Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här självstudien använder du Azure Portal för att skapa en datafabrik. Sedan använder du verktyget Kopiera data för att skapa en pipeline som endast kopierar nya och ändrade filer stegvis, från Azure Blob Storage till Azure Blob Storage. Den använder LastModifiedDate för att avgöra vilka filer som ska kopieras.
När du har slutfört stegen här genomsöker Azure Data Factory alla filer i källarkivet, tillämpar filfiltret efter LastModifiedDateoch kopierar endast filer som är nya eller har uppdaterats sedan förra gången till målarkivet. Observera att om Data Factory söker igenom ett stort antal filer bör du fortfarande förvänta dig långa varaktigheter. Filgenomsökning är tidskrävande, även när mängden data som kopieras minskar.
Kommentar
Om du inte har använt datafabriken tidigare kan du läsa Introduktion till Azure Data Factory.
I den här självstudien får du utföra följande uppgifter:
- Skapa en datafabrik.
- Använd verktyget Kopiera data för att skapa en pipeline.
- Övervaka pipelinen och aktivitetskörningarna.
Förutsättningar
- Azure-prenumeration: Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar.
- Azure Storage-konto: Använd Blob Storage för käll- och mottagardatalager. Om du inte har något Azure Storage-konto följer du anvisningarna i Skapa ett lagringskonto.
Skapa två containrar i Blob Storage
Förbered bloblagringen för självstudien genom att utföra följande steg:
Skapa en container med namnet source. Du kan använda olika verktyg för att utföra den här uppgiften, till exempel Azure Storage Explorer.
Skapa en container med namnet destination.
Skapa en datafabrik
Välj Skapa en resurs>Analys>Datafabrik på den översta menyn:
I fönstret Ny datafabrik, under Namn anger du ADFTutorialDataFactory.
Namnet på datafabriken måste vara globalt unikt. Du kan få det här felmeddelandet:
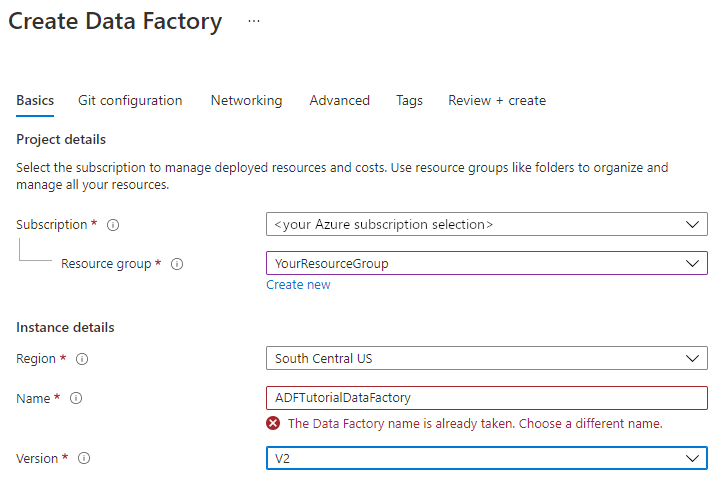
Ange ett annat namn för datafabriken om du får ett felmeddelande om namnvärdet. Använd till exempel namnet dittnamnADFTutorialDataFactory. Se artikeln Data Factory – namnregler för namnregler för Data Factory-artefakter.
Under Prenumeration väljer du den Azure-prenumeration där du ska skapa den nya datafabriken.
Under Resursgrupp gör du något av följande:
Välj Använd befintlig och välj sedan en befintlig resursgrupp i listan.
Välj Skapa ny och ange sedan ett namn för resursgruppen.
Mer information om resursgrupper finns i Använda resursgrupper för att hantera Azure-resurser.
Under Version väljer du V2.
Under Plats väljer du en plats för datafabriken. Endast platser som stöds visas i listan. Datalager (till exempel Azure Storage och Azure SQL Database) och beräkningar (till exempel Azure HDInsight) som din datafabrik använder kan finnas på andra platser och regioner.
Välj Skapa.
När datafabriken har skapats visas startsidan för datafabriken.
Om du vill öppna Användargränssnittet för Azure Data Factory på en separat flik väljer du Öppna på panelen Öppna Azure Data Factory Studio:

Använd verktyget Kopiera data för att skapa en pipeline
På startsidan för Azure Data Factory väljer du panelen Mata in för att öppna verktyget Kopiera data:
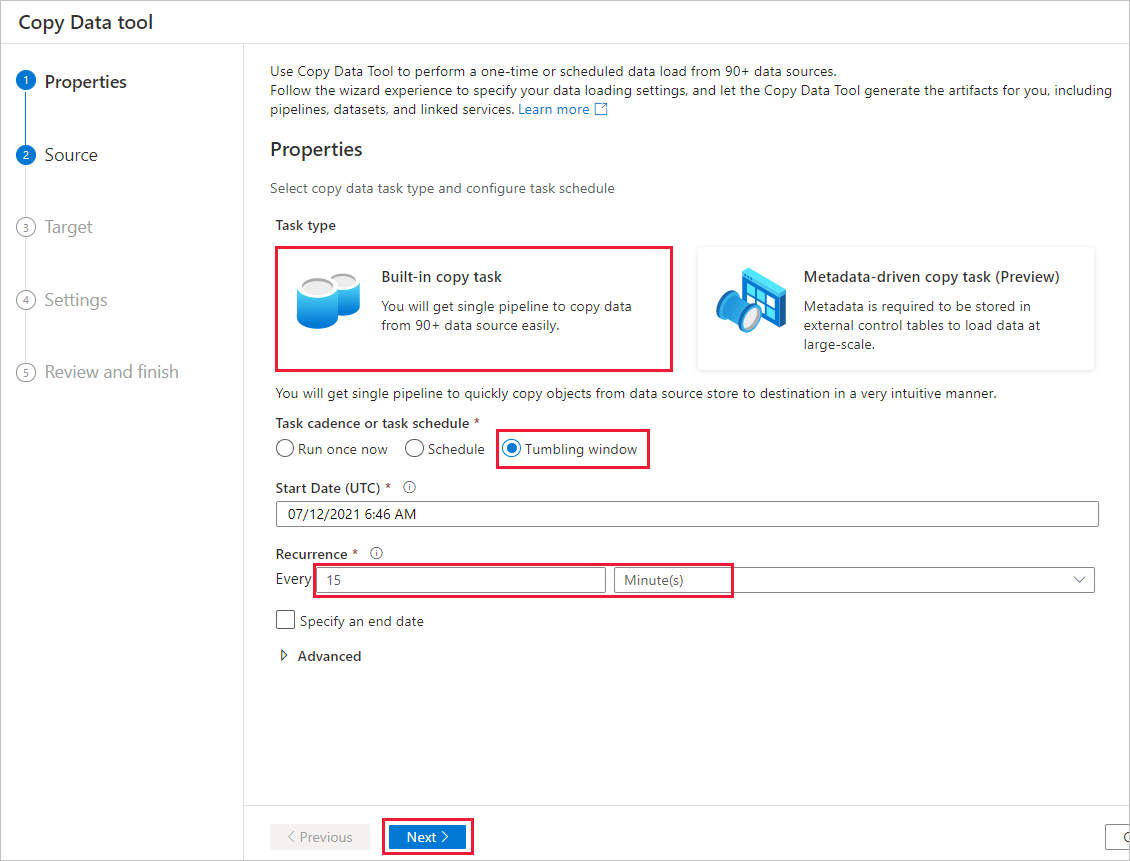
På sidan Egenskaper gör du följande:
Under Aktivitetstyp väljer du Inbyggd kopieringsaktivitet.
Under Aktivitetstakt eller aktivitetsschema väljer du Rullande fönster.
Under Upprepning anger du 15 minuter.
Välj Nästa.
Slutför följande steg på sidan Källdatalager :
Välj + Ny anslutning för att lägga till en anslutning.
Välj Azure Blob Storage i galleriet och välj sedan Fortsätt:

På sidan Ny anslutning (Azure Blob Storage) väljer du din Azure-prenumeration i azure-prenumerationslistan och ditt lagringskonto i listan Lagringskontonamn. Testa anslutningen och välj sedan Skapa.
Välj den nyligen skapade anslutningen i anslutningsblocket.
I avsnittet Fil eller mapp väljer du Bläddra och väljer källmappenoch sedan OK.
Under Beteende för filinläsning väljer du Inkrementell belastning: LastModifiedDate och väljer Binär kopia.
Välj Nästa.
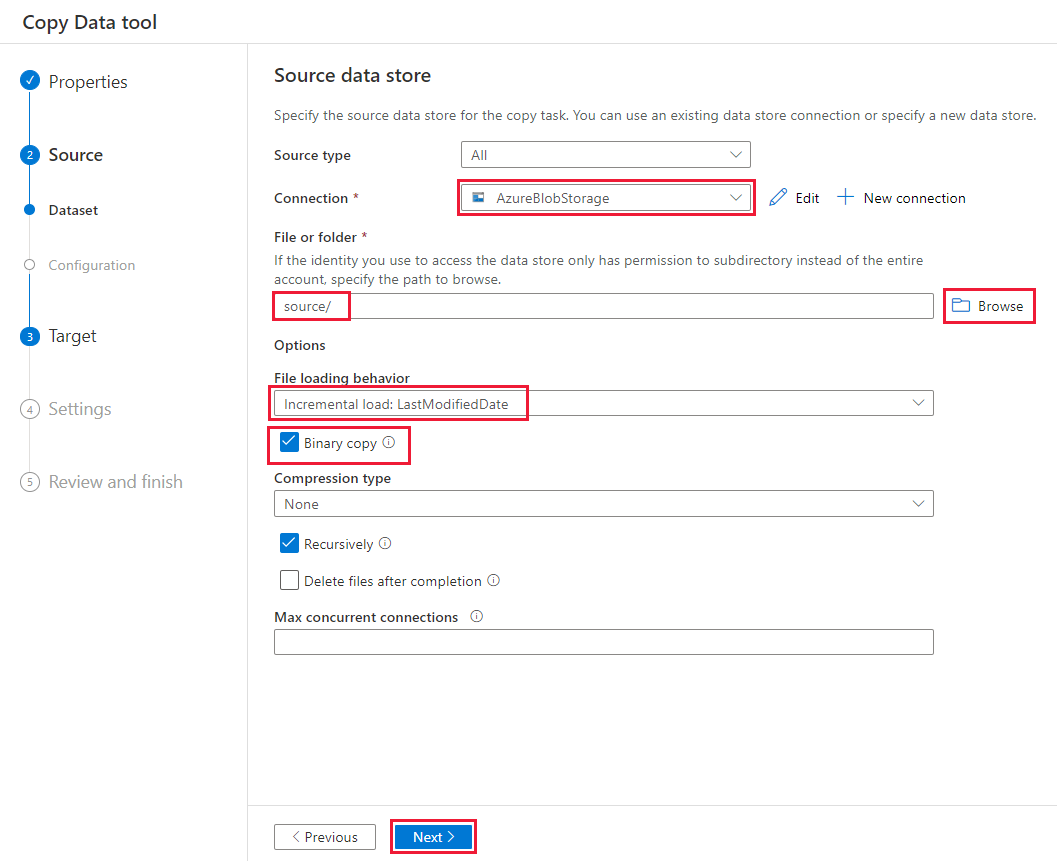
Slutför följande steg på sidan Måldatalager :
Välj den AzureBlobStorage-anslutning som du skapade. Det här är samma lagringskonto som källdatalagret.
I avsnittet Mappsökväg bläddrar du efter och väljer målmappen och väljer sedan OK.
Välj Nästa.
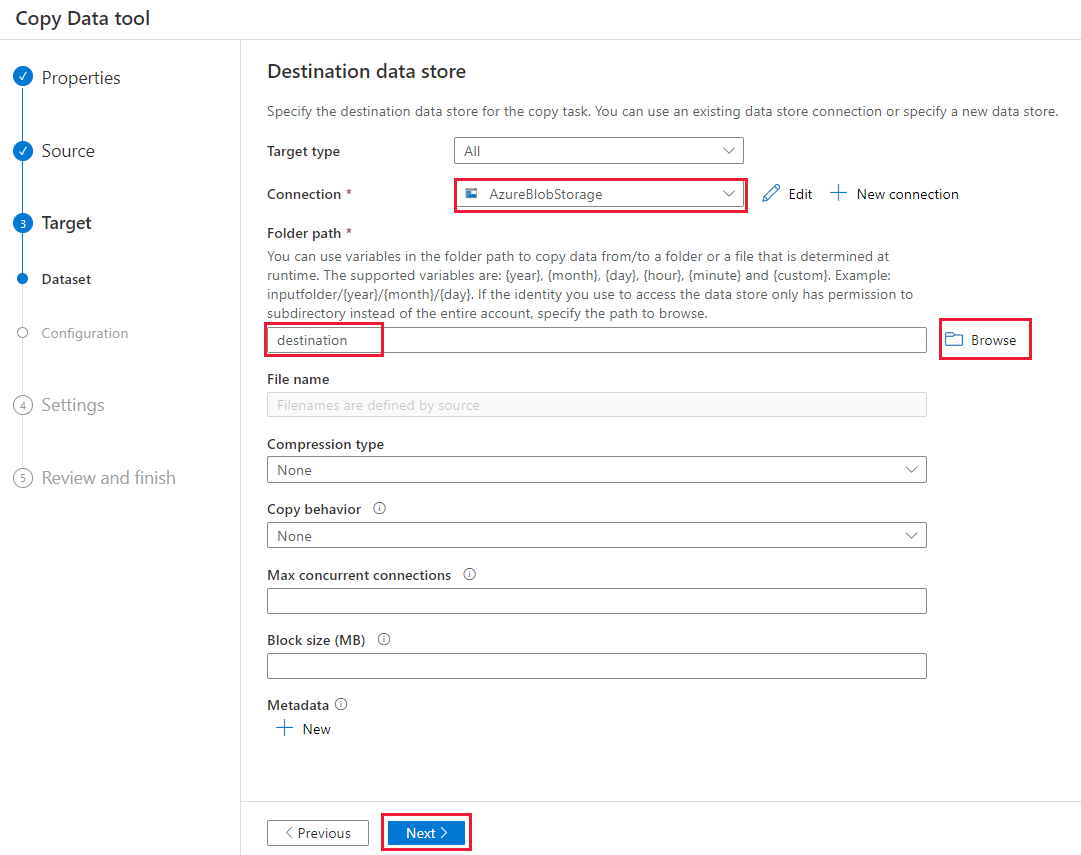
På sidan Inställningar , under Aktivitetsnamn, anger du DeltaCopyFromBlobPipeline och väljer sedan Nästa. Data Factory skapar en pipeline med det angivna aktivitetsnamnet.
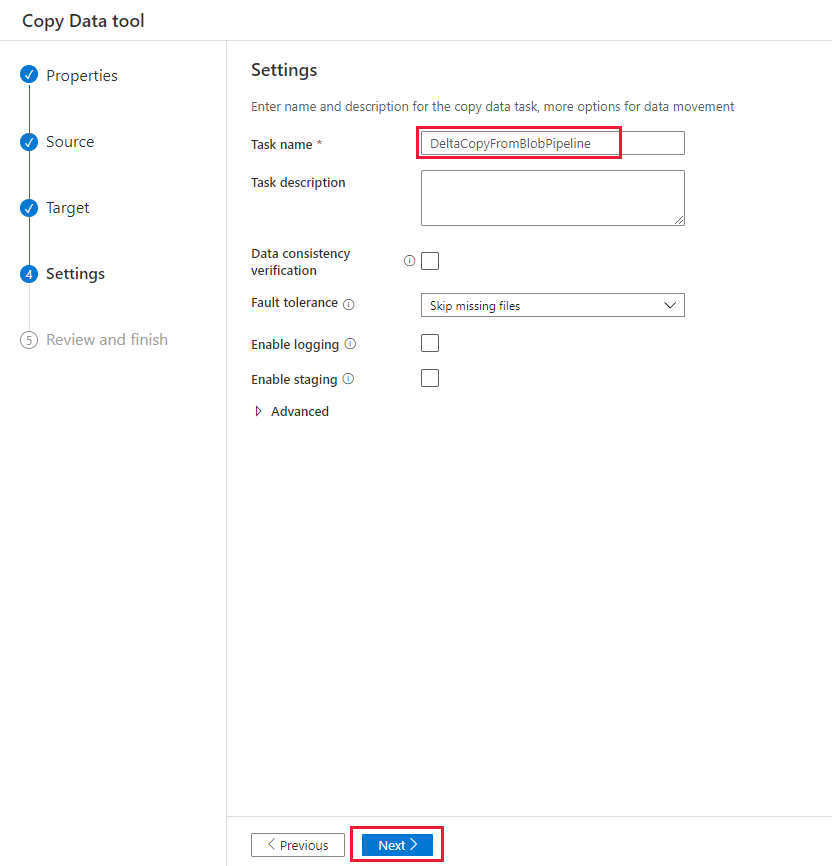
På sidan Sammanfattning granskar du inställningarna och väljer sedan Nästa.
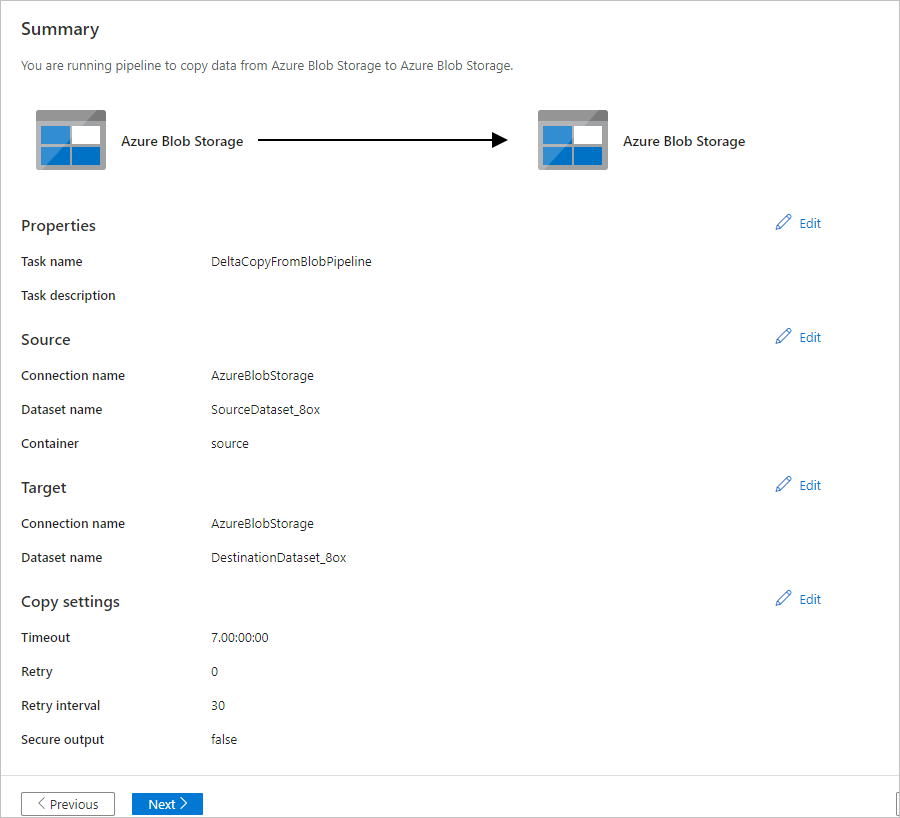
Välj Övervaka på sidan Distribution för att övervaka pipelinen (aktiviteten).
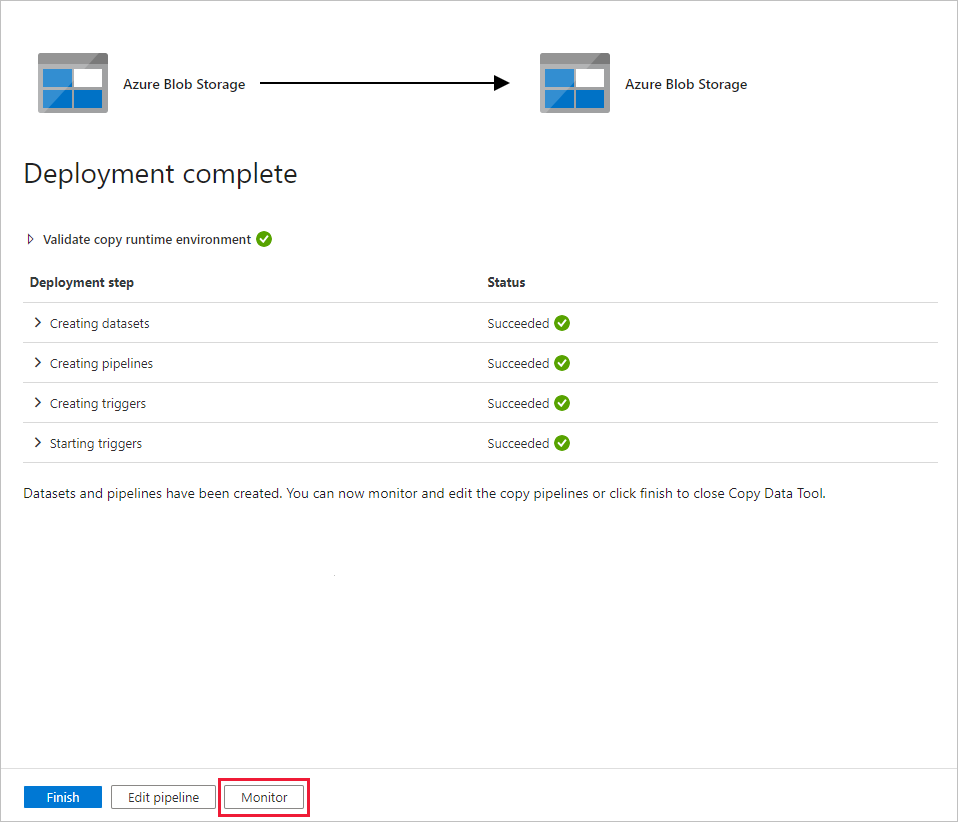
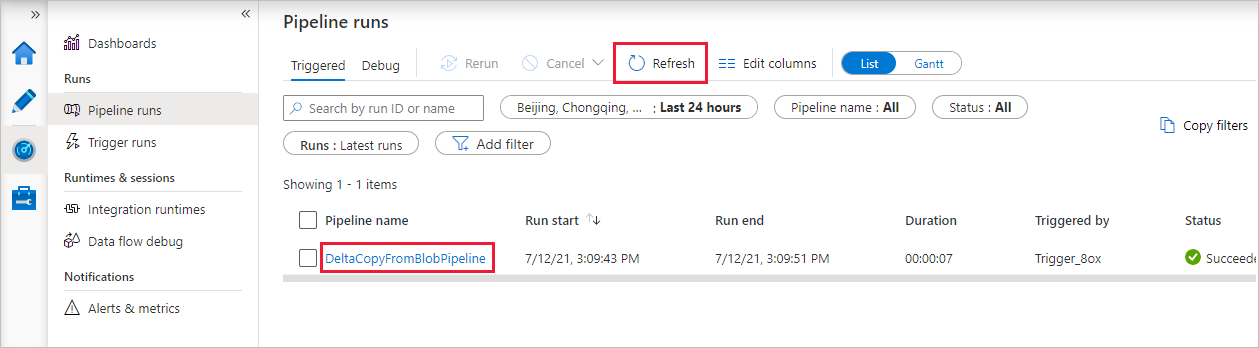
Observera att fliken Övervaka till vänster väljs automatiskt. Programmet växlar till fliken Övervaka . Du ser status för pipelinen. Om du vill uppdatera listan väljer du Refresh (Uppdatera). Välj länken under Pipelinenamn för att visa aktivitetskörningsinformation eller för att köra pipelinen igen.
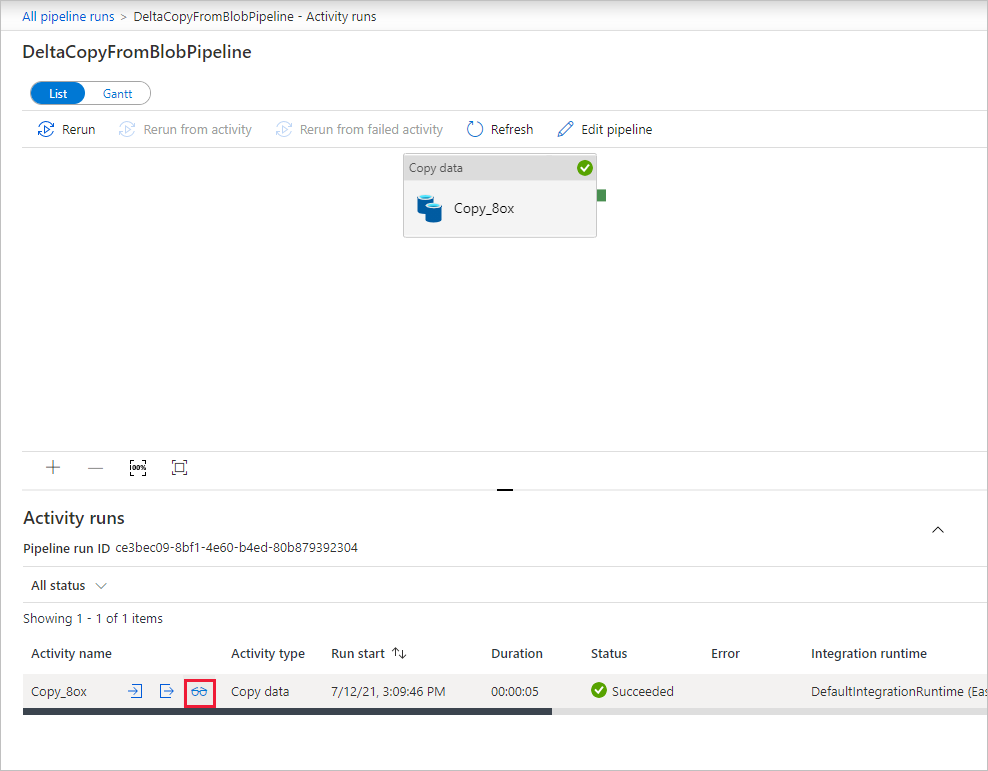
Det finns bara en aktivitet (kopieringsaktiviteten) i pipelinen, så du ser bara en post. Om du vill ha mer information om kopieringsåtgärden går du till sidan Aktivitetskörningar och väljer länken Information (glasögonikonen) i kolumnen Aktivitetsnamn . Mer information om egenskaperna finns i aktiviteten Kopiera översikt.
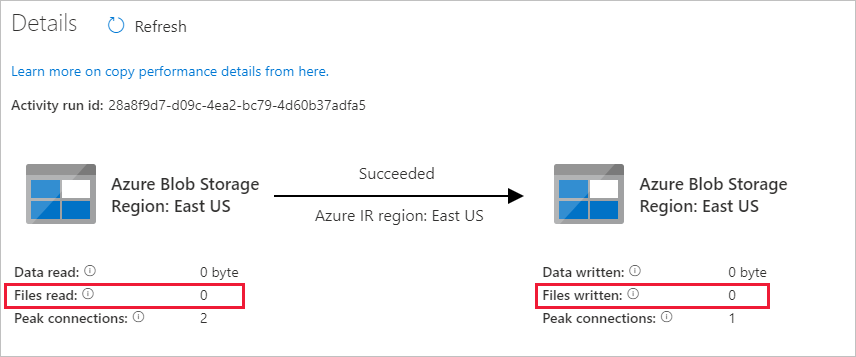
Eftersom det inte finns några filer i källcontainern i ditt Blob Storage-konto ser du inga filer som kopieras till målcontainern i kontot:
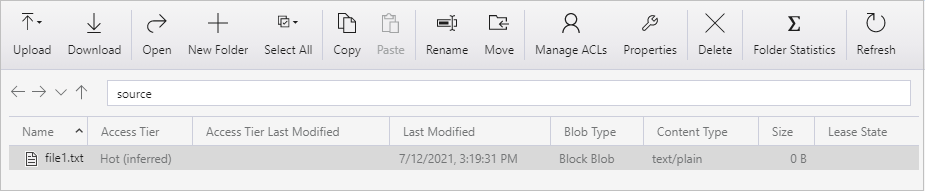
Skapa en tom textfil och ge den namnet file1.txt. Ladda upp textfilen till källcontainern i ditt lagringskonto. Du kan använda olika verktyg för att utföra dessa uppgifter, till exempel Azure Storage Explorer.
Om du vill gå tillbaka till vyn Pipelinekörningar väljer du Länken Alla pipelinekörningar i menyn breadcrumb på sidan Aktivitetskörningar och väntar tills samma pipeline utlöses automatiskt igen.
När den andra pipelinekörningen är klar följer du samma steg som tidigare för att granska aktivitetskörningsinformationen.
Du ser att en fil (file1.txt) har kopierats från källcontainern till målcontainern för ditt Blob Storage-konto:
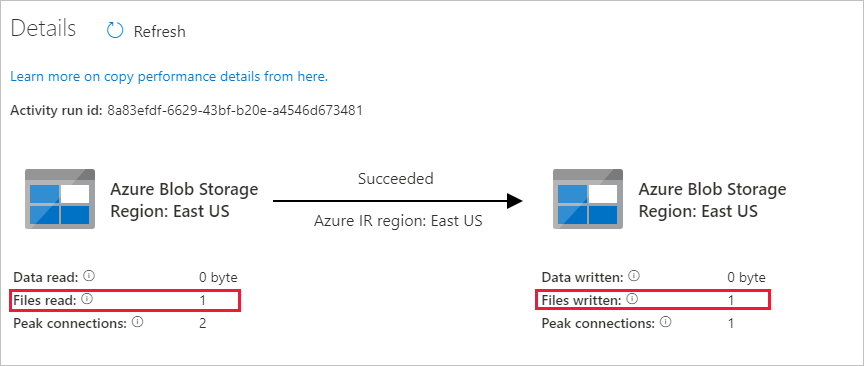
Skapa en annan tom textfil och ge den namnet file2.txt. Ladda upp textfilen till källcontainern i ditt Blob Storage-konto.
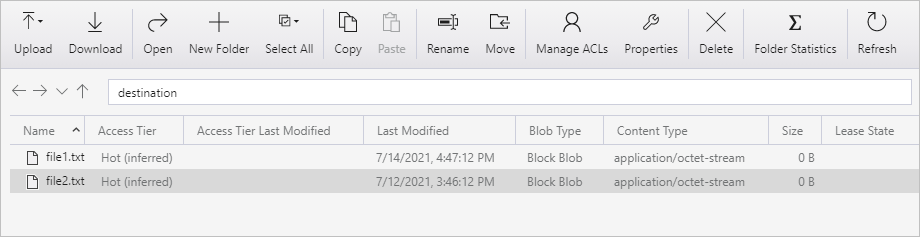
Upprepa steg 11 och 12 för den andra textfilen. Du ser att endast den nya filen (file2.txt) kopierades från källcontainern till målcontainern för ditt lagringskonto under den här pipelinekörningen.
Du kan också kontrollera att endast en fil har kopierats med hjälp av Azure Storage Explorer för att genomsöka filerna:
Relaterat innehåll
Gå till följande självstudie för att lära dig hur du transformerar data med hjälp av ett Apache Spark-kluster i Azure: