Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
En pipeline kan innehålla flera flöden som är nästan identiska och som bara skiljer sig från några få parametrar. Att definiera dessa flöden explicit är felbenäget, redundant och svårt att underhålla. Metaprogrammering med Python inre funktioner genererar repetitiva flöden dynamiskt, där varje anrop tillhandahåller en annan uppsättning parametrar.
Översikt
Metaprogrammering i Lakeflow Spark deklarativa pipelines använder interna Python-funktioner. Eftersom dessa funktioner fördröjd utvärderas av pipeline-körmiljön kan du inkapsla @dp.table dekoratörer inom en fabriksfunktion och anropa denna funktion flera gånger med olika argument. Varje anrop registrerar ett nytt flöde utan att duplicera kod.
Mer information om hur du använder for-loopar med Lakeflow Spark Deklarativa Pipelines kan du läsa i avsnittet Skapa tabeller i en for loop.
Exempel: brandkårens svarstider
I följande exempel används den inbyggda datauppsättningen för brandkåren för att hitta de stadsdelar som har de snabbaste nödsituationstiderna för varje samtalstyp. Utan metaprogrammering måste du skriva nästan identiska tabelldefinitioner för varje samtalstyp (larm, strukturbrand, medicinsk incident). Med metaprogrammering genererar en enda fabriksfunktion alla.
Steg 1: Definiera tabellen för rå inmatning
import functools
from pyspark import pipelines as dp
from pyspark.sql.functions import *
@dp.table(
name="raw_fire_department",
comment="raw table for fire department response"
)
@dp.expect_or_drop("valid_received", "received IS NOT NULL")
@dp.expect_or_drop("valid_response", "responded IS NOT NULL")
@dp.expect_or_drop("valid_neighborhood", "neighborhood != 'None'")
def get_raw_fire_department():
return (
spark.read.format('csv')
.option('header', 'true')
.option('multiline', 'true')
.load('/databricks-datasets/timeseries/Fires/Fire_Department_Calls_for_Service.csv')
.withColumnRenamed('Call Type', 'call_type')
.withColumnRenamed('Received DtTm', 'received')
.withColumnRenamed('Response DtTm', 'responded')
.withColumnRenamed('Neighborhooods - Analysis Boundaries', 'neighborhood')
.select('call_type', 'received', 'responded', 'neighborhood')
)
Steg 2: Definiera flödesfabriksfunktionen
Fabriksfunktionen generate_tables registrerar två tabeller för varje anropstyp: en filtrerad anropstabell och en rangordnad svarstidstabell. Båda skapas som inre funktioner dekorerade med @dp.table.
all_tables = []
def generate_tables(call_table, response_table, filter):
@dp.table(
name=call_table,
comment="top level tables by call type"
)
def create_call_table():
return spark.sql("""
SELECT
unix_timestamp(received,'M/d/yyyy h:m:s a') as ts_received,
unix_timestamp(responded,'M/d/yyyy h:m:s a') as ts_responded,
neighborhood
FROM raw_fire_department
WHERE call_type = '{filter}'
""".format(filter=filter))
@dp.table(
name=response_table,
comment="top 10 neighborhoods with fastest response time"
)
def create_response_table():
return spark.sql("""
SELECT
neighborhood,
AVG((ts_received - ts_responded)) as response_time
FROM {call_table}
GROUP BY 1
ORDER BY response_time
LIMIT 10
""".format(call_table=call_table))
all_tables.append(response_table)
Steg 3: Anropa fabriken och definiera sammanfattningstabellen
Anropa fabriken en gång för varje anropstyp och definiera sedan en sammanfattningstabell som samlar resultaten för att hitta de stadsdelar som oftast visas i alla kategorier.
generate_tables("alarms_table", "alarms_response", "Alarms")
generate_tables("fire_table", "fire_response", "Structure Fire")
generate_tables("medical_table", "medical_response", "Medical Incident")
@dp.table(
name="best_neighborhoods",
comment="which neighbor appears in the best response time list the most"
)
def summary():
target_tables = [dp.read(t) for t in all_tables]
unioned = functools.reduce(lambda x, y: x.union(y), target_tables)
return (
unioned.groupBy(col("neighborhood"))
.agg(count("*").alias("score"))
.orderBy(desc("score"))
)
När du har kört den här pipelinen skapar du en uppsättning liknande tabeller, som den här grafen:
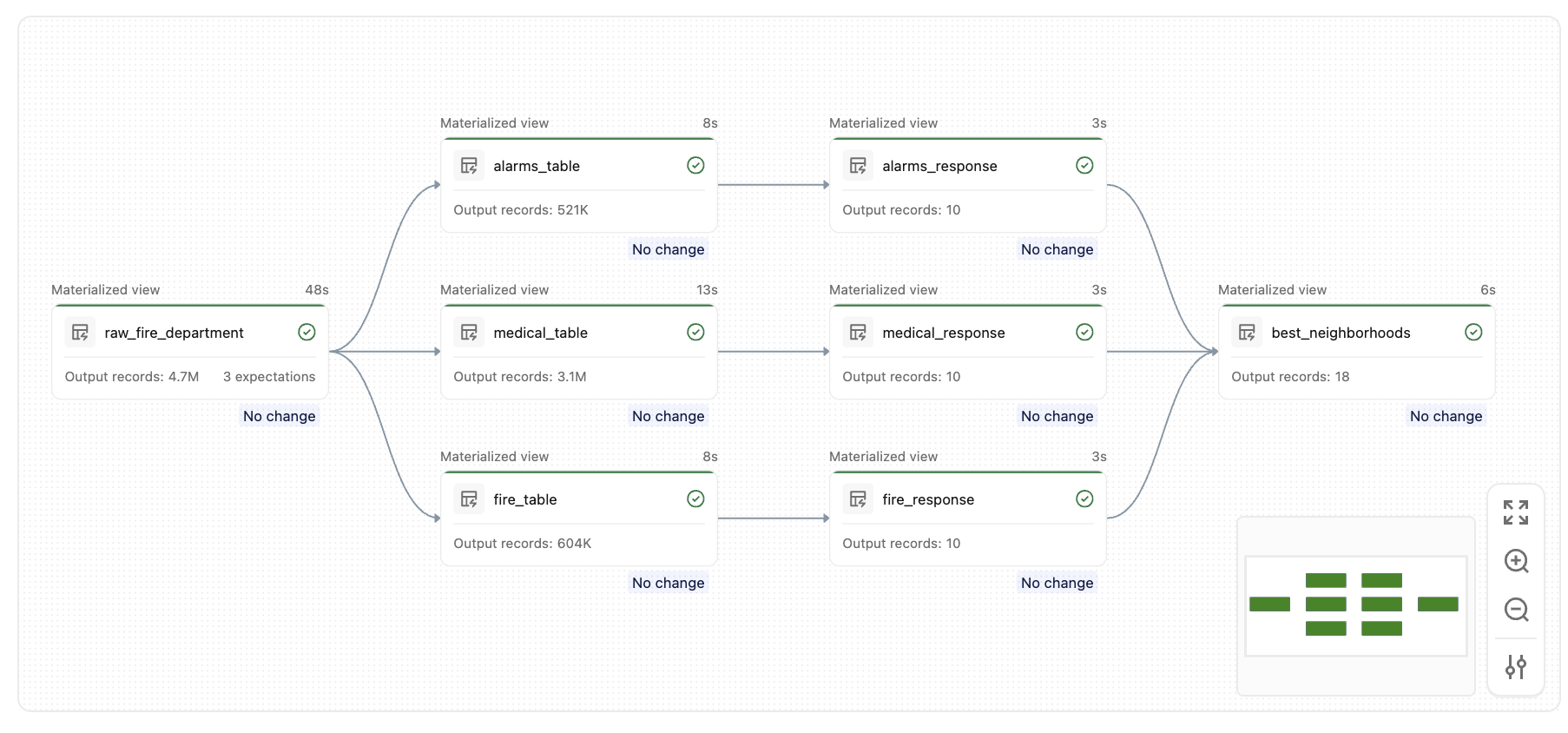
Viktiga begrepp
-
Inre funktioner registreras fördröjt: Dekoratören
@dp.tablekör inte funktionen direkt. Den registrerar funktionen med pipeline-körsystemet, som bestämmer hela dataflödesschemat innan exekveringen börjar. -
Closures fångar upp parametrar: Varje inre funktion fångar upp parametrarna som skickas till fabriken (
call_table,response_table,filter), så att varje registrerat flöde använder sitt eget isolerade värdeset. -
Dynamiska tabelllistor: Om du använder en lista som
all_tablesatt spåra programmatiskt genererade tabellnamn blir det enkelt att referera till dem senare (till exempel i en union eller koppling).