Exempel på arbetsytemodellregister
Kommentar
Den här dokumentationen beskriver arbetsytans modellregister. Azure Databricks rekommenderar att du använder modeller i Unity Catalog. Modeller i Unity Catalog ger centraliserad modellstyrning, åtkomst mellan arbetsytor, ursprung och distribution. Arbetsytemodellregistret kommer att bli inaktuellt i framtiden.
Det här exemplet visar hur du använder arbetsytemodellregistret för att skapa ett maskininlärningsprogram som förutspår den dagliga utdatan för en vindkraftspark. Exemplet visar hur du:
- Spåra och logga modeller med MLflow
- Registrera modeller med modellregistret
- Beskriva modeller och göra modellversionsstegövergångar
- Integrera registrerade modeller med produktionsprogram
- Söka efter och identifiera modeller i modellregistret
- Arkivera och ta bort modeller
I artikeln beskrivs hur du utför de här stegen med hjälp av UIs och API:er för MLflow Tracking och MLflow Model Registry.
En notebook-fil som utför alla dessa steg med hjälp av API:erna för MLflow-spårning och register finns i exempelanteckningsboken modellregister.
Läsa in datauppsättning, träna modell och spåra med MLflow Tracking
Innan du kan registrera en modell i modellregistret måste du först träna och logga modellen under en experimentkörning. Det här avsnittet visar hur du läser in datauppsättningen för vindkraftsparker, tränar en modell och loggar träningskörningen till MLflow.
Läsa in datauppsättning
Följande kod läser in en datauppsättning som innehåller väderdata och utdatainformation för en vindkraftspark i USA. Datamängden innehåller , och funktioner som samplas var sjätte timme (en gång vid 00:00, en gång vid 08:00och en gång vid 16:00), samt dagliga aggregerade utdata (power) under flera år.air temperature wind speedwind direction
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Träna en modell
Följande kod tränar ett neuralt nätverk med TensorFlow Keras för att förutsäga utdata baserat på väderfunktionerna i datamängden. MLflow används för att spåra modellens hyperparametrar, prestandamått, källkod och artefakter.
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
Registrera och hantera modellen med MLflow-användargränssnittet
I detta avsnitt:
- Skapa en ny registrerad modell
- Utforska användargränssnittet för modellregistret
- Lägga till modellbeskrivningar
- Överföra en modellversion
Skapa en ny registrerad modell
Gå till sidofältet MLflow-experimentkörningar genom att klicka på experimentikonen
 i Azure Databricks-anteckningsbokens högra sidofält.
i Azure Databricks-anteckningsbokens högra sidofält.
Leta upp MLflow-körningen som motsvarar TensorFlow Keras-modellträningssessionen och öppna den i MLflow Run-användargränssnittet genom att klicka på ikonen Visa körningsinformation .
I MLflow-användargränssnittet rullar du ned till avsnittet Artefakter och klickar på katalogen med namnet modell. Klicka på knappen Registrera modell som visas.

Välj Skapa ny modell på den nedrullningsbara menyn och ange följande modellnamn:
power-forecasting-model.Klicka på Registrera. Detta registrerar en ny modell med namnet
power-forecasting-modeloch skapar en ny modellversion:Version 1.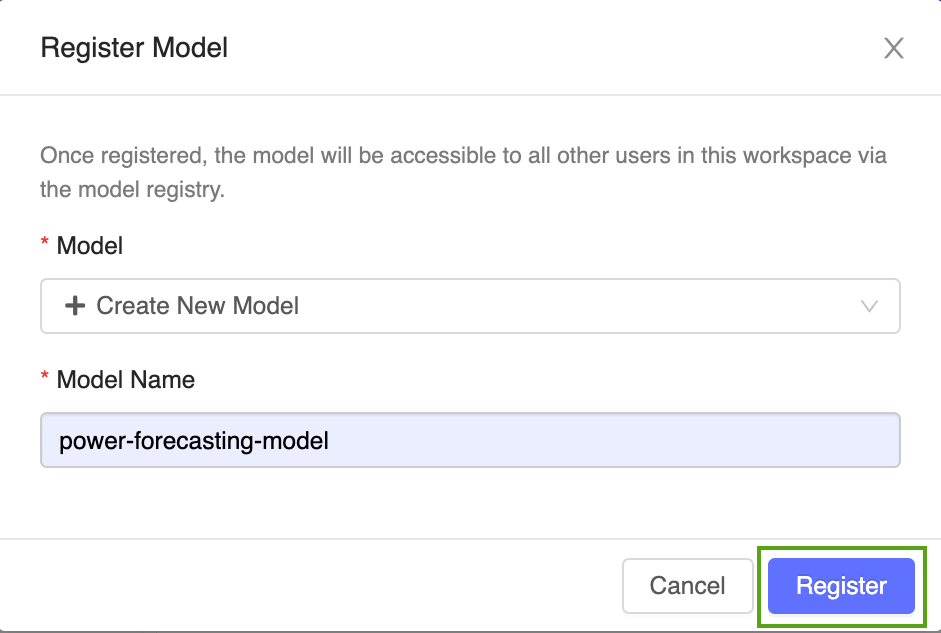
Efter en liten stund visar användargränssnittet för MLflow en länk till den nya registrerade modellen. Följ den här länken för att öppna den nya modellversionen i användargränssnittet för MLflow Model Registry.
Utforska användargränssnittet för modellregistret
Sidan modellversion i användargränssnittet för MLflow Model Registry innehåller information om Version 1 den registrerade prognosmodellen, inklusive dess författare, skapandetid och dess aktuella fas.
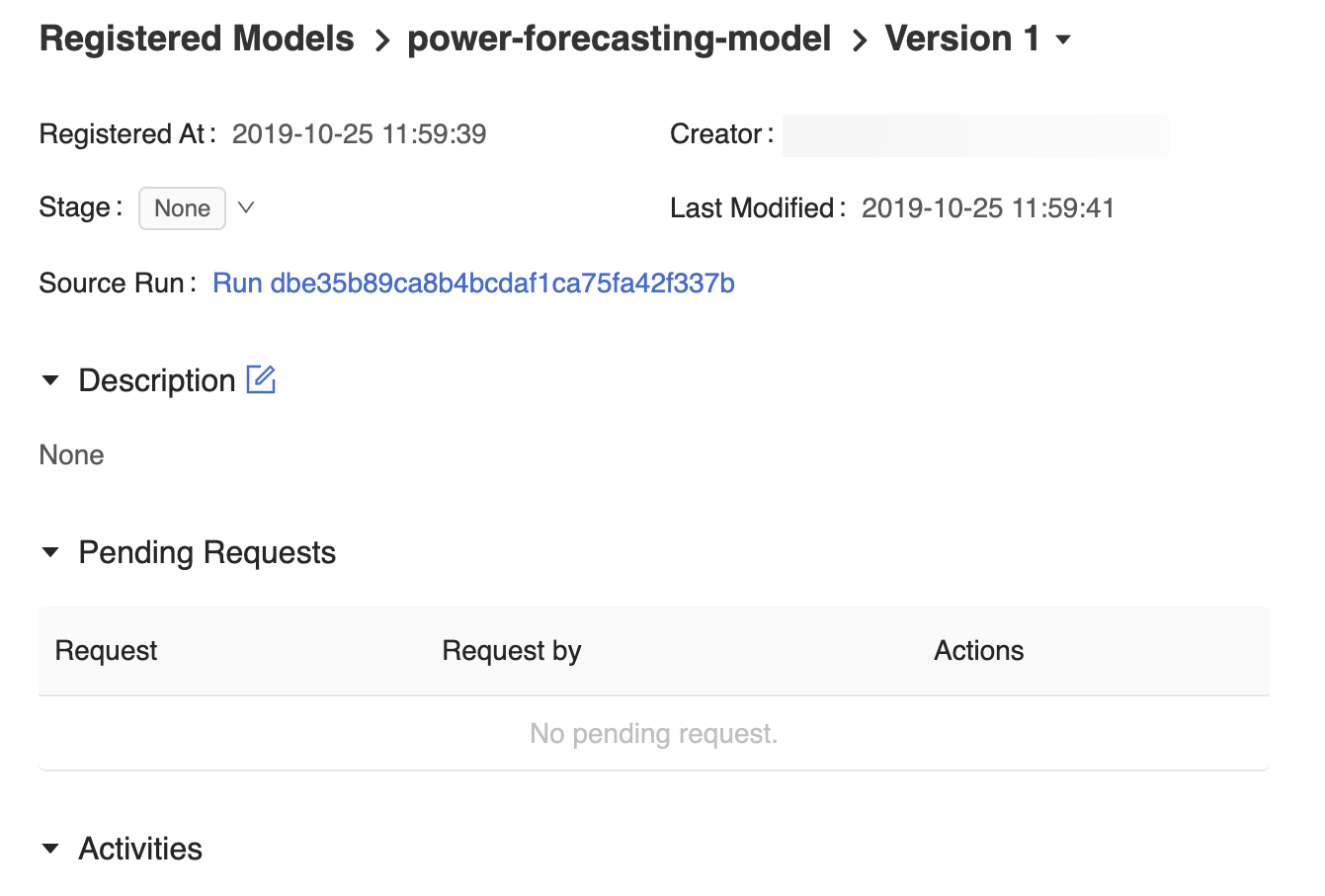
Modellversionssidan innehåller också en länk för källkörning som öppnar MLflow-körningen som användes för att skapa modellen i MLflow-körningsgränssnittet. Från MLflow Run-användargränssnittet kan du komma åt länken Källanteckningsbok för att visa en ögonblicksbild av Azure Databricks-anteckningsboken som användes för att träna modellen.


Om du vill gå tillbaka till MLflow Model Registry klickar du på ![]() Modeller i sidofältet.
Modeller i sidofältet.
Startsidan för MLflow Model Registry visar en lista över alla registrerade modeller på din Azure Databricks-arbetsyta, inklusive deras versioner och faser.
Klicka på länken power-forecasting-model för att öppna den registrerade modellsidan, som visar alla versioner av prognosmodellen.
Lägga till modellbeskrivningar
Du kan lägga till beskrivningar i registrerade modeller och modellversioner. Registrerade modellbeskrivningar är användbara för att registrera information som gäller för flera modellversioner (t.ex. en allmän översikt över modelleringsproblemet och datamängden). Beskrivningar av modellversioner är användbara för att beskriva de unika attributen för en viss modellversion (t.ex. den metod och algoritm som används för att utveckla modellen).
Lägg till en beskrivning på hög nivå i den registrerade energiprognosmodellen.
 Klicka på ikonen och ange följande beskrivning:
Klicka på ikonen och ange följande beskrivning:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.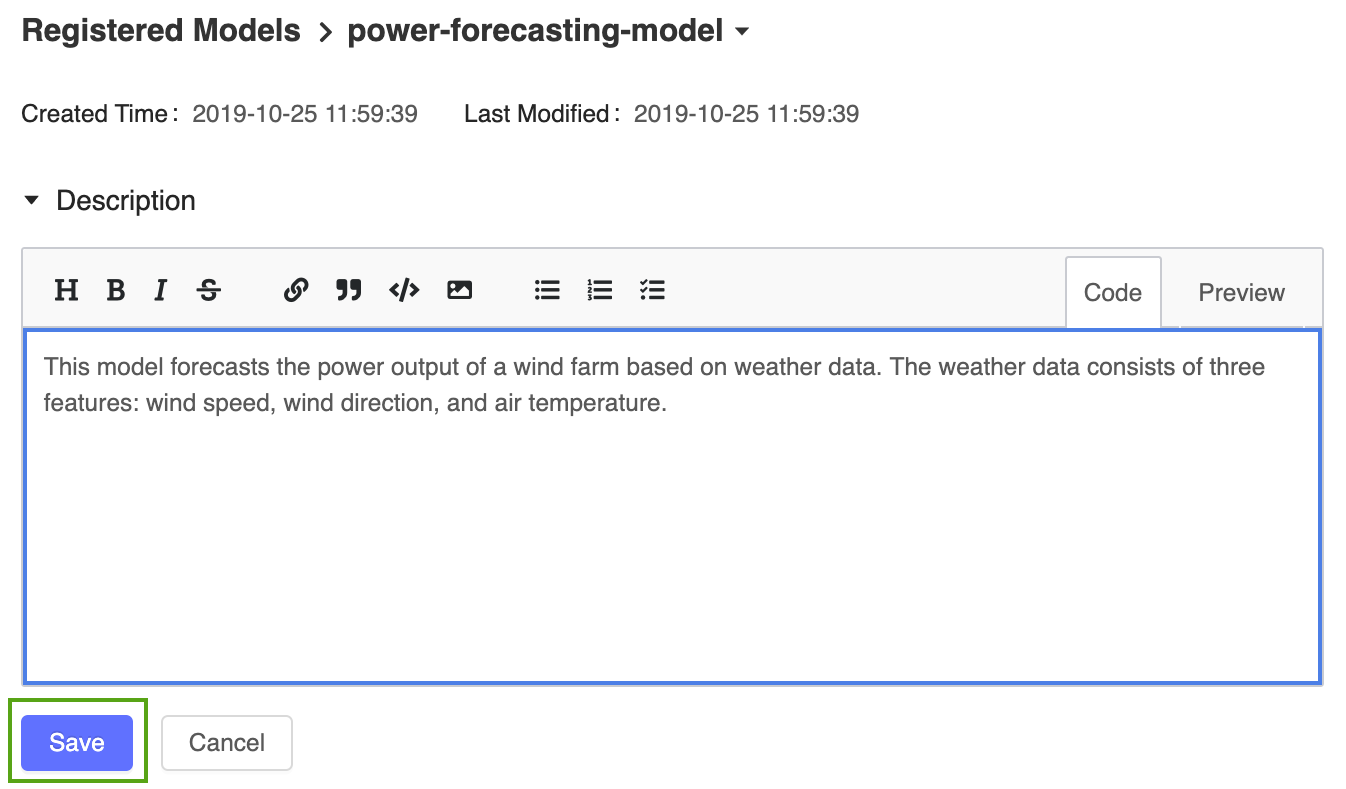
Klicka på Spara.
Klicka på länken Version 1 från den registrerade modellsidan för att gå tillbaka till modellversionssidan.
- Klicka på ikonen och ange följande beskrivning:
This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.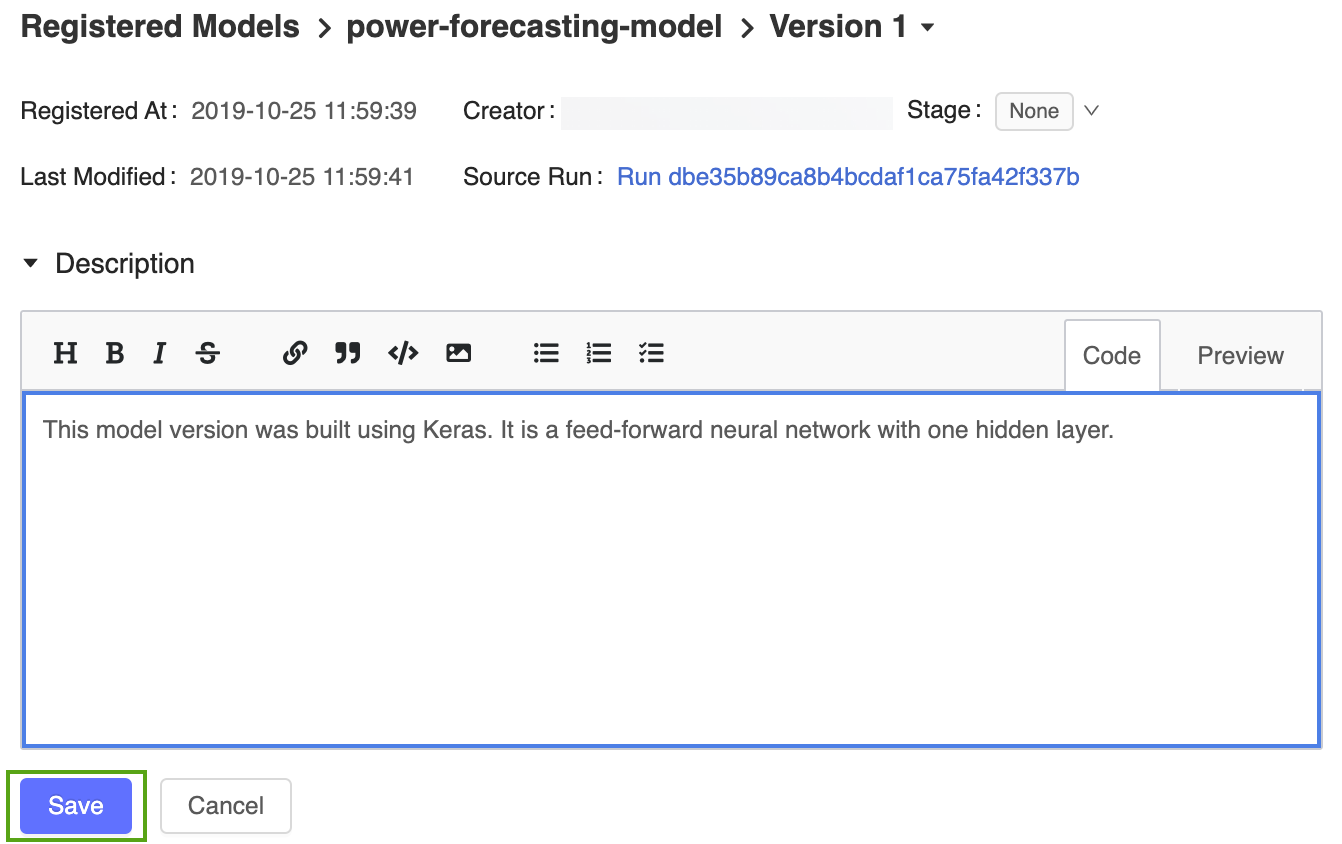
Klicka på Spara.
Överföra en modellversion
MLflow Model Registry definierar flera modellsteg: None, Staging, Production och Archived. Varje fas har en unik betydelse. Mellanlagring är till exempel avsett för modelltestning, medan Produktion är till för modeller som har slutfört test- eller granskningsprocesserna och har distribuerats till program.
Klicka på knappen Steg för att visa listan över tillgängliga modellsteg och tillgängliga alternativ för fasövergång.
Välj Övergång till –> Produktion och tryck på OK i fasövergångsbekräftelsefönstret för att överföra modellen till Produktion.
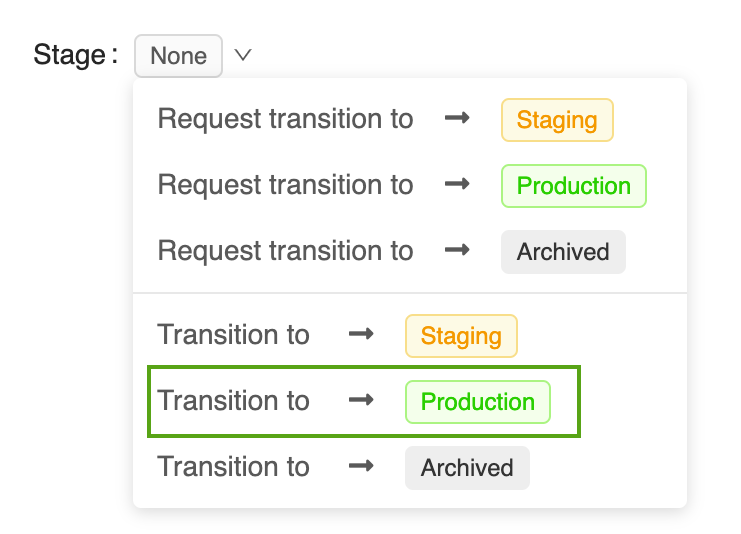
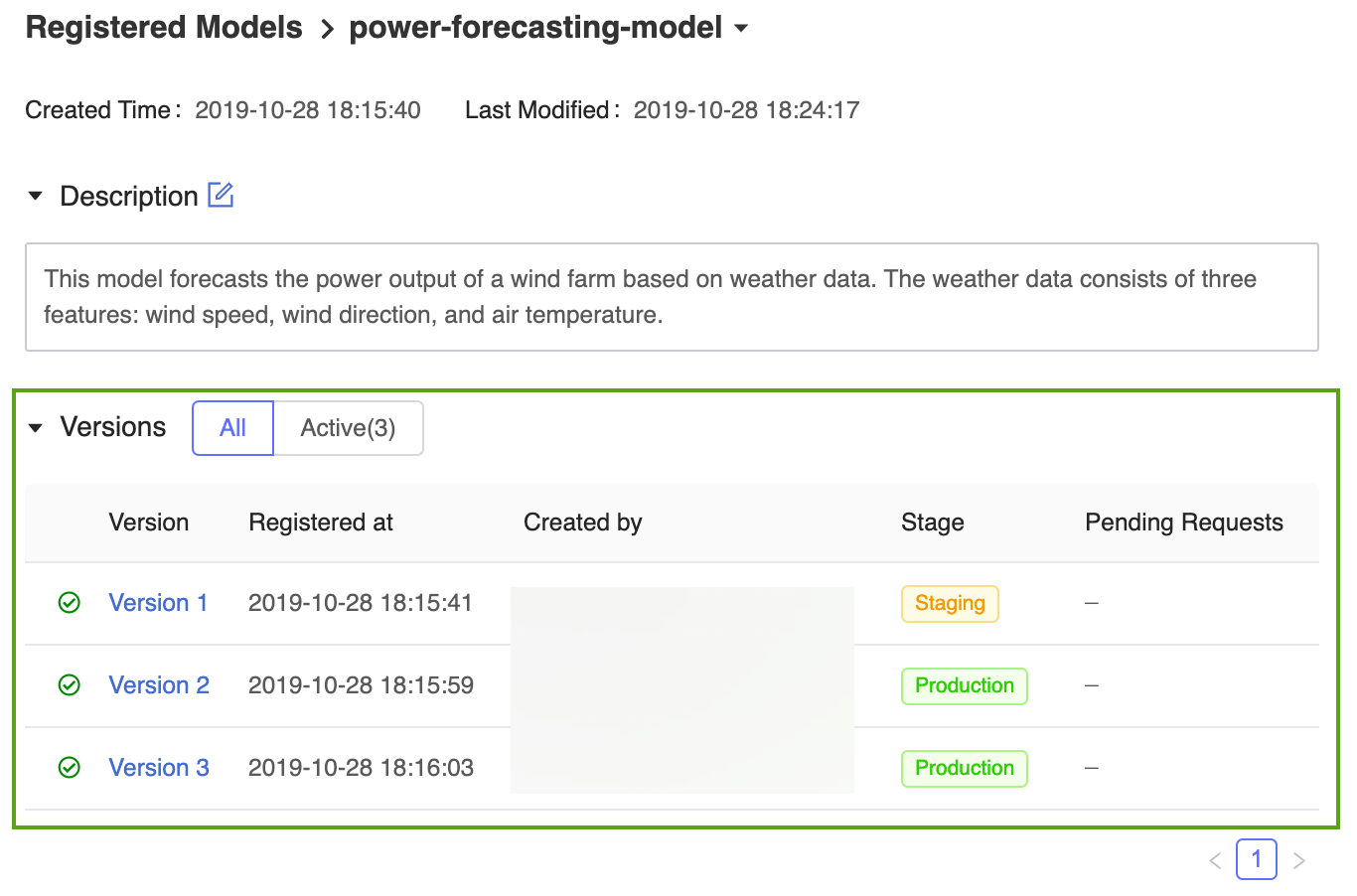
När modellversionen har övergått till Produktion visas den aktuella fasen i användargränssnittet och en post läggs till i aktivitetsloggen för att återspegla övergången.


MLflow Model Registry tillåter att flera modellversioner delar samma fas. När du refererar till en modell efter steg använder modellregistret den senaste modellversionen (modellversionen med det största versions-ID:t). Den registrerade modellsidan visar alla versioner av en viss modell.
Registrera och hantera modellen med hjälp av MLflow-API:et
I detta avsnitt:
- Definiera modellens namn programmatiskt
- Registrera modellen
- Lägga till modell- och modellversionsbeskrivningar med hjälp av API:et
- Överföra en modellversion och hämta information med hjälp av API:et
Definiera modellens namn programmatiskt
Nu när modellen har registrerats och övergått till Produktion kan du referera till den med MLflow-programmatiska API:er. Definiera den registrerade modellens namn enligt följande:
model_name = "power-forecasting-model"
Registrera modellen
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
Lägga till modell- och modellversionsbeskrivningar med hjälp av API:et
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Överföra en modellversion och hämta information med hjälp av API:et
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
Läsa in versioner av den registrerade modellen med hjälp av API:et
Komponenten MLflow Models definierar funktioner för inläsning av modeller från flera maskininlärningsramverk. Används till exempel mlflow.tensorflow.load_model() för att läsa in TensorFlow-modeller som har sparats i MLflow-format och mlflow.sklearn.load_model() används för att läsa in scikit-learn-modeller som har sparats i MLflow-format.
Dessa funktioner kan läsa in modeller från MLflow Model Registry.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
Prognostisera utdata med produktionsmodellen
I det här avsnittet används produktionsmodellen för att utvärdera väderprognosdata för vindkraftsparken. Programmet forecast_power() läser in den senaste versionen av prognosmodellen från den angivna fasen och använder den för att prognostisera energiproduktionen under de kommande fem dagarna.
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
Skapa en ny modellversion
Klassiska maskininlärningstekniker är också effektiva för energiprognoser. Följande kod tränar en slumpmässig skogsmodell med scikit-learn och registrerar den med MLflow Model Registry via mlflow.sklearn.log_model() funktionen.
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
Hämta det nya modellversions-ID:t med MLflow Model Registry-sökning
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
Lägga till en beskrivning i den nya modellversionen
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
Överföra den nya modellversionen till Mellanlagring och testa modellen
Innan du distribuerar en modell till ett produktionsprogram är det ofta bästa praxis att testa den i en mellanlagringsmiljö. Följande kod övergår den nya modellversionen till Mellanlagring och utvärderar dess prestanda.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
Distribuera den nya modellversionen till Produktion
När du har kontrollerat att den nya modellversionen fungerar bra i mellanlagringen övergår följande kod modellen till Produktion och använder exakt samma programkod från avsnittet Prognostisera utdata med produktionsmodellen för att skapa en energiprognos.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
Det finns nu två modellversioner av prognosmodellen i produktionsfasen : modellversionen som tränats i Keras-modellen och den version som tränats i scikit-learn.
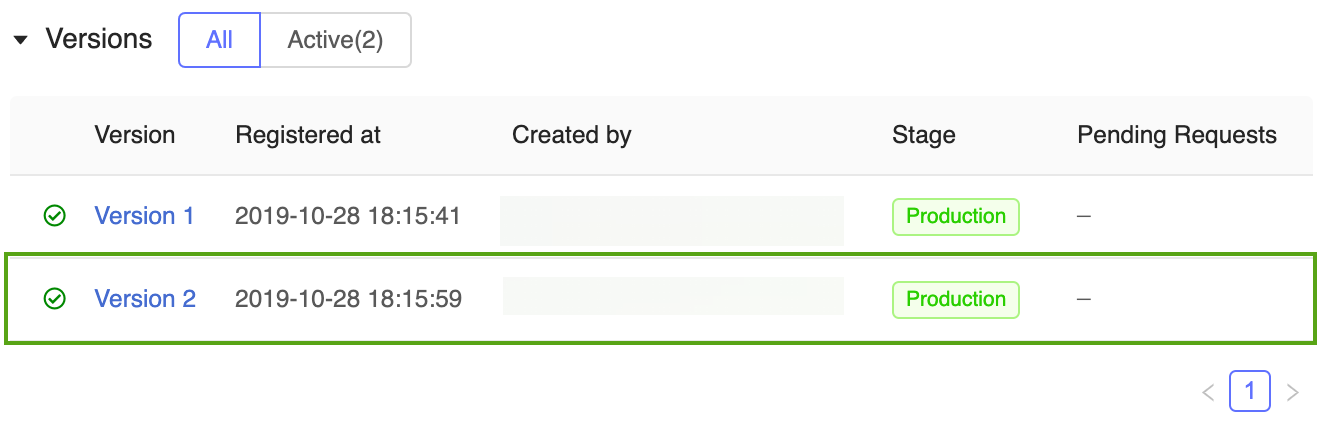
Kommentar
När du refererar till en modell efter steg använder MLflow Model Model Registry automatiskt den senaste produktionsversionen. På så sätt kan du uppdatera dina produktionsmodeller utan att ändra någon programkod.
Arkivera och ta bort modeller
När en modellversion inte längre används kan du arkivera den eller ta bort den. Du kan också ta bort en hel registrerad modell. Detta tar bort alla tillhörande modellversioner.
Arkiv Version 1 för energiprognosmodellen
Arkivera Version 1 energiprognosmodellen eftersom den inte längre används. Du kan arkivera modeller i MLflow Model Registry-användargränssnittet eller via MLflow-API:et.
Arkivera Version 1 i användargränssnittet för MLflow
Så här arkiverar Version 1 du energiprognosmodellen:
Öppna motsvarande modellversionssida i användargränssnittet för MLflow Model Registry:
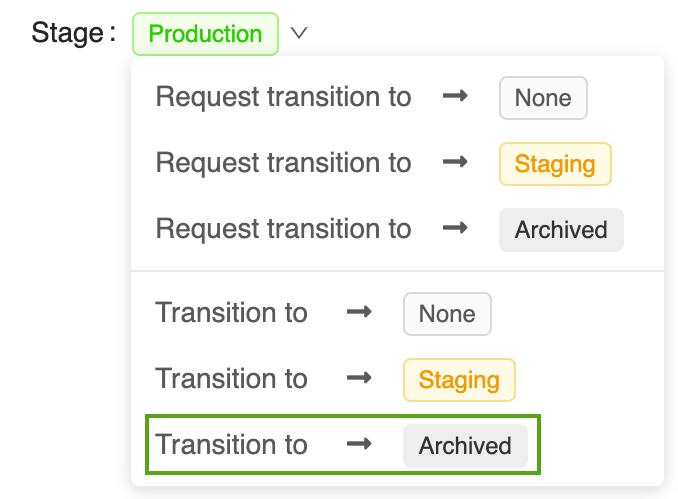
Klicka på knappen Steg , välj Övergång till –> Arkiverad:
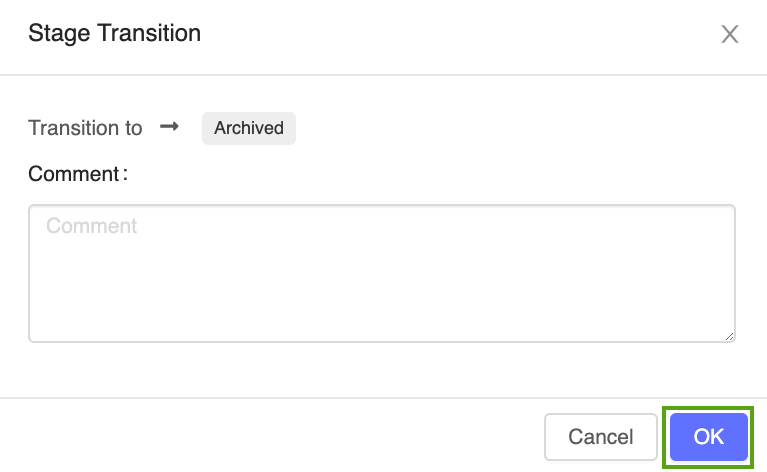
Tryck på OK i bekräftelsefönstret för fasövergången.

Arkivera Version 1 med hjälp av MLflow-API:et
Följande kod använder MlflowClient.update_model_version() funktionen för att arkivera Version 1 energiprognosmodellen.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
Ta bort Version 1 energiprognosmodellen
Du kan också använda MLflow-användargränssnittet eller MLflow-API:et för att ta bort modellversioner.
Varning
Borttagning av modellversioner är permanent och kan inte ångras.
Ta bort Version 1 i användargränssnittet för MLflow
Så här tar du bort Version 1 energiprognosmodellen:
Öppna motsvarande modellversionssida i användargränssnittet för MLflow Model Registry.
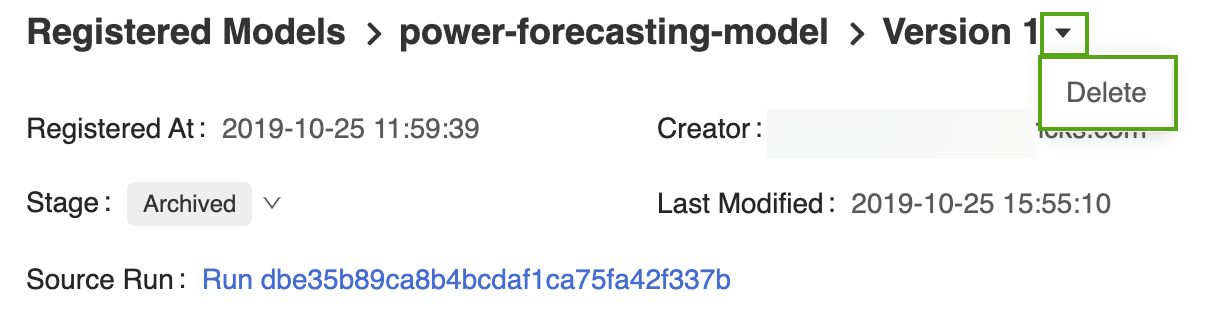
Välj listrutepilen bredvid versionsidentifieraren och klicka på Ta bort.
Ta bort Version 1 med hjälp av MLflow-API:et
client.delete_model_version(
name=model_name,
version=1,
)
Ta bort modellen med hjälp av MLflow-API:et
Du måste först överföra alla återstående modellversionssteg till Ingen eller Arkiverad.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)