Regelverk för Unity-katalog
Det här dokumentet innehåller rekommendationer för att använda Unity Catalog och Delta Sharing för att uppfylla dina datastyrningsbehov.
Unity Catalog är en detaljerad styrningslösning för data och AI på Databricks-plattformen. Det förenklar säkerheten och styrningen av dina data genom att tillhandahålla en central plats för att administrera och granska dataåtkomst. Deltadelning är en säker datadelningsplattform som gör att du kan dela data i Azure Databricks med användare utanför organisationen. Den använder Unity Catalog för att hantera och granska delningsbeteende.
Byggstenar för datastyrning och dataisolering
Om du vill utveckla en datastyrningsmodell och en dataisoleringsplan som fungerar för din organisation hjälper det dig att förstå de primära byggstenar som är tillgängliga för dig när du skapar din datastyrningslösning i Azure Databricks.
Följande diagram illustrerar den primära datahierarkin i Unity Catalog (vissa skyddsbara objekt är nedtonade för att framhäva hierarkin för objekt som hanteras under kataloger).
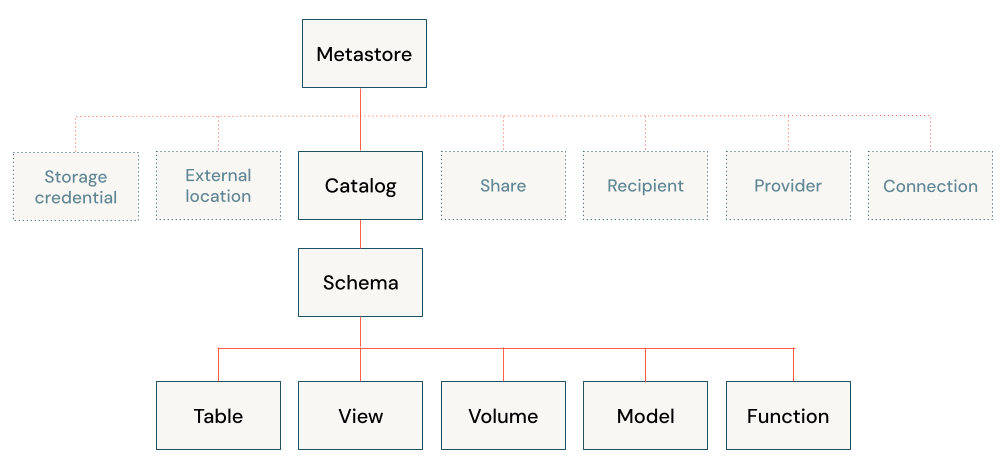
Objekten i hierarkin innehåller följande:
Metaarkiv: Ett metaarkiv är den översta containern för objekt i Unity Catalog. Metaarkiven finns på kontonivå och fungerar överst i pyramiden i Azure Databricks-datastyrningsmodellen.
Metaarkiv hanterar datatillgångar (tabeller, vyer och volymer) och de behörigheter som styr åtkomsten till dem. Azure Databricks-kontoadministratörer kan skapa ett metaarkiv för varje region där de arbetar och tilldela dem till flera Azure Databricks-arbetsytor i samma region. Metaarkivadministratörer kan hantera alla objekt i metaarkivet. De har inte direkt åtkomst till att läsa och skriva till tabeller som är registrerade i metaarkivet, men de har indirekt åtkomst genom sin möjlighet att överföra ägarskap för dataobjekt.
Fysisk lagring för ett visst metaarkiv är som standard isolerat från lagring för alla andra metaarkiv i ditt konto.
Metaarkiv tillhandahåller regional isolering men är inte avsedda som enheter för dataisolering. Dataisolering bör börja på katalognivå.
Katalog: Kataloger är den högsta nivån i datahierarkin (katalogschematabell >> /vy/volym) som hanteras av Unity Catalog-metaarkivet. De är avsedda som den primära enheten för dataisolering i en typisk Azure Databricks-datastyrningsmodell.
Kataloger representerar en logisk gruppering av scheman, som vanligtvis begränsas av dataåtkomstkrav. Kataloger speglar ofta organisationsenheter eller livscykelomfattningar för programvaruutveckling. Du kan till exempel välja att ha en katalog för produktionsdata och en katalog för utvecklingsdata, eller en katalog för icke-kunddata och en katalog för känsliga kunddata.
Kataloger kan lagras på metaarkivnivå, eller så kan du konfigurera en katalog som ska lagras separat från resten av det överordnade metaarkivet. Om din arbetsyta aktiverades automatiskt för Unity Catalog finns det ingen lagring på metaarkivnivå och du måste ange en lagringsplats när du skapar en katalog.
Om katalogen är den primära enheten för dataisolering i Azure Databricks-datastyrningsmodellen är arbetsytan den primära miljön för att arbeta med datatillgångar. Metaarkivadministratörer och katalogägare kan hantera åtkomst till kataloger oberoende av arbetsytor, eller så kan de binda kataloger till specifika arbetsytor för att säkerställa att vissa typer av data endast bearbetas på dessa arbetsytor. Du kanske vill ha separata arbetsytor för produktion och utveckling, till exempel eller en separat arbetsyta för bearbetning av personliga data.
Som standard ärvs åtkomstbehörigheter för ett skyddsbart objekt av underordnade objekt, med kataloger överst i hierarkin. Detta gör det enklare att konfigurera standardåtkomstregler för dina data och att ange olika regler på varje nivå i hierarkin bara där du behöver dem.
Schema (databas): Scheman, även kallade databaser, är logiska grupper av tabelldata (tabeller och vyer), icke-tabelldata (volymer), funktioner och maskininlärningsmodeller. De ger dig ett sätt att organisera och kontrollera åtkomsten till data som är mer detaljerad än kataloger. Vanligtvis representerar de ett enskilt användningsfall, ett projekt eller en sandbox-miljö för teamet.
Scheman kan lagras i samma fysiska lagring som den överordnade katalogen, eller så kan du konfigurera ett schema som ska lagras separat från resten av den överordnade katalogen.
Metaarkivadministratörer, överordnade katalogägare och schemaägare kan hantera åtkomst till scheman.
Tabeller: Tabeller finns i det tredje lagret i Unity Catalogs namnområde på tre nivåer. De innehåller rader med data.
Med Unity Catalog kan du skapa hanterade tabeller och externa tabeller.
För hanterade tabeller hanterar Unity Catalog helt livscykeln och fillayouten. Som standard lagras hanterade tabeller på den rotlagringsplats som du konfigurerar när du skapar ett metaarkiv. Du kan i stället välja att isolera lagring för hanterade tabeller på katalog- eller schemanivå.
Externa tabeller är tabeller vars datalivscykel och fillayout hanteras med hjälp av din molnleverantör och andra dataplattformar, inte Unity Catalog. Vanligtvis använder du externa tabeller för att registrera stora mängder av dina befintliga data, eller om du också behöver skrivåtkomst till data med hjälp av verktyg utanför Azure Databricks-kluster och Databricks SQL-lager. När en extern tabell har registrerats i ett Unity Catalog-metaarkiv kan du hantera och granska Åtkomst till Azure Databricks precis som med hanterade tabeller.
Överordnade katalogägare och schemaägare kan hantera åtkomst till tabeller, liksom metaarkivadministratörer (indirekt).
Vyer: En vy är ett skrivskyddat objekt som härleds från en eller flera tabeller och vyer i ett metaarkiv.
Rader och kolumner: Åtkomst på rad- och kolumnnivå, tillsammans med datamaskering, beviljas med antingen dynamiska vyer eller radfilter och kolumnmasker. Dynamiska vyer är skrivskyddade.
Volymer: Volymer finns i det tredje lagret i Unity Catalogs namnområde på tre nivåer. De hanterar data som inte är tabellbaserade. Du kan använda volymer för att lagra, organisera och komma åt filer i valfritt format, inklusive strukturerade, halvstrukturerade och ostrukturerade data. Filer i volymer kan inte registreras som tabeller.
Modeller och funktioner: Även om de inte är datatillgångar, registrerade modeller och användardefinierade funktioner kan de även hanteras i Unity Catalog och finnas på den lägsta nivån i objekthierarkin. Se Hantera modelllivscykel i Unity Catalog och användardefinierade funktioner (UDF:er) i Unity Catalog.
Planera din dataisoleringsmodell
När en organisation använder en dataplattform som Azure Databricks finns det ofta ett behov av att ha gränser för dataisolering mellan miljöer (till exempel utveckling och produktion) eller mellan organisationens operativa enheter.
Isoleringsstandarderna kan variera för din organisation, men vanligtvis innehåller de följande förväntningar:
- Användare kan bara få åtkomst till data baserat på angivna åtkomstregler.
- Data kan endast hanteras av utsedda personer eller team.
- Data separeras fysiskt i lagringen.
- Data kan endast nås i angivna miljöer.
Behovet av dataisolering kan leda till silobaserade miljöer som kan göra både datastyrning och samarbete onödigt svårt. Azure Databricks löser det här problemet med hjälp av Unity Catalog, som tillhandahåller ett antal alternativ för dataisolering samtidigt som en enhetlig datastyrningsplattform upprätthålls. I det här avsnittet beskrivs de tillgängliga alternativen för dataisolering i Azure Databricks och hur du använder dem, oavsett om du föredrar en centraliserad datastyrningsmodell eller en distribuerad modell.
Användare kan bara få åtkomst till data baserat på angivna åtkomstregler
De flesta organisationer har strikta krav på dataåtkomst baserat på interna eller regelmässiga krav. Vanliga exempel på data som måste hållas säkra är information om anställdas lön eller kreditkortsbetalningsinformation. Åtkomst till den här typen av information kontrolleras vanligtvis noggrant och granskas regelbundet. Unity Catalog ger dig detaljerad kontroll över datatillgångar i katalogen för att uppfylla dessa branschstandarder. Med de kontroller som Unity Catalog tillhandahåller kan användarna bara se och fråga efter de data som de har rätt att se och fråga.
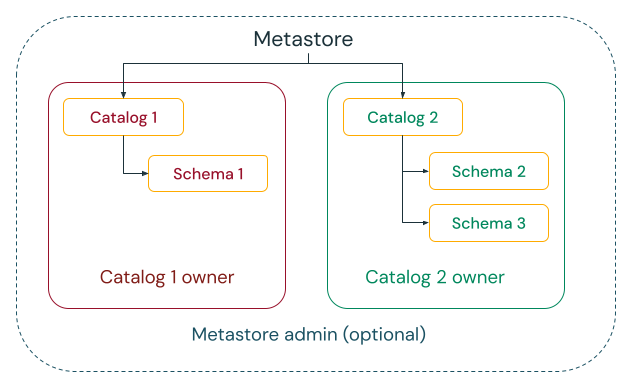
Data kan endast hanteras av utsedda personer eller team
Unity Catalog ger dig möjlighet att välja mellan centraliserade och distribuerade styrningsmodeller.
I den centraliserade styrningsmodellen är dina styrningsadministratörer ägare av metaarkivet och kan ta över ägarskapet för alla objekt och bevilja och återkalla behörigheter.
I en distribuerad styrningsmodell är katalogen eller en uppsättning kataloger datadomänen. Ägaren av katalogen kan skapa och äga alla tillgångar och hantera styrning inom domänen. Ägarna till en viss domän kan fungera oberoende av ägarna till andra domäner.
Oavsett om du väljer metaarkivet eller katalogerna som datadomän rekommenderar Databricks starkt att du anger en grupp som metaarkivadministratör eller katalogägare.
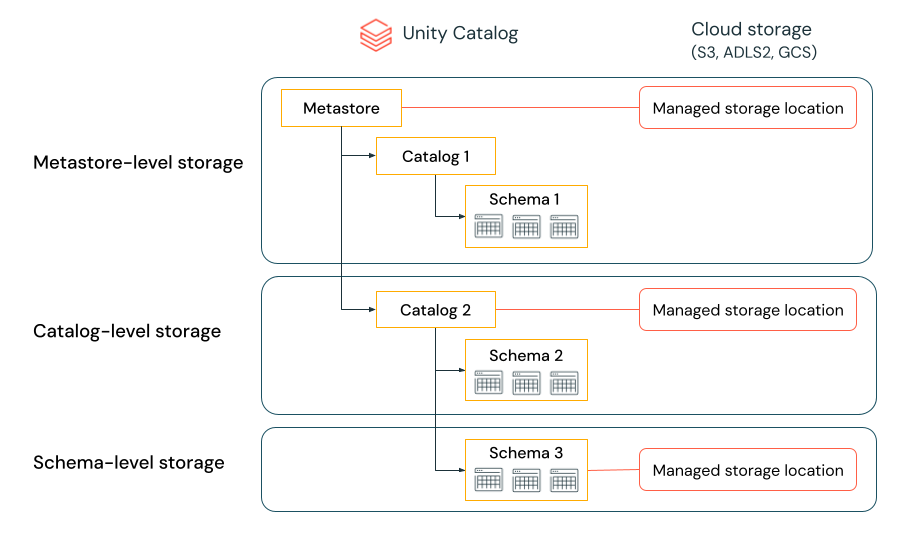
Data separeras fysiskt i lagring
En organisation kan kräva att data av vissa typer lagras i specifika konton eller bucketar i deras molnklientorganisation.
Unity Catalog ger möjlighet att konfigurera lagringsplatser på metaarkiv-, katalog- eller schemanivå för att uppfylla sådana krav.
Anta till exempel att din organisation har en efterlevnadsprincip för företaget som kräver att produktionsdata som rör personal finns i containern abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net. I Unity Catalog kan du uppnå det här kravet genom att ange en plats på katalognivå, skapa en katalog med namnet, till exempel hr_prod, och tilldela platsen abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net/unity-catalog till den. Det innebär att hanterade tabeller eller volymer som skapats i hr_prod katalogen (till exempel med hjälp av CREATE TABLE hr_prod.default.table …) lagrar sina data i abfss://mycompany-hr-prod@storage-account.dfs.core.windows.net/unity-catalog. Du kan också välja att ange platser på schemanivå för att organisera data på hr_prod catalog en mer detaljerad nivå.
Om en sådan lagringsisolering inte krävs kan du ange en lagringsplats på metaarkivnivå. Resultatet är att den här platsen fungerar som en standardplats för att lagra hanterade tabeller och volymer i kataloger och scheman i metaarkivet.
Systemet utvärderar hierarkin för lagringsplatser från schema till katalog till metaarkiv.
Om en tabell myCatalog.mySchema.myTable till exempel skapas i my-region-metastorebestäms lagringsplatsen för tabellen enligt följande regel:
- Om en plats har angetts för
mySchemalagras den där. - Om inte, och en plats har angetts på
myCatalog, lagras den där. - Om ingen plats har angetts på lagras den slutligen på
myCatalogden plats som är associerad medmy-region-metastore.
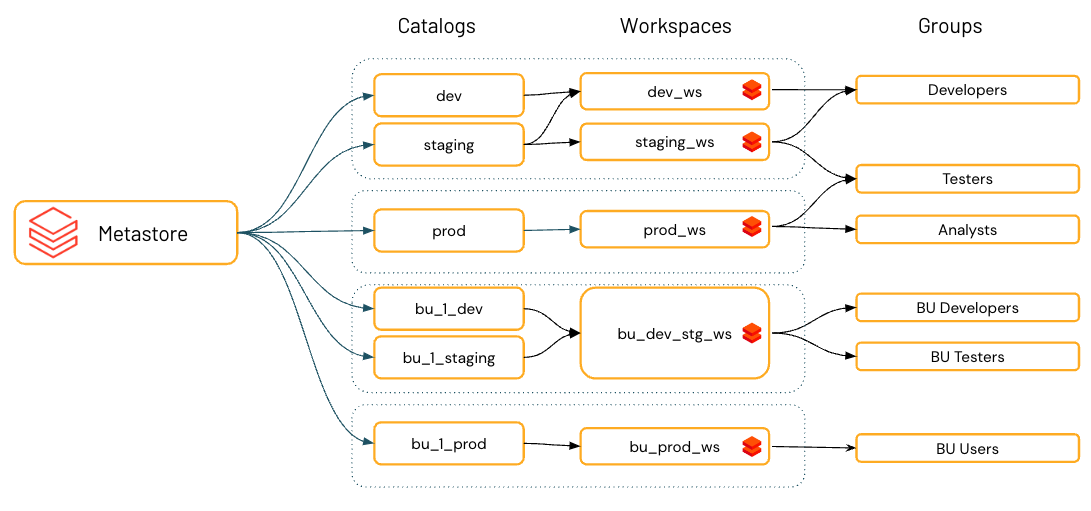
Data kan endast nås i avsedda miljöer
Organisations- och efterlevnadskrav anger ofta att du behåller vissa data, till exempel personliga data, endast tillgängliga i vissa miljöer. Du kanske också vill hålla produktionsdata isolerade från utvecklingsmiljöer eller se till att vissa datauppsättningar och domäner aldrig kopplas samman.
I Databricks är arbetsytan den primära databearbetningsmiljön och kataloger är den primära datadomänen. Unity Catalog låter metaarkivadministratörer och katalogägare tilldela, eller "binda", kataloger till specifika arbetsytor. Dessa miljömedvetna bindningar ger dig möjlighet att se till att endast vissa kataloger är tillgängliga på en arbetsyta, oavsett de specifika behörigheterna för dataobjekt som beviljas en användare.
Nu ska vi titta närmare på processen med att konfigurera Unity Catalog för att uppfylla dina behov.
Konfigurera ett Unity Catalog-metaarkiv
Ett metaarkiv är den översta containern för objekt i Unity Catalog. Metaarkiv hanterar datatillgångar (tabeller, vyer och volymer) samt andra skyddsbara objekt som hanteras av Unity Catalog. En fullständig lista över skyddsbara objekt finns i Skyddsbara objekt i Unity Catalog.
Det här avsnittet innehåller tips för att skapa och konfigurera metaarkiv. Om din arbetsyta aktiverades automatiskt för Unity Catalog behöver du inte skapa ett metaarkiv, men informationen som visas i det här avsnittet kan fortfarande vara användbar. Se Automatisk aktivering av Unity Catalog.
Tips för att konfigurera metaarkiv:
Du bör konfigurera ett metaarkiv för varje region där du har Azure Databricks-arbetsytor.
Varje arbetsyta som är kopplad till ett enda regionalt metaarkiv har åtkomst till de data som hanteras av metaarkivet. Om du vill dela data mellan metaarkiv använder du Deltadelning.
Varje metaarkiv kan konfigureras med en hanterad lagringsplats (kallas även rotlagring) i molnklientorganisationen som kan användas för att lagra hanterade tabeller och hanterade volymer.
Om du väljer att skapa en hanterad plats på metaarkivnivå måste du se till att inga användare har direkt åtkomst till den (det vill: via det molnkonto som innehåller den). Att ge åtkomst till den här lagringsplatsen kan göra det möjligt för en användare att kringgå åtkomstkontroller i ett Unity Catalog-metaarkiv och störa granskningsbarheten. Därför bör din hanterade lagring i metaarkivet vara en dedikerad container. Du bör inte återanvända en container som också är ditt DBFS-rotfilsystem eller tidigare har varit ett DBFS-rotfilsystem.
Du har också möjlighet att definiera hanterad lagring på katalog- och schemanivå, vilket överskrider metaarkivets rotlagringsplats. I de flesta scenarier rekommenderar Databricks att hanterade data lagras på katalognivå.
Du bör förstå behörigheterna för arbetsyteadministratörer på arbetsytor som är aktiverade för Unity Catalog och granska dina befintliga administratörstilldelningar för arbetsytan.
Arbetsyteadministratörer kan hantera åtgärder för sin arbetsyta, inklusive att lägga till användare och tjänstens huvudnamn, skapa kluster och delegera andra användare till arbetsyteadministratörer. Om din arbetsyta har aktiverats för Unity Catalog automatiskt kan arbetsyteadministratörer som standard skapa kataloger och många andra Unity Catalog-objekt. Se Administratörsbehörigheter för arbetsytor när arbetsytor aktiveras automatiskt för Unity Catalog
Arbetsyteadministratörer har också möjlighet att utföra hanteringsuppgifter för arbetsytor, till exempel att hantera jobbägarskap och visa notebook-filer, vilket kan ge indirekt åtkomst till data som registrerats i Unity Catalog. Arbetsyteadministratör är en privilegierad roll som du bör distribuera noggrant.
Om du använder arbetsytor för att isolera åtkomsten till användardata kanske du vill använda bindningar för arbetsytekatalogen. Med bindningar för arbetsytekataloger kan du begränsa katalogåtkomsten efter arbetsytegränser. Du kan till exempel se till att arbetsyteadministratörer och användare bara kan komma åt produktionsdata i
prod_catalogfrån en produktionsarbetsytemiljö,prod_workspace. Standardvärdet är att dela katalogen med alla arbetsytor som är kopplade till det aktuella metaarkivet. Se Begränsa katalogåtkomst till specifika arbetsytor.Om din arbetsyta aktiverades automatiskt för Unity Catalog är den företablerade arbetsytekatalogen bunden till din arbetsyta som standard.
Se Skapa ett Unity Catalog-metaarkiv.
Konfigurera externa platser och autentiseringsuppgifter för lagring
Med externa platser kan Unity Catalog läsa och skriva data i din molnklientorganisation för användarnas räkning. Externa platser definieras som en sökväg till molnlagring, kombinerat med en lagringsautentiseringsuppgift som kan användas för att komma åt den platsen.
Du kan använda externa platser för att registrera externa tabeller och externa volymer i Unity Catalog. Innehållet i dessa entiteter finns fysiskt på en undersökväg på en extern plats som refereras när en användare skapar volymen eller tabellen.
En lagringsautentiseringsuppgift kapslar in en långsiktig molnautentiseringsuppgift som ger åtkomst till molnlagring. Det kan antingen vara en Hanterad Azure-identitet (rekommenderas starkt) eller ett huvudnamn för tjänsten. Att använda en hanterad Azure-identitet har följande fördelar jämfört med att använda tjänstens huvudnamn:
- Hanterade identiteter kräver inte att du underhåller autentiseringsuppgifter eller roterar hemligheter.
- Om din Azure Databricks-arbetsyta distribueras till ditt eget virtuella nätverk (även kallat VNet-inmatning) kan du ansluta till ett Azure Data Lake Storage Gen2-konto som skyddas av en lagringsbrandvägg.
För ökad dataisolering kan du binda autentiseringsuppgifter för lagring och externa platser till specifika arbetsytor. Se (Valfritt) Tilldela en extern plats till specifika arbetsytor och (valfritt) Tilldela en lagringsautentiseringsuppgift till specifika arbetsytor.
Dricks
Externa platser ger stark kontroll och granskning av lagringsåtkomst genom att kombinera autentiseringsuppgifter för lagring och lagringssökvägar. För att förhindra att användare kringgår åtkomstkontrollen som tillhandahålls av Unity Catalog bör du se till att du begränsar antalet användare med direkt åtkomst till alla containrar som används som en extern plats. Av samma anledning bör du inte montera lagringskonton till DBFS om de också används som externa platser. Databricks rekommenderar att du migrerar monteringar på molnlagringsplatser till externa platser i Unity Catalog med hjälp av Catalog Explorer.
En lista över metodtips för att hantera externa platser finns i Hantera externa platser, externa tabeller och externa volymer. Se även Skapa en extern plats för att ansluta molnlagring till Azure Databricks.
Organisera dina data
Databricks rekommenderar att du använder kataloger för att tillhandahålla segregation i organisationens informationsarkitektur. Det innebär ofta att kataloger motsvarar en programutvecklingsmiljöomfattning, ett team eller en affärsenhet. Om du använder arbetsytor som ett dataisoleringsverktyg, till exempel med olika arbetsytor för produktions- och utvecklingsmiljöer eller en specifik arbetsyta för att arbeta med mycket känsliga data, kan du även binda en katalog till specifika arbetsytor. Detta säkerställer att all bearbetning av angivna data hanteras på rätt arbetsyta. Se Begränsa katalogåtkomst till specifika arbetsytor.
Ett schema (kallas även en databas) är det andra lagret i Unity Catalogs namnområde på tre nivåer och organiserar tabeller, vyer och volymer. Du kan använda scheman för att organisera och definiera behörigheter för dina tillgångar.
Objekt som styrs av Unity Catalog kan hanteras eller vara externa:
Hanterade objekt är standardsättet för att skapa dataobjekt i Unity Catalog.
Unity Catalog hanterar livscykeln och fillayouten för dessa skyddsbara objekt. Du bör inte använda verktyg utanför Azure Databricks för att ändra filer i hanterade tabeller eller volymer direkt.
Hanterade tabeller och volymer lagras i hanterad lagring, som kan finnas på metaarkiv-, katalog- eller schemanivå för en viss tabell eller volym. Se Data är fysiskt avgränsade i lagring.
Hanterade tabeller och volymer är en praktisk lösning när du vill etablera en styrd plats för ditt innehåll utan att behöva skapa och hantera externa platser och autentiseringsuppgifter för lagring.
Hanterade tabeller använder alltid deltatabellformatet .
Externa objekt är skyddsbara objekt vars datalivscykel och fillayout inte hanteras av Unity Catalog.
Externa volymer och tabeller registreras på en extern plats för att ge åtkomst till ett stort antal filer som redan finns i molnlagringen utan att datakopieringsaktivitet krävs. Använd externa objekt när du har filer som skapas av andra system och vill att de ska mellanlagras för åtkomst inifrån Azure Databricks, eller när verktyg utanför Azure Databricks kräver direkt åtkomst till dessa filer.
Externa tabeller stöder Delta Lake och många andra dataformat, inklusive Parquet, JSON och CSV. Både hanterade och externa volymer kan användas för att komma åt och lagra filer med godtyckliga format: data kan vara strukturerade, halvstrukturerade eller ostrukturerade.
Mer information om hur du skapar tabeller och volymer finns i Vad är en tabell? och Vad är Unity Catalog-volymer?.
Hantera externa platser, externa tabeller och externa volymer
Diagrammet nedan representerar filsystemhierarkin för en enda molnlagringscontainer, med fyra externa platser som delar en lagringsautentiseringsuppgift.

När du har konfigurerat externa platser i Unity Catalog kan du skapa externa tabeller och volymer på kataloger på de externa platserna. Du kan sedan använda Unity Catalog för att hantera användar- och gruppåtkomst till dessa tabeller och volymer. På så sätt kan du ge specifika användare eller grupper åtkomst till specifika kataloger och filer i molnlagringscontainern.
Kommentar
När du definierar en volym styrs moln-URI-åtkomst till data under volymsökvägen av volymens behörigheter.
Rekommendationer för att använda externa platser
Rekommendationer för att bevilja behörigheter på externa platser:
Ge möjligheten att endast skapa externa platser till en administratör som har till uppgift att konfigurera anslutningar mellan Unity Catalog och molnlagring, eller till betrodda datatekniker.
Externa platser ger åtkomst inifrån Unity Catalog till en brett omfattande plats i molnlagring, till exempel en hel bucket eller container (abfss://my-container@storage-account.dfs.core.windows.net) eller en bred undersökväg (abfss://my-container@storage-account.dfs.core.windows.net/sökväg/till/underkatalog). Avsikten är att en molnadministratör kan vara involverad i att konfigurera några externa platser och sedan delegera ansvaret för att hantera dessa platser till en Azure Databricks-administratör i din organisation. Azure Databricks-administratören kan sedan ytterligare organisera den externa platsen i områden med mer detaljerade behörigheter genom att registrera externa volymer eller externa tabeller med specifika prefix under den externa platsen.
Eftersom externa platser är så omfattande rekommenderar Databricks att endast ge
CREATE EXTERNAL LOCATIONbehörighet till en administratör som har till uppgift att konfigurera anslutningar mellan Unity Catalog och molnlagring eller till betrodda datatekniker. För att ge andra användare mer detaljerad åtkomst rekommenderar Databricks att du registrerar externa tabeller eller volymer ovanpå externa platser och ger användarna åtkomst till data med hjälp av volymer eller tabeller. Eftersom tabeller och volymer är underordnade till en katalog och ett schema har katalog- eller schemaadministratörer den ultimata kontrollen över åtkomstbehörigheter.Du kan också styra åtkomsten till en extern plats genom att binda den till specifika arbetsytor. Se (Valfritt) Tilldela en extern plats till specifika arbetsytor.
Bevilja inte allmänna
READ FILESellerWRITE FILESbehörigheter på externa platser till slutanvändare.Med tillgängligheten för volymer bör användarna inte använda externa platser för något annat än att skapa tabeller, volymer eller hanterade platser. De bör inte använda externa platser för sökvägsbaserad åtkomst för datavetenskap eller andra icke-tabellbaserade dataanvändningsfall.
Volymer ger stöd för att arbeta med filer med hjälp av SQL-kommandon, dbutils, Spark-API:er, REST-API:er, Terraform och ett användargränssnitt för att bläddra, ladda upp och ladda ned filer. Dessutom erbjuder volymer en FUSE-montering som är tillgänglig i det lokala filsystemet under
/Volumes/<catalog_name>/<schema_name>/<volume_name>/. FUSE-monteringen gör det möjligt för dataforskare och ML-tekniker att komma åt filer som om de vore i ett lokalt filsystem, vilket krävs av många maskininlärnings- eller operativsystembibliotek.Om du måste ge direkt åtkomst till filer på en extern plats (för att utforska filer i molnlagring innan en användare till exempel skapar en extern tabell eller volym) kan du bevilja
READ FILES. Användningsfall för beviljandeWRITE FILESär sällsynta.
Du bör använda externa platser för att göra följande:
- Registrera externa tabeller och volymer med hjälp av
CREATE EXTERNAL VOLUMEkommandona ellerCREATE TABLE. - Utforska befintliga filer i molnlagring innan du skapar en extern tabell eller volym med ett specifikt prefix. Privilegiet
READ FILESär en förutsättning. - Registrera en plats som hanterad lagring för kataloger och scheman i stället för metaarkivets rot bucket. Privilegiet
CREATE MANAGED STORAGEär en förutsättning.
Fler rekommendationer för att använda externa platser:
Undvik sökvägskonflikter: Skapa aldrig externa volymer eller tabeller i roten på en extern plats.
Om du skapar externa volymer eller tabeller i roten för den externa platsen kan du inte skapa några ytterligare externa volymer eller tabeller på den externa platsen. Skapa i stället externa volymer eller tabeller på en underkatalog på den externa platsen.
Rekommendationer för användning av externa volymer
Du bör använda externa volymer för att göra följande:
- Registrera landningsområden för rådata som produceras av externa system för att stödja bearbetningen i ett tidigt skede av ETL-pipelines och andra datatekniska aktiviteter.
- Registrera mellanlagringsplatser för inmatning, till exempel med hjälp av autoinläsnings
COPY INTO- eller CTAS-instruktioner (CREATE TABLE AS). - Tillhandahålla fillagringsplatser för dataforskare, dataanalytiker och maskininlärningstekniker som kan användas som delar av deras undersökande dataanalys och andra datavetenskapsuppgifter, när hanterade volymer inte är ett alternativ.
- Ge Azure Databricks-användare åtkomst till godtyckliga filer som produceras och deponeras i molnlagring av andra system, till exempel stora samlingar av ostrukturerade data (till exempel bild-, ljud-, video- och PDF-filer) som avbildas av övervakningssystem eller IoT-enheter eller biblioteksfiler (JAR och Python-hjulfiler) som exporteras från lokala beroendehanteringssystem eller CI/CD-pipelines.
- Lagra driftdata, till exempel loggning eller kontrollpunktsfiler, när hanterade volymer inte är ett alternativ.
Fler rekommendationer för att använda externa volymer:
- Databricks rekommenderar att du skapar externa volymer från en extern plats inom ett schema.
Dricks
Använd externa volymer för inmatningsfall där data kopieras till en annan plats, till exempel med automatisk inläsning eller COPY INTO. Använd externa tabeller när du vill köra frågor mot data på plats som en tabell, utan någon kopia.
Rekommendationer för att använda externa tabeller
Du bör använda externa tabeller för att stödja normala frågemönster ovanpå data som lagras i molnlagring, när det inte är ett alternativ att skapa hanterade tabeller.
Fler rekommendationer för att använda externa tabeller:
- Databricks rekommenderar att du skapar externa tabeller med en extern plats per schema.
- Databricks rekommenderar starkt att du inte registrerar en tabell som en extern tabell i mer än ett metaarkiv på grund av risken för konsekvensproblem. En ändring av schemat i ett metaarkiv registreras till exempel inte i det andra metaarkivet. Använd Deltadelning för att dela data mellan metaarkiv. Se Dela data på ett säkert sätt med deltadelning.
Konfigurera åtkomstkontroll
Varje skyddsbart objekt i Unity Catalog har en ägare. Det huvudnamn som skapar ett objekt blir dess första ägare. Ett objekts ägare har alla behörigheter för objektet, till exempel SELECT och MODIFY i en tabell, samt behörighet att bevilja behörigheter för det skyddsbara objektet till andra huvudnamn. Endast ägare av ett skyddsbart objekt har behörighet att bevilja behörigheter för objektet till andra huvudnamn. Därför är det bästa praxis att konfigurera ägarskap för alla objekt till den grupp som ansvarar för administrationen av bidrag för objektet. Både ägare och metaarkivadministratörer kan överföra ägarskapet för ett skyddsbart objekt till en grupp. Om objektet dessutom finns i en katalog (t.ex. en tabell eller vy) kan katalog- och schemaägaren ändra ägarskapet för objektet.
Skyddsbara objekt i Unity-katalogen är hierarkiska och privilegierna ärvs nedåt. Det innebär att beviljandet av ett privilegium för en katalog eller ett schema automatiskt ger privilegium till alla aktuella och framtida objekt i katalogen eller schemat. Mer information finns i Arvsmodell.
För att kunna läsa data från en tabell eller visa en användare måste ha följande behörigheter:
SELECTi tabellen eller vynUSE SCHEMAi schemat som äger tabellenUSE CATALOGi katalogen som äger schemat
USE CATALOG gör det möjligt för den som beviljar att gå igenom katalogen för att få åtkomst till dess underordnade objekt och USE SCHEMA gör det möjligt för den som beviljar att gå igenom schemat för att få åtkomst till dess underordnade objekt. Om du till exempel vill välja data från en tabell måste användarna ha behörigheten för tabellen SELECT och behörigheten USE CATALOG för den överordnade katalogen, tillsammans med behörigheten för USE SCHEMA dess överordnade schema. Därför kan du använda den här behörigheten för att begränsa åtkomsten till avsnitt i datanamnområdet till specifika grupper. Ett vanligt scenario är att konfigurera ett schema per team där endast det teamet har USE SCHEMA och CREATE i schemat. Det innebär att alla tabeller som skapats av teammedlemmar endast kan delas i teamet.
Du kan skydda åtkomsten till en tabell med hjälp av följande SQL-syntax:
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
Du kan skydda åtkomsten till kolumner med hjälp av en dynamisk vy i ett sekundärt schema enligt följande SQL-syntax:
CREATE VIEW < catalog_name >.< schema_name >.< view_name > as
SELECT
id,
CASE WHEN is_account_group_member(< group_name >) THEN email ELSE 'REDACTED' END AS email,
country,
product,
total
FROM
< catalog_name >.< schema_name >.< table_name >;
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >.< view_name >;
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< view_name >;
TO < group_name >;
Du kan skydda åtkomsten till rader med hjälp av en dynamisk vy i ett sekundärt schema enligt följande SQL-syntax:
CREATE VIEW < catalog_name >.< schema_name >.< view_name > as
SELECT
*
FROM
< catalog_name >.< schema_name >.< table_name >
WHERE
CASE WHEN is_account_group_member(managers) THEN TRUE ELSE total <= 1000000 END;
GRANT USE CATALOG ON CATALOG < catalog_name > TO < group_name >;
GRANT USE SCHEMA ON SCHEMA < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
GRANT
SELECT
ON < catalog_name >.< schema_name >.< table_name >;
TO < group_name >;
Du kan också ge användarna säker åtkomst till tabeller med hjälp av radfilter och kolumnmasker. Mer information finns i Filtrera känsliga tabelldata med hjälp av radfilter och kolumnmasker.
Mer information om alla privilegier i Unity Catalog finns i Hantera privilegier i Unity Catalog.
Hantera klusterkonfigurationer
Databricks rekommenderar att du använder klusterprinciper för att begränsa möjligheten att konfigurera kluster baserat på en uppsättning regler. Med klusterprinciper kan du begränsa åtkomsten till att endast skapa kluster som är Unity Catalog-aktiverade. Med hjälp av klusterprinciper minskar tillgängliga alternativ, vilket avsevärt förenklar processen för att skapa kluster för användare och ser till att de kan komma åt data sömlöst. Med klusterprinciper kan du också styra kostnaden genom att begränsa den maximala kostnaden per kluster.
För att säkerställa integriteten för åtkomstkontroller och framtvinga starka isoleringsgarantier inför Unity Catalog säkerhetskrav på beräkningsresurser. Därför introducerar Unity Catalog begreppet åtkomstläge för ett kluster. Unity Catalog är säker som standard. Om ett kluster inte har konfigurerats med ett lämpligt åtkomstläge kan klustret inte komma åt data i Unity Catalog. Se Beräkningskrav.
Databricks rekommenderar att du använder läget för delad åtkomst när du delar ett kluster och åtkomstläget För enskild användare för automatiserade jobb och maskininlärningsarbetsbelastningar.
JSON nedan innehåller en principdefinition för ett kluster med läget för delad åtkomst:
{
"spark_version": {
"type": "regex",
"pattern": "1[0-1]\\.[0-9]*\\.x-scala.*",
"defaultValue": "10.4.x-scala2.12"
},
"access_mode": {
"type": "fixed",
"value": "USER_ISOLATION",
"hidden": true
}
}
JSON nedan innehåller en principdefinition för ett automatiserat jobbkluster med åtkomstläget Enkel användare:
{
"spark_version": {
"type": "regex",
"pattern": "1[0-1]\\.[0-9].*",
"defaultValue": "10.4.x-scala2.12"
},
"access_mode": {
"type": "fixed",
"value": "SINGLE_USER",
"hidden": true
},
"single_user_name": {
"type": "regex",
"pattern": ".*",
"hidden": true
}
}
Granska åtkomst
En fullständig datastyrningslösning kräver granskning av åtkomst till data och tillhandahålla aviserings- och övervakningsfunktioner. Unity Catalog registrerar en granskningslogg med åtgärder som utförs mot metaarkivet och dessa loggar levereras som en del av Azure Databricks-granskningsloggar.
Du kan komma åt ditt kontos granskningsloggar med hjälp av systemtabeller. Mer information om systemtabellen för granskningsloggar finns i Tabellreferens för granskningsloggsystem.
Dela data på ett säkert sätt med deltadelning
Deltadelning är ett öppet protokoll som utvecklats av Databricks för säker datadelning med andra organisationer eller andra avdelningar i din organisation, oavsett vilka beräkningsplattformar de använder. När deltadelning är aktiverat i ett metaarkiv kör Unity Catalog en Delta Sharing-server.
Om du vill dela data mellan metaarkiv kan du använda Databricks-till-Databricks Delta Sharing. På så sätt kan du registrera tabeller från metaarkiv i olika regioner. Dessa tabeller visas som skrivskyddade objekt i det förbrukande metaarkivet. Dessa tabeller kan beviljas åtkomst som alla andra objekt i Unity Catalog.
När du använder Databricks-till-Databricks Delta-delning för att dela mellan metaarkiv bör du tänka på att åtkomstkontroll är begränsad till ett metaarkiv. Om ett skyddsbart objekt, till exempel en tabell, har bidrag på sig och resursen delas till ett intrakontometaarkiv, gäller inte bidragen från källan för målresursen. Målresursen måste ange egna bidrag.
Läs mer
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för