik i följande diagram.
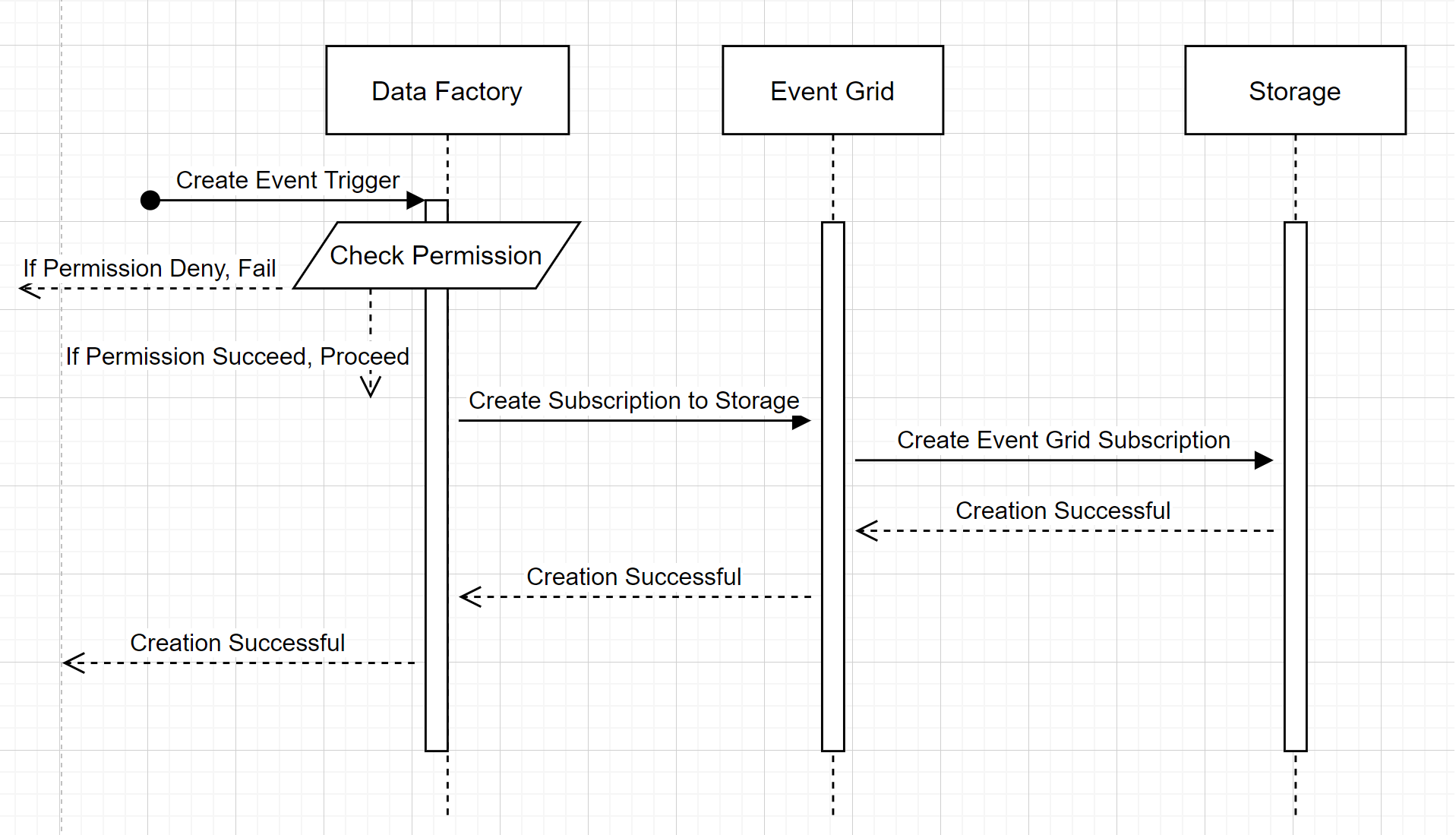
Två märkbara noteringar från arbetsflöden:
- Data Factory och Azure Synapse Analytics kontaktar inte lagringskontot direkt. Begäran om att skapa en prenumeration vidarebefordras i stället och bearbetas av Event Grid. Tjänsten behöver ingen behörighet för att komma åt lagringskontot för det här steget.
- Åtkomstkontroll och behörighetskontroll sker inom tjänsten. Innan tjänsten skickar en begäran om att prenumerera på en lagringshändelse kontrollerar den användarens behörighet. Mer specifikt kontrollerar den om Det Azure-konto som är inloggat och försöker skapa utlösaren för lagringshändelsen har lämplig åtkomst till det relevanta lagringskontot. Om behörighetskontrollen misslyckas misslyckas även skapandet av utlösaren.
Körning av pipeline utlöst av lagringshändelse
Det här arbetsflödet på hög nivå beskriver hur pipelines för utlösare för lagringshändelser körs via Event Grid. För Azure Synapse Analytics är dataflödet detsamma, där Azure Synapse Analytics-pipelines tar rollen som Data Factory i följande diagram.
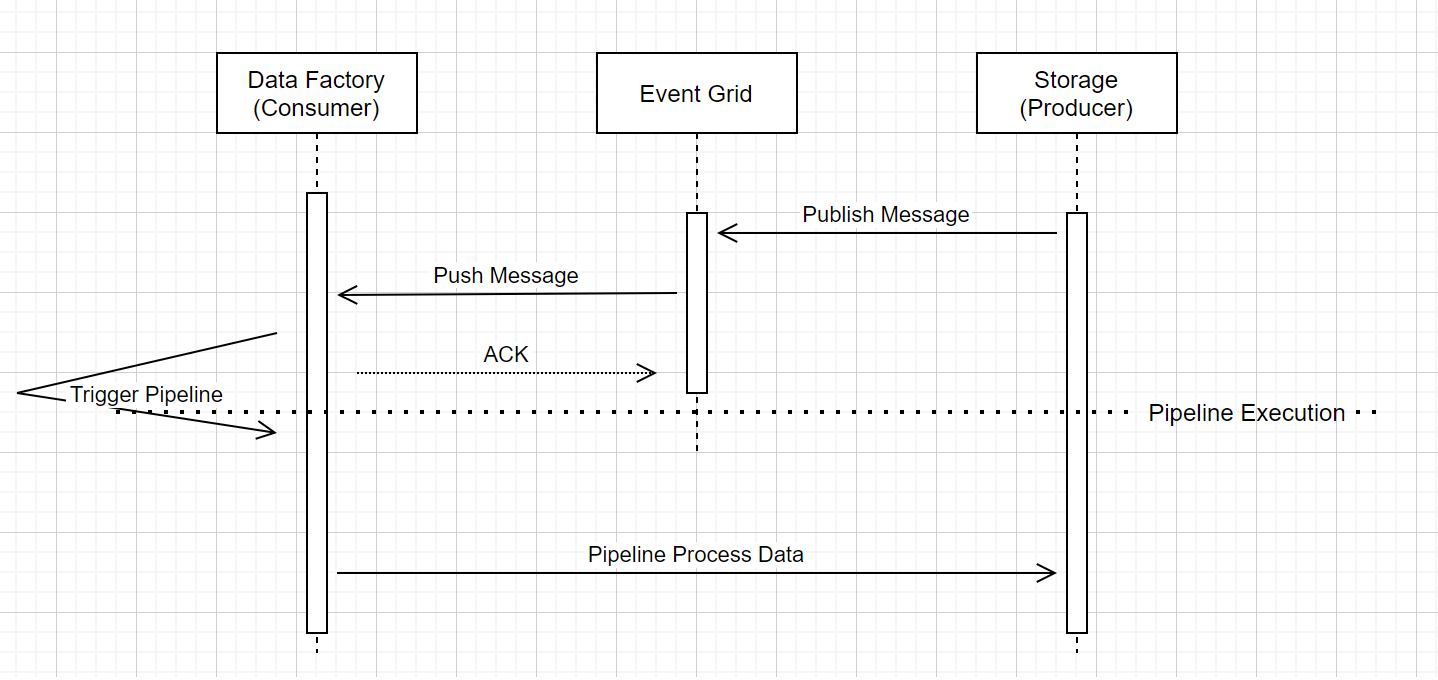
Tre märkbara anvisningar i arbetsflödet är relaterade till event-triggande pipelines inom tjänsten:
Event Grid använder en push-modell som vidarebefordrar meddelandet så snart som möjligt när lagringen släpper meddelandet i systemet. Den här metoden skiljer sig från ett meddelandesystem, till exempel Kafka, där ett Pull-system används.
Händelseutlösaren fungerar som en aktiv lyssnare till det inkommande meddelandet och utlöser den associerade pipelinen korrekt.
Själva lagringshändelseutlösaren tar ingen direkt kontakt med lagringskontot.
- Om du har en Kopieringsaktivitet eller en annan aktivitet i pipelinen för att bearbeta datan i lagringskontot, tar tjänsten direkt kontakt med lagringskontot genom att använda de autentiseringsuppgifter som är lagrade i den länkade tjänsten. Kontrollera att den länkade tjänsten har konfigurerats på rätt sätt.
- Om du inte refererar till lagringskontot i pipelinen behöver du inte ge tjänsten behörighet att komma åt lagringskontot.
Relaterat innehåll
- Mer information om utlösare finns i Pipelinekörning och utlösare.
- För att referera till utlösarmetadata i en pipeline, se Referera till utlösarmetadata i pipelinekörningar.