Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln innehåller rekommendationer och resurser för att konfigurera beräkning för Lakeflow-jobb.
Viktigt!
Begränsningar för serverlös beräkning för jobb inkluderar följande:
- Inget stöd för kontinuerlig schemaläggning.
- Inget stöd för standard- eller tidsbaserade intervallutlösare i Strukturerad direktuppspelning.
Fler begränsningar finns i Begränsningar för serverlös beräkning.
Varje jobb kan ha en eller flera uppgifter. Du definierar beräkningsresurser för varje aktivitet. Flera uppgifter som definierats för samma jobb kan använda samma beräkningsresurs.
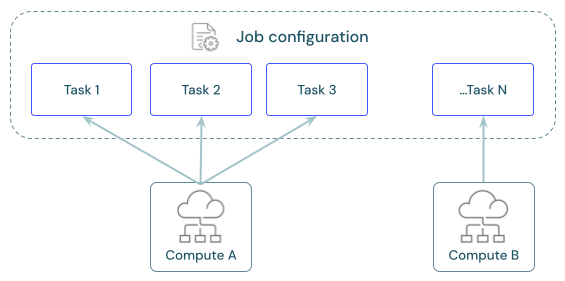
Vilken är den rekommenderade beräkningen för varje uppgift?
I följande tabell visas de rekommenderade och beräkningstyper som stöds för varje aktivitetstyp.
Anteckning
Serverlös beräkning för jobb har begränsningar och stöder inte alla arbetsbelastningar. Se Begränsningar för serverlös beräkning.
| Uppgift | Rekommenderad beräkning | Beräkning som stöds |
|---|---|---|
| Anteckningsböcker | Serverlösa jobb | Serverlösa jobb, klassiska jobb, klassiska allmänna ändamål |
| Python-skript | Serverlösa jobb | Serverlösa jobb, klassiska jobb, klassiska allmänna ändamål |
| Python-hjul | Serverlösa jobb | Serverlösa jobb, klassiska jobb, klassiska allmänna ändamål |
| SQL | Serverlöst SQL-lager | Serverlöst SQL-lager, pro SQL-lager |
| Deklarativa pipelines för Lakeflow Spark | Serverfri pipelina | Serverlös pipeline, klassisk pipeline |
| dbt | Serverlöst SQL-lager | Serverlöst SQL-lager, pro SQL-lager |
| dbt CLI-kommandon | Serverlösa jobb | Serverlösa jobb, klassiska jobb, klassiska allmänna ändamål |
| GLASBURK | Klassiska jobb | Klassiska jobb, klassiska mångsidiga |
| Spark Submit-kommandon | Klassiska jobb | Klassiska jobb |
Prissättningen för Lakeflow-jobb är kopplad till den beräkning som används för att köra uppgifter. Mer information finns i Databricks-priser.
Hur konfigurerar jag datorresurser för jobben?
Beräkning av klassiska jobb konfigureras direkt från användargränssnittet för Lakeflow-jobb och dessa konfigurationer ingår i jobbdefinitionen. Alla andra tillgängliga beräkningstyper lagrar sina konfigurationer med andra arbetsytetillgångar. Följande tabell innehåller mer information:
| Typ av beräkning | Detaljer |
|---|---|
| Beräkning av klassiska jobb | Du konfigurerar beräkning för klassiska jobb med samma användargränssnitt och inställningar som är tillgängliga för all-purpose compute. Se Referens för beräkningskonfiguration. |
| Serverlös beräkning för jobb | Serverlös beräkning för jobb är standard för alla uppgifter som stöder det. Databricks hanterar beräkningsinställningar för serverlös beräkning. Se Köra lakeflow-jobb med serverlös beräkning för arbetsflöden. |
| SQL-lager | Serverlösa och pro SQL-lager konfigureras av arbetsyteadministratörer eller användare med obegränsad behörighet att skapa kluster. Du konfigurerar aktiviteter som ska köras mot befintliga SQL-lager. Se Ansluta till ett SQL-lager. |
| Beräkning av deklarativa pipelines för Lakeflow Spark | Du konfigurerar beräkningsinställningar för deklarativa Lakeflow Spark-pipelines under pipeline-konfigurationen. För pipelines, se Konfigurera klassisk beräkning. Azure Databricks hanterar beräkningsresurser för serverlösa Lakeflow Spark-deklarativa pipelines. Se Konfigurera en serverlös pipeline. |
| Mångsidig beräkning | Du kan valfritt konfigurera uppgifter med klassisk all-purpose compute. Databricks rekommenderar inte den här konfigurationen för produktionsjobb. Se: Referens för beräkningskonfiguration och Ska generell datoranvändning någonsin användas för jobb?. |
Dela beräkning mellan uppgifter
Konfigurera uppgifter för att använda samma jobbberäkningsresurser för att optimera resursanvändningen med jobb som samordnar flera uppgifter. Att dela beräkning mellan aktiviteter kan minska svarstiden som är associerad med starttider.
Du kan använda en beräkningsresurs för ett enda jobb för att köra alla aktiviteter som ingår i jobbet eller flera jobbresurser som är optimerade för specifika arbetsbelastningar. Alla jobbberäkning som konfigurerats som en del av ett jobb är tillgängliga för alla andra aktiviteter i jobbet.
I följande tabell visas skillnader mellan jobbberäkning som konfigurerats för en enskild uppgift och jobbberäkning som delas mellan aktiviteter:
| Enskild uppgift | Delas mellan uppgifter | |
|---|---|---|
| Starta | När uppgiften körs igång. | När den första aktivitetskörningen som konfigurerats för att använda beräkningsresursen börjar. |
| Avsluta | När uppgiften är klar. | Efter att den sista uppgiften som konfigurerats för att använda beräkningsresursen har körts. |
| Inaktiv beräkning | Ej tillämpbart. | Beräkningsresursen förblir påslagen och inaktiv medan uppgifter som inte använder beräkningsresursen körs. |
Ett delat jobbkluster är begränsat till en enda jobbkörning och kan inte användas av andra jobb eller körningar av samma jobb.
Bibliotek kan inte deklareras i en klusterkonfiguration för delat jobb. Du måste lägga till beroende bibliotek i aktivitetsinställningarna.
Delat drivrutinstillstånd för aktiviteter
När flera aktiviteter delar en jobbberäkningsresurs körs aktiviteterna på samma JVM-drivrutin. Klasstillstånd och singletons bevaras mellan uppgifter under jobbkörningen. För de flesta arbetsbelastningar är detta transparent, men tänk på följande konsekvenser:
- Scala-singletons och tillhörande objekt delas mellan aktiviteter. Det föränderliga tillståndet i ett Scala-tilläggsobjekt bevaras mellan aktiviteter som körs i samma delade kluster. Om parallella uppgifter läses från eller skrivs till samma variabel för tillhörande objekt kan en aktivitets värde skriva över en annans. Ett fungerande exempel finns i kunskapsbasartikeln Arbetsflöden för flera aktiviteter med felaktiga parametervärden.
- Bibliotek som läses in av en aktivitet är fortfarande tillgängliga för efterföljande aktiviteter under hela jobbkörningen.
Om koden kräver isolering på aktivitetsnivå använder du någon av följande metoder:
- Konfigurera varje uppgift så att den använder en separat jobbberäkningsresurs.
- Lägg till explicita aktivitetsberoenden så att aktiviteterna körs sekventiellt i stället för parallellt.
- Omstrukturera koden för att undvika att förlita sig på singleton-tillstånd eller delat föränderligt tillstånd. Du kan till exempel uttryckligen skicka parametrar till varje funktion i stället för att läsa dem från ett tillhörande objekt.
Granska, konfigurera och byta beräkningsresurser för jobb
Avsnittet Beräkning i panelen Jobbinformation visar en lista över alla beräkningar som konfigurerats för aktiviteter i det aktuella jobbet.
Uppgifter som konfigurerats för att använda en beräkningsresurs markeras i aktivitetsdiagrammet när du hovra över beräkningsspecifikationen.
Använd knappen Växla för att ändra beräkningen för alla aktiviteter som är associerade med en beräkningsresurs.
Beräkningsresurser för klassiska jobb har alternativet Konfigurera . Andra beräkningsresurser ger dig alternativ för att visa och ändra information om beräkningskonfiguration.
Mer information
Mer information om hur du konfigurerar klassiska Azure Databricks-jobb finns i Metodtips för att konfigurera klassiska Lakeflow-jobb.