Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Den här artikeln beskriver två vanliga mönster för att flytta ML-artefakter via mellanlagring och till produktion. Asynkrona ändringar i modeller och kod innebär att det finns flera möjliga mönster som en ML-utvecklingsprocess kan följa.
Modeller skapas med kod, men de resulterande modellartefakterna och koden som skapade dem kan fungera asynkront. Nya modellversioner och kodändringar kanske inte sker samtidigt. Ta exempelvis följande scenarier:
- För att identifiera bedrägliga transaktioner utvecklar du en ML-pipeline som tränar om en modell varje vecka. Koden kanske inte ändras särskilt ofta, men modellen kan tränas om varje vecka för att införliva nya data.
- Du kan skapa ett stort, djupt neuralt nätverk för att klassificera dokument. I det här fallet är träning av modellen beräkningsmässigt dyr och tidskrävande, och omträning av modellen kommer sannolikt att ske sällan. Koden som distribuerar, hanterar och övervakar den här modellen kan dock uppdateras utan att modellen tränas om.
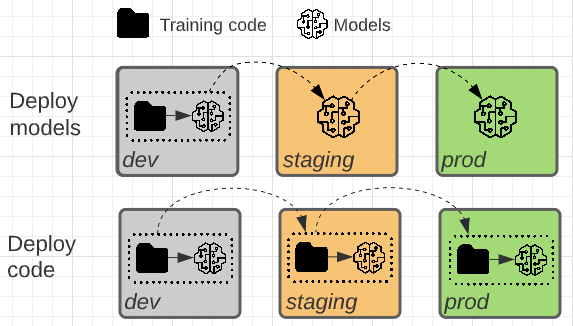
De två mönstren skiljer sig åt i huruvida modellartefakten eller träningskoden som genererar modellartefakten befordras till produktion.
Distribuera kod (rekommenderas)
I de flesta fall rekommenderar Databricks metoden "distribuera kod". Den här metoden ingår i det rekommenderade MLOps-arbetsflödet.
I det här mönstret utvecklas koden för att träna modeller i utvecklingsmiljön. Samma kod flyttas till mellanlagring och sedan produktion. Modellen tränas i varje miljö: ursprungligen i utvecklingsmiljön som en del av modellutvecklingen, i mellanlagring (på en begränsad delmängd av data) som en del av integreringstester och i produktionsmiljön (på fullständiga produktionsdata) för att producera den slutliga modellen.
Fördelar:
- I organisationer där åtkomsten till produktionsdata är begränsad tillåter det här mönstret att modellen tränas på produktionsdata i produktionsmiljön.
- Automatiserad omträning av modeller är säkrare eftersom träningskoden granskas, testas och godkänns för produktion.
- Stödkod följer samma mönster som modellträningskoden. Båda går igenom integreringstester i mellanlagring.
Nackdelar:
- Inlärningskurvan för dataforskare att lämna över kod till medarbetare kan vara brant. Fördefinierade projektmallar och arbetsflöden är användbara.
I det här mönstret måste dataexperter också kunna granska träningsresultat från produktionsmiljön, eftersom de har kunskap om att identifiera och åtgärda ML-specifika problem.
Om din situation kräver att modellen tränas i mellanlagring över den fullständiga produktionsdatauppsättningen kan du använda en hybridmetod genom att distribuera kod till mellanlagring, träna modellen och sedan distribuera modellen till produktion. Den här metoden sparar träningskostnader i produktion men lägger till en extra åtgärdskostnad i mellanlagringen.
Distribuera modeller
I det här mönstret genereras modellartefakten av träningskod i utvecklingsmiljön. Artefakten testas sedan i mellanlagringsmiljön innan den distribueras till produktion.
Överväg det här alternativet när ett eller flera av följande gäller:
- Modellträning är mycket dyrt eller svårt att återskapa.
- Allt arbete utförs på en enda Azure Databricks-arbetsyta.
- Du arbetar inte med externa lagringsplatser eller en CI/CD-process.
Fördelar:
- En enklare överlämning för dataforskare
- I de fall där modellträning är dyr behöver du bara träna modellen en gång.
Nackdelar:
- Om produktionsdata inte är tillgängliga från utvecklingsmiljön (vilket kan vara sant av säkerhetsskäl) kanske den här arkitekturen inte är användbar.
- Automatiserad omträning av modeller är knepigt i det här mönstret. Du kan automatisera omträningen i utvecklingsmiljön, men teamet som ansvarar för att distribuera modellen i produktion kanske inte accepterar den resulterande modellen som produktionsklar.
- Stödkod, till exempel pipelines som används för funktionsutveckling, slutsatsdragning och övervakning, måste distribueras till produktion separat.
Vanligtvis motsvarar en miljö (utveckling, mellanlagring eller produktion) en katalog i Unity Catalog. Mer information om hur du implementerar det här mönstret finns i uppgraderingsguiden.
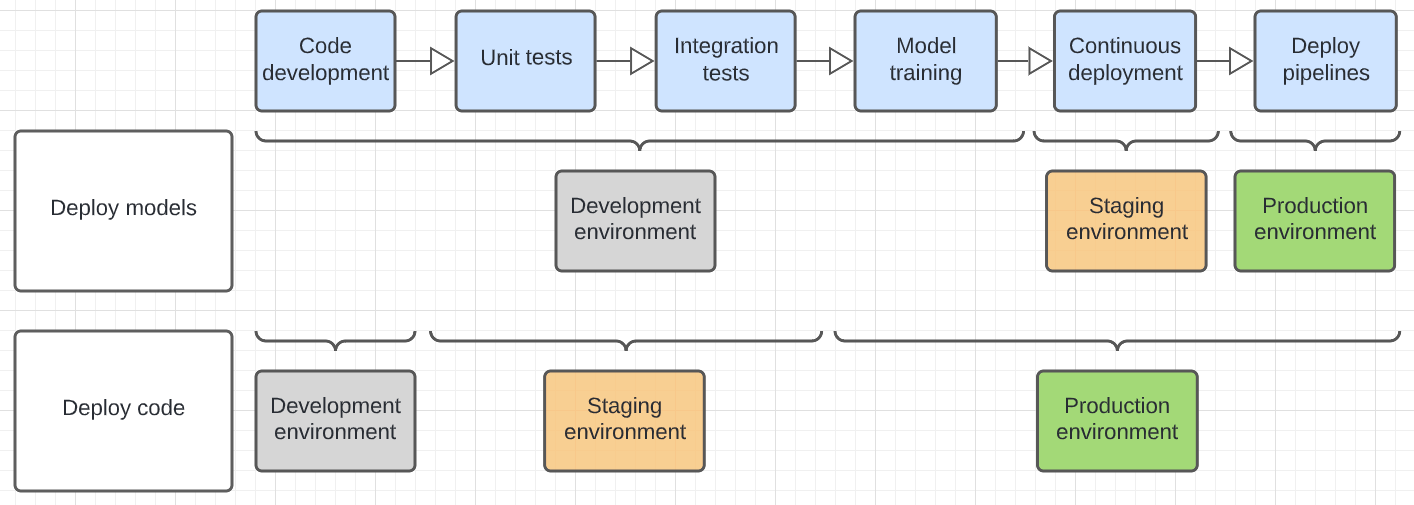
Diagrammet nedan kontrasterar kodlivscykeln för ovanstående distributionsmönster i de olika körningsmiljöerna.
Miljön som visas i diagrammet är den sista miljön där ett steg körs. I mönstret för distributionsmodeller utförs till exempel slutenhets- och integreringstestning i utvecklingsmiljön. I distributionskodmönstret körs enhetstester och integreringstester i utvecklingsmiljöerna, och den slutliga enhets- och integreringstestningen utförs i mellanlagringsmiljön.