Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Kommentar
Det lakeflow schemat kallades tidigare workflow. Innehållet i båda schemana är identiskt.
Den här artikeln är en referens för lakeflow systemtabellerna som registrerar jobbaktivitet i ditt konto. Dessa tabeller innehåller poster från alla arbetsytor i ditt konto som distribuerats i samma molnregion. Om du vill se poster från en annan region måste du visa tabellerna från en arbetsyta som finns i den regionen.
Krav
- För att få åtkomst till dessa systemtabeller måste användarna antingen:
- Vara både metaarkivadministratör och kontoadministratör, eller
- Ha
USEochSELECTbehörigheter för systemscheman. Se Bevilja åtkomst till systemtabeller.
Tillgängliga jobbtabeller
Alla jobbrelaterade systemtabeller finns i system.lakeflow schemat. Schemat är för närvarande värd för fyra tabeller:
| Bord | beskrivning | Stöder direktuppspelning | Fri kvarhållningsperiod | Innehåller globala eller regionala data |
|---|---|---|---|---|
| jobb (offentlig förhandsversion) | Spårar alla jobb som skapats i kontot | Ja | 365 dagar | Regionell |
| job_tasks (offentlig förhandsversion) | Spårar alla jobbaktiviteter som körs i kontot | Ja | 365 dagar | Regionell |
| job_run_timeline (offentlig förhandsversion) | Övervakar jobbexekveringar och relaterade metadata | Ja | 365 dagar | Regionell |
| job_task_run_timeline (offentlig förhandsversion) | Spårar jobbtaskkörningar och relaterad metadata | Ja | 365 dagar | Regionell |
| pipelines (offentlig förhandsversion) | Spårar alla pipelines som skapats i kontot | Ja | 365 dagar | Regionell |
Detaljerad schemareferens
Följande avsnitt innehåller schemareferenser för var och en av de jobbrelaterade systemtabellerna.
Tabellschema för jobben
Tabellen jobs är en långsamt föränderlig dimensionstabell (SCD2). När en rad ändras genereras en ny rad, vilket logiskt ersätter den föregående.
Tabellsökväg: system.lakeflow.jobs
| Kolumnnamn | Datatyp | beskrivning | Anteckningar |
|---|---|---|---|
account_id |
sträng | ID:t för det konto som jobbet tillhör | |
workspace_id |
sträng | ID för arbetsytan som detta jobb tillhör | |
job_id |
sträng | Jobbets ID | Endast unikt inom en enda arbetsyta |
name |
sträng | Det användarlevererade namnet på jobbet | |
description |
sträng | Beskrivningen av jobbet som användaren har angett | Det här fältet är tomt om du har kundhanterade nycklar konfigurerade. Fylls inte i för rader som genereras före slutet av augusti 2024 |
creator_id |
sträng | ID för huvudmannen som skapade jobbet | |
tags |
karta | De anpassade taggar som har angetts av användaren som är associerade med det här jobbet | |
change_time |
tidsstämpel | Den tid då jobbet senast ändrades | Tidszon som registrerats som +00:00 (UTC) |
delete_time |
tidsstämpel | Den tid då jobbet togs bort av användaren | Tidszon som registrerats som +00:00 (UTC) |
run_as |
sträng | ID för användaren eller tjänstens principal vars behörigheter används för jobbutförandet |
Exempelfråga
-- Get the most recent version of a job
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.jobs QUALIFY rn=1
Schema för arbetsuppgiftstabell
Tabellen för jobbuppgifter är en långsamt föränderlig dimensionstabell (SCD2). När en rad ändras genereras en ny rad, vilket logiskt ersätter den föregående.
Tabellsökväg: system.lakeflow.job_tasks
| Kolumnnamn | Datatyp | beskrivning | Anteckningar |
|---|---|---|---|
account_id |
sträng | ID:t för det konto som jobbet tillhör | |
workspace_id |
sträng | ID för arbetsytan som detta jobb tillhör | |
job_id |
sträng | Jobbets ID | Endast unikt inom en enda arbetsyta |
task_key |
sträng | Referensnyckeln för en uppgift i ett jobb | Endast unikt inom ett enda jobb |
depends_on_keys |
samling | Aktivitetsnycklarna för alla överordnade beroenden för den här aktiviteten | |
change_time |
tidsstämpel | Den tid då aktiviteten senast ändrades | Tidszon som registrerats som +00:00 (UTC) |
delete_time |
tidsstämpel | Den tid då en uppgift togs bort av användaren | Tidszon som registrerats som +00:00 (UTC) |
Exempelfråga
-- Get the most recent version of a job task
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.job_tasks QUALIFY rn=1
schema för jobbkörningens tidslinjetabell
Tidslinjetabellen för jobben är oföränderlig och slutförd när den skapas.
Tabellsökväg: system.lakeflow.job_run_timeline
| Kolumnnamn | Datatyp | beskrivning | Anteckningar |
|---|---|---|---|
account_id |
sträng | ID:t för det konto som jobbet tillhör | |
workspace_id |
sträng | ID för arbetsytan som detta jobb tillhör | |
job_id |
sträng | Jobbets ID | Den här nyckeln är bara unik på en enda arbetsyta |
run_id |
sträng | ID:t för jobbkörningen | |
period_start_time |
tidsstämpel | Starttiden för loppet eller tidsperioden. | Tidszonsinformation registreras i slutet av värdet med +00:00 som representerar UTC |
period_end_time |
tidsstämpel | Sluttiden för körningen eller för tidsperioden | Tidszonsinformation registreras i slutet av värdet med +00:00 som representerar UTC |
trigger_type |
sträng | Typen av trigger som kan starta en körning | Möjliga värden finns under utlösartyper |
run_type |
sträng | Typ av jobbkörning | Möjliga värden finns i Körningstypvärden |
run_name |
sträng | Det användarinställda körningsnamnet som är associerat med den här jobbkörningen | |
compute_ids |
samling | Matris som innehåller jobbberäknings-ID:t för den överordnade jobbkörningen | Används för att identifiera jobbkluster som används av WORKFLOW_RUN körtyper. Annan beräkningsinformation finns i tabellen job_task_run_timeline.Fylls inte i för rader som genereras före slutet av augusti 2024 |
result_state |
sträng | Resultatet av jobbkörningen | För möjliga värden, se Resultattillståndsvärdena |
termination_code |
sträng | Avslutningskoden för jobbkörningen | För möjliga värden, se Avslutningskodvärden. Fylls inte i för rader som genereras före slutet av augusti 2024 |
job_parameters |
karta | De parametrar på jobbnivå som används i jobbkörningen | De inaktuella notebook_params-inställningarna ingår inte i det här fältet. Fylls inte i för rader som genereras före slutet av augusti 2024 |
Exempelfråga
-- This query gets the daily job count for a workspace for the last 7 days:
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
-- This query returns the daily job count for a workspace for the last 7 days, distributed by the outcome of the job run.
SELECT
workspace_id,
COUNT(DISTINCT run_id) as job_count,
result_state,
to_date(period_start_time) as date
FROM system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
AND result_state IS NOT NULL
GROUP BY ALL
-- This query returns the average time of job runs, measured in seconds. The records are organized by job. A top 90 and a 95 percentile column show the average lengths of the job's longest runs.
with job_run_duration as (
SELECT
workspace_id,
job_id,
run_id,
CAST(SUM(period_end_time - period_start_time) AS LONG) as duration
FROM
system.lakeflow.job_run_timeline
WHERE
period_start_time > CURRENT_TIMESTAMP() - INTERVAL 7 DAYS
GROUP BY ALL
)
SELECT
t1.workspace_id,
t1.job_id,
COUNT(DISTINCT t1.run_id) as runs,
MEAN(t1.duration) as mean_seconds,
AVG(t1.duration) as avg_seconds,
PERCENTILE(t1.duration, 0.9) as p90_seconds,
PERCENTILE(t1.duration, 0.95) as p95_seconds
FROM
job_run_duration t1
GROUP BY ALL
ORDER BY mean_seconds DESC
LIMIT 100
-- This query provides a historical runtime for a specific job based on the `run_name` parameter. For the query to work, you must set the `run_name`.
SELECT
workspace_id,
run_id,
SUM(period_end_time - period_start_time) as run_time
FROM system.lakeflow.job_run_timeline
WHERE
run_type="SUBMIT_RUN"
AND run_name = :run_name
AND period_start_time > CURRENT_TIMESTAMP() - INTERVAL 60 DAYS
GROUP BY ALL
-- This query collects a list of retried job runs with the number of retries for each run.
with repaired_runs as (
SELECT
workspace_id, job_id, run_id, COUNT(*) - 1 as retries_count
FROM system.lakeflow.job_run_timeline
WHERE result_state IS NOT NULL
GROUP BY ALL
HAVING retries_count > 0
)
SELECT
*
FROM repaired_runs
ORDER BY retries_count DESC
LIMIT 10;
tabellschema för jobbuppgiftens tidslinje
Tabellen med tidslinjen för körningsuppgiften är oföränderlig och fullständig när den skapas.
Tabellsökväg: system.lakeflow.job_task_run_timeline
| Kolumnnamn | Datatyp | beskrivning | Anteckningar |
|---|---|---|---|
account_id |
sträng | ID:t för det konto som jobbet tillhör | |
workspace_id |
sträng | ID för arbetsytan som detta jobb tillhör | |
job_id |
sträng | Jobbets ID | Endast unikt inom en enda arbetsyta |
run_id |
sträng | ID för aktivitetskörningen | |
job_run_id |
sträng | ID:t för jobbkörningen | Fylls inte i för rader som genereras före slutet av augusti 2024 |
parent_run_id |
sträng | ID för den överordnade körningen | Fylls inte i för rader som genereras före slutet av augusti 2024 |
period_start_time |
tidsstämpel | Starttiden för aktiviteten eller för tidsperioden | Tidszonsinformation registreras i slutet av värdet med +00:00 som representerar UTC |
period_end_time |
tidsstämpel | Sluttiden för aktiviteten eller för tidsperioden | Tidszonsinformation registreras i slutet av värdet med +00:00 som representerar UTC |
task_key |
sträng | Referensnyckeln för en uppgift i ett jobb | Den här nyckeln är bara unik i ett enda jobb |
compute_ids |
samling | Matrisen compute_ids innehåller ID:t för jobbkluster, interaktiva kluster och SQL-lager som används av jobbaktiviteten | |
result_state |
sträng | Resultatet av arbetsuppgiftens genomförande | För möjliga värden, se Resultattillståndsvärdena |
termination_code |
sträng | Avslutningskoden för aktivitetskörningen | För möjliga värden, se Avslutningskodvärden. Fylls inte i för rader som genereras före slutet av augusti 2024 |
Pipelines tabellschema
Tabellen pipelines är en långsamt föränderlig dimensionstabell (SCD2). När en rad ändras genereras en ny rad, vilket logiskt ersätter den föregående.
Tabellsökväg: system.lakeflow.pipelines
| Kolumnnamn | Datatyp | beskrivning | Anteckningar |
|---|---|---|---|
account_id |
sträng | ID:t för det konto som pipelinen tillhör | |
workspace_id |
sträng | ID:t för arbetsytan som den här pipelinen tillhör | |
pipeline_id |
sträng | ID för pipelinen | Endast unikt inom en enda arbetsyta |
pipeline_type |
sträng | Typ av pipeline | Möjliga värden finns i Pipelinetypsvärden |
name |
sträng | Det användaruppgivna namnet på pipelinen | |
created_by |
sträng | Användarens e-post eller service principalens ID som skapade pipelinen | |
run_as |
sträng | E-postadressen för användaren eller ID:t för tjänstens huvudkonto vars behörigheter används för pipelinekörningen | |
tags |
karta | De anpassade taggar som har angetts av användaren som är associerade med det här jobbet | |
settings |
Struktur | Inställningarna för pipelinen | Se Pipelineinställningar |
configuration |
karta | Konfigurationen av pipelinen som tillhandahålls av användaren | |
change_time |
tidsstämpel | Tiden då pipelinen senast ändrades | Tidszon som registrerats som +00:00 (UTC) |
delete_time |
tidsstämpel | Tiden då pipelinen togs bort av användaren | Tidszon som registrerats som +00:00 (UTC) |
Exempelfråga
-- Get the most recent version of a pipeline
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, pipeline_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.pipelines QUALIFY rn=1
-- Enrich billing logs with pipeline metadata
with latest_pipelines AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, pipeline_id ORDER BY change_time DESC) as rn
FROM
system.lakeflow.pipelines QUALIFY rn=1
)
SELECT
usage.*,
pipelines.*
FROM system.billing.usage
LEFT JOIN latest_pipelines
ON (usage.workspace_id = pipelines.workspace_id
AND usage.usage_metadata.dlt_pipeline_id = pipelines.pipeline_id)
WHERE
usage.usage_metadata.dlt_pipeline_id IS NOT NULL
Vanliga kopplingsmönster
Följande avsnitt innehåller exempelfrågor som markerar vanliga kopplingsmönster för jobbsystemtabeller.
Ansluta till tidslinjetabeller för jobb och jobbkörning
Berika jobbkörningen med ett jobbnamn
with jobs as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, job_id ORDER BY change_time DESC) as rn
FROM system.lakeflow.jobs QUALIFY rn=1
)
SELECT
job_run_timeline.*
jobs.name
FROM system.lakeflow.job_run_timeline
LEFT JOIN jobs USING (workspace_id, job_id)
Gå med i tidslinjen för jobbkörningar och användningstabellerna
Berika varje faktureringslogg med jobbkörningsmetadata
SELECT
t1.*,
t2.*
FROM system.billing.usage t1
LEFT JOIN system.lakeflow.job_run_timeline t2
ON t1.workspace_id = t2.workspace_id
AND t1.usage_metadata.job_id = t2.job_id
AND t1.usage_metadata.job_run_id = t2.run_id
AND t1.usage_start_time >= date_trunc("Hour", t2.period_start_time)
AND t1.usage_start_time < date_trunc("Hour", t2.period_end_time) + INTERVAL 1 HOUR
WHERE
billing_origin_product="JOBS"
Beräkna kostnad per jobbkörning
Den här frågan ansluter till systemtabellen billing.usage för att beräkna en kostnad per jobbkörning.
with jobs_usage AS (
SELECT
*,
usage_metadata.job_id,
usage_metadata.job_run_id as run_id,
identity_metadata.run_as as run_as
FROM system.billing.usage
WHERE billing_origin_product="JOBS"
),
jobs_usage_with_usd AS (
SELECT
jobs_usage.*,
usage_quantity * pricing.default as usage_usd
FROM jobs_usage
LEFT JOIN system.billing.list_prices pricing ON
jobs_usage.sku_name = pricing.sku_name
AND pricing.price_start_time <= jobs_usage.usage_start_time
AND (pricing.price_end_time >= jobs_usage.usage_start_time OR pricing.price_end_time IS NULL)
AND pricing.currency_code="USD"
),
jobs_usage_aggregated AS (
SELECT
workspace_id,
job_id,
run_id,
FIRST(run_as, TRUE) as run_as,
sku_name,
SUM(usage_usd) as usage_usd,
SUM(usage_quantity) as usage_quantity
FROM jobs_usage_with_usd
GROUP BY ALL
)
SELECT
t1.*,
MIN(period_start_time) as run_start_time,
MAX(period_end_time) as run_end_time,
FIRST(result_state, TRUE) as result_state
FROM jobs_usage_aggregated t1
LEFT JOIN system.lakeflow.job_run_timeline t2 USING (workspace_id, job_id, run_id)
GROUP BY ALL
ORDER BY usage_usd DESC
LIMIT 100
Hämta användningsloggar för ett SUBMIT_RUN jobb
SELECT
*
FROM system.billing.usage
WHERE
EXISTS (
SELECT 1
FROM system.lakeflow.job_run_timeline
WHERE
job_run_timeline.job_id = usage_metadata.job_id
AND run_name = :run_name
AND workspace_id = :workspace_id
)
Anslut till tidslinjen för körning av arbetsuppgifter och klustertabeller
Enrich-jobbaktivitet körs med klustermetadata
with clusters as (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters QUALIFY rn=1
),
exploded_task_runs AS (
SELECT
*,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE array_size(compute_ids) > 0
)
SELECT
exploded_task_runs.*,
clusters.*
FROM exploded_task_runs t1
LEFT JOIN clusters t2
USING (workspace_id, cluster_id)
Hitta jobb som körs på allmän beräkningsmiljö
Den här frågan ansluter till systemtabellen compute.clusters för att returnera de senaste jobben som körs på all-purpose compute i stället för jobbberäkning.
with clusters AS (
SELECT
*,
ROW_NUMBER() OVER(PARTITION BY workspace_id, cluster_id ORDER BY change_time DESC) as rn
FROM system.compute.clusters
WHERE cluster_source="UI" OR cluster_source="API"
QUALIFY rn=1
),
job_tasks_exploded AS (
SELECT
workspace_id,
job_id,
EXPLODE(compute_ids) as cluster_id
FROM system.lakeflow.job_task_run_timeline
WHERE period_start_time >= CURRENT_DATE() - INTERVAL 30 DAY
GROUP BY ALL
),
all_purpose_cluster_jobs AS (
SELECT
t1.*,
t2.cluster_name,
t2.owned_by,
t2.dbr_version
FROM job_tasks_exploded t1
INNER JOIN clusters t2 USING (workspace_id, cluster_id)
)
SELECT * FROM all_purpose_cluster_jobs LIMIT 10;
Instrumentpanel för jobbövervakning
Följande instrumentpanel använder systemtabeller för att hjälpa dig att komma igång med att övervaka dina jobb och driftshälsa. Den innehåller vanliga användningsfall som spårning av jobbprestanda, felövervakning och resursanvändning.
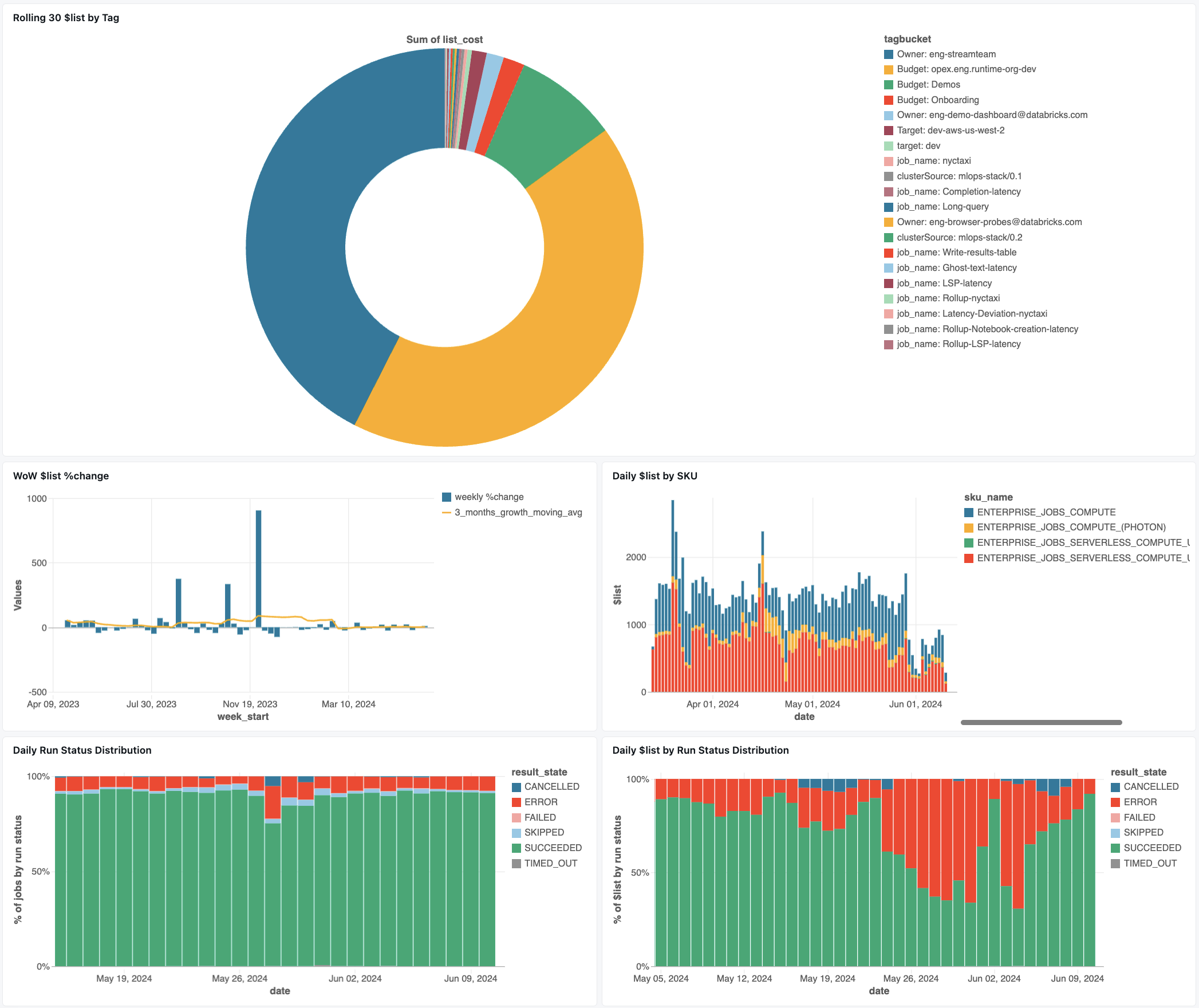
För information om hur du laddar ner instrumentpanelen, se Övervaka jobbkostnader & och prestanda med systemtabeller.
Felsökning
Jobbprocessen loggas inte i den specifika tabellen lakeflow.jobs
Om ett jobb inte visas i systemtabellerna:
- Jobbet har inte ändrats under de senaste 365 dagarna
- Ändra något av jobbets fält som finns i schemat för att generera en ny post.
- Jobbet skapades i en annan region
- Senaste jobbskapande (tabellfördröjning)
Det går inte att hitta ett jobb som visas i job_run_timeline tabellen
Alla jobbkörningar visas inte överallt. Även om JOB_RUN-poster visas i alla jobbrelaterade tabeller, registreras WORKFLOW_RUN (körningar av notebook-arbetsflöden) endast i job_run_timeline och SUBMIT_RUN (körningar som skickas en gång) registreras endast i tidslinjetabellerna. Dessa körningar fylls inte i andra jobbsystemtabeller som jobs eller job_tasks.
Se tabellen Körningstyper nedan för en detaljerad uppdelning av var varje typ av körning kan ses och nås.
Jobbet syns inte i billing.usage tabellen
I system.billing.usagefylls usage_metadata.job_id bara i för jobb som körs på jobbberäkning eller serverlös beräkning.
Dessutom har WORKFLOW_RUN jobb inte egna usage_metadata.job_id eller usage_metadata.job_run_id tilldelning i system.billing.usage.
I stället hänförs deras beräkningsanvändning till den överordnade anteckningsboken som utlöste dem.
Det innebär att när en notebook-fil startar en arbetsflödeskörning visas alla beräkningskostnader under den överordnade notebook-filens användning, inte som ett separat arbetsflödesjobb.
Mer information finns i -referensen för användningsmetadata.
Beräkna kostnaden för ett jobb som körs på universell datorkraft
Precis kostnadsberäkning för jobb som körs på specialanpassad beräkning är inte möjlig med 100% noggrannhet. När ett jobb körs på en interaktiv (all-purpose) beräkning körs ofta flera arbetsbelastningar som notebook-filer, SQL-frågor eller andra jobb samtidigt på samma beräkningsresurs. Eftersom klusterresurserna delas finns det ingen direkt 1:1-mappning mellan beräkningskostnader och enskilda jobbkörningar.
För korrekt jobbkostnadsspårning rekommenderar Databricks att du kör jobb på dedikerad jobbberäkning eller serverlös beräkning, där usage_metadata.job_id och usage_metadata.job_run_id möjliggör exakt kostnadsattribution.
Om du måste använda all-purpose compute kan du:
- Övervaka övergripande klusteranvändning och kostnader i
system.billing.usagebaserat påusage_metadata.cluster_id. - Spåra jobbkörningsmetrik separat.
- Tänk på att alla kostnadsuppskattningar kommer att vara ungefärliga på grund av delade resurser.
Mer information om kostnadstillskrivning finns i referens för användningsmetadata.
Referensvärden
Följande avsnitt innehåller referenser för utvalda kolumner i jobbrelaterade tabeller.
utlösartypsvärden
I tabellen job_run_timeline är de möjliga värdena för trigger_type kolumnen:
CONTINUOUSCRONFILE_ARRIVALONETIMEONETIME_RETRY
Kör typvärden
I tabellen job_run_timeline är de möjliga värdena för run_type kolumnen:
| Typ | beskrivning | UI-läge | API-slutpunkt | Systemtabeller |
|---|---|---|---|---|
JOB_RUN |
Standardjobbutförande | Jobb & jobb kör användargränssnittet | /jobs och /jobs/runs ändpunkter | jobb, arbetsuppgifter, tidplan för jobbkörning, tidplan för körning av arbetsuppgift |
SUBMIT_RUN |
Engångskörning via POST /jobs/runs/submit | Endast jobbkörningsanvändargränssnittet | /jobs/runs endpoints endast | jobbkörningstidslinje, uppdragens tidslinje |
WORKFLOW_RUN |
Kör initierat från notebook-arbetsflöde | Inte synlig | Inte tillgänglig | Tidslinje för jobbkörning |
Resultatstatusvärden
I tabellerna job_task_run_timeline och job_run_timeline är möjliga värden för result_state kolumnen:
| Stat | beskrivning |
|---|---|
SUCCEEDED |
Körningen har slutförts framgångsrikt |
FAILED |
Körningen slutfördes med ett fel |
SKIPPED |
Körningen utfördes aldrig eftersom en villkorsregel inte var uppfylld |
CANCELLED |
Körningen avbröts på användarens begäran |
TIMED_OUT |
Körningen stoppades efter att tidsgränsen nåtts |
ERROR |
Körningen slutfördes med ett fel |
BLOCKED |
Körningen blockerades på grund av ett uppströmsberoende |
Avslutningskodvärden
I tabellerna job_task_run_timeline och job_run_timeline är möjliga värden för termination_code kolumnen:
| Avslutningskod | beskrivning |
|---|---|
SUCCESS |
Körningen har slutförts |
CANCELLED |
Körningen avbröts av Databricks-plattformen under utförandet, till exempel om den maximala körningstiden överskreds. |
SKIPPED |
Körningen utfördes aldrig, till exempel om den föregående aktivitetskörningen misslyckades, beroendevillkoret inte uppfylldes eller om det inte fanns några aktuella uppgifter att köra |
DRIVER_ERROR |
Körningen påträffade ett fel när den kommunicerade med Spark-drivrutinen |
CLUSTER_ERROR |
Körningen misslyckades på grund av ett klusterproblem |
REPOSITORY_CHECKOUT_FAILED |
Det gick inte att slutföra utcheckningen på grund av ett fel vid kommunikation med tjänsten från tredje part |
INVALID_CLUSTER_REQUEST |
Körningen misslyckades eftersom den skickade en ogiltig begäran om att starta klustret |
WORKSPACE_RUN_LIMIT_EXCEEDED |
Arbetsytan har nått kvoten för maximalt antal samtidiga aktiva processer. Överväg att schemalägga körningarna över en större tidsram |
FEATURE_DISABLED |
Körningen misslyckades eftersom den försökte komma åt en funktionalitet som inte är tillgänglig för arbetsytan |
CLUSTER_REQUEST_LIMIT_EXCEEDED |
Antalet begäranden om att skapa, starta och utvidga kluster har överskridit den tilldelade hastighetsgränsen. Överväg att sprida körningens genomförande över en större tidsram |
STORAGE_ACCESS_ERROR |
Körningen misslyckades på grund av ett fel vid åtkomst till kundens bloblagringssystem |
RUN_EXECUTION_ERROR |
Körningen slutfördes med aktivitetsfel |
UNAUTHORIZED_ERROR |
Körningen misslyckades på grund av ett behörighetsproblem vid åtkomst till en resurs |
LIBRARY_INSTALLATION_ERROR |
Körningen misslyckades när det användar begärda biblioteket skulle installeras. Orsakerna kan vara, men är inte begränsade till: Det angivna biblioteket är ogiltigt, det finns inte tillräckliga behörigheter för att installera biblioteket och så vidare |
MAX_CONCURRENT_RUNS_EXCEEDED |
Den schemalagda körningen överskrider gränsen för maximala samtidiga körningar som angetts för jobbet |
MAX_SPARK_CONTEXTS_EXCEEDED |
Körningen är schemalagd i ett kluster som redan har nått det maximala antalet kontexter som den har konfigurerats för att skapa |
RESOURCE_NOT_FOUND |
En resurs som krävs för körningens genomförande finns inte |
INVALID_RUN_CONFIGURATION |
Körningen misslyckades på grund av en ogiltig konfiguration |
CLOUD_FAILURE |
Körningen misslyckades på grund av ett problem med molnleverantören |
MAX_JOB_QUEUE_SIZE_EXCEEDED |
Körningen hoppades över på grund av att köstorleksgränsen på jobbnivå nåddes |
Värden för pipelinetyp
I tabellen pipelines är de möjliga värdena för pipeline_type kolumnen:
| Typ av pipeline | beskrivning |
|---|---|
ETL_PIPELINE |
Standardpipeline |
MATERIALIZED_VIEW |
Materialiserade vyer i Databricks SQL |
STREAMING_TABLE |
Strömmande tabeller i Databricks SQL |
INGESTION_PIPELINE |
Lakeflow Connect Ingestor |
INGESTION_GATEWAY |
Ingestor för Lakeflow Connect-gateway |
Referens för pipelineinställningar
I tabellen pipelines är de möjliga värdena för settings kolumnen:
| Värde | beskrivning |
|---|---|
photon |
En flagga som anger om du vill använda Photon för att köra pipelinen |
development |
En flagga som anger om pipelinen ska köras i utvecklings- eller produktionsläge |
continuous |
En flagga som anger om pipelinen ska köras kontinuerligt |
serverless |
En flagga som anger om pipelinen ska köras på ett serverlöst kluster |
edition |
Produktutgåvan som ska köra pipelinen |
channel |
Den version av pipelinekörningen som ska användas |