Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Lär dig hur du orkestrerar notebook-filer och modulariserar kod i notebook-filer. Se exempel och förstå när man ska använda alternativa metoder för notebook-orkestrering.
Orkestrerings- och kod modulariseringsmetoder
I följande tabell jämförs de metoder som är tillgängliga för att orkestrera notebook-filer och modularisera kod i notebook-filer.
| Metod | Användningsfall | Anteckningar |
|---|---|---|
| Lakeflow-jobb | Orkestrering av notebook-filer (rekommenderas) | Rekommenderad metod för att orkestrera notebook-filer. Stöder komplexa arbetsflöden med aktivitetsberoenden, schemaläggning och utlösare. Tillhandahåller en robust och skalbar metod för produktionsarbetsbelastningar, men kräver installation och konfiguration. |
| dbutils.notebook.run() | Orkestrering av notebook-filer | Använd dbutils.notebook.run() om Jobb inte kan stödja ditt användningsfall, till exempel loopa notebook-filer över en dynamisk uppsättning parametrar.Startar ett nytt tillfälliga jobb för varje anrop, vilket kan öka omkostnaderna och saknar avancerade schemaläggningsfunktioner. |
| arbetsrumsfiler | Kod modularisering (rekommenderas) | Rekommenderad metod för modularisering av kod. Modularisera kod till återanvändbara kodfiler som lagras på arbetsytan. Stöder versionskontroll med lagringsplatser och integrering med IDE:er för bättre felsökning och enhetstestning. Kräver ytterligare installation för att hantera filsökvägar och beroenden. |
| %run | Kod modularisering | Använd %run om du inte kan komma åt arbetsytefiler.Importera funktioner eller variabler från andra notebook-filer genom att köra dem direkt. Användbart för prototyper men kan leda till tätt kopplad kod som är svårare att underhålla. Stöder inte parameteröverföring eller versionskontroll. |
%run jämfört med dbutils.notebook.run()
Med %run-kommandot kan du inkludera en annan notebook i en notebook. Du kan använda %run för att modularisera koden genom att placera stödfunktioner i en separat notebook-fil. Du kan också använda den för att sammanfoga notebook-filer som implementerar stegen i en analys. När du använder %runkörs den anropade notebook-filen omedelbart och de funktioner och variabler som definieras i den blir tillgängliga i den anropande notebook-filen.
dbutils.notebook-API:et kompletterar %run eftersom du kan skicka parametrar till och returnera värden från en notebook-fil. På så sätt kan du skapa komplexa arbetsflöden och pipelines med beroenden. Du kan till exempel hämta en lista över filer i en katalog och skicka namnen till en annan anteckningsbok, vilket är omöjligt med %run. Du kan också skapa if-then-else-arbetsflöden baserat på returvärden.
Till skillnad från %run startar dbutils.notebook.run()-metoden ett nytt jobb för att köra notebook-filen.
Precis som alla API:er för dbutils är dessa metoder endast tillgängliga i Python och Scala. Du kan dock använda dbutils.notebook.run() för att anropa en R-notebook-fil.
Använd %run för att importera en notebook
I det här exemplet definierar den första notebook-filen en funktion, reverse, som är tillgänglig i den andra notebook-filen när du använder magin %run för att köra shared-code-notebook.

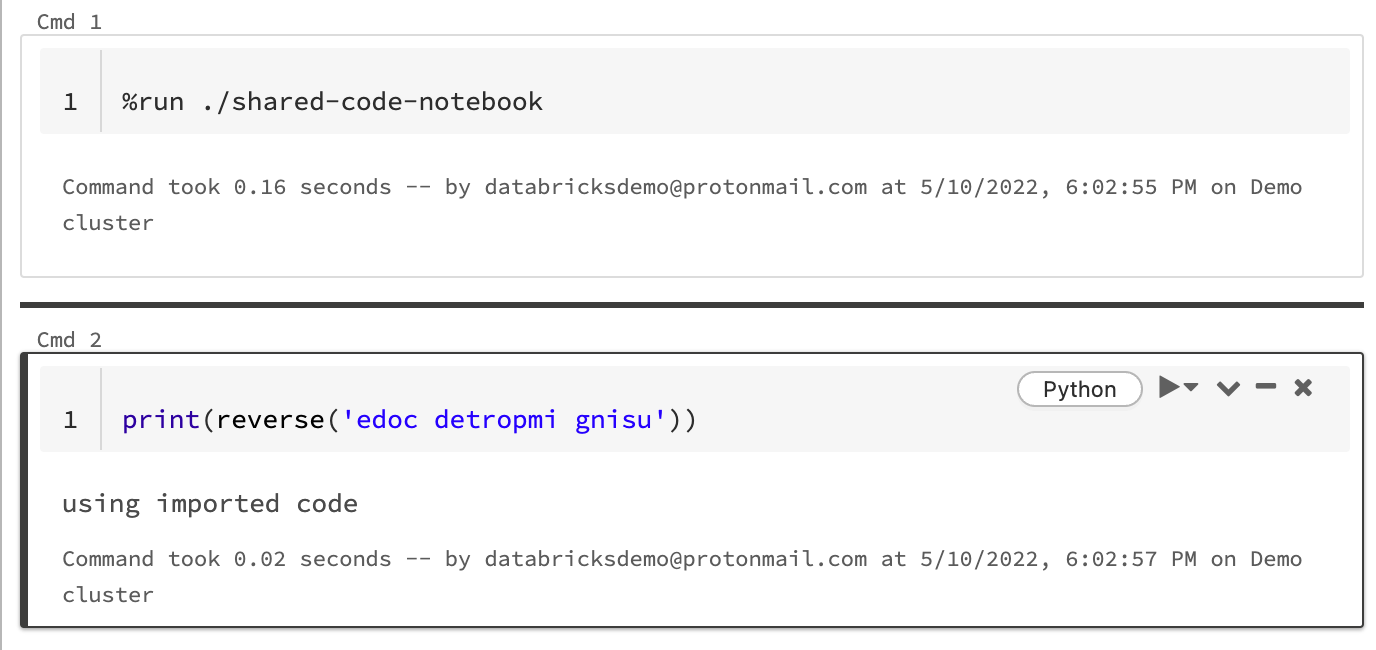
Eftersom båda notebook-filerna finns i samma katalog på arbetsytan använder du prefixet ./ i ./shared-code-notebook för att ange att sökvägen ska matchas i förhållande till den notebook-fil som körs. Du kan ordna notebook-filer i kataloger, till exempel %run ./dir/notebook, eller använda en absolut sökväg som %run /Users/username@organization.com/directory/notebook.
Kommentar
-
%runmåste vara i en cell ensam, eftersom den kör hela notebooken inline. - Du kan inte använda
%runför att köra en Python-fil ochimportimportera de entiteter som definierats i den filen i en notebook. Om du vill importera från en Python fil kan du läsa Modularisera koden med hjälp av filer. Du kan också paketera filen i ett Python bibliotek, skapa en Azure Databricks library från det Python biblioteket och installera biblioteket i klustret som du använder för att köra anteckningsboken. - När du använder
%runför att köra en notebook-fil som innehåller widgetar körs som standard den angivna notebook-filen med widgetens standardvärden. Du kan också skicka värden till widgetar. Se Använda Databricks-widgetar med %run.
Använda dbutils.notebook.run för att starta ett nytt jobb
Kör en notebook-fil och returnera dess slutvärde. Metoden startar ett tillfälliga jobb som körs omedelbart.
De metoder som är tillgängliga i API:et dbutils.notebook är run och exit. Både parametrar och returvärden måste vara strängar.
run(path: String, timeout_seconds: int, arguments: Map): String
Parametern timeout_seconds styr tidsgränsen för körningen (0 innebär ingen tidsgräns). Anropet till run utlöser ett undantag om det inte slutförs inom den angivna tiden. Om Azure Databricks är nere i mer än 10 minuter misslyckas notebook-körningen oavsett timeout_seconds.
Parametern arguments anger widgetvärden för den målanpassade anteckningsboken. Specifikt, om noteboken du kör har en widget med namnet A, och du skickar ett nyckel-värde-par ("A": "B") som en del av argumentparametern vid anropet run(), då kommer hämtningen av värdet för widget A att returnera "B". Du hittar instruktionerna för att skapa och arbeta med widgetar på sidan Med Databricks-widgetar .
Kommentar
- Parametern
argumentsaccepterar endast latinska tecken (ASCII-teckenuppsättning). Om du använder icke-ASCII-tecken returneras ett fel. - Jobb som skapas med hjälp av API:et
dbutils.notebookmåste slutföras om 30 dagar eller mindre.
run Användning
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Skicka strukturerade data mellan notebook-filer
Det här avsnittet visar hur du skickar strukturerade data mellan notebook-filer.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Hantera felmeddelanden
Det här avsnittet visar hur du hanterar fel.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Köra flera anteckningsböcker samtidigt
Du kan köra flera notebook-filer samtidigt med hjälp av standardkonstruktionerna Scala och Python, till exempel Trådar (Scala, Python) och futures (Scala, Python). Exempelanteckningsböckerna visar hur du använder dessa konstruktioner.
- Ladda ner följande fyra anteckningsböcker. Notebook-filerna är skrivna i Scala.
- Importera anteckningsböckerna till en enda mapp på arbetsytan.
- Kör anteckningsboken Kör samtidigt .