Migrera normaliserat databasschema från Azure SQL Database till en avnormaliserad Azure Cosmos DB-container
Den här guiden beskriver hur du tar ett befintligt normaliserat databasschema i Azure SQL Database och konverterar det till ett avnormaliserat Schema i Azure Cosmos DB för inläsning till Azure Cosmos DB.
SQL-scheman modelleras vanligtvis med tredje normal form, vilket resulterar i normaliserade scheman som ger höga dataintegritetsnivåer och färre duplicerade datavärden. Frågor kan koppla samman entiteter mellan tabeller för läsning. Azure Cosmos DB är optimerat för supersnabba transaktioner och frågor i en samling eller container via avnormaliserade scheman med data som är fristående i ett dokument.
Med Azure Data Factory skapar vi en pipeline som använder en enda mappning Dataflöde för att läsa från två normaliserade Azure SQL Database-tabeller som innehåller primära och externa nycklar som entitetsrelation. ADF ansluter dessa tabeller till en enda ström med hjälp av Spark-motorn för dataflöde, samlar in anslutna rader i matriser och skapar enskilda rensade dokument för infogning i en ny Azure Cosmos DB-container.
Den här guiden skapar en ny container i farten med namnet "orders" som använder tabellerna SalesOrderHeader och från sql Server Adventure Works-exempeldatabasenSalesOrderDetail. Dessa tabeller representerar försäljningstransaktioner som är kopplade till SalesOrderID. Varje unik detaljpost har en egen primärnyckel för SalesOrderDetailID. Relationen mellan rubrik och detaljer är 1:M. Vi ansluter till SalesOrderID ADF och distribuerar sedan varje relaterad detaljpost till en matris med namnet "detail".
Den representativa SQL-frågan för den här guiden är:
SELECT
o.SalesOrderID,
o.OrderDate,
o.Status,
o.ShipDate,
o.SalesOrderNumber,
o.ShipMethod,
o.SubTotal,
(select SalesOrderDetailID, UnitPrice, OrderQty from SalesLT.SalesOrderDetail od where od.SalesOrderID = o.SalesOrderID for json auto) as OrderDetails
FROM SalesLT.SalesOrderHeader o;
Den resulterande Azure Cosmos DB-containern bäddar in den inre frågan i ett enda dokument och ser ut så här:

Skapa en pipeline
Välj +Ny pipeline för att skapa en ny pipeline.
Lägga till en dataflödesaktivitet
I dataflödesaktiviteten väljer du Nytt mappningsdataflöde.
Vi skapar det här dataflödesdiagrammet nedan
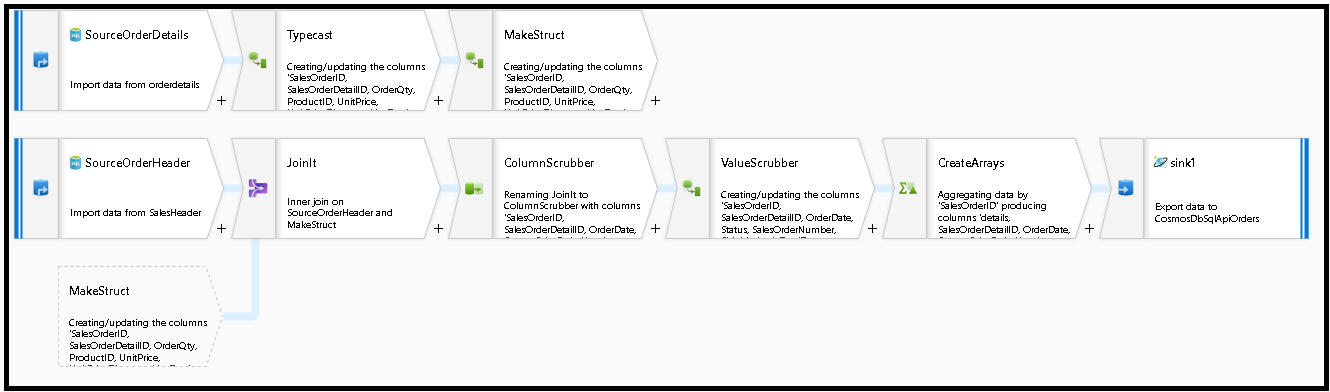
Definiera källan för "SourceOrderDetails". För datauppsättning skapar du en ny Azure SQL Database-datauppsättning som pekar på
SalesOrderDetailtabellen.Definiera källan för "SourceOrderHeader". För datauppsättning skapar du en ny Azure SQL Database-datauppsättning som pekar på
SalesOrderHeadertabellen.Lägg till en transformering av härledd kolumn efter "SourceOrderDetails" på den översta källan. Anropa den nya omvandlingen "TypeCast". Vi måste avrunda kolumnen och omvandla den
UnitPricetill en dubbel datatyp för Azure Cosmos DB. Ange formeln till:toDouble(round(UnitPrice,2)).Lägg till en annan härledd kolumn och kalla den "MakeStruct". Här skapar vi en hierarkisk struktur för att lagra värdena från informationstabellen. Kom ihåg att information är en
M:1relation till huvudet. Namnge den nya strukturenorderdetailsstructoch skapa hierarkin på det här sättet och ange varje underkolumn till det inkommande kolumnnamnet: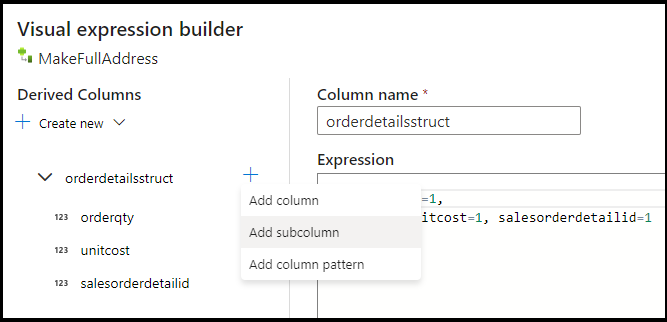
Nu går vi till källan för försäljningshuvudet. Lägg till en Join-transformering. Välj "MakeStruct" till höger. Låt den vara inställd på inre koppling och välj
SalesOrderIDför båda sidor av kopplingsvillkoret.Klicka på fliken Dataförhandsgranskning i den nya koppling som du har lagt till så att du kan se dina resultat fram till den här punkten. Du bör se alla rubrikrader som är kopplade till de detaljerade raderna. Det här är resultatet av att kopplingen skapas från
SalesOrderID. Därefter kombinerar vi informationen från de gemensamma raderna till informations struct och aggregerar de gemensamma raderna.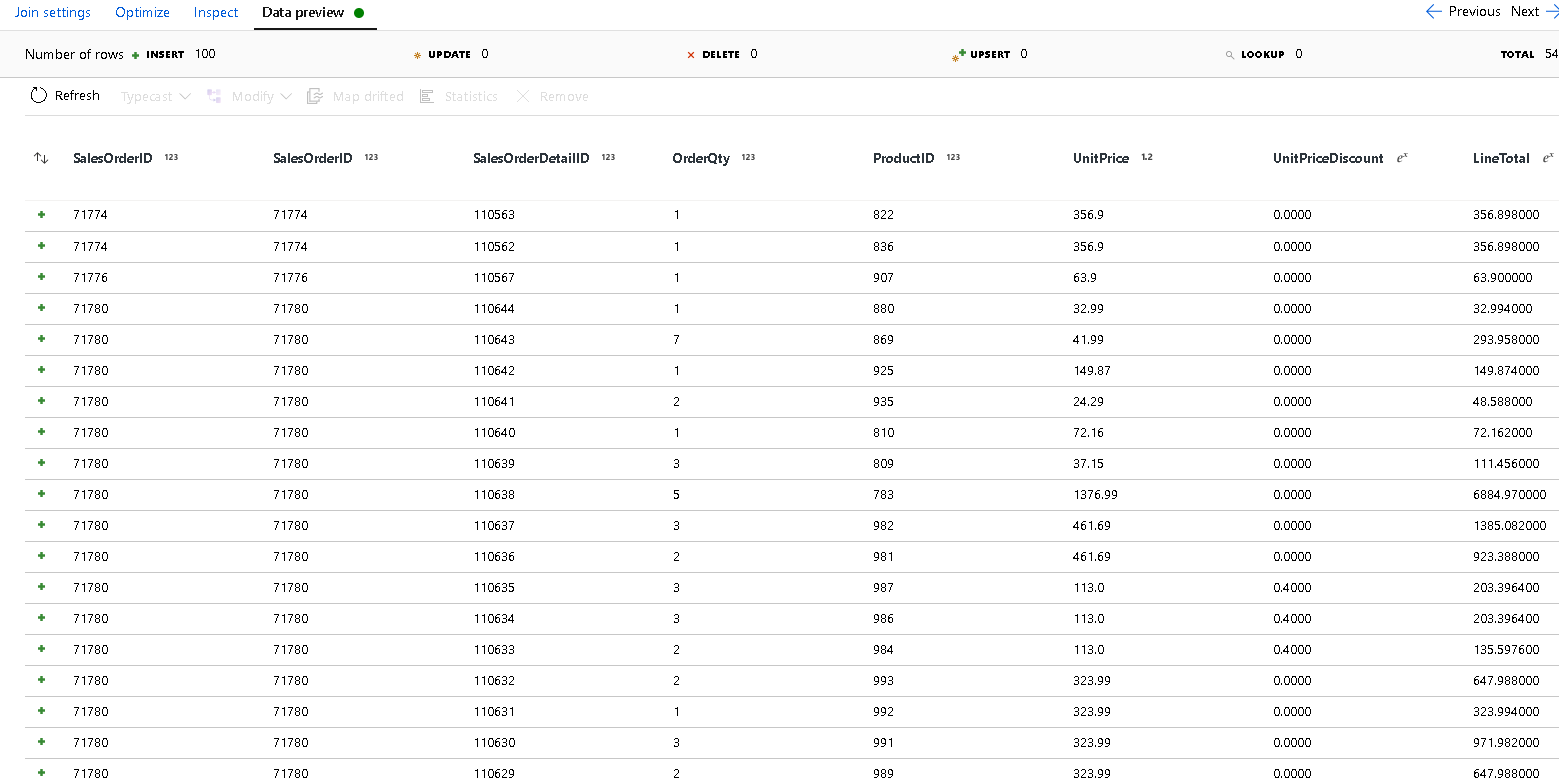
Innan vi kan skapa matriserna för att avnormalisera dessa rader måste vi först ta bort oönskade kolumner och se till att datavärdena matchar Azure Cosmos DB-datatyper.
Lägg till en Välj transformering härnäst och ställ in fältmappningen så här:
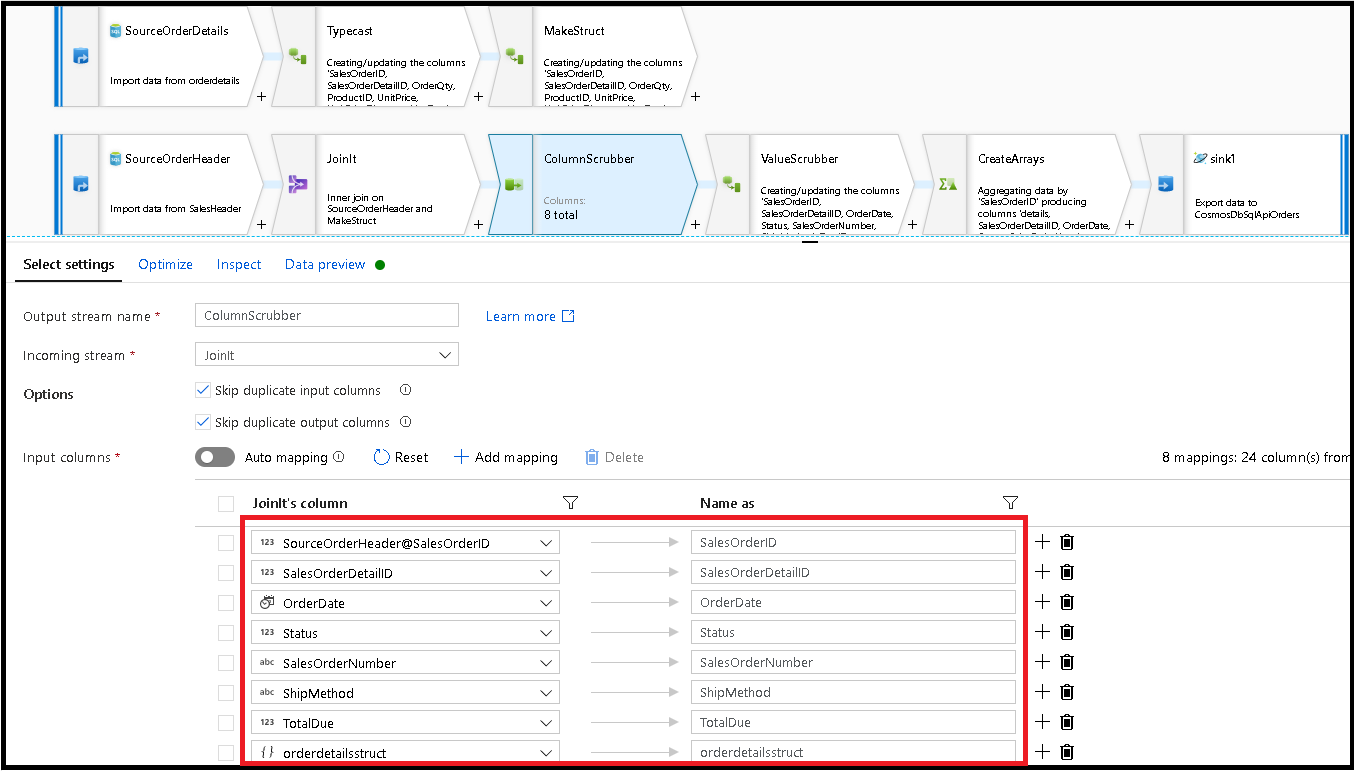
Nu ska vi återigen kasta en valutakolumn, den här gången
TotalDue. Precis som vi gjorde ovan i steg 7 anger du formeln till:toDouble(round(TotalDue,2)).Här avnormaliserar vi raderna genom att gruppera efter den gemensamma nyckeln
SalesOrderID. Lägg till en aggregeringstransformering och ange gruppen efter tillSalesOrderID.I sammansättningsformeln lägger du till en ny kolumn med namnet "details" och använder den här formeln för att samla in värdena i den struktur som vi skapade tidigare med namnet
orderdetailsstruct:collect(orderdetailsstruct).Den aggregerade omvandlingen matar bara ut kolumner som ingår i aggregerade eller grupperade efter formler. Därför måste vi även inkludera kolumnerna från försäljningshuvudet. Det gör du genom att lägga till ett kolumnmönster i samma aggregerade transformering. Det här mönstret innehåller alla andra kolumner i utdata, exklusive kolumnerna nedan (OrderQty, UnitPrice, SalesOrderID):
instr(name,'OrderQty')==0&&instr(name,'UnitPrice')==0&&instr(name,'SalesOrderID')==0
Använd syntaxen "this" ($$) i de andra egenskaperna så att vi behåller samma kolumnnamn och använder
first()funktionen som aggregering. Detta talar om för ADF att behålla det första matchande värdet som hittas: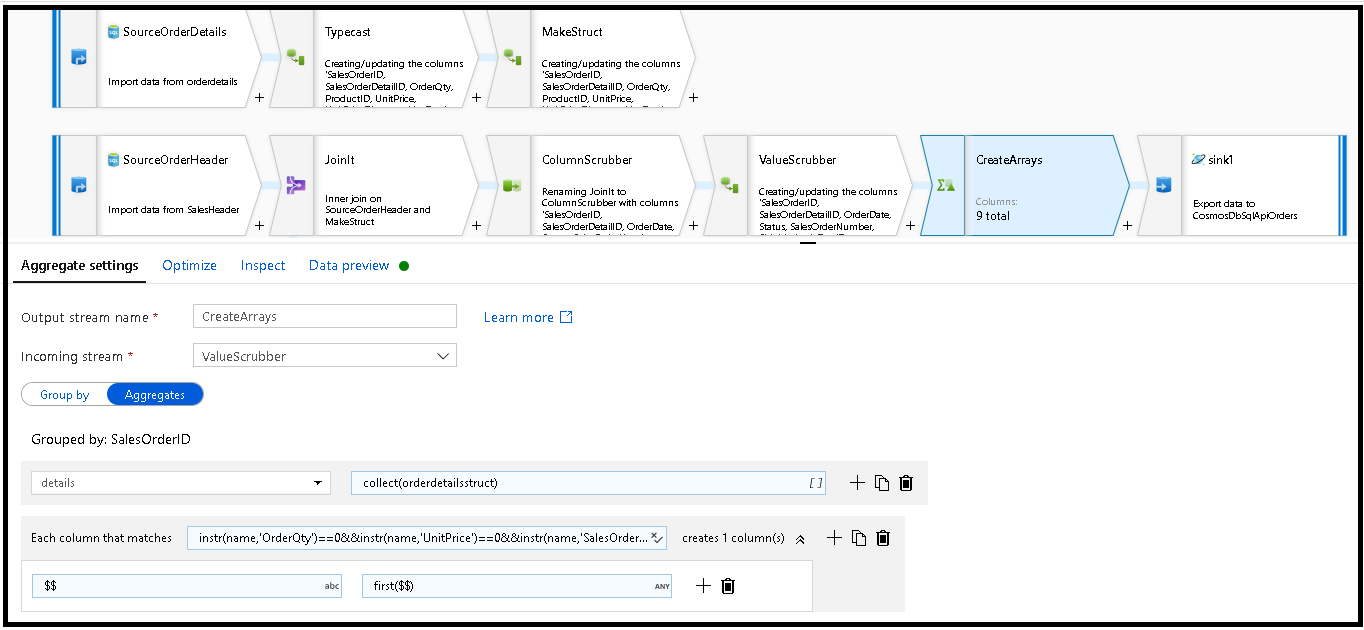
Vi är redo att slutföra migreringsflödet genom att lägga till en mottagartransformering. Klicka på "ny" bredvid datauppsättningen och lägg till en Azure Cosmos DB-datauppsättning som pekar på din Azure Cosmos DB-databas. För samlingen kallar vi den "beställningar" och den har inget schema och inga dokument eftersom den kommer att skapas i farten.
I sink Inställningar, partitionsnyckel till
/SalesOrderIDoch insamlingsåtgärd för att "återskapa". Kontrollera att mappningsfliken ser ut så här: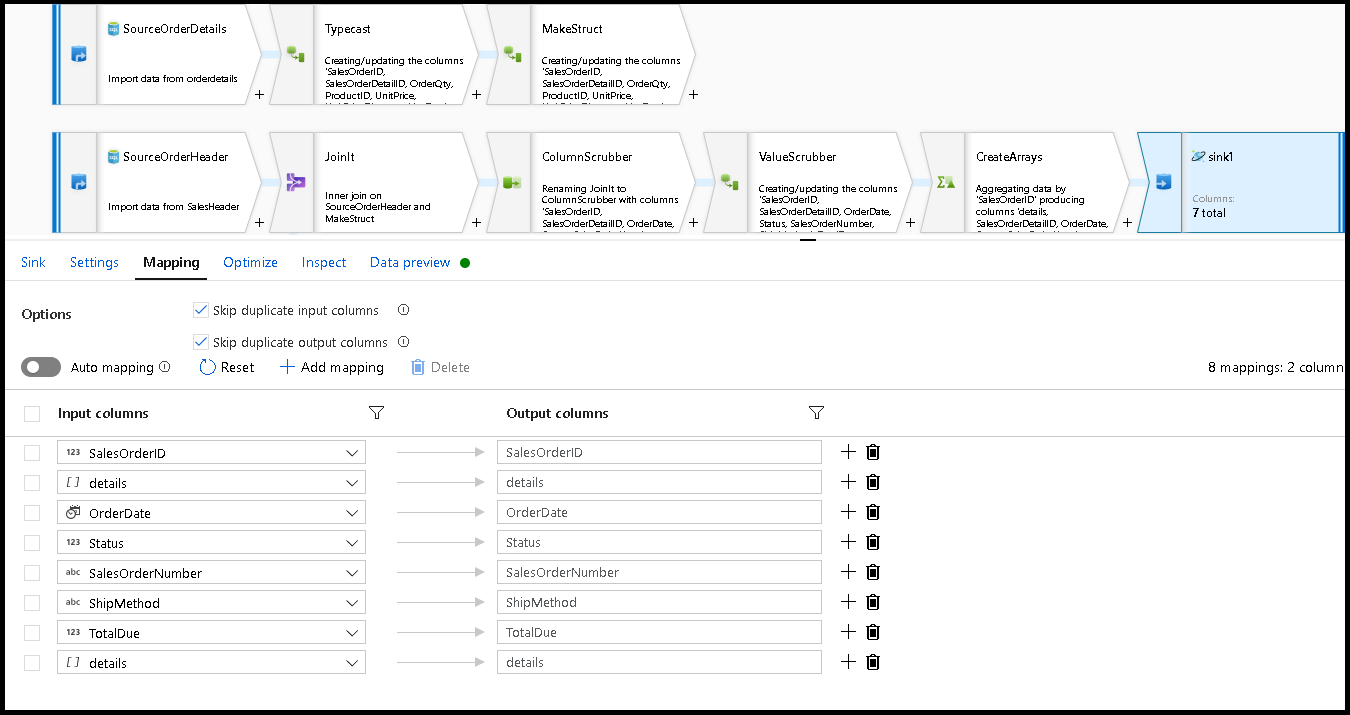
Klicka på förhandsversionen av data för att se till att de här 32 raderna är inställda på att infogas som nya dokument i den nya containern:
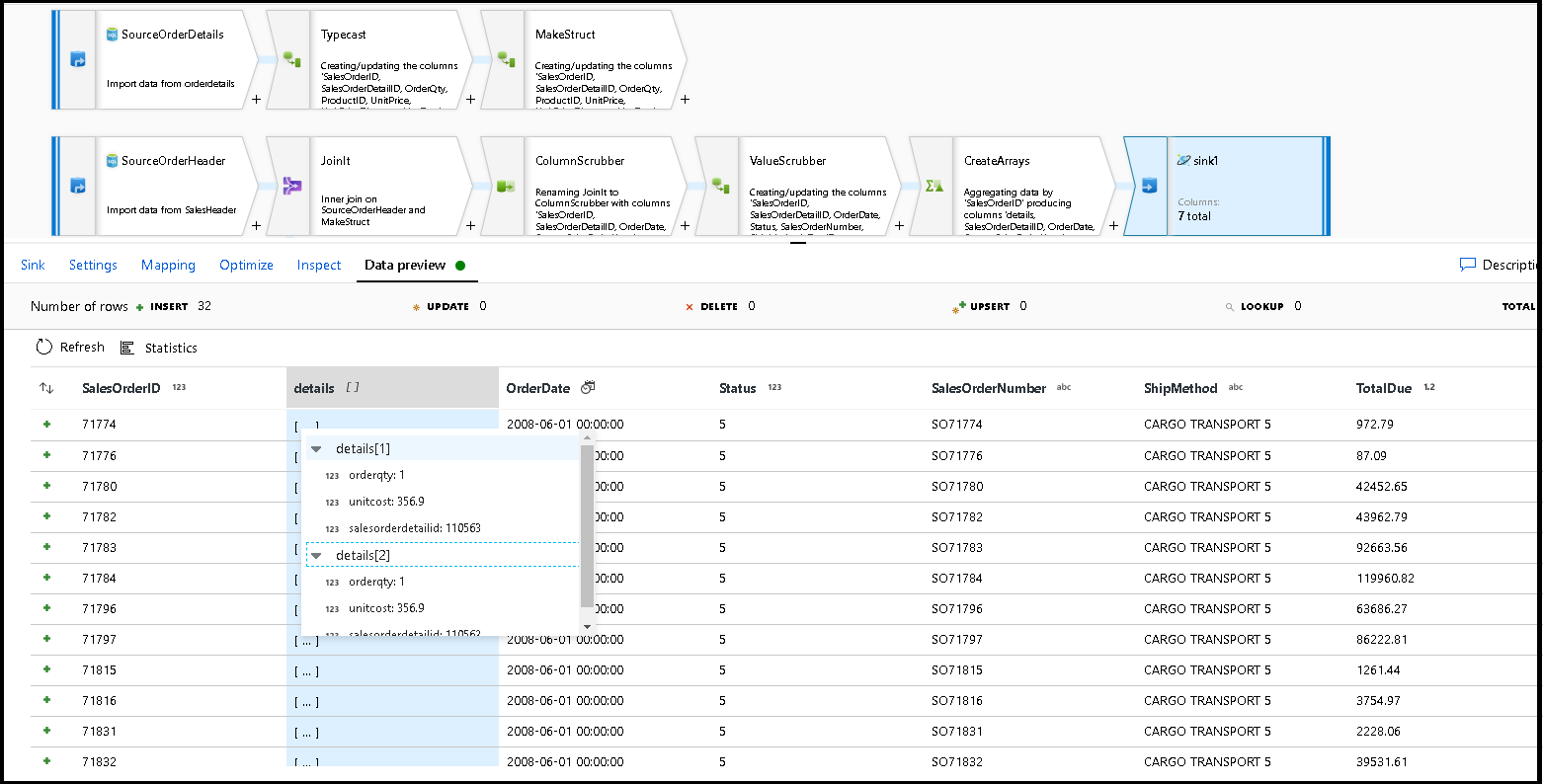
Om allt ser bra ut är du nu redo att skapa en ny pipeline, lägga till den här dataflödesaktiviteten i pipelinen och köra den. Du kan köra från felsökning eller en utlöst körning. Efter några minuter bör du ha en ny avnormaliserad container med order som kallas "beställningar" i din Azure Cosmos DB-databas.
Relaterat innehåll
- Skapa resten av dataflödeslogik med hjälp av omvandlingar av dataflöden.
- Ladda ned den färdiga pipelinemallen för den här självstudien och importera mallen till din fabrik.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för