Api:er för grundmodell för etablerat dataflöde
Den här artikeln visar hur du distribuerar modeller med foundation model-API:er med etablerat dataflöde. Databricks rekommenderar etablerat dataflöde för produktionsarbetsbelastningar och ger optimerad slutsatsdragning för grundmodeller med prestandagarantier.
En lista över modellarkitekturer som stöds finns i API:er för etablering av dataflödesmodell.
Krav
Se krav.
För att distribuera finjusterade grundmodeller,
- Din modell måste loggas med MLflow 2.11 eller senare, ELLER Databricks Runtime 15.0 ML eller senare.
- Databricks rekommenderar att du använder modeller i Unity Catalog för snabbare uppladdning och nedladdning av stora modeller.
[Rekommenderas] Distribuera grundläggande grundmodeller från Databricks Marketplace
Du kan installera grundläggande grundmodeller i Unity Catalog med hjälp av Databricks Marketplace.
Databricks rekommenderar att du installerar grundmodeller med Databricks Marketplace. Du kan söka efter en modellfamilj och från modellsidan kan du välja Hämta åtkomst och ange inloggningsuppgifter för att installera modellen i Unity Catalog.
När modellen har installerats i Unity Catalog kan du skapa en modell som betjänar slutpunkten med hjälp av användargränssnittet för servering. Se Skapa din etablerade dataflödesslutpunkt med hjälp av användargränssnittet.
DBRX-modeller från Databricks Marketplace
Databricks rekommenderar att du hanterar DBRX Instruct-modellen för dina arbetsbelastningar. Om du vill hantera DBRX Base- och DBRX Instruct-modellerna med etablerat dataflöde måste du följa anvisningarna i föregående avsnitt för att installera dessa modeller i Unity Catalog från Databricks Marketplace.
När du hanterar dessa DBRX-modeller stöder etablerat dataflöde en kontextlängd på upp till 16 000. Större kontextstorlekar kommer snart.
DBRX-modeller använder följande standardsystemprompt för att säkerställa relevans och noggrannhet i modellsvar:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
Logga finjusterade grundmodeller
Om du inte kan installera modellen från Databricks Marketplace kan du distribuera en finjusterad grundmodell genom att logga den till Unity Catalog. Följande visar hur du konfigurerar koden för att logga en MLflow-modell till Unity Catalog:
mlflow.set_registry_uri('databricks-uc')
CATALOG = "ml"
SCHEMA = "llm-catalog"
MODEL_NAME = "mpt" # or "bge"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Du kan logga din modell med MLflow-smaken transformers och ange uppgiftsargumentet med rätt modelltypsgränssnitt från följande alternativ:
task="llm/v1/completions"task="llm/v1/chat"task="llm/v1/embeddings"
Dessa argument anger API-signaturen som används för modellen som betjänar slutpunkten, och modeller som loggas på det här sättet är berättigade till etablerat dataflöde.
Modeller som loggas från sentence_transformers paketet har också stöd för att definiera slutpunktstypen "llm/v1/embeddings" .
För modeller som loggas med MLflow 2.12 eller senare log_model anger metadatatask argumentet task nyckelns värde automatiskt. task Om argumentet och metadatatask argumentet är inställda på olika värden utlöses ettException.
Följande är ett exempel på hur du loggar en textkompletteringsspråkmodell som loggats med MLflow 2.12 eller senare:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b-instruct",torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
task="llm/v1/completions",
registered_model_name=registered_model_name
)
För modeller som loggas med MLflow 2.11 eller senare kan du ange gränssnittet för slutpunkten med hjälp av följande metadatavärden:
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
Följande är ett exempel på hur du loggar en textkompletteringsspråkmodell som loggats med MLflow 2.11 eller senare:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b-instruct",torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
task="llm/v1/completions",
metadata={"task": "llm/v1/completions"},
registered_model_name=registered_model_name
)
Etablerat dataflöde stöder även både den lilla och stora BGE-inbäddningsmodellen. Följande är ett exempel på hur du loggar modellen, BAAI/bge-small-en-v1.5 så att den kan hanteras med etablerat dataflöde med MLflow 2.11 eller senare:
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-small-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="bge-small-transformers",
task="llm/v1/embeddings",
metadata={"task": "llm/v1/embeddings"}, # not needed for MLflow >=2.12.1
registered_model_name=registered_model_name
)
När du loggar en finjusterad BGE-modell måste du också ange model_type metadatanyckel:
metadata={
"task": "llm/v1/embeddings",
"model_type": "bge-large" # Or "bge-small"
}
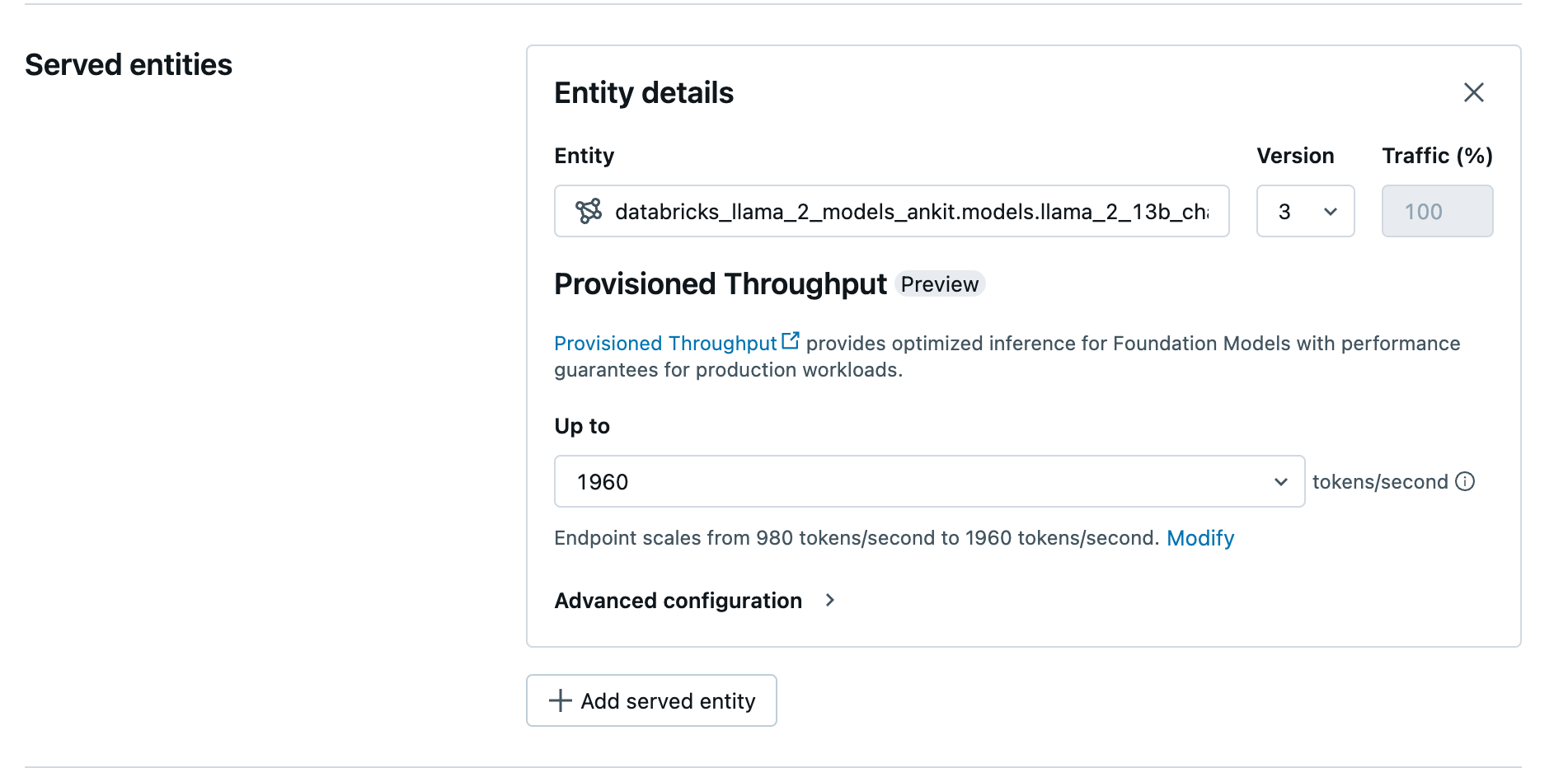
Skapa din etablerade dataflödesslutpunkt med hjälp av användargränssnittet
När den loggade modellen finns i Unity Catalog skapar du en etablerad dataflödesserverslutpunkt med följande steg:
- Gå till användargränssnittet för servering på din arbetsyta.
- Välj Skapa serverdelsslutpunkt.
- I fältet Entitet väljer du din modell från Unity Catalog. För berättigade modeller visar användargränssnittet för den serverade entiteten skärmen Etablerat dataflöde.
- I listrutan Upp till kan du konfigurera det maximala dataflödet för token per sekund för slutpunkten.
- Etablerade dataflödesslutpunkter skalas automatiskt så att du kan välja Ändra för att visa de minsta token per sekund som slutpunkten kan skalas ned till.
Skapa din etablerade dataflödesslutpunkt med hjälp av REST-API:et
Om du vill distribuera din modell i etablerat dataflödesläge med hjälp av REST-API:et måste du ange min_provisioned_throughput och max_provisioned_throughput fält i din begäran.
Information om det lämpliga intervallet för etablerat dataflöde för din modell finns i Hämta etablerat dataflöde i steg.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "llama2-13b-chat"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.llama-13b"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().get()
API_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Hämta etablerat dataflöde i steg
Etablerat dataflöde är tillgängligt i steg av token per sekund med specifika steg som varierar efter modell. För att identifiera det lämpliga intervallet för dina behov rekommenderar Databricks att du använder API:et för modelloptimeringsinformation på plattformen.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
Följande är ett exempelsvar från API:et:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Notebook-exempel
Följande notebook-filer visar exempel på hur du skapar ett etablerat dataflödes-API för Foundation Model:
Etablerad dataflödesservering för Llama2-modellanteckningsbok
Etablerad dataflödesservering för Mistral-modellanteckningsboken
Etablerat dataflöde för BGE-modellanteckningsbok
Begränsningar
- Modelldistributionen kan misslyckas på grund av GPU-kapacitetsproblem, vilket resulterar i en tidsgräns när slutpunkten skapas eller uppdateras. Kontakta ditt Databricks-kontoteam för att lösa problemet.
- Automatisk skalning för FOUNDATION Models-API:er är långsammare än processormodellservern. Databricks rekommenderar överetablering för att undvika tidsgränser för begäranden.
Ytterligare resurser
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för