Så här skapar och frågar du ett vektorsökningsindex
Den här artikeln beskriver hur du skapar och frågar ett vektorsökningsindex med hjälp av Mosaic AI Vector Search.
Du kan skapa och hantera vektorsökningskomponenter, till exempel en slutpunkt för vektorsökning och vektorsökningsindex, med hjälp av användargränssnittet, Python SDK eller REST-API:et.
Krav
- Unity Catalog-aktiverad arbetsyta.
- Serverlös beräkning aktiverad.
- Källtabellen måste ha Ändringsdataflöde aktiverat.
- Om du vill skapa ett index måste du ha CREATE TABLE-behörigheter för katalogscheman för att skapa index. Om du vill köra frågor mot ett index som ägs av en annan användare måste du ha ytterligare behörigheter. Se Fråga en slutpunkt för vektorsökning.
- Om du vill använda personliga åtkomsttoken (rekommenderas inte för produktionsarbetsbelastningar) kontrollerar du att personliga åtkomsttoken är aktiverade. Om du vill använda en token för tjänstens huvudnamn i stället skickar du den explicit med SDK- eller API-anrop.
Om du vill använda SDK:et måste du installera det i notebook-filen. Använd följande kod:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
Skapa en slutpunkt för vektorsökning
Du kan skapa en slutpunkt för vektorsökning med hjälp av Databricks-användargränssnittet, Python SDK eller API:et.
Skapa en slutpunkt för vektorsökning med hjälp av användargränssnittet
Följ de här stegen för att skapa en slutpunkt för vektorsökning med hjälp av användargränssnittet.
Klicka på Beräkning i det vänstra sidofältet.
Klicka på fliken Vektorsökning och klicka på Skapa.

Formuläret Skapa slutpunkt öppnas. Ange ett namn för den här slutpunkten.
Klicka på Bekräfta.
Skapa en slutpunkt för vektorsökning med Hjälp av Python SDK
I följande exempel används funktionen create_endpoint() SDK för att skapa en slutpunkt för vektorsökning.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Skapa en slutpunkt för vektorsökning med hjälp av REST-API:et
Se POST /api/2.0/vector-search/endpoints.
(Valfritt) Skapa och konfigurera en slutpunkt för att hantera inbäddningsmodellen
Om du väljer att låta Databricks beräkna inbäddningarna kan du använda en förkonfigurerad FOUNDATION Model-API:er-slutpunkt eller skapa en modell som betjänar slutpunkten för att hantera den inbäddningsmodell du väljer. Mer information finns i Api:er för Grundmodell för betalning per token eller Skapa generativ AI-modell som betjänar slutpunkter. Exempel på notebook-filer finns i Notebook-exempel för att anropa en inbäddningsmodell.
När du konfigurerar en inbäddningsslutpunkt rekommenderar Databricks att du tar bort standardvalet Skala till noll. Det kan ta några minuter att värma upp serverdelsslutpunkterna, och den första frågan i ett index med en nedskalad slutpunkt kan överskrida tidsgränsen.
Kommentar
Initieringen av vektorsökningsindexet kan överskrida tidsgränsen om inbäddningsslutpunkten inte är korrekt konfigurerad för datauppsättningen. Du bör bara använda CPU-slutpunkter för små datamängder och tester. För större datamängder använder du en GPU-slutpunkt för optimala prestanda.
Skapa ett vektorsökningsindex
Du kan skapa ett vektorsökningsindex med hjälp av användargränssnittet, Python SDK eller REST-API:et. Användargränssnittet är den enklaste metoden.
Det finns två typer av index:
- Delta Sync Index synkroniseras automatiskt med en deltatabell för källan, och uppdaterar automatiskt indexet när underliggande data i deltatabellen ändras.
- Direct Vector Access Index stöder direkt läsning och skrivning av vektorer och metadata. Användaren ansvarar för att uppdatera den här tabellen med hjälp av REST API eller Python SDK. Det går inte att skapa den här typen av index med hjälp av användargränssnittet. Du måste använda REST-API:et eller SDK:n.
Skapa index med hjälp av användargränssnittet
I det vänstra sidofältet klickar du på Katalog för att öppna katalogutforskarens användargränssnitt.
Gå till den Delta-tabell som du vill använda.
Klicka på knappen Skapa längst upp till höger och välj Vektorsökningsindex i den nedrullningsbara menyn.
Använd väljarna i dialogrutan för att konfigurera indexet.
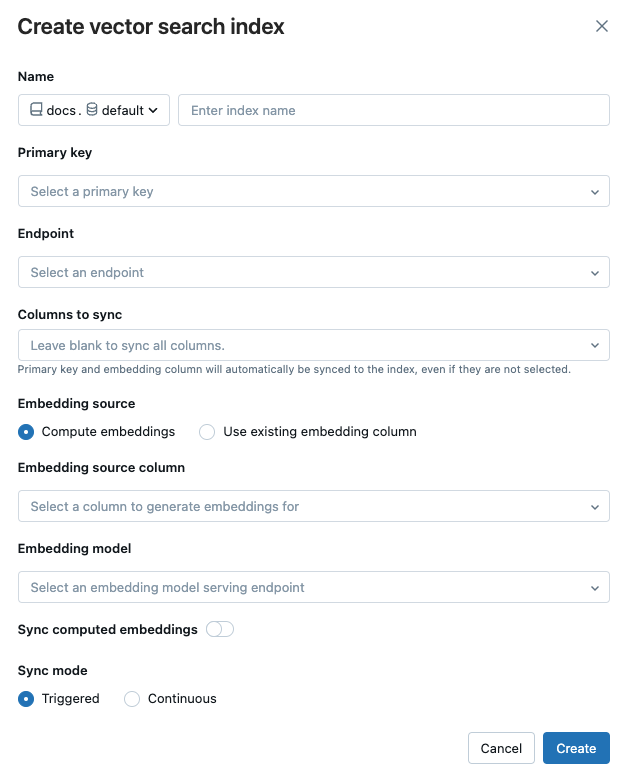
Namn: Namn som ska användas för onlinetabellen i Unity Catalog. Namnet kräver ett namnområde på tre nivåer,
<catalog>.<schema>.<name>. Endast alfanumeriska tecken och understreck tillåts.Primärnyckel: Kolumn som ska användas som primärnyckel.
Slutpunkt: Välj den slutpunkt för vektorsökning som du vill använda.
Inbäddningskälla: Ange om du vill att Databricks ska beräkna inbäddningar för en textkolumn i Delta-tabellen (Beräkningsinbäddningar) eller om deltatabellen innehåller förberäknade inbäddningar (Använd befintlig inbäddningskolumn).
- Om du har valt Beräkningsinbäddningar väljer du den kolumn som du vill att inbäddningar ska beräknas för och slutpunkten som betjänar inbäddningsmodellen. Endast textkolumner stöds.
- Om du har valt Använd befintlig inbäddningskolumn väljer du den kolumn som innehåller de förberäknade inbäddningarna och inbäddningsdimensionen. Formatet för den förberäknade inbäddningskolumnen ska vara
array[float].
Synkronisera beräknade inbäddningar: Växla den här inställningen för att spara de genererade inbäddningarna i en Unity Catalog-tabell. Mer information finns i Spara genererad inbäddningstabell.
Synkroniseringsläge: Kontinuerligt håller indexet synkroniserat med sekunders svarstid. Den har dock en högre kostnad som är associerad med den eftersom ett beräkningskluster har etablerats för att köra pipelinen för kontinuerlig synkroniseringsströmning. Utlöses är mer kostnadseffektivt, men måste startas manuellt med hjälp av API:et. För både Kontinuerlig och Utlöst är uppdateringen inkrementell – endast data som har ändrats sedan den senaste synkroniseringen bearbetas.
När du har konfigurerat indexet klickar du på Skapa.
Skapa index med Python SDK
I följande exempel skapas ett Delta Sync-index med inbäddningar som beräknas av Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
I följande exempel skapas ett Delta Sync-index med självhanterade inbäddningar.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
I följande exempel skapas ett direktvektoråtkomstindex.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "str",
"field3": "float",
"text_vector": "array<float>"}
)
Skapa index med hjälp av REST-API:et
Se POST /api/2.0/vector-search/indexes.
Spara genererad inbäddningstabell
Om Databricks genererar inbäddningarna kan du spara de genererade inbäddningarna i en tabell i Unity Catalog. Den här tabellen skapas i samma schema som vektorindexet och länkas från vektorindexsidan.
Namnet på tabellen är namnet på vektorsökningsindexet, som läggs till av _writeback_table. Namnet kan inte redigeras.
Du kan komma åt och köra frågor mot tabellen på samma sätt som andra tabeller i Unity Catalog. Du bör dock inte släppa eller ändra tabellen eftersom den inte är avsedd att uppdateras manuellt. Tabellen tas bort automatiskt om indexet tas bort.
Uppdatera ett vektorsökningsindex
Uppdatera ett Delta Sync-index
Index som skapas med läget För kontinuerlig synkronisering uppdateras automatiskt när deltatabellen för källan ändras. Om du använder utlöst synkroniseringsläge kan du använda Python SDK eller REST-API:et för att starta synkroniseringen.
Python SDK
index.sync()
REST-API
Se REST API (POST /api/2.0/vector-search/indexes/{index_name}/sync).
Uppdatera ett direktvektoråtkomstindex
Du kan använda Python SDK eller REST API för att infoga, uppdatera eller ta bort data från ett Direct Vector Access Index.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST-API
Se REST API (POST /api/2.0/vector-search/indexes).
Fråga en slutpunkt för vektorsökning
Du kan bara köra frågor mot slutpunkten för vektorsökning med hjälp av Python SDK, REST API eller SQL vector_search() AI-funktionen.
Kommentar
Om användaren som frågar slutpunkten inte är ägare till vektorsökningsindexet måste användaren ha följande UC-behörigheter:
- ANVÄND KATALOG i katalogen som innehåller vektorsökningsindexet.
- ANVÄND SCHEMA för schemat som innehåller vektorsökningsindexet.
- VÄLJ på vektorsökningsindexet.
Om du vill utföra en hybridsökning med nyckelordslikhet anger du parametern query_type till hybrid. Standardvärdet är ann (ungefärlig närmaste granne).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST-API
Se POST /api/2.0/vector-search/indexes/{index_name}/query.
SQL
Viktigt!
vector_search() AI-funktionen finns i offentlig förhandsversion.
Information om hur du använder den här AI-funktionen finns i funktionen vector_search.
Använda filter för frågor
En fråga kan definiera filter baserat på valfri kolumn i Delta-tabellen. similarity_search returnerar endast rader som matchar de angivna filtren. Följande filter stöds:
| Filteroperator | Funktionssätt | Exempel |
|---|---|---|
NOT |
Negerar filtret. Nyckeln måste sluta med "NOT". Till exempel matchar "color NOT" med värdet "red" dokument där färgen inte är röd. | {"id NOT": 2} {“color NOT”: “red”} |
< |
Kontrollerar om fältvärdet är mindre än filtervärdet. Nyckeln måste sluta med " <". Till exempel matchar "price <" med värdet 100 dokument där priset är mindre än 100. | {"id <": 200} |
<= |
Kontrollerar om fältvärdet är mindre än eller lika med filtervärdet. Nyckeln måste sluta med " <=". Till exempel matchar "price <=" med värdet 100 dokument där priset är mindre än eller lika med 100. | {"id <=": 200} |
> |
Kontrollerar om fältvärdet är större än filtervärdet. Nyckeln måste sluta med " >". Till exempel matchar "price >" med värdet 100 dokument där priset är större än 100. | {"id >": 200} |
>= |
Kontrollerar om fältvärdet är större än eller lika med filtervärdet. Nyckeln måste sluta med " >=". Till exempel matchar "price >=" med värdet 100 dokument där priset är större än eller lika med 100. | {"id >=": 200} |
OR |
Kontrollerar om fältvärdet matchar något av filtervärdena. Nyckeln måste innehålla OR för att avgränsa flera undernycklar. Med värdet matchar till exempel color1 OR color2 dokument där antingen color1 är red eller color2 är blue.["red", "blue"] |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Matchar partiella strängar. | {"column LIKE": "hello"} |
| Ingen filteroperator har angetts | Filtrera söker efter en exakt matchning. Om flera värden anges matchar det något av värdena. | {"id": 200} {"id": [200, 300]} |
Se följande kodexempel:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]}
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]}
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"}
num_results=2
)
REST-API
Se POST /api/2.0/vector-search/indexes/{index_name}/query.
Exempel på notebook-filer
Exemplen i det här avsnittet visar användningen av Python SDK för vektorsökning.
LangChain-exempel
Se Använda LangChain med Mosaic AI Vector Search för att använda Mosaic AI Vector Search som i integrering med LangChain-paket.
Följande notebook-fil visar hur du konverterar sökresultat för likhet till LangChain-dokument.
Vektorsökning med Python SDK-notebook-filen
Notebook-exempel för att anropa en inbäddningsmodell
Följande notebook-filer visar hur du konfigurerar en mosaik-AI-modell som betjänar slutpunkten för inbäddningsgenerering.
Anropa en OpenAI-inbäddningsmodell med hjälp av Mosaic AI Model Serving Notebook
Anropa en GTE-inbäddningsmodell med hjälp av Mosaic AI Model Serving Notebook
Registrera och hantera en OSS-inbäddningsmodellanteckningsbok
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för