Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här självstudien använder du Azure-portalen till att skapa Azure Data Factory-pipeline. Pipelinen transformerar data med en Spark-aktivitet och en länkad Azure HDInsight-tjänst på begäran.
I de här självstudierna går du igenom följande steg:
- Skapa en datafabrik.
- Skapa en pipeline som använder en Spark-aktivitet.
- Utlös en pipelinekörning.
- Övervaka pipelinekörningen.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
Kommentar
Vi rekommenderar att du använder Azure Az PowerShell-modulen för att interagera med Azure. Se Installera Azure PowerShell för att komma igång. Information om hur du migrerar till Az PowerShell-modulen finns i artikeln om att migrera Azure PowerShell från AzureRM till Az.
- Azure Storage-konto. Du skapar ett Python-skript och en indatafil, och laddar upp dem till Azure Storage. Utdata från Spark-programmet lagras på det här lagringskontot. Spark-klustret på begäran använder samma lagringskonto som den primära lagringen.
Kommentar
HdInsight stöder endast lagringskonton för generell användning med standardnivån. Kontrollera att kontot inte är ett lagringskonto enbart för premium- eller bloblagring.
- Azure PowerShell. Följ instruktionerna i Så här installerar och konfigurerar du Azure PowerShell.
Ladda upp Python-skriptet till ditt Blob Storage-konto
Skapa en Python-fil med namnet WordCount_Spark.py med följande innehåll:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()Ersätt <storageAccountName> med namnet på ditt Azure Storage-konto. Spara sedan filen.
Skapa en container med namnet adftutorial i Azure Blob Storage om den inte redan finns.
Skapa en mapp med namnet spark.
Skapa en undermapp med namnet script under mappen spark.
Överför filen WordCount_Spark.py till undermappen script.
Överföra indatafilen
- Skapa en fil med namnet minecraftstory.txt med lite text. Spark-programmet räknar antalet ord i texten.
- Skapa en undermapp med namnet inputfiles i mappen spark.
- Ladda upp filen minecraftstory.txt till undermappen inputfiles.
Skapa en datafabrik
Följ stegen i artikeln Snabbstart: Skapa en datafabrik med hjälp av Azure Portal för att skapa en datafabrik om du inte redan har en att arbeta med.
Skapa länkade tjänster
Du skapar två länkade tjänster i det här avsnittet:
- En länkad Azure Storage-tjänst som länkar ditt Azure Storage-konto till datafabriken. Den här lagringen används av HDInsight-kluster på begäran. Den innehåller också Spark-skriptet som ska köras.
- En länkad HDInsight-tjänst på begäran. Azure Data Factory skapar automatiskt ett HDInsight-kluster och kör Spark-programmet. HDInsight-klustret tas bort när det har varit inaktivt under en förinställd tid.
Skapa en länkad Azure Storage-tjänst
På startsidan växlar du till fliken Hantera i den vänstra panelen.
Välj Anslutningar längst ned i fönstret och sedan +Ny.
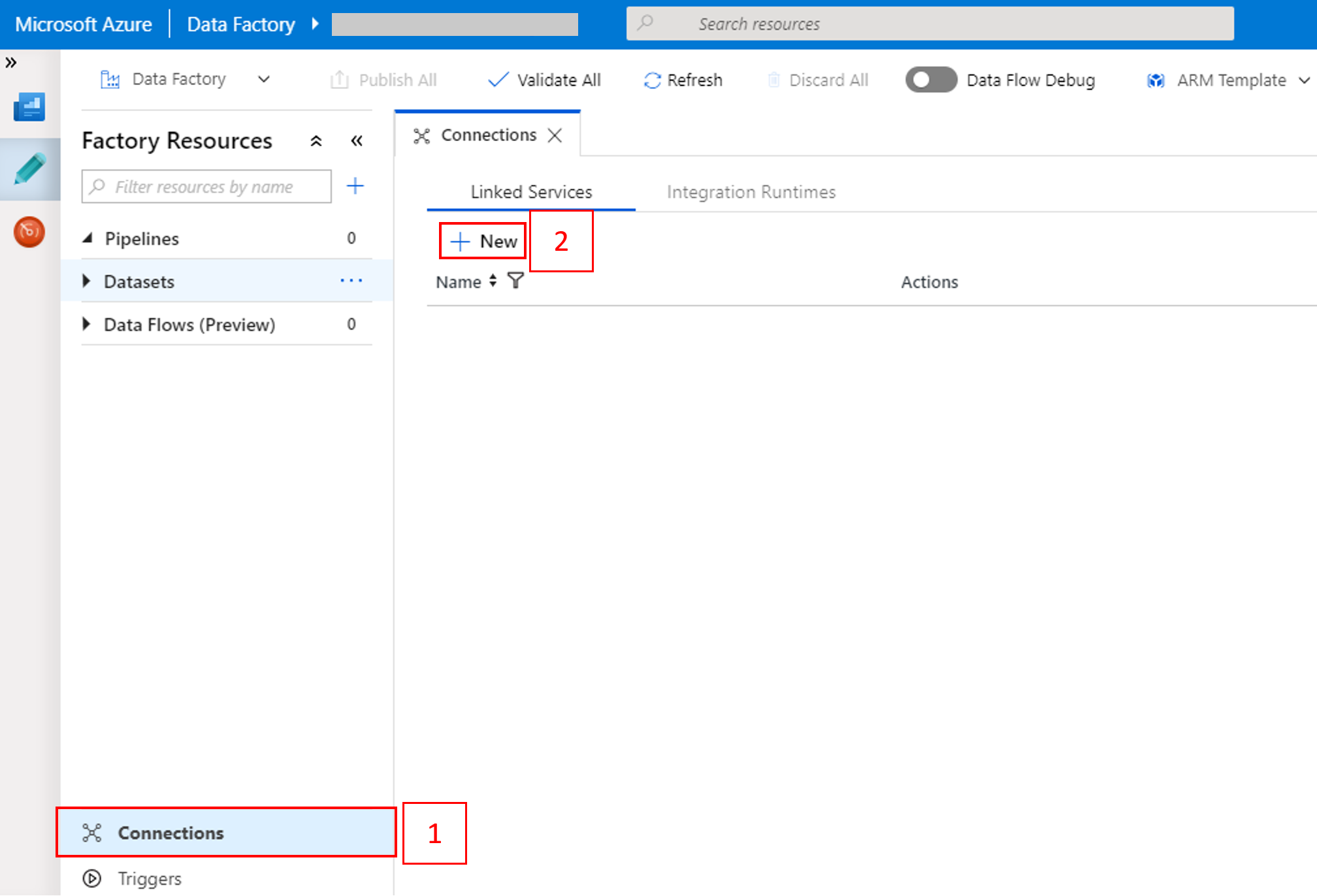
I fönstret New Linked Service (Ny länkad tjänst) väljer du Data Store>Azure Blob Storage och klickar på Fortsätt.

För Lagringskontonamn väljer du namnet i listan och väljer sedan Spara.
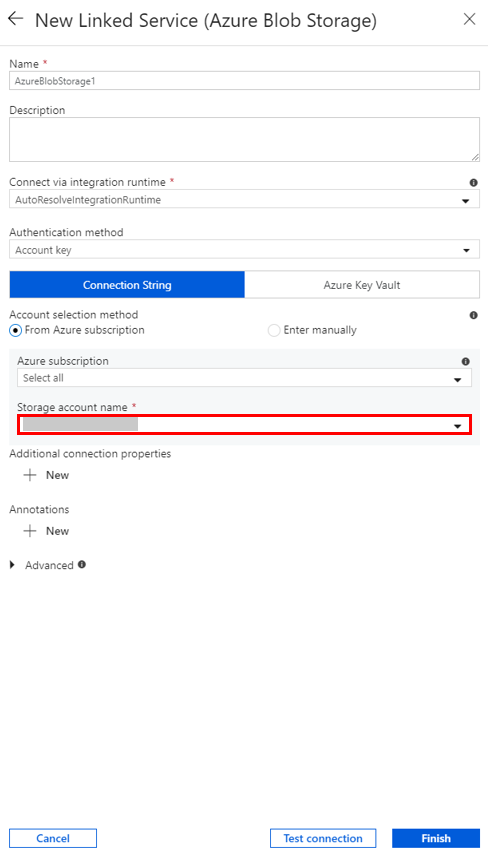
Skapa en på begäran länkad HDInsight-tjänst
Välj knappen +Ny igen för att skapa ytterligare en länkad tjänst.
I fönstret New Linked Service (Ny länkad tjänst) väljer du Compute>Azure HDInsight och sedan Fortsätt.

Utför följande steg i fönstret New Linked Service (Ny länkad tjänst):
a. Som Namn anger du AzureHDInsightLinkedService.
b. För Typ kontrollerar du att HDInsight på begäran är valt.
c. För Länkad Azure Storage-tjänst väljer du AzureBlobStorage1. Du skapade den här länkade tjänsten tidigare. Ange rätt namn här om du tidigare använde ett annat namn.
d. För Klustertyp väljer du spark.
e. För ID för tjänstens huvudnamn anger du det ID för tjänsten huvudman som har behörighet att skapa ett HDInsight-kluster.
Tjänstens huvudnamn måste vara medlem i rollen Deltagare för prenumerationen eller resursgruppen som klustret har skapats i. Mer information finns i Skapa ett Microsoft Entra-program och tjänstens huvudnamn. Tjänstens huvudnamns-ID motsvarar program-ID:t och en huvudnyckel för tjänsten motsvarar värdet för en klienthemlighet.
f. Ange nyckeln i Nyckel för tjänstens huvudnamn.
g. Välj samma resursgrupp som du använde när du skapade datafabriken i Resursgrupp. Spark-klustret skapas i den här resursgruppen.
h. Öppna OS-typ.
i. Ange ett namn som klusteranvändarnamn.
j. Ange användarens klusterlösenord.
k. Välj Slutför.
Kommentar
Azure HDInsight begränsar hur många kärnor du kan använda i varje Azure-region som stöds. För den länkade HDInsight-tjänsten på begäran skapas HDInsight-klustret på samma Azure Storage-plats som används för primär lagring. Se till att du har tillräckligt med kärnkvoter så att klustret kan skapats på rätt sätt. Mer information finns i Set up clusters in HDInsight with Hadoop, Spark, Kafka, and more (Konfigurera kluster i HDInsight med Hadoop, Spark, Kafka med mera).
Skapa en pipeline
Välj knappen + (plus) och sedan Pipeline från menyn.
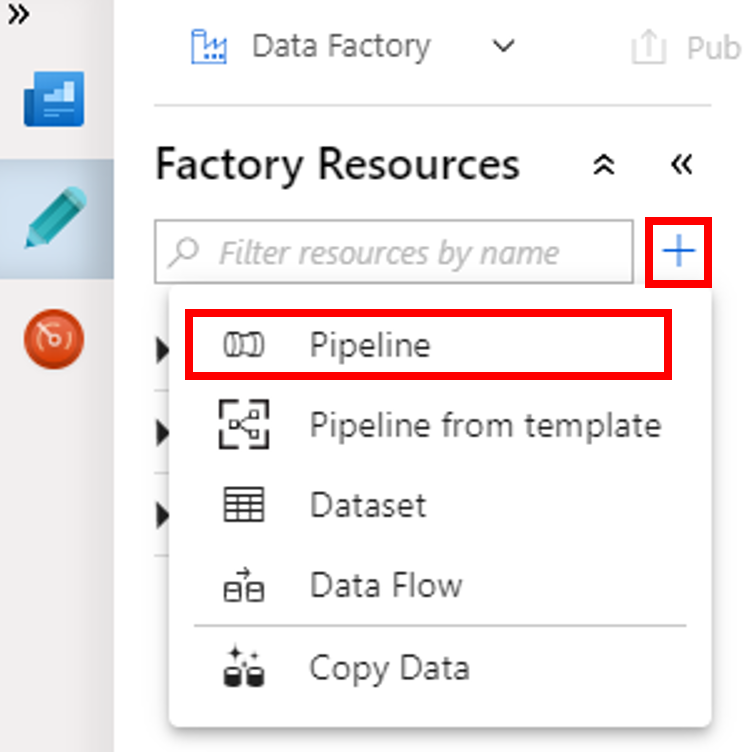
Gå till verktygsfältet Aktiviteter och expandera HDInsight. Dra aktiviteten Spark från verktygsfältet Aktiviteter till pipelinedesignytan.
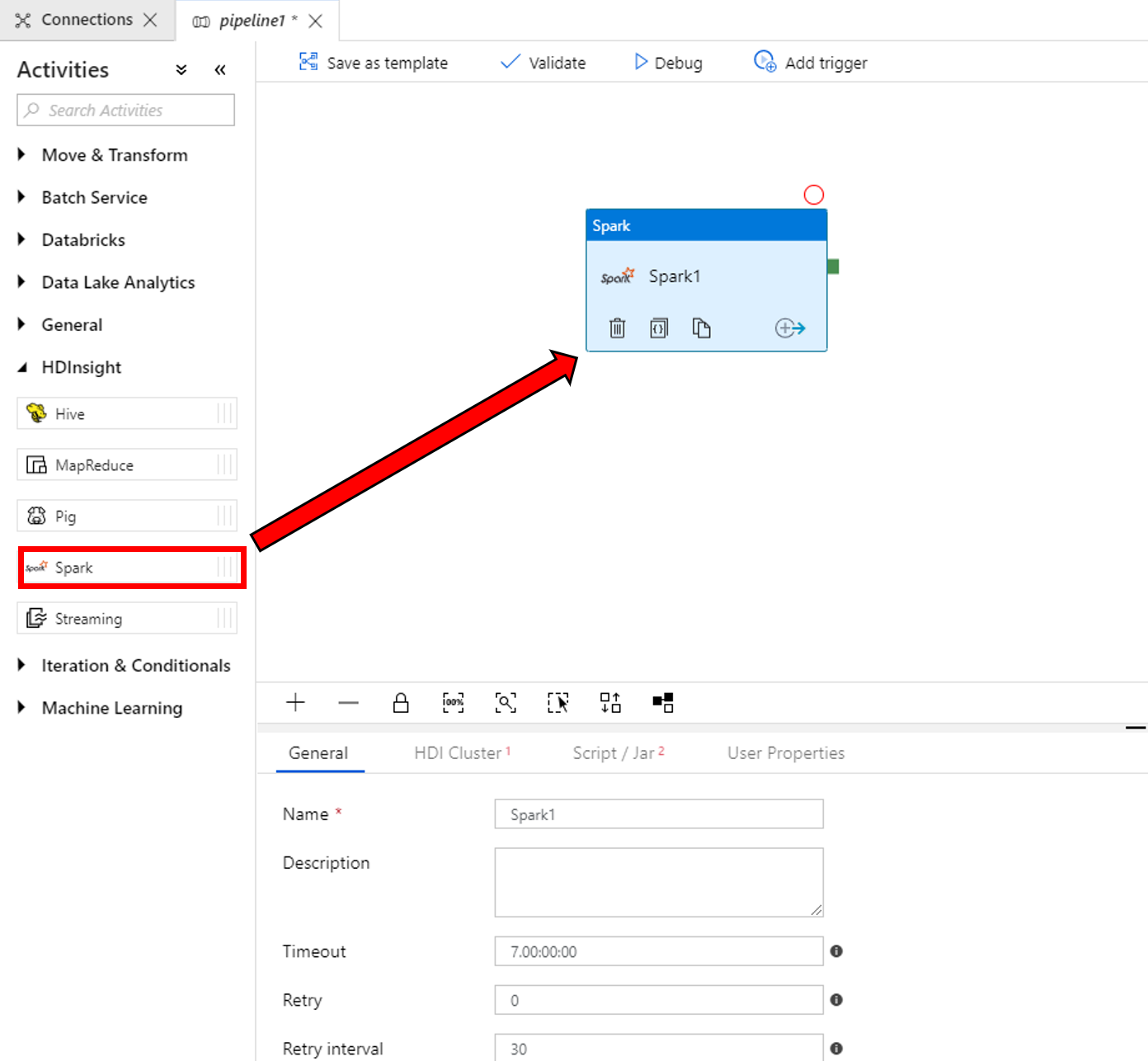
Utför följande steg i egenskaperna för Spark-aktivitetsfönstret längst ned:
a. Växla till fliken HDI-kluster.
b. Välj AzureHDInsightLinkedService (som du skapade i föregående procedur).
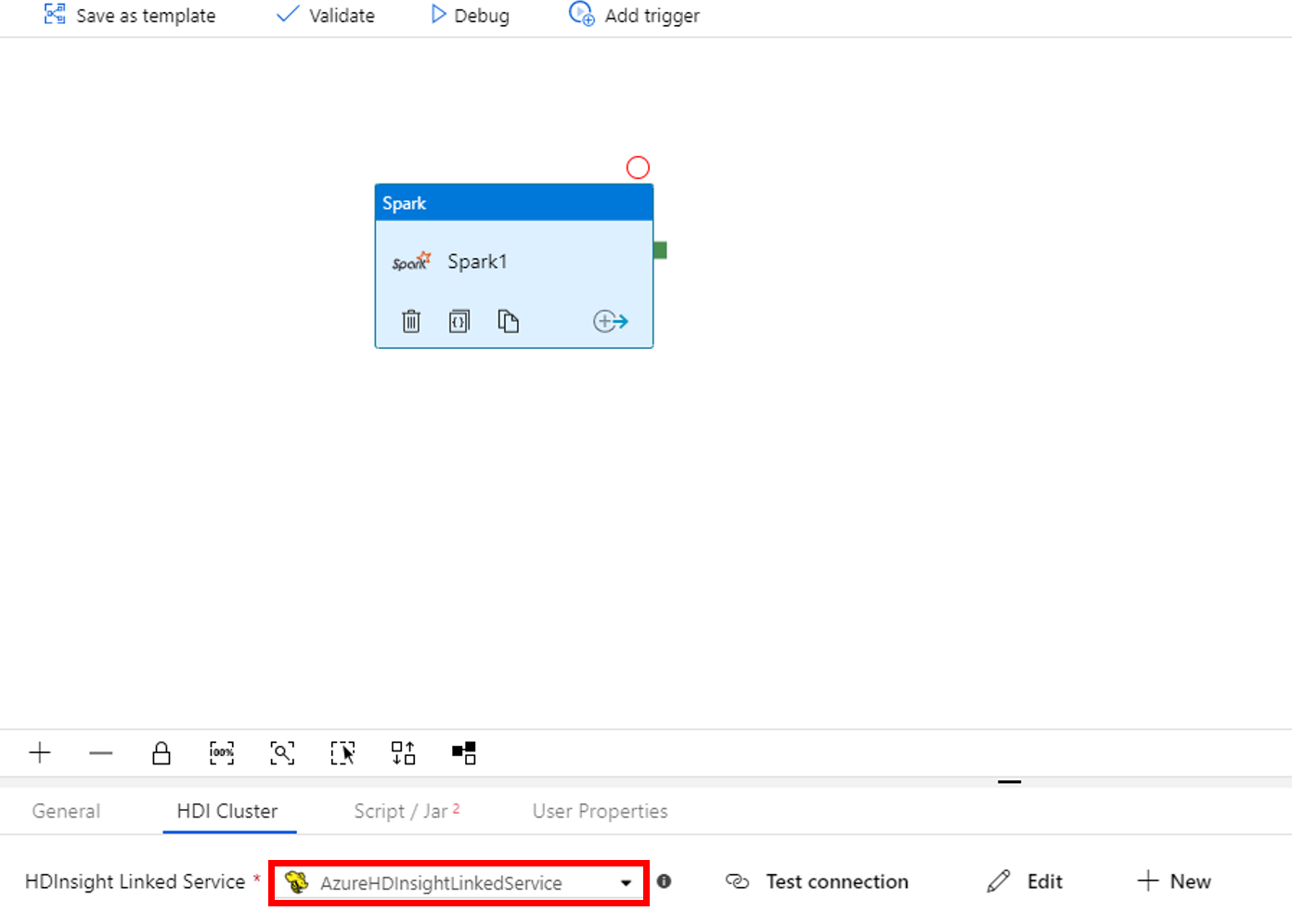
Växla till fliken Skript/Jar och utför följande steg:
a. För Jobblänkade tjänster väljer du AzureBlobStorage1.
b. Välj Bläddra i lagring.

c. Bläddra till mappen adftutorial/spark/script, välj WordCount_Spark.py och välj sedan Slutför.
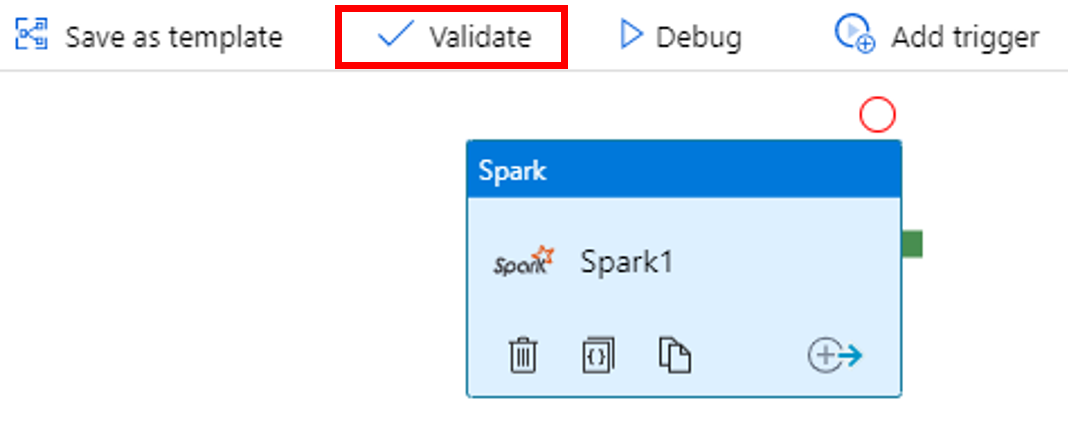
Verifiera pipelinen genom att välja knappen Verifiera i verktygsfältet. Klicka på knappen >> (högerpil) för att stänga verifieringsfönstret.
Välj Publicera alla. Data Factory-gränssnittet publicerar entiteter (länkade tjänster och pipelines) till Azure Data Factory-tjänsten.
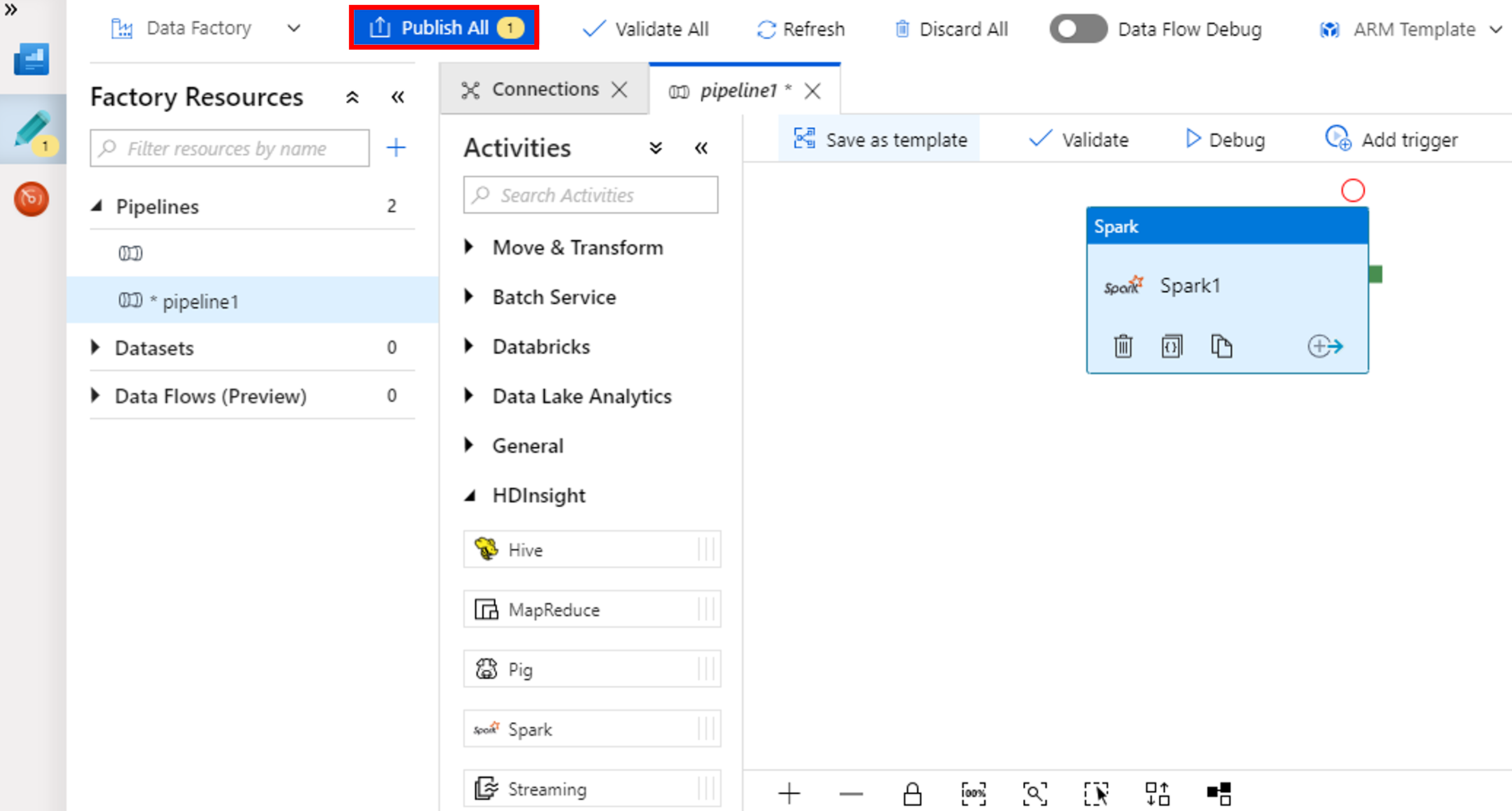
Utlös en pipelinekörning
Välj Lägg till utlösare i verktygsfältet och välj sedan Utlösa nu.
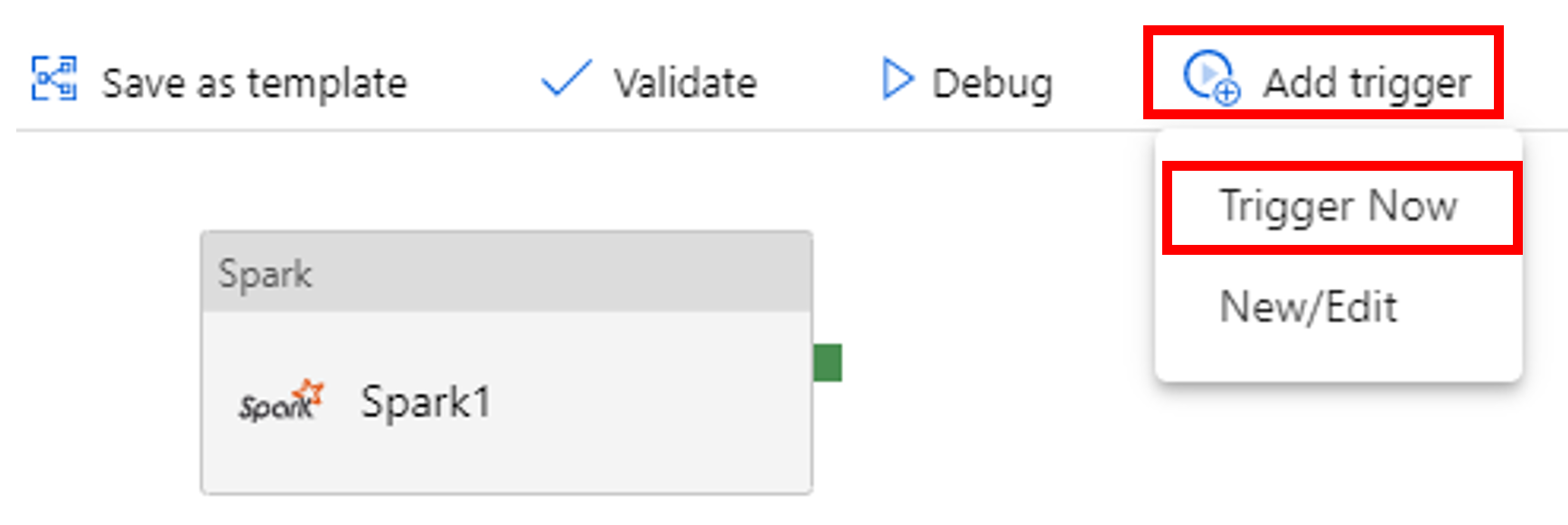
Övervaka pipelinekörningen
Växla till fliken Övervaka . Bekräfta att du ser en pipelinekörning. Det tar ungefär 20 minuter att skapa ett Spark-kluster.
Klicka på Uppdatera då och då så att du ser pipelinekörningens status.
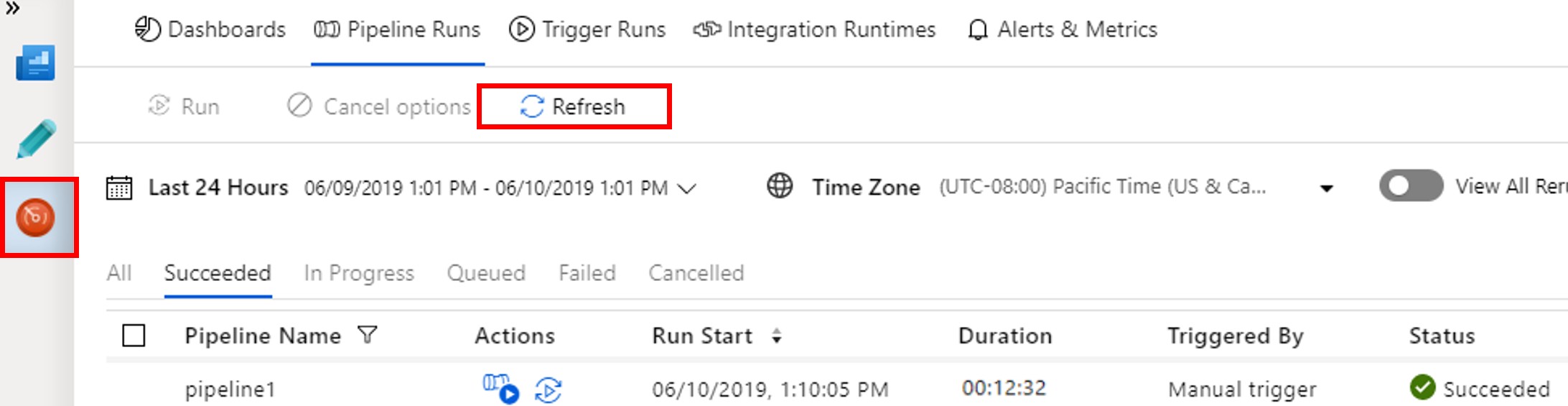
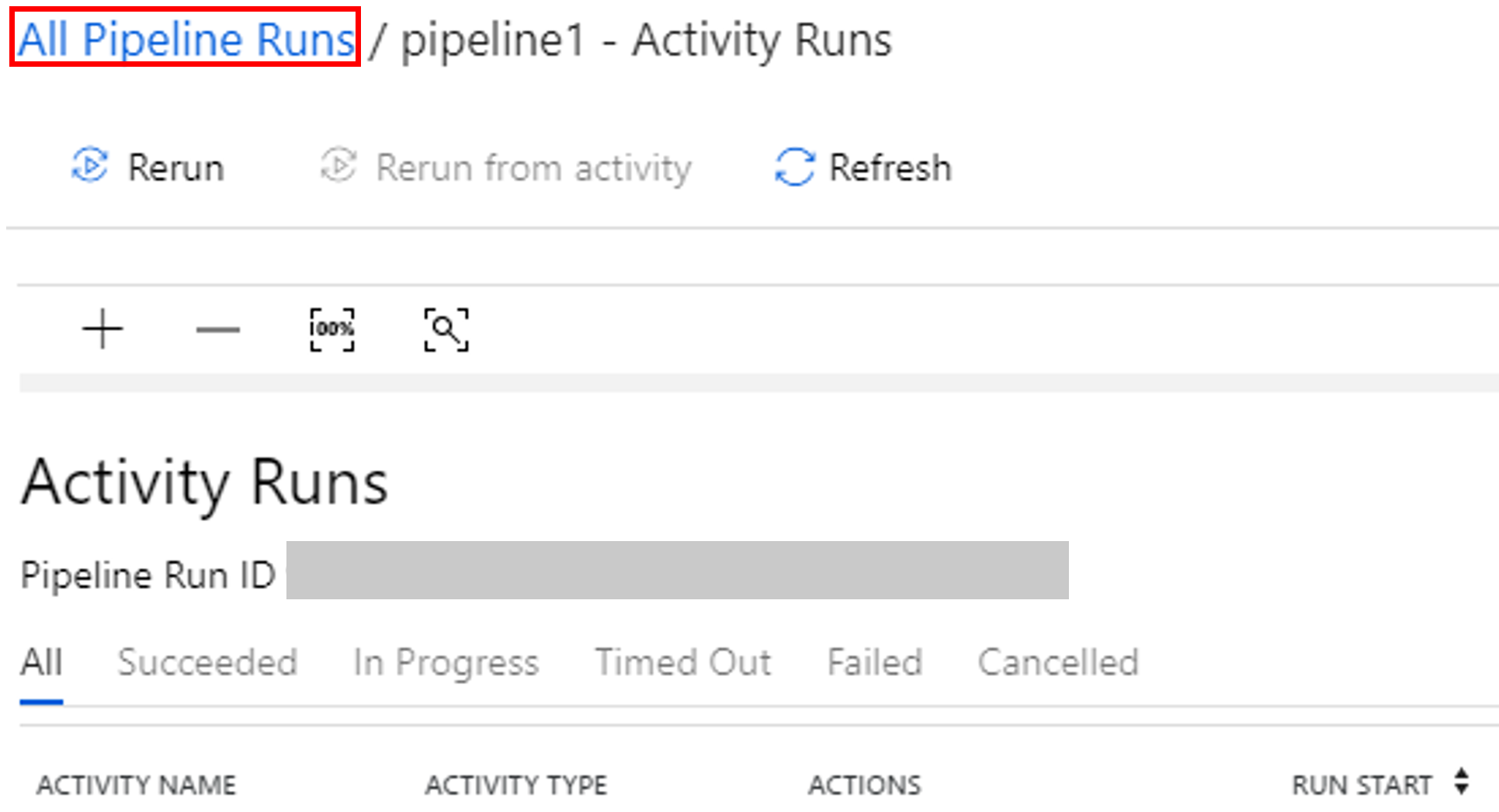
Om du vill visa aktivitetskörningar som är associerade med pipelinekörningarna väljer på länken View activity runs (Visa aktivitetskörningar) i kolumnen Åtgärd.
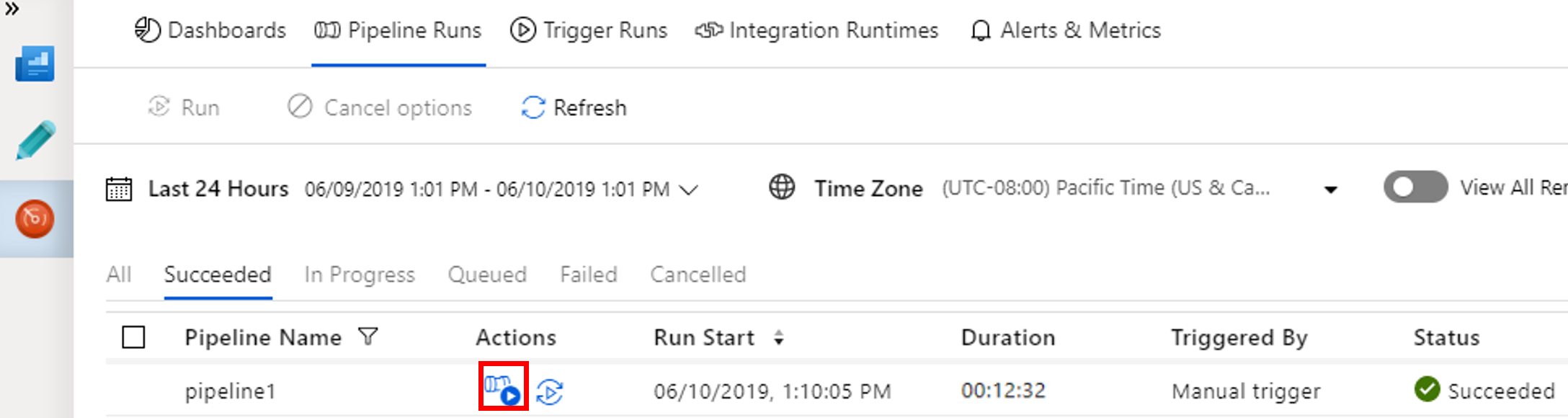
Du kan växla tillbaka till pipelinekörningsvyn genom att välja länken Alla pipelinekörningar högst upp.
Verifiera utdata
Verifiera att utdatafilen har skapats i mappen spark/otuputfiles/wordcount för containern adftutorial.
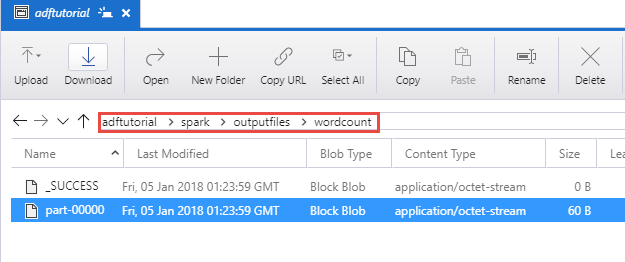
Filen bör ha alla ord från indatafilen samma antal gånger som ordet förekommer i filen. Till exempel:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
Relaterat innehåll
Pipelinen i det här exemplet transformerar data med en Spark-aktivitet och en länkad HDInsight-tjänst på begäran. Du har lärt dig att:
- Skapa en datafabrik.
- Skapa en pipeline som använder en Spark-aktivitet.
- Utlös en pipelinekörning.
- Övervaka pipelinekörningen.
Om du vill hur du transformerar data genom att köra ett Hive-skript i ett Azure HDInsight-kluster i ett virtuellt nätverk går du vidare till nästa självstudie: