Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Du skapar en ny Lakeflow-pipeline för dataorkestrering med Auto Loader och utökar sedan exempelpipelinen genom att rensa data och skapa en fråga för att hitta de 100 främsta användarna.
I den här självstudien lär du dig hur du använder Lakeflow Pipelines-redigeraren för att:
- Skapa en ny pipeline med standardmappstrukturen och börja med en uppsättning exempelfiler.
- Definiera datakvalitetsbegränsningar med hjälp av förväntningar.
- Använd redigeringsfunktionerna för att utöka pipelinen med en ny transformering för att utföra analys av dina data.
Kravspecifikation
Innan du påbörjar den här självstudien måste du:
- Loggas in på en Azure Databricks arbetsyta.
- Låt Unity Catalog vara aktiverat för din arbetsyta.
- Ha behörighet att skapa en beräkningsresurs eller åtkomst till en beräkningsresurs.
- Ha behörighet att skapa ett nytt schema i en katalog. De behörigheter som krävs är
ALL PRIVILEGESellerUSE CATALOGochCREATE SCHEMA. - Fullständig uppsättning behörigheter som krävs för att skapa, köra, uppdatera och visa pipelines och deras utdata finns i Hantera identiteter, behörigheter och behörigheter för pipelines.
Steg 1: Skapa en pipeline
I det här steget skapar du en pipeline med hjälp av standardmappstrukturen och kodexempel. Kodexemplen refererar till users tabellen i wanderbricks exempeldatakällan.
I din Azure Databricks arbetsyta klickar du på
 Ny, sedan
Ny, sedan  ETL-pipeline. Då öppnas pipelineredigeraren med ett standardnamn för pipelinen, till exempel
ETL-pipeline. Då öppnas pipelineredigeraren med ett standardnamn för pipelinen, till exempel New Pipeline <date> <time>.(Valfritt) Välj namnet och ange ett beskrivande namn för pipelinen.
(Valfritt) Till höger om namnet klickar du på katalogen och schemat för att ange olika standardvärden.
(Valfritt) I den
my_transformationkällfil som skapats åt dig väljer du Python eller SQL i listrutan språk för att ange språket för filen.Klicka på
 Använd exempelkod.
Använd exempelkod.Exempelkoden på det valda språket visas i
my_transformationkällfilen itransformationsmappen. Utdatauppsättningarna har ännu inte skapats och pipelinediagrammet till höger på skärmen är tomt.Om du vill köra pipelinekoden (koden i
transformationsmappen) klickar du på Kör pipeline i den övre högra delen av skärmen.När körningen är klar visas de två nya tabeller som skapades i den nedre delen av arbetsytan,
sample_users_<date_time>ochsample_aggregation_<date_time>. Diagrammet Pipeline till höger på arbetsytan visar nu de två tabellerna, inklusive källansample_usersförsample_aggregation. Anteckna det fullständigasample_users_<date_time>tabellnamnet. Du refererar till det i nästa steg.
Steg 2: Tillämpa datakvalitetskontroller
I det här steget lägger du till en datakvalitetskontroll i sample_users tabellen. Du använder pipeline-förväntningar för att begränsa data. I det här fallet tar du bort alla användarposter som inte har en giltig e-postadress och matar ut den rensade tabellen som users_cleaned.
I resursbläddraren för pipeline till vänster klickar du på
och väljer Transformation.I dialogrutan Skapa ny transformeringsfil gör du följande val:
- Välj antingen Python eller SQL för Language. Detta behöver inte matcha ditt tidigare val.
- Ge filen ett namn. I det här fallet väljer du
users_cleaned. - För Målsökväg lämnar du standardvärdet.
- För Datauppsättningstyp lämnar du den antingen som Ingen markerad eller väljer Materialiserad vy. Om du väljer Materialiserad vy genererar den exempelkod åt dig.
Klicka på Skapa för att skapa transformeringskodfilen.
I den nya kodfilen redigerar du koden så att den matchar följande (använd SQL eller Python, baserat på ditt val på föregående skärm). Ersätt
sample_users_<date_time>med det fullständiga namnet på tabellensample_usersfrån föregående avsnitt.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<date_time>;Python
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<date_time>") )Klicka på Kör pipeline för att uppdatera pipelinen. Den bör nu ha tre tabeller.
Steg 3: Analysera de främsta användarna
Få sedan de 100 bästa användarna efter antalet bokningar som de har skapat. Koppla tabellen wanderbricks.bookings till den users_cleaned materialiserade vyn.
I pipeline-resursbläddraren till vänster klickar du på
och väljer Transformation.I dialogrutan Skapa ny transformeringsfil gör du följande val:
- Välj antingen Python eller SQL för Language. Detta behöver inte matcha dina tidigare val.
- Ge filen ett namn. I det här fallet väljer du
users_and_bookings. - För Målsökväg lämnar du standardvärdet.
- För Datauppsättningstyp låter du det vara som Inget valt.
Klicka på Skapa för att skapa transformeringskodfilen.
I den nya kodfilen redigerar du koden så att den matchar följande (använd SQL eller Python, baserat på ditt val på föregående skärm).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Python
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Klicka på Kör pipeline för att uppdatera datamängderna. När körningen är klar kan du se i Pipeline Graph att det finns fyra tabeller, inklusive den nya
users_and_bookingstabellen.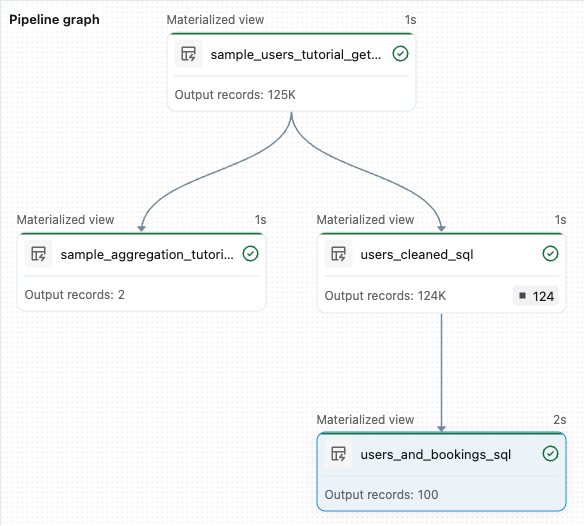
Ytterligare resurser
Nu när du har lärt dig hur du använder några av funktionerna i Lakeflow Pipelines-redigeraren och skapat en pipeline, finns här några andra funktioner för att lära dig mer om:
Verktyg för att arbeta med och felsöka transformeringar när du skapar pipelines:
- Selektiv exekvering
- Dataförhandsgranskningar
- Interaktiv pipelinediagram (diagram över datauppsättningarna i din pipeline)
Inbyggd deklarativ Automation-paketintegrering för effektivt samarbete, versionskontroll och CI/CD-integrering direkt från redigeraren: