Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Azure Databricks Python-aktiviteten i en pipeline kör en Python-fil i Azure Databricks kluster. Den här artikeln bygger på artikeln om datatransformeringsaktiviteter , som visar en allmän översikt över datatransformering och de omvandlingsaktiviteter som stöds. Azure Databricks är en hanterad plattform för att köra Apache Spark.
Om du vill se en introduktion och demonstration av den här funktionen rekommenderar vi följande videoklipp (11 minuter):
Lägga till en Python-aktivitet för Azure Databricks i en pipeline med användargränssnittet
Utför följande steg för att använda en Python aktivitet för Azure Databricks i en pipeline:
Sök efter Python i fönstret Pipelineaktiviteter, och dra en Python-aktivitet till pipelinearbetsytan.
Välj den nya Python aktiviteten på arbetsytan om den inte redan är markerad.
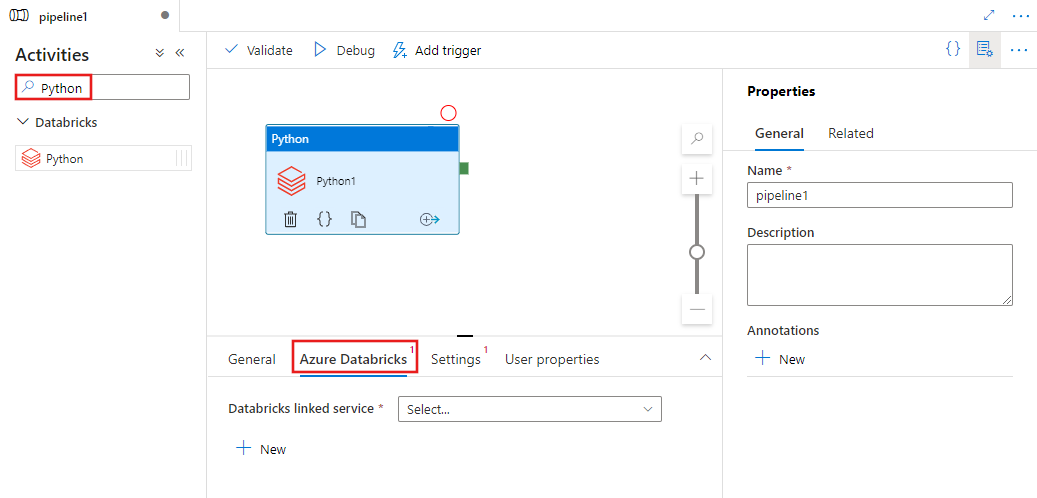
Välj fliken Azure Databricks för att välja eller skapa en ny Azure Databricks länkad tjänst som ska köra Python aktiviteten.
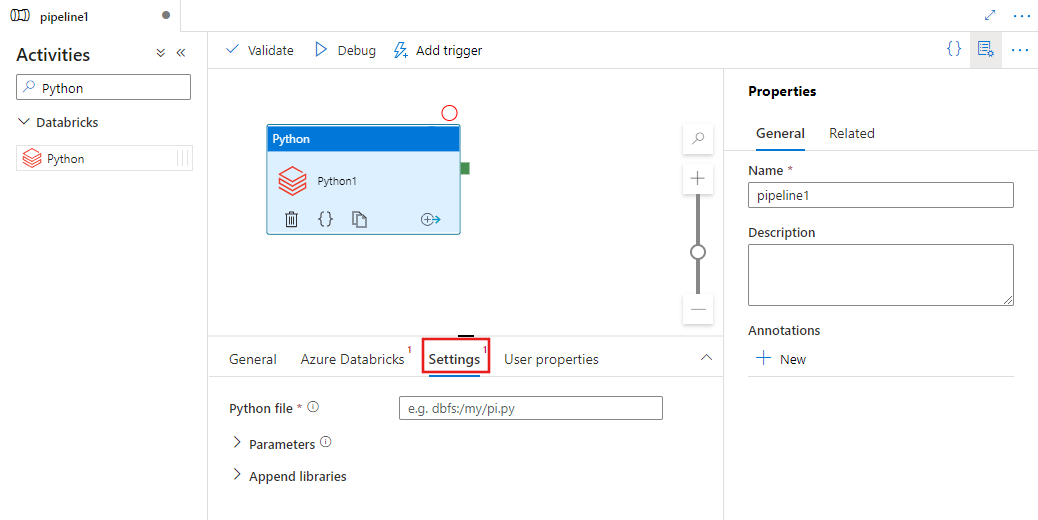
Välj fliken Settings och ange sökvägen inom Azure Databricks till en Python fil som ska köras, valfria parametrar som ska skickas och eventuella ytterligare bibliotek som ska installeras i klustret för att köra jobbet.
Databricks Python aktivitetsdefinition
Här är JSON-exempeldefinitionen för en Databricks-Python-aktivitet:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksSparkPython",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"pythonFile": "dbfs:/docs/pi.py",
"parameters": [
"10"
],
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
}
]
}
}
}
Databricks Python aktivitetsegenskaper
I följande tabell beskrivs de JSON-egenskaper som används i JSON-definitionen:
| Egenskap | Beskrivning | Obligatoriskt |
|---|---|---|
| namn | Namnet på aktiviteten i pipelinen. | Ja |
| beskrivning | Text som beskriver vad aktiviteten gör. | Nej |
| typ | För Databricks Python Activity är aktivitetstypen DatabricksSparkPython. | Ja |
| länkatTjänstnamn | Namnet på den länkade Databricks-tjänst som Python-aktiviteten körs på. Mer information om den här länkade tjänsten finns i artikeln Compute linked services (Beräkningslänkade tjänster ). | Ja |
| pythonFile | URI:n för den Python fil som ska köras. Endast DBFS-sökvägar stöds. | Ja |
| parametrar | Kommandoradsparametrar som skickas till filen Python. Det här är en matris med strängar. | Nej |
| bibliotek | En lista över bibliotek som ska installeras i klustret som ska köra jobbet. Det kan vara en matris med <sträng, objekt> | Nej |
Bibliotek som stöds för databricks-aktiviteter
I databricks-aktivitetsdefinitionen ovan anger du följande bibliotekstyper: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Mer information finns i Databricks-dokumentationen för bibliotekstyper.
Ladda upp ett bibliotek i Databricks
Du kan använda arbetsytans användargränssnitt:
Om du vill hämta dbfs-sökvägen för biblioteket som lagts till med hjälp av användargränssnittet kan du använda Databricks CLI.
Vanligtvis lagras Jar-biblioteken under dbfs:/FileStore/jars när användargränssnittet används. Du kan lista alla via CLI: databricks fs ls dbfs:/FileStore/job-jars
Eller så kan du använda Databricks CLI:
Använda Databricks CLI (installationssteg)
Om du till exempel vill kopiera en JAR-fil till dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar