Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln beskriver hur du kan använda MLOps på Databricks-plattformen för att optimera prestanda och långsiktig effektivitet för dina ML-system (Machine Learning). Den innehåller allmänna rekommendationer för en MLOps-arkitektur och beskriver ett generaliserat arbetsflöde med databricks-plattformen som du kan använda som modell för din ML-utveckling till produktionsprocess. Ändringar av det här arbetsflödet för LLMOps-program finns i LLMOps-arbetsflöden.
Mer information finns i The Big Book of MLOps.
Vad är MLOps?
MLOps är en uppsättning processer och automatiserade steg för att hantera kod, data och modeller för att förbättra prestanda, stabilitet och långsiktig effektivitet i ML-system. Den kombinerar DevOps, DataOps och ModelOps.

ML-tillgångar som kod, data och modeller utvecklas i steg som går från tidiga utvecklingsstadier som inte har snäva åtkomstbegränsningar och som inte testas noggrant, genom ett mellanliggande teststeg, till ett slutligt produktionsstadium som är noggrant kontrollerat. Med Databricks-plattformen kan du hantera dessa tillgångar på en enda plattform med enhetlig åtkomstkontroll. Du kan utveckla dataprogram och ML-program på samma plattform, vilket minskar riskerna och fördröjningarna i samband med att data flyttas runt.
Allmänna rekommendationer för MLOps
Det här avsnittet innehåller några allmänna rekommendationer för MLOps på Databricks med länkar för mer information.
Skapa en separat miljö för varje steg
En exekveringsmiljö är den plats där modeller och data skapas eller används av kod. Varje körningsmiljö består av beräkningsinstanser, deras runtimes och bibliotek samt automatiserade jobb.
Databricks rekommenderar att du skapar separata miljöer för de olika stegen i ML-kod och modellutveckling med tydligt definierade övergångar mellan steg. Arbetsflödet som beskrivs i den här artikeln följer den här processen med hjälp av vanliga namn för stegen:
Andra konfigurationer kan också användas för att uppfylla organisationens specifika behov.
Åtkomstkontroll och versionshantering
Åtkomstkontroll och versionshantering är viktiga komponenter i alla programvaruåtgärder. Databricks rekommenderar följande:
- Använd Git för versionskontroll. Pipelines och kod ska lagras i Git för versionskontroll. Att flytta ML-logik mellan faser kan sedan tolkas som att flytta kod från utvecklingsgrenen till mellanlagringsgrenen till versionsgrenen. Använd Databricks Git-mappar för att integrera med git-providern och synkronisera notebook-filer och källkod med Databricks-arbetsytor. Databricks tillhandahåller även ytterligare verktyg för Git-integrering och versionskontroll. se Lokala utvecklingsverktyg.
- Lagra data i en lakehouse-arkitektur med hjälp av Delta-tabeller. Data ska lagras i en lakehouse-arkitektur i ditt molnkonto. Både rådata och funktionstabeller ska lagras som Delta-tabeller med åtkomstkontroller för att avgöra vem som kan läsa och ändra dem.
- Hantera modellutveckling med MLflow. Du kan använda MLflow för att spåra modellutvecklingsprocessen och spara ögonblicksbilder av kod, modellparametrar, mått och andra metadata.
- Använd Modeller i Unity Catalog för att hantera modellens livscykel. Använd Modeller i Unity Catalog för att hantera modellversions-, styrnings- och distributionsstatus.
Distribuera kod, inte modeller
I de flesta situationer rekommenderar Databricks att du under ML-utvecklingsprocessen höjer upp kod, snarare än modeller, från en miljö till en annan. Om du flyttar projekttillgångar på det här sättet ser du till att all kod i ML-utvecklingsprocessen genomgår samma processer för kodgranskning och integreringstestning. Det säkerställer dessutom att produktionsversionen av modellen tränas med produktionskod. En mer detaljerad beskrivning av alternativ och kompromisser finns i Modelldistributionsmönster.
Rekommenderat MLOps-arbetsflöde
I följande avsnitt beskrivs ett typiskt MLOps-arbetsflöde som täcker vart och ett av de tre stegen: utveckling, mellanlagring och produktion.
I det här avsnittet används termerna "data scientist" och "ML Engineer" som arketypiska personas; specifika roller och ansvarsområden i MLOps-arbetsflödet varierar mellan team och organisationer.
Utvecklingsfas
Fokus för utvecklingssteget är experimentering. Dataforskare utvecklar funktioner och modeller och kör experiment för att optimera modellprestanda. Utdata från utvecklingsprocessen är ML-pipelinekod som kan innehålla funktionsberäkning, modellträning, slutsatsdragning och övervakning.
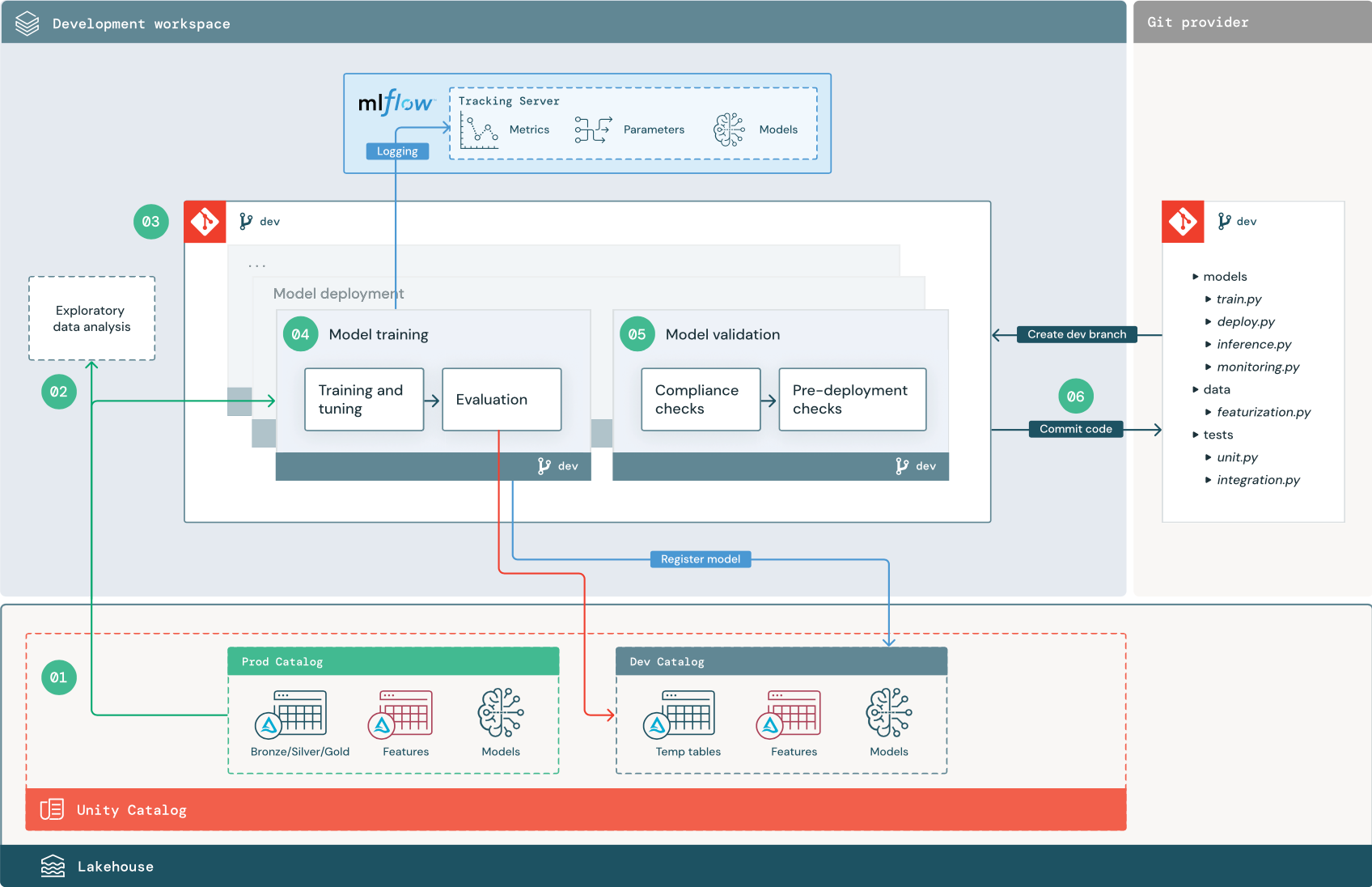
De numrerade stegen motsvarar de tal som visas i diagrammet.
1. Datakällor
Utvecklingsmiljön representeras av utvecklingskatalogen i Unity Catalog. Dataexperter har läs- och skrivåtkomst till utvecklingskatalogen när de skapar tillfälliga data- och funktionstabeller på arbetsytan utveckling. Modeller som skapats i utvecklingsfasen registreras i utvecklingskatalogen.
Dataforskare som arbetar på utvecklingsarbetsytan bör helst också ha skrivskyddad åtkomst till produktionsdata i produktionskatalogen. Genom att ge dataexperter läsåtkomst till produktionsdata, slutsatsdragningstabeller och måtttabeller i prod-katalogen kan de analysera förutsägelser och prestanda för den aktuella produktionsmodellen. Dataforskare bör också kunna läsa in produktionsmodeller för experimentering och analys.
Om det inte går att bevilja skrivskyddad åtkomst till prod-katalogen kan en ögonblicksbild av produktionsdata skrivas till utvecklingskatalogen så att dataforskare kan utveckla och utvärdera projektkod.
2. Undersökande dataanalys (EDA)
Dataexperter utforskar och analyserar data i en interaktiv, iterativ process med hjälp av notebook-filer. Målet är att utvärdera om tillgängliga data har potential att lösa affärsproblemet. I det här steget börjar dataexperten identifiera förberedelse- och funktionaliseringssteg för modellträning. Den här ad hoc-processen är vanligtvis inte en del av en pipeline som ska distribueras i andra körningsmiljöer.
AutoML påskyndar den här processen genom att generera baslinjemodeller för en datauppsättning. AutoML utför och registrerar en uppsättning utvärderingsversioner och tillhandahåller en Python-notebook-fil med källkoden för varje utvärderingskörning, så att du kan granska, återskapa och ändra koden. AutoML beräknar även sammanfattningsstatistik för din datamängd och sparar den här informationen i en notebook-fil som du kan granska.
3. Kod
Kodlagringsplatsen innehåller alla pipelines, moduler och andra projektfiler för ett ML-projekt. Dataforskare skapar nya eller uppdaterade pipelines i en utvecklingsgren ("dev") på projektlagringsplatsen. Från och med EDA och de inledande faserna i ett projekt bör dataexperter arbeta på en lagringsplats för att dela kod och spåra ändringar.
4. Träna modellen (i utvecklingsfasen)
Dataexperter utvecklar modellträningspipelinen i utvecklingsmiljön med hjälp av tabeller från utvecklingskatalogerna eller prod-katalogerna.
Den här pipelinen innehåller två uppgifter:
Träning och justering. Träningsprocessen loggar modellparametrar, mått och artefakter till MLflow Tracking-servern. Efter träning och justering av hyperparametrar loggas den slutliga modellartefakten till spårningsservern för att registrera en länk mellan modellen, indata som den tränades på och den kod som användes för att generera den.
Utvärdering. Utvärdera modellkvaliteten genom att testa på utelämnade data. Resultatet av dessa tester loggas till MLflow Tracking-servern. Syftet med utvärderingen är att avgöra om den nyutvecklade modellen presterar bättre än den aktuella produktionsmodellen. Med tillräcklig behörighet kan alla produktionsmodeller som är registrerade i prod-katalogen läsas in på utvecklingsarbetsytan och jämföras med en nytränad modell.
Om organisationens styrningskrav innehåller ytterligare information om modellen kan du spara den med hjälp av MLflow-spårning. Typiska artefakter är beskrivningar av oformaterad text och modelltolkningar, till exempel diagram som skapats av SHAP. Specifika styrningskrav kan komma från en datastyrningsansvarig eller affärsintressenter.
Utdata från modellträningspipelinen är en ML-modellartefakt som lagras i MLflow Tracking-servern för utvecklingsmiljön. Om pipelinen körs i staging- eller produktionsarbetsytan, lagras modellartefakten på MLflow Tracking-servern för den arbetsytan.
När modellträningen är klar registrerar du modellen i Unity Catalog. Konfigurera din pipelinekod för att registrera modellen till katalogen som motsvarar den miljö som modellpipelinen kördes i. i det här exemplet utvecklingskatalogen.
Med den rekommenderade arkitekturen distribuerar du ett Databricks-arbetsflöde med flera uppgifter där den första uppgiften är modellträningspipelinen, följt av modellverifiering och modelldistributionsuppgifter. Modellträningsaktiviteten ger en modell-URI som modellverifieringsuppgiften kan använda. Du kan använda aktivitetsvärden för att skicka den här URI:n till modellen.
5. Validera och distribuera modell (utveckling)
Förutom modellträningspipelinen utvecklas andra pipelines som modellvalidering och modelldistributionspipelines i utvecklingsmiljön.
Modellverifiering. Modellverifieringspipelinen tar modell-URI:n från modellträningspipelinen, läser in modellen från Unity Catalog och kör valideringskontroller.
Verifieringskontroller beror på kontexten. De kan omfatta grundläggande kontroller som att bekräfta format och nödvändiga metadata och mer komplexa kontroller som kan krävas för strikt reglerade branscher, till exempel fördefinierade efterlevnadskontroller och bekräfta modellprestanda för valda datasektorer.
Den primära funktionen för modellverifieringspipelinen är att avgöra om en modell ska gå vidare till distributionssteget. Om modellen klarar fördistributionskontroller kan den tilldelas aliaset "Challenger" i Unity Catalog. Om kontrollerna misslyckas avslutas processen. Du kan konfigurera arbetsflödet för att meddela användarna om ett valideringsfel. Se Lägg till notifikationer på ett jobb.
Modellimplementering. Modelldistributionspipelinen höjer vanligtvis direkt upp den nyligen tränade "Challenger"-modellen till "Champion"-status med hjälp av en aliasuppdatering, eller underlättar en jämförelse mellan den befintliga "Champion"-modellen och den nya "Challenger"-modellen. Den här pipelinen kan också konfigurera valfri nödvändig slutsatsdragningsinfrastruktur, till exempel modellserverslutpunkter. En detaljerad beskrivning av stegen i modelldistributionspipelinen finns i Produktion.
6. Incheckningskod
När du har utvecklat kod för träning, validering, distribution och andra pipelines genomför dataexperten eller ML-teknikern dev-grenändringarna i källkontrollen.
Förberedelsesteg
Fokus i det här steget är att testa ML-pipelinekoden för att säkerställa att den är redo för produktion. All ML-pipelinekod testas i det här steget, inklusive kod för modellträning samt funktionsutvecklingspipelines, slutsatsdragningskod och så vidare.
ML-tekniker skapar en CI-pipeline för att implementera de enhets- och integreringstester som körs i det här steget. Utdata från staging-processen är en utgåvegren som utlöser CI/CD-systemet att starta produktionsfasen.
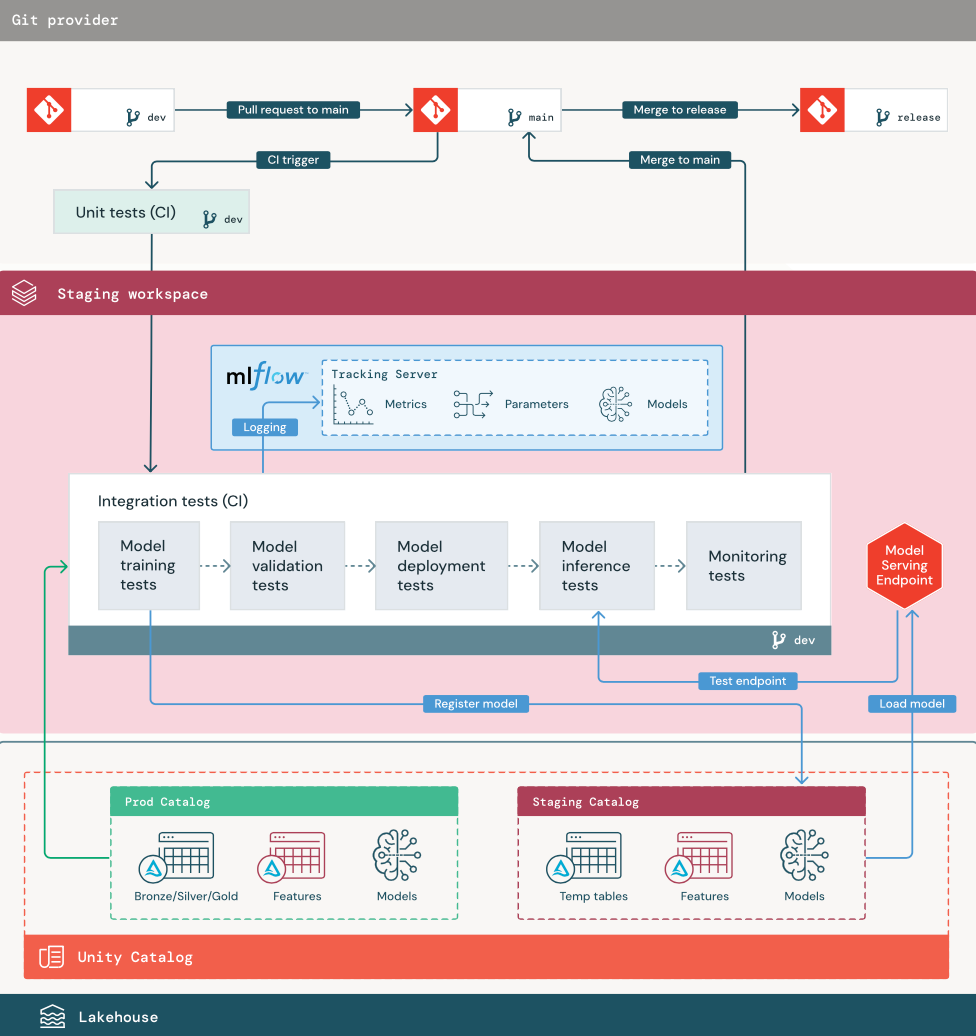
1. Data
Mellanlagringsmiljön bör ha en egen katalog i Unity Catalog för testning av ML-pipelines och registrering av modeller till Unity Catalog. Den här katalogen visas som "staging"-katalogen i diagrammet. Tillgångar som skrivs till den här katalogen är vanligtvis tillfälliga och behålls endast tills testningen är klar. Utvecklingsmiljön kan också kräva åtkomst till mellanlagringskatalogen i felsökningssyfte.
2. Sammanslagningskod
Dataexperter utvecklar modellträningspipelinen i utvecklingsmiljön med hjälp av tabeller från utvecklings- eller produktionskatalogerna.
Pull-förfrågan. Distributionsprocessen börjar när en pull request skapas för huvudgrenen för projektet i versionshanteringssystemet.
Enhetstester (CI). Pull-begäran bygger automatiskt källkod och startar enhetstester. Om enhetstesterna misslyckas avvisas pull-begäran.
Enhetstester är en del av programutvecklingsprocessen och körs kontinuerligt och läggs till i kodbasen under utvecklingen av valfri kod. Genom att köra enhetstester som en del av en CI-pipeline ser du till att ändringar som görs i en utvecklingsgren inte bryter befintliga funktioner.
3. Integrationstester (CI)
CI-processen kör sedan integreringstesterna. Integreringstester kör alla pipelines (inklusive funktionsutveckling, modellträning, slutsatsdragning och övervakning) för att säkerställa att de fungerar korrekt tillsammans. Mellanlagringsmiljön bör matcha produktionsmiljön så nära som det är rimligt.
Om du distribuerar ett ML-program med slutsatsdragning i realtid bör du skapa och testa infrastruktur för servering i mellanlagringsmiljön. Detta innebär att utlösa modelldistributionspipelinen, vilket skapar en tjänsteslutpunkt i testmiljön och laddar en modell.
För att minska den tid som krävs för att köra integrationstester kan några steg kompromissa mellan noggrannheten i testningen och fart eller kostnad. Om modeller till exempel är dyra eller tidskrävande att träna kan du använda små delmängder av data eller köra färre tränings iterationer. För modellservering kan du, beroende på produktionskraven, utföra fullskalig belastningstestning i integrationstester, eller så kanske du bara testar små batchjobb eller begäranden till en tillfällig slutpunkt.
4. Sammanfoga till mellanlagringsgren
Om alla tester godkänns sammanfogas den nya koden till huvudgrenen i projektet. Om testerna misslyckas bör CI/CD-systemet meddela användarna och publicera resultat på pull-begäran.
Du kan schemalägga regelbundna integreringstester på huvudgrenen. Det här är en bra idé om grenen uppdateras ofta med samtidiga pull-begäranden från flera användare.
5. Skapa en versionsgren
När CI-testerna har godkänts och utvecklingsgrenen har sammanfogats till huvudgrenen skapar ML-teknikern en versionsgren som utlöser CI/CD-systemet för att uppdatera produktionsjobb.
Steget Produktion
ML-tekniker äger produktionsmiljön där ML-pipelines distribueras och körs. Dessa pipelines utlöser modellträning, validerar och distribuerar nya modellversioner, publicerar förutsägelser till underordnade tabeller eller program och övervakar hela processen för att undvika prestandaförsämring och instabilitet.
Dataexperter har vanligtvis inte skriv- eller beräkningsåtkomst i produktionsmiljön. Det är dock viktigt att de har insyn i testrapporter, loggar, modellartefakter, status för produktionspipeline och övervakningstabeller. Med den här synligheten kan de identifiera och diagnostisera problem i produktionen och jämföra prestanda för nya modeller med modeller som för närvarande är i produktion. Du kan bevilja dataforskare skrivskyddad åtkomst till tillgångar i produktionskatalogen för dessa ändamål.
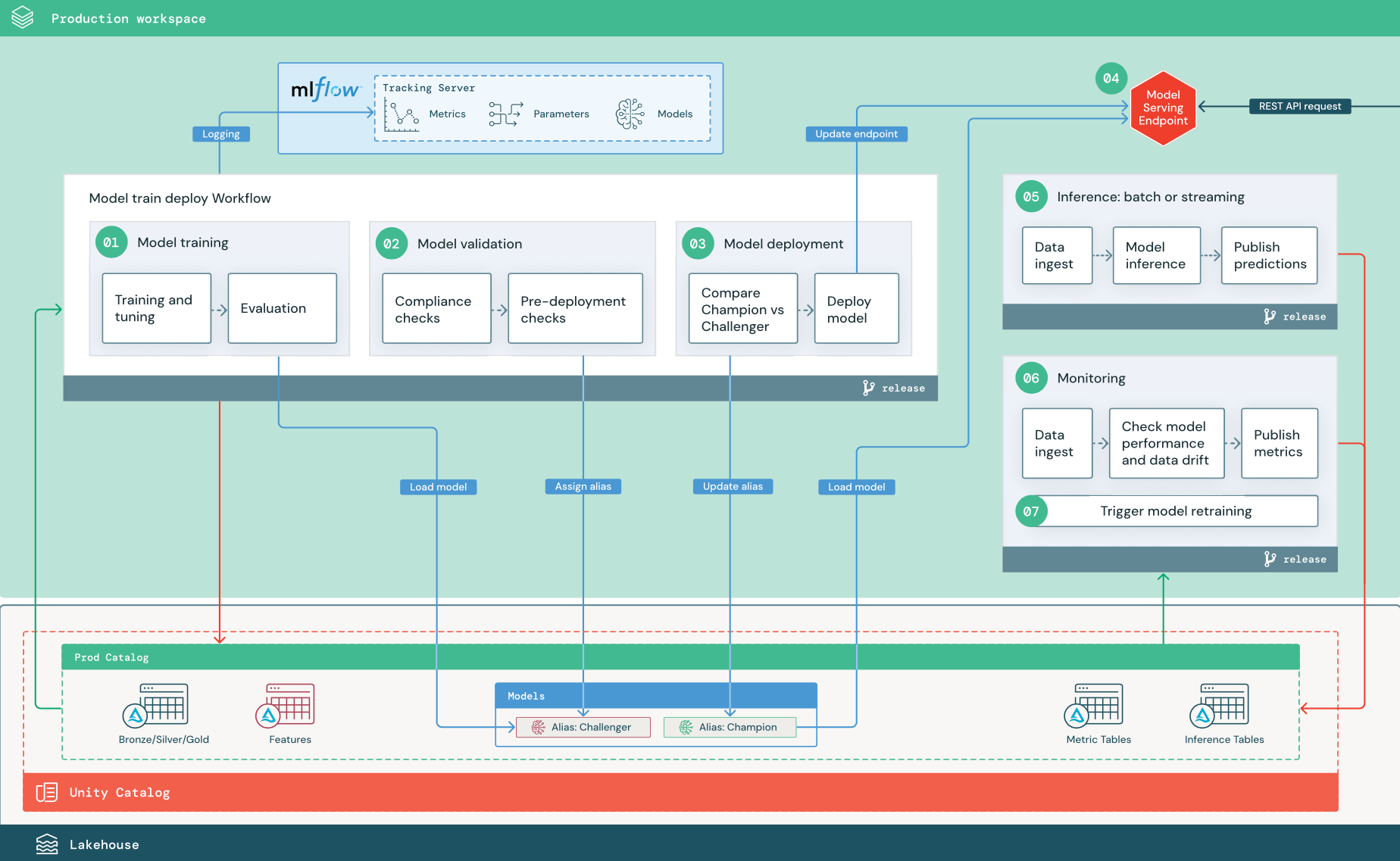
De numrerade stegen motsvarar de tal som visas i diagrammet.
Träna en modell
Den här pipelinen kan utlösas av kodändringar eller av automatiserade omträningsjobb. I det här steget används tabeller från produktionskatalogen för följande steg.
Träning och justering. Under träningsprocessen registreras loggar till produktionsmiljöns MLflow Tracking-server. Dessa loggar omfattar modellmått, parametrar, taggar och själva modellen. Om du använder funktionstabeller loggas modellen till MLflow med hjälp av Databricks Feature Store-klienten, som paketar modellen med information om funktionssökning som används vid slutsatsdragningstiden.
Under utvecklingen kan dataexperter testa många algoritmer och hyperparametrar. I produktionsträningskoden är det vanligt att bara överväga de bästa alternativen. Att begränsa justeringen på det här sättet sparar tid och kan minska variansen från justering i automatisk omträning.
Om dataexperter har skrivskyddad åtkomst till produktionskatalogen kanske de kan fastställa den optimala uppsättningen hyperparametrar för en modell. I det här fallet kan modellträningspipelinen som distribueras i produktion köras med hjälp av den valda uppsättningen hyperparametrar, som vanligtvis ingår i pipelinen som en konfigurationsfil.
Utvärdering. Modellkvaliteten utvärderas genom testning på reserverade produktionsdata. Resultatet av dessa tester loggas till MLflow-spårningsservern. Det här steget använder de utvärderingsmått som anges av dataexperter i utvecklingsfasen. Dessa mått kan innehålla anpassad kod.
Registrera modell. När modellträningen är klar sparas modellartefakten som en registrerad modellversion på den angivna modellsökvägen i produktionskatalogen i Unity Catalog. Modellträningsaktiviteten ger en modell-URI som modellverifieringsuppgiften kan använda. Du kan använda aktivitetsvärden för att skicka den här URI:n till modellen.
2. Verifiera modellen
Den här pipelinen använder modell-URI:n från steg 1 och läser in modellen från Unity Catalog. Sedan körs en serie verifieringskontroller. Dessa kontroller beror på din organisation och användningsfall och kan omfatta saker som grundläggande format- och metadatavalidering, prestandautvärderingar på valda datasektorer och efterlevnad av organisationens krav, till exempel efterlevnadskontroller för taggar eller dokumentation.
Om modellen klarar alla valideringskontroller kan du tilldela aliaset "Challenger" till modellversionen i Unity Catalog. Om modellen inte klarar alla valideringskontroller avslutas processen och användarna kan meddelas automatiskt. Du kan använda taggar för att lägga till nyckel/värde-attribut beroende på resultatet av dessa valideringskontroller. Du kan till exempel skapa en tagg "model_validation_status" och ange värdet till "VÄNTAR" när testerna körs och sedan uppdatera den till "GODKÄND" eller "MISSLYCKAD" när pipelinen är klar.
Eftersom modellen är registrerad i Unity Catalog kan dataexperter som arbetar i utvecklingsmiljön läsa in den här modellversionen från produktionskatalogen för att undersöka om modellen misslyckas med valideringen. Oavsett resultatet registreras resultaten till den registrerade modellen i produktionskatalogen med anteckningar till modellversionen.
3. Implementera modell
Precis som valideringspipelinen beror modelldistributionspipelinen på din organisation och användningsfall. Det här avsnittet förutsätter att du har tilldelat den nyligen verifierade modellen aliaset "Challenger" och att den befintliga produktionsmodellen har tilldelats aliaset "Champion". Det första steget innan du distribuerar den nya modellen är att bekräfta att den fungerar minst lika bra som den aktuella produktionsmodellen.
Jämför modellen "CHALLENGER" med "CHAMPION". Du kan utföra den här jämförelsen offline eller online. En offlinejämförelse utvärderar båda modellerna mot en uthållen datauppsättning och spårar resultat med hjälp av MLflow Tracking-servern. För realtidsmodellservering kanske du vill utföra längre varande onlinejämförelser, såsom A/B-tester eller en gradvis utrullning av den nya modellen. Om modellversionen "Challenger" presterar bättre i jämförelsen ersätter den det aktuella "Champion"-aliaset.
Med Mosaic AI Model Serving och dataprofilering kan du automatiskt samla in och övervaka slutsatsdragningstabeller som innehåller begärande- och svarsdata för en slutpunkt.
Om det inte finns någon befintlig "Champion"-modell kan du jämföra "Challenger"-modellen med ett affärs-heuristiskt eller annat tröskelvärde som baslinje.
Processen som beskrivs här är helt automatiserad. Om manuella godkännandesteg krävs kan du konfigurera dem med hjälp av arbetsflödesaviseringar eller CI/CD-återanrop från modelldistributionspipelinen.
Distribuera modellen. Batch- eller strömmande inferenspipelines kan konfigureras för att använda modellen med aliaset "Champion". För användningsfall i realtid måste du konfigurera infrastrukturen för att distribuera modellen som en REST API-slutpunkt. Du kan skapa och hantera den här slutpunkten med hjälp av Mosaic AI Model Serving. Om en slutpunkt redan används för den aktuella modellen kan du uppdatera slutpunkten med den nya modellen. Mosaic AI Model Serving kör en uppdatering med noll stilleståndstid genom att hålla den befintliga konfigurationen igång tills den nya är klar.
4. Modellservering
När du konfigurerar en modellserverslutpunkt anger du namnet på modellen i Unity Catalog och den version som ska användas. Om modellversionen har tränats med funktioner från tabeller i Unity Catalog lagrar modellen beroendena för funktionerna. Modellservern använder automatiskt det här beroendediagrammet för att söka efter funktioner från lämpliga onlinebutiker vid slutsatsdragningstid. Den här metoden kan också användas för att tillämpa funktioner för förbearbetning av data eller för att beräkna funktioner på begäran under modellbedömning.
Du kan skapa en enskild slutpunkt med flera modeller och ange slutpunktstrafiken som delas mellan dessa modeller, så att du kan utföra jämförelser mellan "Champion" online och "Challenger".
5. Slutsatsdragning: batch eller direktuppspelning
Slutsatsdragningspipelinen läser de senaste data från produktionskatalogen, kör funktioner för att beräkna funktioner på begäran, läser in modellen "Champion", poängsätter data och returnerar förutsägelser. Batch- eller strömningsinferens är vanligtvis det mest kostnadseffektiva alternativet för användningsfall med högre dataflöde och högre svarstid. För scenarier där förutsägelser med låg latens krävs, men förutsägelser kan beräknas offline, kan dessa batchförutsägelser publiceras till ett nyckelvärdeslager online, till exempel DynamoDB eller Cosmos DB.
Den registrerade modellen i Unity Catalog refereras av dess alias. Slutsatsdragningspipelinen är konfigurerad för att läsa in och tillämpa modellversionen "Champion". Om "Champion"-versionen uppdateras till en ny modellversion använder slutsatsdragningspipelinen automatiskt den nya versionen för nästa körning. På så sätt frikopplas modelldistributionssteget från slutsatsdragningspipelines.
Batch-jobb publicerar vanligtvis förutsägelser till tabeller i produktionskatalogen, till flata filer eller via en JDBC-anslutning. Direktuppspelningsjobb publicerar vanligtvis förutsägelser antingen till Unity Catalog-tabeller eller till meddelandeköer som Apache Kafka.
6. Dataprofilering
Dataprofilering övervakar statistiska egenskaper, till exempel dataavvikelse och modellprestanda, för indata och modellförutsägelser. Du kan skapa aviseringar baserat på dessa mått eller publicera dem på instrumentpaneler.
- Datainsamling. Den här pipelinen läser in loggar från batch-, strömnings- eller onlineinferens.
- Kontrollera noggrannhet och datadrift. Pipelinen beräknar mått om indata, modellens förutsägelser och infrastrukturprestanda. Dataexperter anger data- och modellmått under utvecklingen och ML-tekniker anger infrastrukturmått. Du kan också definiera anpassade mått.
- Publicera mått och konfigurera aviseringar. Pipelinen skriver till tabeller i produktionskatalogen för analys och rapportering. Du bör konfigurera dessa tabeller så att de kan läsas från utvecklingsmiljön så att dataforskare har åtkomst till analys. Du kan använda Databricks SQL för att skapa övervakningsinstrumentpaneler för att spåra modellprestanda och konfigurera övervakningsjobbet eller instrumentpanelsverktyget för att utfärda ett meddelande när ett mått överskrider ett angivet tröskelvärde.
- Omträning av utlösarmodell. När övervakningsmått indikerar prestandaproblem eller ändringar i indata kan dataexperten behöva utveckla en ny modellversion. Du kan konfigurera SQL-aviseringar för att meddela dataexperter när detta händer.
7. Omträning
Den här arkitekturen stöder automatisk omträning med samma modellträningspipeline ovan. Databricks rekommenderar att du börjar med schemalagd, regelbunden omträning och flyttar till utlöst omträning när det behövs.
- Schemalagd. Om nya data är tillgängliga regelbundet kan du skapa ett schemalagt jobb för att köra modellträningskoden på de senaste tillgängliga data. Se Automatisera jobb med scheman och utlösare
- Utlösta. Om övervakningspipelinen kan identifiera problem med modellprestanda och skicka aviseringar kan den också utlösa omträning. Om till exempel fördelningen av inkommande data ändras avsevärt eller om modellprestandan försämras kan automatisk omträning och omdistribution öka modellprestandan med minimal mänsklig inblandning. Detta kan uppnås genom en SQL-avisering för att kontrollera om ett mått är avvikande (till exempel kontrollera drift- eller modellkvalitet mot ett tröskelvärde). Larmet kan konfigureras för att använda en webhook-destination, vilket sedan kan utlösa arbetsflödet för träning.
Om omträningspipelinen eller andra pipelines uppvisar prestandaproblem kan dataexperten behöva återvända till utvecklingsmiljön för ytterligare experimentering för att åtgärda problemen.