Introduktion till Databricks Lakehouse Monitoring
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Den här artikeln beskriver Databricks Lakehouse Monitoring. Den omfattar fördelarna med att övervaka dina data och ger en översikt över komponenterna och användningen av Databricks Lakehouse Monitoring.
Med Databricks Lakehouse Monitoring kan du övervaka statistiska egenskaper och datakvalitet i alla tabeller i ditt konto. Du kan också använda den för att spåra prestanda för maskininlärningsmodeller och modellbetjäningsslutpunkter genom att övervaka slutsatsdragningstabeller som innehåller modellindata och förutsägelser. Diagrammet visar dataflödet via data- och ML-pipelines i Databricks och hur du kan använda övervakning för att kontinuerligt spåra datakvalitet och modellprestanda.
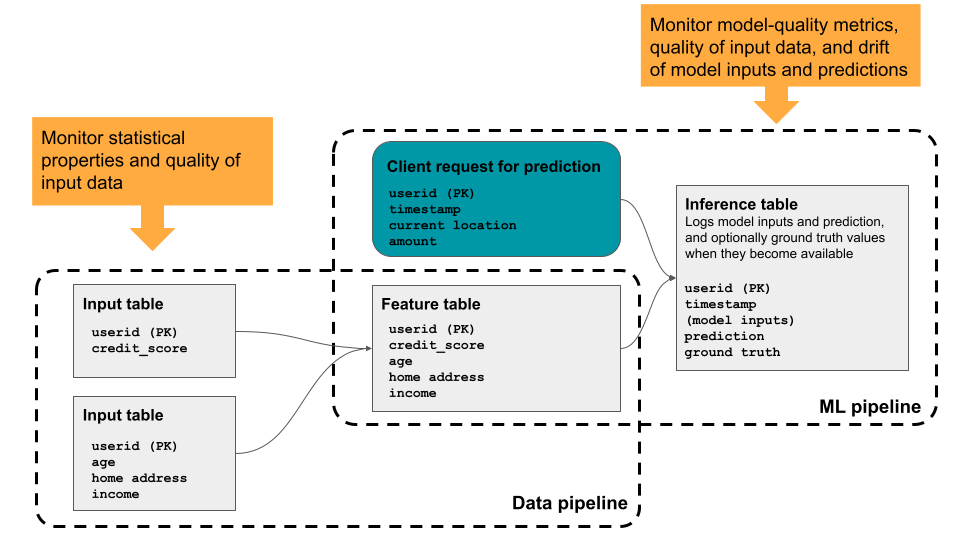
Varför ska du använda Databricks Lakehouse Monitoring?
För att få användbara insikter från dina data måste du ha förtroende för kvaliteten på dina data. Övervakning av dina data innehåller kvantitativa mått som hjälper dig att spåra och bekräfta kvaliteten och konsekvensen i dina data över tid. När du identifierar ändringar i tabellens datadistribution eller motsvarande modells prestanda kan tabellerna som skapats av Databricks Lakehouse Monitoring samla in och varna dig för ändringen och kan hjälpa dig att identifiera orsaken.
Databricks Lakehouse Monitoring hjälper dig att besvara frågor som följande:
- Hur ser dataintegriteten ut och hur ändras den över tid? Till exempel, vad är fraktionen av null- eller nollvärden i aktuella data och har den ökat?
- Hur ser den statistiska fördelningen av data ut och hur ändras den över tid? Vad är till exempel den 90:e percentilen i en numerisk kolumn? Eller vad är fördelningen av värden i en kategorisk kolumn, och hur skiljer det sig från igår?
- Finns det en avvikelse mellan aktuella data och en känd baslinje, eller mellan efterföljande tidsfönster för data?
- Hur ser den statistiska fördelningen eller avvikelsen för en delmängd eller sektor av data ut?
- Hur skiftar ML-modellindata och förutsägelser över tid?
- Hur trendar modellprestanda över tid? Presterar modellversion A bättre än version B?
Dessutom kan du med Databricks Lakehouse Monitoring styra tidskornigheten för observationer och konfigurera anpassade mått.
Krav
Följande krävs för att använda Databricks Lakehouse Monitoring:
- Arbetsytan måste vara aktiverad för Unity Catalog och du måste ha åtkomst till Databricks SQL.
- Endast Delta-tabeller, inklusive hanterade tabeller, externa tabeller, vyer, materialiserade vyer och strömmande tabeller, stöds för övervakning. Övervakare som skapats över materialiserade vyer och strömmande tabeller stöder inte inkrementell bearbetning.
- Alla regioner stöds inte. Regionalt stöd finns i Azure Databricks-regioner.
Kommentar
Databricks Lakehouse Monitoring använder serverlös beräkning för arbetsflöden. Information om hur du spårar Lakehouse-övervakningskostnader finns i Visa lakehouseövervakningskostnader.
Så här fungerar Lakehouse Monitoring på Databricks
Om du vill övervaka en tabell i Databricks skapar du en övervakare som är kopplad till tabellen. Om du vill övervaka prestanda för en maskininlärningsmodell kopplar du övervakaren till en slutsatsdragningstabell som innehåller modellens indata och motsvarande förutsägelser.
Databricks Lakehouse Monitoring tillhandahåller följande typer av analys: tidsserier, ögonblicksbilder och slutsatsdragningar.
| Profiltyp | beskrivning |
|---|---|
| Tidsserier | Använd för tabeller som innehåller en tidsseriedatauppsättning baserat på en tidsstämpelkolumn. Övervakning beräknar datakvalitetsmått i tidsbaserade fönster i tidsserien. |
| Slutsatsdragning | Används för tabeller som innehåller begärandeloggen för en modell. Varje rad är en begäran, med kolumner för tidsstämpeln , modellindata, motsvarande förutsägelse och (valfritt) mark-sanningsetikett. Övervakning jämför modellprestanda och datakvalitetsmått i tidsbaserade fönster i begärandeloggen. |
| Ögonblicksbild | Används för alla andra typer av tabeller. Övervakning beräknar datakvalitetsmått för alla data i tabellen. Den fullständiga tabellen bearbetas med varje uppdatering. |
I det här avsnittet beskrivs kortfattat de indatatabeller som används av Databricks Lakehouse Monitoring och de måtttabeller som skapas. Diagrammet visar relationen mellan indatatabellerna, måtttabellerna, övervakaren och instrumentpanelen.
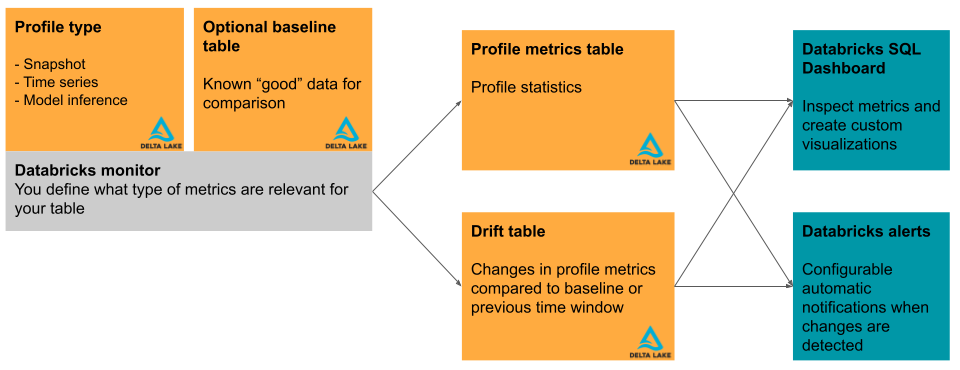
Primär tabell och baslinjetabell
Förutom den tabell som ska övervakas, som kallas "primär tabell", kan du också ange en baslinjetabell som ska användas som referens för att mäta avdrift eller ändring i värden över tid. En baslinjetabell är användbar när du har ett exempel på hur du förväntar dig att dina data ska se ut. Tanken är att driften sedan beräknas i förhållande till förväntade datavärden och distributioner.
Baslinjetabellen bör innehålla en datauppsättning som återspeglar den förväntade kvaliteten på indata, när det gäller statistiska fördelningar, enskilda kolumnfördelningar, saknade värden och andra egenskaper. Det bör matcha schemat för den övervakade tabellen. Undantaget är tidsstämpelkolumnen för tabeller som används med tidsserie- eller slutsatsdragningsprofiler. Om kolumner saknas i antingen den primära tabellen eller baslinjetabellen använder övervakningen heuristik med bästa förmåga för att beräkna utdatamåtten.
För övervakare som använder en ögonblicksbildsprofil ska baslinjetabellen innehålla en ögonblicksbild av de data där fördelningen representerar en acceptabel kvalitetsstandard. När det till exempel gäller klassificeringsdistributionsdata kan man ange baslinjen till en tidigare klass där betygen fördelades jämnt.
För övervakare som använder en tidsserieprofil bör baslinjetabellen innehålla data som representerar tidsfönster där datadistributioner representerar en acceptabel kvalitetsstandard. När det till exempel gäller väderdata kan du ställa in baslinjen på en vecka, månad eller år där temperaturen var nära förväntade normala temperaturer.
För övervakare som använder en slutsatsdragningsprofil är ett bra val för en baslinje de data som användes för att träna eller verifiera modellen som övervakas. På så sätt kan användare aviseras när data har drivits i förhållande till vad modellen har tränats och verifierats på. Den här tabellen bör innehålla samma funktionskolumner som den primära tabellen och dessutom ha samma model_id_col som angavs för den primära tabellens InferenceLog så att data aggregeras konsekvent. Helst bör test- eller valideringsuppsättningen som används för att utvärdera modellen användas för att säkerställa jämförbara modellkvalitetsmått.
Måtttabeller och instrumentpanel
En tabellövervakare skapar två måtttabeller och en instrumentpanel. Måttvärden beräknas för hela tabellen och för de tidsfönster och dataunderuppsättningar (eller "sektorer") som du anger när du skapar övervakaren. För slutsatsdragningsanalys beräknas dessutom mått för varje modell-ID. Mer information om måtttabellerna finns i Övervaka måtttabeller.
- Tabellen för profilmått innehåller sammanfattningsstatistik. Se tabellschemat för profilmått.
- Tabellen driftmått innehåller statistik som rör datas drift över tid. Om en baslinjetabell tillhandahålls övervakas även drift i förhållande till baslinjevärdena. Se tabellschemat för driftmått.
Måtttabellerna är Delta-tabeller och lagras i ett Unity Catalog-schema som du anger. Du kan visa dessa tabeller med hjälp av Databricks-användargränssnittet, köra frågor mot dem med Hjälp av Databricks SQL och skapa instrumentpaneler och aviseringar baserat på dem.
För varje övervakare skapar Databricks automatiskt en instrumentpanel som hjälper dig att visualisera och presentera övervakningsresultaten. Instrumentpanelen är helt anpassningsbar som alla andra äldre instrumentpaneler.
Börja använda Lakehouse Monitoring på Databricks
Se följande artiklar för att komma igång:
- Skapa en övervakare med hjälp av Databricks-användargränssnittet.
- Skapa en övervakare med hjälp av API:et.
- Förstå övervaka måtttabeller.
- Arbeta med övervakningsinstrumentpanelen.
- Skapa SQL-aviseringar baserat på en övervakare.
- Skapa anpassade mått.
- Övervaka modell som betjänar slutpunkter.
- Övervaka rättvisa och bias för klassificeringsmodeller.
- Se referensmaterialet för Databricks Lakehouse Monitoring API.
- Exempel på notebook-filer.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för