Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Anteckning
Organisationen av den här artikeln förutsätter att du använder det enkla användargränssnittet för formulärberäkning. En översikt över de enkla formuläruppdateringarna finns i Använda det enkla formuläret för att hantera beräkning.
I den här artikeln beskrivs de konfigurationsinställningar som är tillgängliga när du skapar en ny beräkningsresurs för alla syften eller jobb. De flesta användare skapar beräkningsresurser med hjälp av sina tilldelade principer, vilket begränsar de konfigurerbara inställningarna. Om du inte ser någon viss inställning i användargränssnittet beror det på att principen du har valt inte tillåter att du konfigurerar den inställningen.
Rekommendationer om hur du konfigurerar beräkning för din arbetsbelastning finns i rekommendationer för beräkningskonfiguration.
De konfigurationer och hanteringsverktyg som beskrivs i den här artikeln gäller för både allmän användning och beräkning av uppgifter. Mer information om hur du konfigurerar jobbberäkning finns i Konfigurera beräkning för jobb.
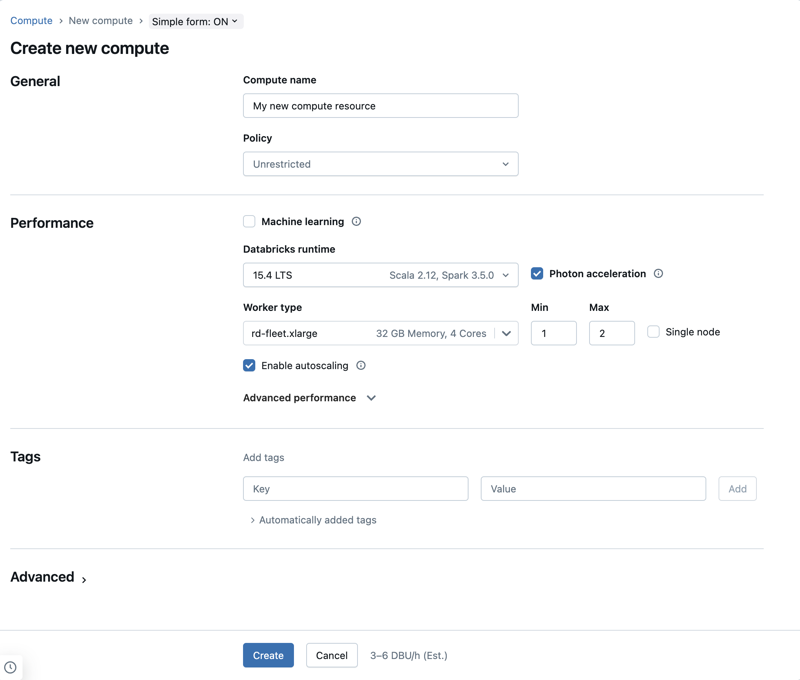
Skapa en ny beräkningsresurs för alla syften
Så här skapar du en ny beräkningsresurs för alla syften:
- I sidofältet för arbetsytan klickar du på Beräkning.
- Klicka på knappen Skapa beräkning .
- Konfigurera beräkningsresursen.
- Klicka på Skapa.
Den nya beräkningsresursen börjar automatiskt att snurra upp och vara redo att användas inom kort.
Beräkningsprincip
Principer är en uppsättning regler som används för att begränsa de konfigurationsalternativ som är tillgängliga för användare när de skapar beräkningsresurser. Om en användare inte har behörigheten Att skapa obegränsade kluster kan de bara skapa beräkningsresurser med hjälp av sina tilldelade principer.
Om du vill skapa beräkningsresurser enligt en princip väljer du en princip på den nedrullningsbara menyn Princip .
Som standard har alla användare åtkomst till principen för personlig beräkning , vilket gör att de kan skapa beräkningsresurser för en enda dator. Om du behöver åtkomst till Personal Computing eller några ytterligare policyer, kontakta administratören för arbetsytan.
Prestandainställningar
Följande inställningar visas under avsnittet Prestanda i det enkla användargränssnittet för beräkning av formulär:
- Databricks Runtime-versioner
- Använd fotonacceleration
- Typ av arbetsnod
- Beräkning med en nod
- Aktivera automatisk skalning
- Avancerade prestandainställningar
Versioner av Databricks Runtime
Databricks Runtime är den uppsättning kärnkomponenter som körs på din beräkning. Välj körmiljön genom listrutan Databricks Runtime Version. Mer information om specifika Databricks Runtime-versioner finns i Versionsanmärkningsversioner och kompatibilitet för Databricks Runtime. Alla versioner inkluderar Apache Spark. Databricks rekommenderar följande:
- För all användningsberäkning använder du den senaste versionen för att säkerställa att du har de senaste optimeringarna och den senaste kompatibiliteten mellan din kod och förinstallerade paket.
- För jobbutförande som kör operativa arbetsbelastningar bör du överväga att använda Long Term Support (LTS) Databricks Runtime-versionen. Om du använder LTS-versionen ser du till att du inte stöter på kompatibilitetsproblem och kan testa arbetsbelastningen noggrant innan du uppgraderar.
- För användningsfall för datavetenskap och maskininlärning bör du överväga Ml-versionen för Databricks Runtime.
Använd fotonacceleration
Photon är aktiverat som standard vid beräkning som kör Databricks Runtime 9.1 LTS och senare.
Om du vill aktivera eller inaktivera fotoacceleration markerar du kryssrutan Använd fotonacceleration . Mer information om Foton finns i Vad är Foton?.
Arbetarnodtyp
En beräkningsresurs består av en drivrutinsnod och noll eller fler arbetsnoder. Du kan välja separata typer av molnproviderinstanser för drivrutins- och arbetsnoderna, men som standard använder drivrutinsnoden samma instanstyp som arbetsnoden. Inställningen för drivrutinsnoden finns under avsnittet Avancerade prestanda .
Olika typer av instanstyper passar olika användningsfall, till exempel minnesintensiva eller beräkningsintensiva arbetsbelastningar. Du kan också välja en pool som ska användas som arbets- eller drivrutinsnod.
Viktigt!
Använd inte en pool med spotinstanser som förartyp. Välj en drivrutinstyp på begäran för att förhindra att drivrutinen återkallas. Se Ansluta till pooler.
I beräkning med flera noder kör arbetsnoder Spark-kören och andra tjänster som krävs för en korrekt fungerande beräkningsresurs. När du distribuerar arbetsbelastningen med Spark sker all distribuerad bearbetning på arbetsnoder. Azure Databricks kör en köre per arbetsnod. Därför används termerna executor och worker utbytbart i kontexten för Databricks-arkitekturen.
Tips
Om du vill köra ett Spark-jobb behöver du minst en arbetsnod. Om beräkningsresursen har noll arbetare kan du köra icke-Spark-kommandon på drivrutinsnoden, men Spark-kommandon misslyckas.
Flexibla nodtyper
Om din arbetsyta har flexibla nodtyper aktiverade kan du använda flexibla nodtyper för beräkningsresursen. Med flexibla nodtyper kan beräkningsresursen återgå till alternativa, kompatibla instanstyper när den angivna instanstypen inte är tillgänglig. Det här beteendet förbättrar tillförlitligheten för beräkningsstarten genom att minska kapacitetsfelen vid beräkningsstarter. Se Förbättra tillförlitligheten för beräkningsstart med flexibla nodtyper.
IP-adresser för arbetsnod
Azure Databricks startar arbetsnoder med två privata IP-adresser vardera. Nodens primära privata IP-adress hanterar Azure Databricks intern trafik. Den sekundära privata IP-adressen används av Spark-containern för kommunikation mellan kluster. Med den här modellen kan Azure Databricks isolera flera beräkningsresurser på samma arbetsyta.
GPU-instanstyper
För beräkningsmässigt utmanande uppgifter som kräver höga prestanda, som de som är associerade med djupinlärning, stöder Azure Databricks beräkningsresurser som accelereras med grafikprocessorer (GPU:er). Mer information finns i GPU-aktiverad beräkning.
Azure virtuella datorer för konfidentiell databehandling
Azure typer av konfidentiell databehandling av virtuella datorer förhindrar obehörig åtkomst till data när de används, inklusive från molnoperatören. Den här typen av virtuell dator är fördelaktig för strikt reglerade branscher och regioner samt företag med känsliga data i molnet. Mer information om Azure konfidentiell databehandling finns i Azure konfidentiell databehandling.
Om du vill köra dina arbetsbelastningar med hjälp av Azure virtuella datorer för konfidentiell databehandling väljer du från vm-typerna dc eller EC-serien i listrutorna för arbets- och drivrutinsnoder. Se alternativen för Azure Confidential VMs.
enkel nodberäkning
Med kryssrutan Enkel nod kan du skapa en beräkningsresurs för en enda nod.
Beräkning med en nod är avsedd för jobb som använder små mängder data eller icke-distribuerade arbetsbelastningar, till exempel maskininlärningsbibliotek med en nod. Beräkning med flera noder ska användas för större jobb med distribuerade arbetsbelastningar.
Egenskaper för enskild nod
En beräkningsresurs med en nod har följande egenskaper:
- Kör Spark lokalt.
- Drivrutinen fungerar som både huvud- och arbetsroll, utan arbetsnoder.
- Skapar en körtråd per logisk kärna i beräkningsresursen, minus 1 kärna för drivrutinen.
- Sparar alla
stderr,stdoutochlog4jloggutdata i drivrutinsloggen. - Det går inte att konvertera till en beräkningsresurs med flera noder.
Välja en eller flera noder
Tänk på ditt användningsfall när du bestämmer mellan beräkning med en eller flera noder:
Storskalig databearbetning uttömmer resurserna på en beräkningsresurs med en enda nod. För dessa arbetsbelastningar rekommenderar Databricks att du använder beräkning med flera noder.
En beräkningsresurs med flera noder kan inte skalas till 0 arbetare. Använd beräkning med en nod i stället.
GPU-schemaläggning är inte aktiverat för beräkning med en enda nod.
Vid beräkning på en enda nod kan Spark inte läsa Parquet-filer med en UDT-kolumn. Följande felmeddelanderesultat:
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.Om du vill undvika det här problemet inaktiverar du den inbyggda Parquet-läsaren:
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
Aktivera automatisk skalning
När Aktivera autoskalning är markerat kan du ange ett minsta och högsta antal arbetare för beräkningsresursen. Databricks väljer sedan rätt antal arbetare som krävs för att köra jobbet.
Om du vill ange det lägsta och högsta antalet arbetare som beräkningsresursen ska skalas mellan automatiskt använder du fälten Min och Max bredvid listrutan Arbetstyp .
Om du inte aktiverar automatisk skalning måste du ange ett fast antal arbetare i fältet Arbetare bredvid listrutan Arbetstyp .
Anteckning
När beräkningsresursen körs visar sidan med beräkningsinformation antalet allokerade arbetare. Du kan jämföra antalet allokerade arbetare med arbetskonfigurationen och göra justeringar efter behov.
Fördelar med automatisk skalning
Med autoskalning omallokerar Azure Databricks arbetare dynamiskt för att ta hänsyn till egenskaperna för ditt jobb. Vissa delar av pipelinen kan vara mer beräkningsmässigt krävande än andra, och Databricks lägger automatiskt till ytterligare arbetare under dessa faser av jobbet (och tar bort dem när de inte längre behövs).
Autoskalning gör det enklare att uppnå hög användning eftersom du inte behöver tillhandahålla datorkapacitet för att matcha en arbetslast. Detta gäller särskilt för arbetsbelastningar vars krav ändras över tid (till exempel att utforska en datauppsättning under en dag), men det kan även gälla för en enstaka kortare arbetsbelastning vars etableringskrav är okända. Automatisk skalning erbjuder därför två fördelar:
- Arbetsbelastningar kan köras snabbare jämfört med en underdimensionerad beräkningsresurs av fast storlek.
- Autoskalning kan minska de totala kostnaderna jämfört med en statiskt storleksanpassad beräkningsresurs.
Beroende på beräkningsresursens och arbetsbelastningens konstanta storlek ger automatisk skalning dig en eller båda av dessa fördelar samtidigt. Beräkningsstorleken kan gå under det minsta antal arbetare som valts när molnleverantören avslutar instanser. I det här fallet försöker Azure Databricks kontinuerligt på nytt att återupprätta instanser för att behålla det minimala antalet arbetare.
Anteckning
Autoskalning är inte tillgängligt för spark-submit-jobb.
Anteckning
Automatiserad skalning av beräkningar har begränsningar när det gäller att minska klusterstorleken för arbetsbelastningar med strukturerad strömning. Databricks rekommenderar att du använder Lakeflow Spark Deklarativa pipelines med förbättrad automatisk skalning för strömningsarbetsbelastningar. Se även Optimera klusteranvändningen för Lakeflow Spark deklarativa pipelines med autoskalning.
Hur autoskalning fungerar
Arbetsytor på Premium-planen använder avancerad automatisk skalning. Arbetsytor i standardprisplanen använder standardautoskalning.
Optimerad automatisk skalning har följande egenskaper:
- Skalas upp från min till max i två steg.
- Kan skala ned, även om beräkningsresursen inte är inaktiv, genom att titta på shuffle-filtillståndet.
- Skalas ned procentuellt utifrån de aktuella noderna.
- Vid jobbberäkning skalas ned om beräkningsresursen underutnyttjers under de senaste 40 sekunderna.
- Vid all-purpose compute skalas ned om beräkningsresursen underutnyttjers under de senaste 150 sekunderna.
- Spark-konfigurationsegenskapen
spark.databricks.aggressiveWindowDownSanger i sekunder hur ofta beräkningen fattar beslut om nedskalning. Om du ökar värdet skalas beräkningen ned långsammare. Det maximala värdet är 600.
Standard autoskalning används i arbetsytor med standardplan. Standard automatisk skalning har följande egenskaper:
- Börjar med att lägga till 8 noder. Skala sedan upp exponentiellt och vidta så många steg som krävs för att nå maxvärdet.
- Skalas ned när 90 % av noderna inte är upptagna på 10 minuter och beräkningen har varit inaktiv i minst 30 sekunder.
- Skalas ned exponentiellt, från och med 1 nod.
Varning
Aktivera inte Apache Spark Dynamic Allocation (spark.dynamicAllocation.enabled) för beräkningsresurser som använder automatisk skalning av Databricks. Databricks autoskalning hanterar arbetsnoder och exekveringslivscykel på plattformsnivå. Aktivering av dynamisk Spark-allokering parallellt kan orsaka motstridiga skalningsbeslut, vilket leder till exekutoromsättning, NODES_LOST fel och uppgifter som aldrig hämtas.
Dynamisk skalning med resurspooler
Tänk på följande om du kopplar beräkningsresursen till en pool:
- Kontrollera att den begärda beräkningsstorleken är mindre än eller lika med det minsta antalet inaktiva instanser i poolen. Om den är större, är beräkningsstarttiden som en beräkning utan pool.
- Kontrollera att den maximala beräkningsstorleken är mindre än eller lika med poolens maximala kapacitet . Om den är större misslyckas beräkningsgenereringen.
Exempel på automatisk skalning
Om du konfigurerar om en statisk beräkningsresurs till autoskalning ändrar Azure Databricks omedelbart storlek på beräkningsresursen inom de lägsta och högsta gränserna och startar sedan autoskalning. I följande tabell visas till exempel vad som händer med en beräkningsresurs med en viss initial storlek om du konfigurerar om beräkningsresursen för automatisk skalning mellan 5 och 10 noder.
| Ursprunglig storlek | Storlek efter omkonfiguration |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Avancerade prestandainställningar
Följande inställning visas under avsnittet Avancerad prestanda i det enkla användargränssnittet för beräkning.
Spot-instanser
Om du vill spara kostnader kan du välja att använda Spot-instansen, även kända som Azure Spot VMs genom att kryssa i rutan Spot-instansen.

Den första instansen är alltid på begäran (drivnoden är alltid på begäran) och efterföljande instanser är spot-instanser.
Om instanser avlägsnas på grund av otillgänglighet försöker Azure Databricks hämta nya spotinstanser för att ersätta de borttagna instanserna. Om det inte går att hämta spotinstanser distribueras instanser på begäran för att ersätta de avvisade instanserna. Den här failback-funktionen på begäran stöds bara för spotinstanser som är fullt förvärvade och körs. Spot-instanser som misslyckas under konfigurationen ersätts inte automatiskt.
När nya noder läggs till i befintliga beräkningsresurser försöker Azure Databricks dessutom hämta spot-instanser för dessa noder.
Automatisk avslutning
Du kan ange automatisk avslutning för beräkning under avsnittet Avancerade prestanda . När beräkning skapas anger du en inaktivitetsperiod i minuter efter vilken du vill att beräkningsresursen ska avslutas.
Om skillnaden mellan den aktuella tiden och den senaste kommandokörningen på beräkningsresursen är mer än den angivna inaktivitetsperioden Azure Databricks automatiskt avslutar beräkningsresursen. Mer information om beräkningsavslut finns i Avsluta en beräkning.
Drivertyp
Du kan välja drivrutinstyp under avsnittet Avancerad prestanda . Drivrutinsnoden håller reda på tillståndsinformation för alla notebooks som är kopplade till beräkningsresursen. Drivrutinsnoden underhåller också SparkContext, tolkar alla kommandon som du kör från en notebook-fil eller ett bibliotek på beräkningsresursen och kör Apache Spark-huvudservern som samordnar med Spark-körarna.
Standardvärdet för drivrutinsnodtypen är samma som arbetsnodtypen. Du kan välja en större drivarnodtyp med mer minne om du planerar att collect() använda mycket data från Spark-arbetare och analysera dem i anteckningsboken.
Tips
Eftersom drivrutinsnoden innehåller all tillståndsinformation för de anslutna notebookarna, se till att koppla bort oanvända notebookar från drivrutinsnoden.
Taggar
Med taggar kan du enkelt övervaka kostnaden för beräkningsresurser som används av olika grupper i din organisation. Ange taggar som nyckel/värde-par när du skapar beräkning och Azure Databricks tillämpar dessa taggar på molnresurser som virtuella datorer och diskvolymer samt Databricks-användningsloggarna.
För beräkning som startas från pooler tillämpas de anpassade taggarna endast på DBU-användningsrapporter och sprids inte till molnresurser.
Detaljerad information om hur pool- och beräkningstaggtyper fungerar tillsammans finns i Använda taggar för att attribut och spåra användning
Så här lägger du till taggar i beräkningsresursen:
- I avsnittet Taggar lägger du till ett nyckel/värde-par för varje anpassad tagg.
- Klicka på Lägg till.
Avancerade inställningar
Följande inställningar visas under avsnittet Avancerat i det enkla användargränssnittet för beräkning av formulär:
- Åtkomstlägen
- Aktivera lokal lagring för automatisk skalning
- Lokal diskkryptering
- Spark-konfiguration
- Leverans av beräkningslogg
- SSH-åtkomst till beräkning
- Miljövariabler
Åtkomstlägen
Åtkomstläge är en säkerhetsfunktion som avgör vem som kan använda beräkningsresursen och de data som de kan komma åt med hjälp av beräkningsresursen. Varje beräkningsresurs i Azure Databricks har ett åtkomstläge. Inställningar för åtkomstläge finns i avsnittet Avancerat i det enkla användargränssnittet för beräkning av formulär.
Valet av åtkomstläge är automatiskt som standard, vilket innebär att åtkomstläget väljs automatiskt för dig baserat på din valda Databricks Runtime. Automatisk standardinställning är Standard om inte en maskininlärningsmiljö eller en Databricks Runtime under 14.3 har valts, i vilket fall Dedicated används.
Databricks rekommenderar att du använder standardåtkomstläge såvida inte nödvändiga funktioner inte stöds.
| Åtkomstläge | Description | Språk som stöds |
|---|---|---|
| Norm | Kan användas av flera användare med dataisolering mellan användare. | Python, SQL, Scala |
| Dedicated | Kan tilldelas till och användas av en enskild användare eller grupp. | Python, SQL, Scala, R |
Detaljerad information om funktionsstöd för var och en av dessa åtkomstlägen finns i Standardkrav och begränsningar för beräkning ochdedikerade beräkningskrav och begränsningar.
Anteckning
I Databricks Runtime 13.3 LTS och senare stöds init-skript och bibliotek av alla åtkomstlägen. Krav och supportnivåer varierar. Se Var kan init-skript installeras? och Beräkningsomspännande bibliotek.
Aktivera lokal lagring för automatisk skalning
Det kan ofta vara svårt att uppskatta hur mycket diskutrymme ett visst jobb tar. För att spara dig från att behöva uppskatta hur många gigabyte hanterad disk som ska anslutas till din beräkning vid skapandetillfället aktiverar Azure Databricks automatiskt automatisk skalning av lokal lagring på alla Azure Databricks beräkning.
Med lokal lagring med automatisk skalning övervakar Azure Databricks mängden ledigt diskutrymme som är tillgängligt för spark-arbetare i din beräkning. Om en arbetare börjar köra för lågt på disken kopplar Databricks automatiskt en ny hanterad disk till arbetaren innan diskutrymmet tar slut. Diskar är anslutna till en gräns på 5 TB totalt diskutrymme per virtuell dator (inklusive den virtuella datorns ursprungliga lokala lagring).
De hanterade diskarna som är anslutna till en virtuell dator kopplas endast bort när den virtuella datorn returneras till Azure. Det vill: hanterade diskar kopplas aldrig från en virtuell dator så länge de ingår i en beräkning som körs. Om du vill skala ned användningen av hanterade diskar rekommenderar Azure Databricks att du använder den här funktionen i beräkning som konfigurerats med autoscaling compute eller automatisk avslutning.
Lokal diskkryptering
Viktigt!
Den här funktionen finns i offentlig förhandsversion.
Vissa instanstyper som du använder för att köra beräkning kan ha lokalt anslutna diskar. Azure Databricks kan lagra shuffle-data eller tillfälliga data på dessa lokalt anslutna diskar. För att säkerställa att alla vilande data krypteras för alla lagringstyper, inklusive shuffle-data som lagras tillfälligt på beräkningsresursens lokala diskar, kan du aktivera lokal diskkryptering.
Viktigt!
Dina arbetsbelastningar kan köras långsammare på grund av prestandapåverkan vid läsning och skrivning av krypterade data till och från lokala volymer.
När lokal diskkryptering är aktiverat genererar Azure Databricks en krypteringsnyckel lokalt som är unik för varje beräkningsnod och som används för att kryptera alla data som lagras på lokala diskar. Omfånget för nyckeln är lokalt för varje beräkningsnod och förstörs tillsammans med själva beräkningsnoden. Under dess livslängd finns nyckeln i minnet för kryptering och dekryptering och lagras krypterad på disken.
Om du vill aktivera lokal diskkryptering måste du använda kluster-API:et. När beräkning skapas eller redigeras anger du enable_local_disk_encryption till true.
Apache Spark-konfiguration
Om du vill finjustera Spark-jobb kan du ange anpassade Spark-konfigurationsegenskaper.
På sidan för beräkningskonfiguration klickar du på växlingsknappen Avancerat .
Klicka på fliken Spark .
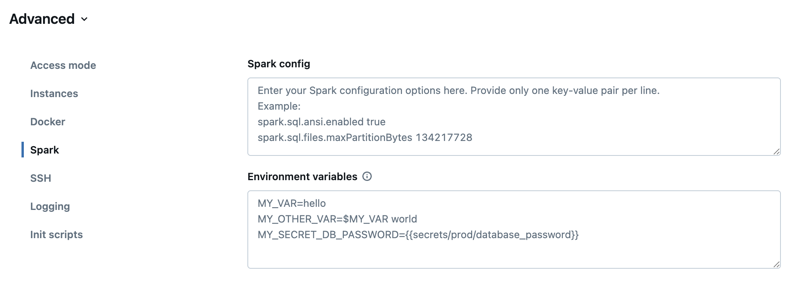
I Spark-konfiguration anger du konfigurationsegenskaperna som ett nyckel/värde-par per rad.
När du konfigurerar beräkning med hjälp av kluster-API:et anger du Spark-egenskaper i spark_conf fältet i API:et create cluster eller Update cluster API.
För att framtvinga Spark-konfigurationer på beräkning kan arbetsyteadministratörer använda beräkningsprinciper.
Hämta en Spark-konfigurationsinställning från ett hemligt system.
Databricks rekommenderar att du lagrar känslig information, till exempel lösenord, i en hemlighet i stället för i klartext. Om du vill referera till en hemlighet i Spark-konfigurationen använder du följande syntax:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Om du till exempel vill ange en Spark-konfigurationsegenskap som anropas password till värdet för hemligheten som lagras i secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Mer information finns i Hantera hemligheter.
Leverans av dataloggar
När du skapar beräkning för alla syften eller jobb kan du ange en plats för klusterloggar, inklusive loggar från Spark-drivrutinen, arbetsnoder och händelser. Loggar levereras var femte minut och arkiveras varje timme i det valda målet. Databricks fortsätter att leverera loggar tills beräkningsresursen har avslutats.
Du kan lagra loggar på någon av följande platser:
- Volymer (rekommenderas): Lagrar loggar i en volymsökväg i Unity Catalog. Detta är det rekommenderade och säkraste alternativet när du använder Unity Catalog-aktiverade beräkningsresurser.
- DBFS (äldre): Lagrar loggar i DBFS-sökvägen (Databricks File System). Det här alternativet är bara tillgängligt om DBFS-roten och monteringarna inte är inaktiverade för arbetsytan. Se Inaktivera åtkomst till DBFS-rotmappen och dess monteringar i din befintliga Azure Databricks-arbetsyta.
Så här konfigurerar du loggleveransplatsen:
- På beräkningssidan klickar du på växlingsknappen Avancerat .
- Klicka på fliken Loggning .
- Välj en måltyp.
- Ange loggsökvägen .
För att lagra loggarna skapar Databricks en undermapp i den valda loggsökvägen som namnges efter beräkningens cluster_id.
Om den angivna loggsökvägen till exempel är /Volumes/catalog/schema/volumelevereras loggar för 06308418893214 till /Volumes/catalog/schema/volume/06308418893214.
Anteckning
Att leverera loggar till en volym stöds endast på Unity Catalog-aktiverad beräkning med standardåtkomstläge eller dedikerat åtkomstläge som tilldelats en användare. Det stöds inte med dedikerat åtkomstläge som tilldelats till en grupp. Om du väljer en volym som sökväg kontrollerar du att beräkningens ägare eller den användare som tilldelats den har behörigheterna READ VOLUME och WRITE VOLUME på volymen. Se Behörigheter för Unity Catalog-volymer.
SSH-åtkomst till beräkning
Av säkerhetsskäl stängs SSH-porten som standard i Azure Databricks. Om du vill aktivera SSH-åtkomst till dina Spark-kluster, se SSH till drivrutinsnoden.
Anteckning
SSH kan aktiveras endast om arbetsytan distribueras i ditt eget Azure-virtuella nätverk.
Miljövariabler
Konfigurera anpassade miljövariabler som du kan komma åt från init-skript som körs på beräkningsresursen. Databricks innehåller också fördefinierade miljövariabler som du kan använda i init-skript. Du kan inte åsidosätta dessa fördefinierade miljövariabler.
På sidan för beräkningskonfiguration klickar du på Avancerat.
Klicka på fliken Spark .
Ange miljövariablerna i fältet Miljövariabler .
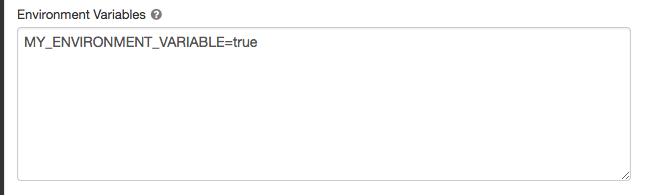
Du kan också ange miljövariabler med hjälp spark_env_vars av fältet i API:et Skapa kluster eller Uppdatera kluster-API.