Skapa och hantera kataloger
Den här artikeln visar hur du skapar och hanterar kataloger i Unity Catalog. En katalog innehåller scheman (databaser) och ett schema innehåller tabeller, vyer, volymer, modeller och funktioner.
Kommentar
I arbetsytor som aktiverades automatiskt för Unity Catalog skapades en arbetsytekatalog åt dig som standard. Alla användare på din arbetsyta (och endast din arbetsyta) har åtkomst till den som standard. Se Steg 1: Bekräfta att arbetsytan är aktiverad för Unity Catalog.
Kommentar
Information om hur du skapar en utländsk katalog, ett Unity Catalog-objekt som speglar en databas i ett externt datasystem, finns i Skapa en sekundär katalog. Se även Hantera och arbeta med utländska kataloger.
Krav
Så här skapar du en katalog:
Du måste vara administratör för Azure Databricks-metaarkivet eller ha behörighet för
CREATE CATALOGmetaarkivet.Du måste ha ett Unity Catalog-metaarkiv länkat till arbetsytan där du skapar katalogen.
Klustret som du använder för att köra en notebook-fil för att skapa en katalog måste använda ett Åtkomstläge som är kompatibelt med Unity Catalog. Se Åtkomstlägen.
SQL-lager stöder alltid Unity Catalog.
Skapa en katalog
Om du vill skapa en katalog kan du använda Catalog Explorer eller ett SQL-kommando.
Katalogutforskaren
Logga in på en arbetsyta som är länkad till metaarkivet.
Klicka på
 Katalog.
Katalog.Klicka på knappen Skapa katalog .
Välj den katalogtyp som du vill skapa:
- Standardkatalog : ett skyddsbart objekt som organiserar datatillgångar som hanteras av Unity Catalog. För alla användningsfall utom Lakehouse Federation.
- Utländsk katalog: ett skyddsbart objekt i Unity Catalog som speglar en databas i ett externt datasystem med Hjälp av Lakehouse Federation. Se Översikt över Konfiguration av Lakehouse Federation.
(Valfritt men starkt rekommenderat) Ange en hanterad lagringsplats. Kräver behörigheten
CREATE MANAGED STORAGEpå den externa målplatsen. Se Ange en hanterad lagringsplats i Unity Catalog.Viktigt!
Om din arbetsyta inte har någon lagringsplats på metaarkivnivå måste du ange en hanterad lagringsplats när du skapar en katalog.
Klicka på Skapa.
(Valfritt) Ange den arbetsyta som katalogen är bunden till.
Som standard delas katalogen med alla arbetsytor som är kopplade till det aktuella metaarkivet. Om katalogen innehåller data som ska begränsas till specifika arbetsytor går du till fliken Arbetsytor och lägger till dessa arbetsytor.
Mer information finns i (Valfritt) Tilldela en katalog till specifika arbetsytor.
Tilldela behörigheter för katalogen. Se Behörigheter och skyddsbara objekt i Unity Catalog.
SQL
Kör följande SQL-kommando i en notebook- eller Databricks SQL-redigerare. Objekt inom hakparenteser är valfria. Ersätt platshållarvärdena:
<catalog-name>: Ett namn på katalogen.<location-path>: Valfritt men starkt rekommenderat. Ange en lagringsplatssökväg om du vill att hanterade tabeller i den här katalogen ska lagras på en annan plats än standardrotlagringen som konfigurerats för metaarkivet.Viktigt!
Om din arbetsyta inte har någon lagringsplats på metaarkivnivå måste du ange en hanterad lagringsplats när du skapar en katalog.
Den här sökvägen måste definieras i en extern platskonfiguration och du måste ha behörighet för konfigurationen
CREATE MANAGED STORAGEav den externa platsen. Du kan använda sökvägen som definieras i konfigurationen av den externa platsen eller en undersökväg (med andra ord eller'abfss://my-container-name@storage-account-name.dfs.core.windows.net/finance''abfss://my-container-name@storage-account-name.dfs.core.windows.net/finance/product'). Kräver Databricks Runtime 11.3 och senare.<comment>: Valfri beskrivning eller annan kommentar.
Kommentar
Om du skapar en sekundär katalog (ett skyddsbart objekt i Unity Catalog som speglar en databas i ett externt datasystem som används för Lakehouse Federation) är
CREATE FOREIGN CATALOGSQL-kommandot och alternativen är olika. Se Skapa en sekundär katalog.CREATE CATALOG [ IF NOT EXISTS ] <catalog-name> [ MANAGED LOCATION '<location-path>' ] [ COMMENT <comment> ];Om du till exempel vill skapa en katalog med namnet
example:CREATE CATALOG IF NOT EXISTS example;Om du vill begränsa katalogåtkomsten till specifika arbetsytor i ditt konto, även kallat bindning mellan arbetsytor och katalog, kan du läsa Binda en katalog till en eller flera arbetsytor.
Parameterbeskrivningar finns i SKAPA KATALOG.
Tilldela behörigheter till katalogen. Se Behörigheter och skyddsbara objekt i Unity Catalog.
När du skapar en katalog skapas två scheman (databaser) automatiskt: default och information_schema.
Du kan också skapa en katalog med hjälp av Databricks Terraform-providern och databricks_catalog. Du kan hämta information om kataloger med hjälp av databricks_catalogs.
(Valfritt) Tilldela en katalog till specifika arbetsytor
Om du använder arbetsytor för att isolera åtkomst till användardata kanske du vill begränsa katalogåtkomsten till specifika arbetsytor i ditt konto, även kallat bindning mellan arbetsytor och katalog. Standardvärdet är att dela katalogen med alla arbetsytor som är kopplade till det aktuella metaarkivet.
Du kan tillåta läs- och skrivåtkomst till katalogen från en arbetsyta (standard) eller så kan du ange skrivskyddad åtkomst. Om du anger skrivskyddad blockeras alla skrivåtgärder från arbetsytan till katalogen.
Vanliga användningsfall för att binda en katalog till specifika arbetsytor är:
- Se till att användarna bara kan komma åt produktionsdata från en miljö för produktionsarbetsytor.
- Se till att användarna bara kan bearbeta känsliga data från en dedikerad arbetsyta.
- Ge användarna skrivskyddad åtkomst till produktionsdata från en arbetsyta för utvecklare för att möjliggöra utveckling och testning.
Exempel på bindning av arbetsytekatalog
Ta exemplet med produktions- och utvecklingsisolering. Om du anger att dina produktionsdatakataloger bara kan nås från produktionsarbetsytor ersätter detta alla enskilda bidrag som utfärdas till användare.
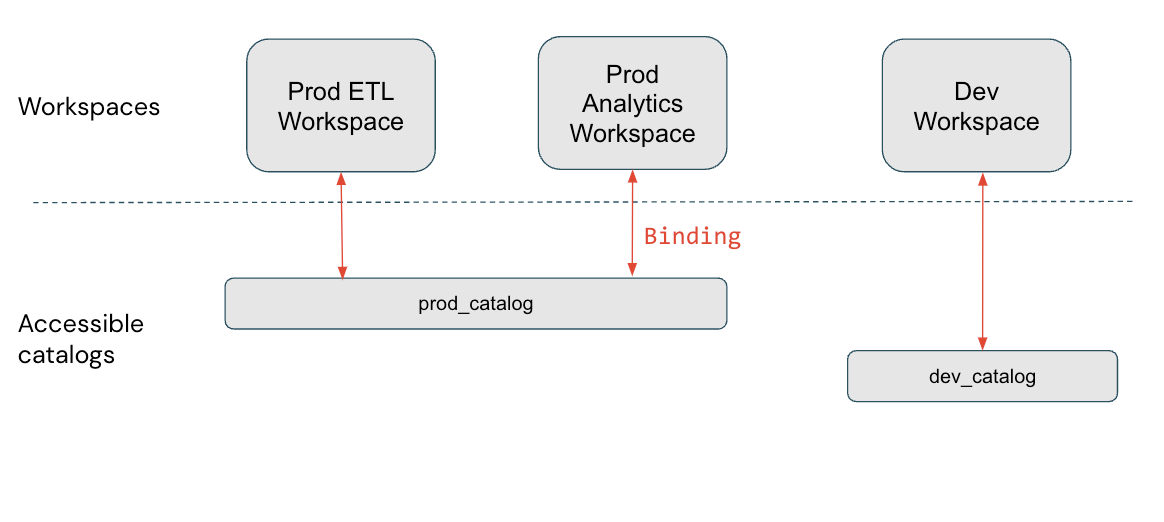
I det här diagrammet prod_catalog är det bundet till två produktionsarbetsytor. Anta att en användare har beviljats åtkomst till en tabell i prod_catalog med namnet my_table (med ).GRANT SELECT ON my_table TO <user> Om användaren försöker komma åt my_table på Dev-arbetsytan får de ett felmeddelande. Användaren kan bara komma åt my_table från Prod ETL- och Prod Analytics-arbetsytorna.
Bindningar för arbetsytekataloger respekteras inom alla delar av plattformen. Om du till exempel frågar efter informationsschemat ser du bara de kataloger som är tillgängliga på arbetsytan där du utfärdar frågan. Data härkomst och sök-UIs visar också bara de kataloger som har tilldelats till arbetsytan (oavsett om du använder bindningar eller som standard).
Binda en katalog till en eller flera arbetsytor
Om du vill tilldela en katalog till specifika arbetsytor kan du använda Catalog Explorer eller REST-API:et för Unity Catalog.
Behörigheter som krävs: Metaarkivadministratör eller katalogägare.
Kommentar
Metaarkivadministratörer kan se alla kataloger i ett metaarkiv med hjälp av Catalog Explorer – och katalogägare kan se alla kataloger som de äger i ett metaarkiv – oavsett om katalogen har tilldelats till den aktuella arbetsytan. Kataloger som inte har tilldelats arbetsytan visas nedtonade och inga underordnade objekt är synliga eller frågebara.
Katalogutforskaren
Logga in på en arbetsyta som är länkad till metaarkivet.
Klicka på
Katalog.Klicka på katalognamnet till vänster i fönstret Katalog.
Huvudfönstret i Katalogutforskaren är standard i listan Kataloger . Du kan också välja katalogen där.
På fliken Arbetsytor avmarkerar du kryssrutan Alla arbetsytor har åtkomst .
Om katalogen redan är bunden till en eller flera arbetsytor är den här kryssrutan redan avmarkerad.
Klicka på Tilldela till arbetsytor och ange eller hitta de arbetsytor som du vill tilldela.
(Valfritt) Begränsa åtkomsten till skrivskyddad arbetsyta.
På menyn Hantera åtkomstnivå väljer du Ändra åtkomst till skrivskyddad.
Du kan ångra det här valet när som helst genom att redigera katalogen och välja Ändra åtkomst till läs- och skrivbehörighet.
Om du vill återkalla åtkomsten går du till fliken Arbetsytor , väljer arbetsytan och klickar på Återkalla.
Api
Det finns två API:er och två steg som krävs för att tilldela en katalog till en arbetsyta. I följande exempel ersätter du <workspace-url> med namnet på arbetsytans instans. Information om hur du hämtar arbetsytans instansnamn och arbetsyte-ID finns i Hämta identifierare för arbetsyteobjekt. Mer information om hur du hämtar åtkomsttoken finns i Autentisering för Azure Databricks Automation – översikt.
Använd API:et
catalogsför att ange katalogensisolation modetillISOLATED:curl -L -X PATCH 'https://<workspace-url>/api/2.1/unity-catalog/catalogs/<my-catalog> \ -H 'Authorization: Bearer <my-token> \ -H 'Content-Type: application/json' \ --data-raw '{ "isolation_mode": "ISOLATED" }'Standardvärdet
isolation modeär alla arbetsytor som ärOPENkopplade till metaarkivet.Använd uppdaterings-API
bindings:et för att tilldela arbetsytorna till katalogen:curl -L -X PATCH 'https://<workspace-url>/api/2.1/unity-catalog/bindings/catalog/<my-catalog> \ -H 'Authorization: Bearer <my-token> \ -H 'Content-Type: application/json' \ --data-raw '{ "add": [{"workspace_id": <workspace-id>, "binding_type": <binding-type>}...], "remove": [{"workspace_id": <workspace-id>, "binding_type": "<binding-type>}...] }'"add"Använd egenskaperna och"remove"för att lägga till eller ta bort arbetsytebindningar.<binding-type>kan vara antingen“BINDING_TYPE_READ_WRITE”(standard) eller“BINDING_TYPE_READ_ONLY”.
Om du vill visa en lista över alla arbetsytetilldelningar för en katalog använder du list-API bindings :et:
curl -L -X GET 'https://<workspace-url>/api/2.1/unity-catalog/bindings/catalog/<my-catalog> \
-H 'Authorization: Bearer <my-token> \
Koppla bort en katalog från en arbetsyta
Instruktioner för att återkalla arbetsytans åtkomst till en katalog med hjälp av Katalogutforskaren eller API:et bindings ingår i Binda en katalog till en eller flera arbetsytor.
Viktigt!
Om din arbetsyta har aktiverats för Unity Catalog automatiskt och du har en arbetsytekatalog äger arbetsyteadministratörerna katalogen och har alla behörigheter för katalogen endast på arbetsytan. Om du avbindde den katalogen eller binder den till andra kataloger måste du bevilja nödvändiga behörigheter manuellt till medlemmarna i gruppen arbetsyteadministratörer som enskilda användare eller använda grupper på kontonivå, eftersom arbetsytans administratörsgrupp är en arbetsytelokal grupp. Mer information om kontogrupper jämfört med arbetsytelokala grupper finns i Skillnaden mellan kontogrupper och lokala arbetsytegrupper.
Lägga till scheman i katalogen
Lär dig hur du lägger till scheman (databaser) i katalogen. se Skapa och hantera scheman (databaser).
Visa kataloginformation
Om du vill visa information om en katalog kan du använda Catalog Explorer eller ett SQL-kommando.
Katalogutforskaren
Logga in på en arbetsyta som är länkad till metaarkivet.
Klicka på
Katalog.Leta reda på katalogen i fönstret Katalog och klicka på dess namn.
En del information visas överst på sidan. Andra kan visas på flikarna Scheman, Information, Behörigheter och Arbetsytor .
SQL
Kör följande SQL-kommando i en notebook- eller Databricks SQL-redigerare. Objekt inom hakparenteser är valfria. Ersätt platshållaren <catalog-name>.
Mer information finns i BESKRIVA KATALOG.
DESCRIBE CATALOG <catalog-name>;
Använd CATALOG EXTENDED för att hämta fullständig information.
Ta bort en katalog
Om du vill ta bort (eller ta bort) en katalog kan du använda Catalog Explorer eller ett SQL-kommando. Om du vill släppa en katalog måste du vara dess ägare.
Katalogutforskaren
Du måste ta bort alla scheman i katalogen förutom information_schema innan du kan ta bort en katalog. Detta inkluderar det automatiskt skapade default schemat.
- Logga in på en arbetsyta som är länkad till metaarkivet.
- Klicka på Katalog.
- I fönstret Katalog till vänster klickar du på den katalog som du vill ta bort.
- I detaljfönstret klickar du på menyn med tre punkter till vänster om knappen Skapa databas och väljer Ta bort.
- I dialogrutan Ta bort katalog klickar du på Ta bort.
SQL
Kör följande SQL-kommando i en notebook- eller Databricks SQL-redigerare. Objekt inom hakparenteser är valfria. Ersätt platshållaren <catalog-name>.
Parameterbeskrivningar finns i SLÄPP KATALOG.
Om du använder DROP CATALOG utan CASCADE alternativet måste du ta bort alla scheman i katalogen förutom information_schema innan du kan ta bort katalogen. Detta inkluderar det automatiskt skapade default schemat.
DROP CATALOG [ IF EXISTS ] <catalog-name> [ RESTRICT | CASCADE ]
Om du till exempel vill ta bort en katalog med namnet vaccine och dess scheman:
DROP CATALOG vaccine CASCADE
Hantera standardkatalogen
En standardkatalog konfigureras för varje arbetsyta som är aktiverad för Unity Catalog. Med standardkatalogen kan du utföra dataåtgärder utan att ange en katalog. Om du utelämnar katalognamnet på den översta nivån när du utför dataåtgärder antas standardkatalogen.
En arbetsyteadministratör kan visa eller växla standardkatalogen med hjälp av administratörsgränssnittet Inställningar. Du kan också ange standardkatalogen för ett kluster med hjälp av en Spark-konfiguration.
Kommandon som inte anger katalogen (till exempel GRANT CREATE TABLE ON SCHEMA myschema TO mygroup) utvärderas för katalogen i följande ordning:
- Är katalogen inställd för sessionen med hjälp av en
USE CATALOGinstruktion eller en JDBC-inställning? - Är Spark-konfigurationen
spark.databricks.sql.initial.catalog.namespaceinställd på klustret? - Finns det en standardkatalog för arbetsytan för klustret?
Standardkatalogkonfigurationen när Unity Catalog är aktiverat
Standardkatalogen som ursprungligen konfigurerades för din arbetsyta beror på hur din arbetsyta har aktiverats för Unity Catalog:
- För vissa arbetsytor som aktiverades automatiskt för Unity Catalog angavs arbetsytekatalogen som standardkatalog. Se Automatisk aktivering av Unity Catalog.
- För alla andra arbetsytor angavs
hive_metastorekatalogen som standardkatalog.
Om du övergår från Hive-metaarkivet till Unity Catalog på en befintlig arbetsyta är det vanligtvis klokt att använda hive_metastore som standardkatalog för att undvika att påverka befintlig kod som refererar till hive-metaarkivet.
Ändra standardkatalogen
En arbetsyteadministratör kan ändra standardkatalogen för arbetsytan. Alla som har behörighet att skapa eller redigera ett kluster kan ange en annan standardkatalog för klustret.
Varning
Om du ändrar standardkatalogen kan du bryta befintliga dataåtgärder som är beroende av den.
Så här konfigurerar du en annan standardkatalog för en arbetsyta:
- Logga in på din arbetsyta som administratör för arbetsytan.
- Klicka på ditt användarnamn i arbetsytans övre stapel och välj Inställningar i listrutan.
- Klicka på fliken Avancerat.
- På raden Standardkatalog för arbetsytan anger du katalognamnet och klickar på Spara.
Starta om dina SQL-lager och -kluster för att ändringen ska börja gälla. Alla nya och omstartade SQL-lager och -kluster använder den här katalogen som standard för arbetsytan.
Du kan också åsidosätta standardkatalogen för ett visst kluster genom att ange följande Spark-konfiguration i klustret. Den här metoden är inte tillgänglig för SQL-lager:
spark.databricks.sql.initial.catalog.name
Anvisningar finns i Spark-konfiguration.
Visa den aktuella standardkatalogen
Om du vill hämta den aktuella standardkatalogen för din arbetsyta kan du använda en SQL-instruktion i en notebook- eller SQL-redigerarfråga. En arbetsyteadministratör kan hämta standardkatalogen med hjälp av användargränssnittet admin Inställningar.
Administratörsinställningar
- Logga in på din arbetsyta som administratör för arbetsytan.
- Klicka på ditt användarnamn i arbetsytans övre stapel och välj Inställningar i listrutan.
- Klicka på fliken Avancerat.
- Visa katalognamnet på raden Standardkatalog för arbetsytan.
SQL
Kör följande kommando i en notebook- eller SQL-redigerarfråga som körs på ett SQL-lager eller ett Unity Catalog-kompatibelt kluster. Standardkatalogen för arbetsytan returneras så länge ingen USE CATALOG instruktion eller JDBC-inställning har angetts för sessionen och så länge ingen spark.databricks.sql.initial.catalog.namespace konfiguration har angetts för klustret.
SELECT current_catalog();
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för