Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Ett tydligt haveriberedskapsmönster är viktigt för en molnbaserad dataanalysplattform som Azure Databricks. Det är viktigt att dina datateam kan använda Azure Databricks-plattformen även i sällsynta fall av ett regionalt tjänstomfattande molntjänstleverantörsfel, oavsett om de orsakas av en regional katastrof som en orkan eller jordbävning eller någon annan källa.
Azure Databricks är ofta en viktig del av ett övergripande dataekosystem som innehåller många tjänster, inklusive överordnade datainmatningstjänster (batch/strömning), molnbaserad lagring som ADLS (för arbetsytor som skapats före den 6 mars 2023, Azure Blob Storage), underordnade verktyg och tjänster som business intelligence-appar och dirigeringsverktyg. Vissa av dina användningsfall kan vara särskilt känsliga för ett regionalt serviceomfattande avbrott.
Den här artikeln beskriver begrepp och metodtips för en lyckad lösning för haveriberedskap mellan regioner för Databricks-plattformen.
Garantier för hög tillgänglighet i regionen
Resten av det här avsnittet fokuserar på implementeringen av haveriberedskap mellan regioner, men det är viktigt att förstå de garantier med hög tillgänglighet som Azure Databricks tillhandahåller i den enskilda regionen. Garantier för hög tillgänglighet i regionen omfattar följande komponenter:
Tillgänglighet för Databricks-kontrollplanet
Databricks-kontrollplanet är motståndskraftigt mot zonfel och bör automatiskt återställas inom ~15 minuter efter ett zonfel. Rutinmässig testning av zonfel bekräftar detta.
Alla tillståndslösa kontrollplanstjänster kan hantera förlusten av enskilda virtuella datorer och alla virtuella datorer i en hel zon automatiskt. Arbetsytedata lagras i databaser som replikeras mellan zoner i regionen. Lagringskonton som används för att hantera Databricks Runtime-avbildningar är också redundanta i regionen och alla regioner har sekundära lagringskonton som används när den primära är nere. Se Azure Databricks-regioner.
Zonindelad felresiliens stöder endast högst en zon som är nere och är endast tillgänglig i Azure-regioner som stöder flera zoner.
Tillgänglighet för beräkningsplanet
Tillgängligheten för arbetsytan beror på tillgängligheten för kontrollplanet (enligt beskrivningen ovan). Data på DBFS-roten påverkas inte om lagringskontot för DBFS-roten har konfigurerats med zonredundant lagring (ZRS) eller geo-zonredundant lagring (GZRS) (standardvärdet är Geo-redundant lagring (GRS)).
Noder för kluster hämtas från de olika tillgänglighetszonerna genom att begära noder från Azure-beräkningsprovidern (förutsatt att det finns tillräckligt med kapacitet i de återstående zonerna för att uppfylla begäran). Om en nod går förlorad begär klusterhanteraren ersättningsnoder från Azure-beräkningsprovidern, vilket hämtar dem från de tillgängliga AZ:erna. Det enda undantaget är när drivrutinsnoden går förlorad. I det här fallet startar klusterhanteraren om jobbet och klustret.
Översikt över haveriberedskap
Haveriberedskap omfattar en uppsättning principer, verktyg och procedurer som möjliggör återställning eller fortsättning av viktig teknikinfrastruktur och system efter en naturlig eller mänsklig katastrof. En stor molntjänst som Azure betjänar många kunder och har inbyggda skydd mot ett enda fel. En region är till exempel en grupp byggnader som är anslutna till olika energikällor för att garantera att en enda strömförlust inte stänger av en region. Men fel i molnregionen kan inträffa, och graden av avbrott och dess inverkan på din organisation kan variera.
Innan du implementerar en haveriberedskapsplan är det viktigt att förstå skillnaden mellan haveriberedskap (DR) och hög tillgänglighet (HA).
Hög tillgänglighet är en återhämtningsegenskaper hos ett system. Hög tillgänglighet säkerställer en lägsta nivå av driftprestanda som vanligtvis definieras när det gäller konsekvent drifttid eller procentandel drifttid. Hög tillgänglighet implementeras på plats (i samma region som ditt primära system) genom att utforma den som en funktion i det primära systemet. Molntjänster som Azure har till exempel tjänster med hög tillgänglighet, till exempel ADLS (för arbetsytor som skapades före den 6 mars 2023, Azure Blob Storage). Hög tillgänglighet kräver ingen betydande explicit förberedelse från Azure Databricks-kunden.
En haveriberedskapsplan kräver däremot beslut och lösningar som fungerar för din specifika organisation för att hantera ett större regionalt avbrott för kritiska system. I den här artikeln beskrivs vanliga terminologi för haveriberedskap, vanliga lösningar och några metodtips för haveriberedskapsplaner med Azure Databricks.
Terminologi
Regionterminologi
Den här artikeln använder följande definitioner för regioner:
Primär region: Den geografiska region där användarna kör typiska dagliga interaktiva och automatiserade arbetsbelastningar för dataanalys.
Sekundär region: Den geografiska region där IT-team tillfälligt flyttar dataanalysarbetsbelastningar under ett avbrott i den primära regionen.
Geo-redundant lagring: Azure har geo-redundant lagring mellan regioner för sparad lagring med hjälp av en asynkron lagringsreplikeringsprocess.
Viktigt!
För haveriberedskapsprocesser rekommenderar Databricks att du inte förlitar dig på geo-redundant lagring för dubbelarbete mellan regioner av data, till exempel din ADLS (för arbetsytor som skapats före den 6 mars 2023, Azure Blob Storage) som Azure Databricks skapar för varje arbetsyta i din Azure-prenumeration. I allmänhet använder du Deep Clone för Delta-tabeller och konverterar data till Delta-format för att använda Deep Clone om möjligt för andra dataformat.
Terminologi för distributionsstatus
I den här artikeln används följande definitioner av distributionsstatus:
Aktiv distribution: Användare kan ansluta till en aktiv distribution av en Azure Databricks-arbetsyta och köra arbetsbelastningar. Jobb schemaläggs regelbundet med Azure Databricks-schemaläggaren eller andra mekanismer. Dataströmmar kan också köras i den här miljön. Vissa dokument kan referera till en aktiv distribution som en frekvent distribution.
Passiv distribution: Processer körs inte i en passiv distribution. IT-team kan konfigurera automatiserade procedurer för att distribuera kod, konfiguration och andra re:[Databricks]-objekt till den passiva distributionen. En distribution blir endast aktiv om en aktuell aktiv distribution är nere. Vissa dokument kan referera till en passiv distribution som en kall distribution.
Viktigt!
Ett projekt kan också innehålla flera passiva distributioner i olika regioner för att tillhandahålla ytterligare alternativ för att lösa regionala avbrott.
Vanligtvis har ett team bara en aktiv driftsättning i taget, i en så kallad aktiv-passiv haveriberedskapsstrategi. Det finns en mindre vanlig strategi för katastrofåterställning som kallas aktiv-aktiv, där det finns två samtidiga aktiva distributioner.
Terminologi för haveriberedskapsindustrin
Det finns två viktiga branschvillkor som du måste förstå och definiera för ditt team:
Mål för återställningspunkt: Ett mål för återställningspunkt (RPO) är den maximala målperiod under vilken data (transaktioner) kan gå förlorade från en IT-tjänst på grund av en större incident. Din Azure Databricks-distribution lagrar inte dina viktigaste kunddata. Det lagras i separata system som ADLS (för arbetsytor som skapats före den 6 mars 2023, Azure Blob Storage) eller andra datakällor som du har kontroll över. Azure Databricks-kontrollplanet lagrar vissa objekt delvis eller i sin helhet, till exempel jobb och notebook-filer. För Azure Databricks definieras RPO som den maximala målperiod där objekt, till exempel jobb och notebook-ändringar, kan gå förlorade. Dessutom ansvarar du för att definiera RPO för dina egna kunddata i ADLS (för arbetsytor som skapats före den 6 mars 2023, Azure Blob Storage) eller andra datakällor under din kontroll.
Mål för återställningstid: Återställningstidens mål (RTO) är den tidsperiod och den tjänstenivå inom vilken en affärsprocess måste återställas efter en katastrof.
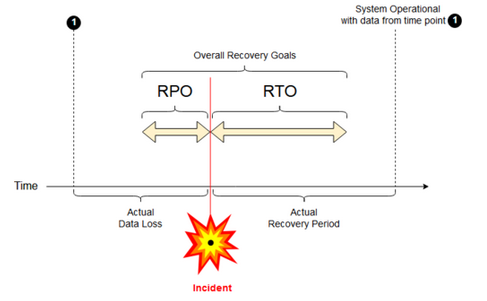
Katastrofåterställning och datakorruption
En haveriberedskapslösning minimerar inte skadade data. Skadade data i den primära regionen replikeras från den primära regionen till en sekundär region och är skadade i båda regionerna. Det finns andra sätt att minimera den här typen av fel, till exempel deltatidsresor.
Typiskt återställningsarbetsflöde
Ett scenario för katastrofåterställning i Azure Databricks förlöper vanligtvis på följande sätt:
Ett fel inträffar i en kritisk tjänst som du använder i din primära region. Det kan vara en datakälla eller ett nätverk som påverkar Azure Databricks-distributionen.
Du undersöker situationen med molnleverantören.
Om du drar slutsatsen att företaget inte kan vänta på att problemet ska åtgärdas i den primära regionen kan du välja att redundansväxla till en sekundär region.
Kontrollera att samma problem inte också påverkar den sekundära regionen.
Redundansväxla till en sekundär region.
- Stoppa alla aktiviteter på arbetsytan. Användare stoppar arbetsbelastningar. Användare eller administratörer uppmanas att göra en säkerhetskopia av de senaste ändringarna om möjligt. Jobb stängs av om de inte redan har misslyckats på grund av avbrottet.
- Starta återställningsproceduren i den sekundära regionen. Återställningsproceduren uppdaterar routningen och byter namn på anslutningar och nätverkstrafik till den sekundära regionen.
- Efter testningen deklarerar du att den sekundära regionen är i drift. Produktionsarbetsbelastningar kan nu återupptas. Användare kan logga in på den nu aktiva distributionen. Du kan återutlösa schemalagda eller fördröjda uppgifter.
Detaljerade steg i en Azure Databricks-kontext finns i Testa redundans.
Vid något tillfälle minimeras problemet i den primära regionen, och du bekräftar detta faktum.
Återgå till din primära region.
- Stoppa allt arbete i den sekundära regionen.
- Starta återställningsproceduren i den primära regionen. Återställningsproceduren hanterar routning och namnbyte av anslutningen och nätverkstrafiken tillbaka till den primära regionen.
- Replikera data tillbaka till den primära regionen efter behov. För att minska komplexiteten kan du minimera hur mycket data som behöver replikeras. Om vissa jobb till exempel är skrivskyddade när de körs i den sekundära distributionen kanske du inte behöver replikera dessa data tillbaka till den primära distributionen i den primära regionen. Du kan dock ha ett produktionsjobb som måste köras och som kan behöva datareplikering tillbaka till den primära regionen.
- Testa distributionen i den primära regionen.
- Ange att din primära region är i drift och att den är din aktiva implementering. Återuppta produktionsarbetsbelastningar.
Mer information om hur du återställer till din primära region finns i Teståterställning (återställning efter fel).
Viktigt!
Under de här stegen kan viss dataförlust inträffa. Din organisation måste definiera hur mycket dataförlust som är acceptabel och vad du kan göra för att minska den här förlusten.
Steg 1: Förstå dina affärsbehov
Ditt första steg är att definiera och förstå dina affärsbehov. Definiera vilka datatjänster som är kritiska och vad som är deras förväntade RPO och RTO.
Undersöka den verkliga toleransen för varje system. Kom ihåg att haveriberedskap, redundans och återställning efter fel kan vara kostsamma och medföra andra risker. Andra risker kan vara skadade data, dataduplicering (om du skriver till fel lagringsplats) och användare som loggar in och gör ändringar på fel platser.
Mappa alla Azure Databricks-integreringsplatser som påverkar ditt företag:
- Behöver din haveriberedskapslösning hantera interaktiva processer, automatiserade processer eller både och?
- Vilka datatjänster använder du? Vissa kan vara på plats.
- Hur kommer indata till molnet?
- Vem använder dessa data? Vilka processer använder det nedströms?
- Finns det integreringar från tredje part som behöver vara medvetna om ändringar i återställning vid haveri?
Fastställ de verktyg eller kommunikationsstrategier som kan stödja din plan för haveriberedskap:
- Vilka verktyg kommer du att använda för att snabbt ändra nätverkskonfigurationer?
- Kan du fördefiniera din konfiguration och göra den modulär för att möjliggöra haveriberedskapslösningar på ett naturligt och underhållbart sätt?
- Vilka kommunikationsverktyg och kanaler kommer att informera interna team och tredje part (integreringar, nedströmskonsumenter) om övergångar och återställningsåtgärder vid katastrofhantering? Hur bekräftar du deras bekräftelse?
- Vilka verktyg eller särskilt stöd kommer att behövas?
- Vilka tjänster, om några, kommer att stängas av tills fullständig återställning är på plats?
Steg 2: Välj en process som uppfyller dina affärsbehov
Lösningen måste replikera rätt data i kontrollplanet, beräkningsplanet och datakällorna. Redundanta arbetsytor för katastrofåterställning måste mappas till olika kontrollplaner i olika regioner. Du måste regelbundet synkronisera dessa data med hjälp av en skriptbaserad lösning, antingen ett synkroniseringsverktyg eller ett CI/CD-arbetsflöde. Du behöver inte synkronisera data från själva beräkningsplanets nätverk, till exempel från Databricks Runtime-arbetare.
Om du använder funktionen VNet-inmatning (inte tillgängligt med alla prenumerations- och distributionstyper) kan du konsekvent distribuera dessa nätverk i båda regionerna med hjälp av mallbaserade verktyg som Terraform.
Dessutom måste du se till att dina datakällor replikeras efter behov mellan regioner.
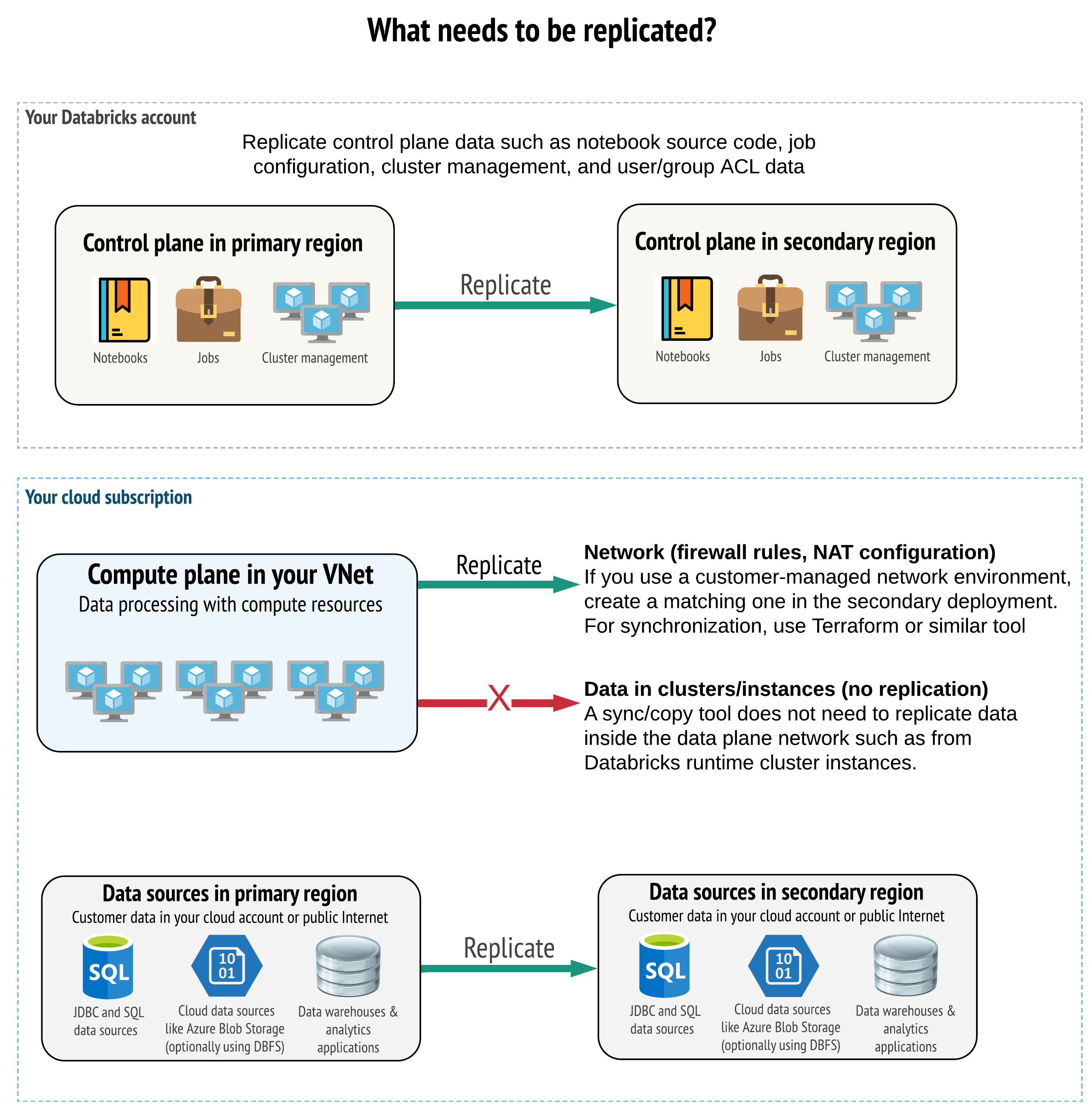
Allmänna metodtips
Allmänna bästa praxis för en framgångsrik katastrofberedskapsplan inkluderar:
Förstå vilka processer som är viktiga för verksamheten och måste köras i haveriberedskap.
Identifiera tydligt vilka tjänster som ingår, vilka data som bearbetas, vad dataflödet är och var de lagras.
Isolera tjänsterna och data så mycket som möjligt. Skapa till exempel en särskild molnlagringscontainer för data för haveriberedskap eller flytta Azure Databricks-objekt som behövs under en katastrof till en separat arbetsyta.
Det är ditt ansvar att upprätthålla integriteten mellan primära och sekundära distributioner för andra objekt som inte lagras i Databricks-kontrollplanet.
Varning
Bästa praxis är att du inte lagrar data i rot-ADLS (för arbetsytor som skapades före den 6 mars 2023, Azure Blob Storage) som används för DBFS-rotåtkomst för arbetsytan. DBFS-rotlagring stöds inte för produktionskunddata. Databricks rekommenderar också att du inte lagrar bibliotek, konfigurationsfiler eller init-skript på den här platsen.
När det gäller datakällor rekommenderar vi att du använder inbyggda Azure-verktyg för replikering och redundans för att replikera data till katastrofåterställningsregionerna.
Välj en strategi för återställningslösning
Typiska haveriberedskapslösningar omfattar två (eller eventuellt fler) arbetsytor. Du kan välja mellan flera strategier. Tänk på den potentiella längden på störningen (timmar eller kanske till och med en dag), arbetet för att säkerställa att arbetsytan är fullt fungerande och arbetet med att återställa till den primära regionen.
Strategi för aktiv-passiv lösning
En aktiv-passiv lösning är den vanligaste och enklaste lösningen, och den här typen av lösning är i fokus för den här artikeln. En aktiv-passiv lösning synkroniserar ändringar av data och objekt från din aktiva utplacering till din passiva utplacering. Om du vill kan du ha flera passiva distributioner i olika regioner, men den här artikeln fokuserar på den enskilda passiva distributionsmetoden. Vid en katastrofåterställning blir den passiva distributionen i den sekundära regionen din aktiva distribution.
Det finns två huvudsakliga varianter av den här strategin:
- Enhetlig lösning (företagsvis): Exakt en uppsättning aktiva och passiva distributioner som stöder hela organisationen.
- Lösning efter avdelning eller projekt: Varje avdelning eller projektdomän har en separat haveriberedskapslösning. Vissa organisationer vill frikoppla detaljer om haveriberedskap mellan avdelningar och använda olika primära och sekundära regioner för varje team utifrån varje teams unika behov.
Det finns andra varianter, till exempel att använda passiv distribution för skrivskyddade användningsfall. Om du har arbetsuppgifter som är skrivskyddade, till exempel användarfrågor, kan de köras på en passiv lösning så länge de inte ändrar data eller Azure Databricks-objekt som anteckningsböcker eller jobb.
Strategi för aktiv-aktiv lösning
I en aktiv-aktiv lösning kör du alla dataprocesser i båda regionerna hela tiden parallellt. Driftteamet måste se till att en dataprocess, till exempel ett jobb, endast markeras som slutförd när den har slutförts i båda regionerna. Objekt kan inte ändras i produktion och måste följa en strikt CI/CD-process från utveckling och mellanlagring till produktion.
En aktiv-aktiv lösning är den mest komplexa strategin, och eftersom arbeten körs i båda regionerna tillkommer extra kostnader.
Precis som med den aktiva-passiva strategin kan du implementera detta som en enhetlig organisationslösning eller per avdelning.
Du kanske inte behöver en motsvarande arbetsyta i det sekundära systemet för alla arbetsytor, beroende på ditt arbetsflöde. En utvecklings- eller stagingmiljö kanske till exempel inte behöver en dubblett. Med en väl utformad utvecklingspipeline kanske du enkelt kan rekonstruera dessa arbetsytor om det behövs.
Välj verktyg
Det finns två huvudsakliga metoder för verktyg för att hålla data så lika som möjligt mellan arbetsytor i dina primära och sekundära regioner:
- Synkroniseringsklient som kopierar från primär till sekundär: En synkroniseringsklient skickar produktionsdata och tillgångar från den primära regionen till den sekundära regionen. Normalt körs detta enligt schema.
- CI/CD-verktyg för parallell distribution: För produktionskod och tillgångar använder du CI/CD-verktyg som push-överför ändringar till produktionssystem samtidigt till båda regionerna. Till exempel, när du överför kod och resurser från staging/utveckling till produktion, gör ett CI/CD-system det tillgängligt i båda regionerna samtidigt. Huvudidén är att behandla alla artefakter på en Azure Databricks-arbetsyta som infrastruktur som kod. De flesta artefakter kan samdistribueras till både primära och sekundära arbetsytor, medan vissa artefakter kan behöva distribueras först efter en haveriberedskapshändelse. Verktyg finns i Automation-skript, exempel och prototyper.
Följande diagram kontrasterar dessa två metoder.
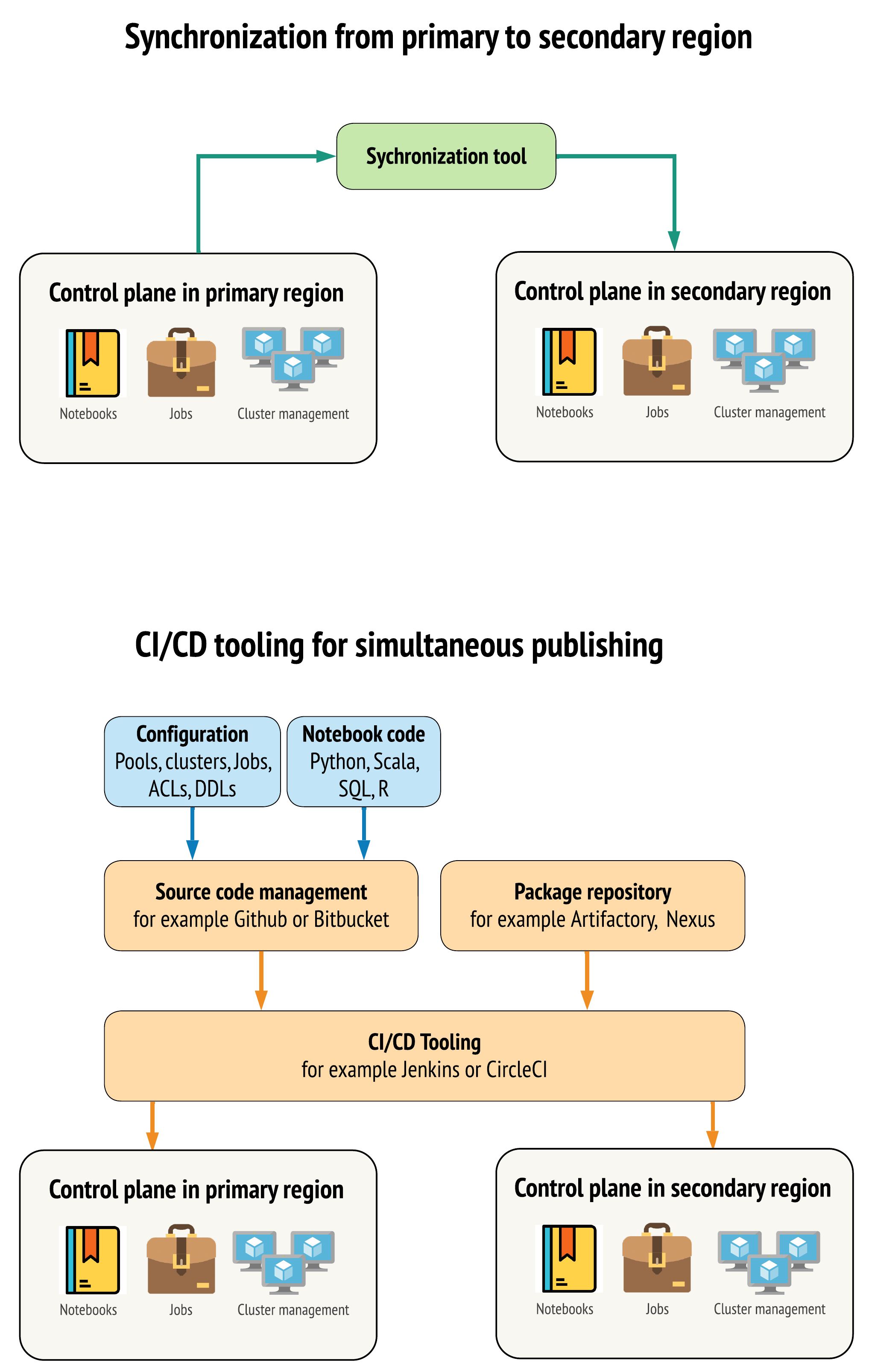
Beroende på dina behov kan du kombinera metoderna. Använd till exempel CI/CD för notebook-källkod, men använd synkronisering för konfiguration som pooler och åtkomstkontroller.
I följande tabell beskrivs hur du hanterar olika typer av data med varje verktygsalternativ.
| beskrivning | Hur man hanterar CI/CD-verktyg | Så här hanterar du med synkroniseringsverktyget |
|---|---|---|
| Källkod: export av källkod från notebookar och för paketerade programvarubibliotek | Distribuera både till primär och sekundär. | Synkronisera källkod från primär till sekundär. |
| Användare och grupper | Hantera metadata som konfiguration i Git. Du kan också använda samma identitetsprovider (IdP) för båda arbetsytorna. Samtidigt distribuera användar- och gruppdata till primära och sekundära etableringar. | Använd SCIM eller annan automatisering för båda regionerna. Manuellt skapande rekommenderas inte , men om det används måste det göras för båda samtidigt. Om du använder en manuell installation skapar du en schemalagd automatiserad process för att jämföra listan över användare och grupper mellan de två distributionerna. |
| Poolkonfigurationer | Kan vara mallar i Git. Samdistribuering till primär och sekundär. I sekundärt måste dock min_idle_instances vara noll tills haveriberedskapshändelsen. |
Pooler som skapas med valfria min_idle_instances när de synkroniseras till en sekundär arbetsyta med hjälp av API:et eller CLI. |
| Jobbkonfigurationer | Kan vara mallar i Git. Distribuera jobbdefinitionen som den är för primär distribution. För sekundär distribution distribuerar du jobbet och ställer in samtidigheten på noll. Detta inaktiverar jobbet i den här distributionen och förhindrar extra körningar. Ändra samtidighetsvärdet när den sekundära distributionen blir aktiv. | Om jobben av någon anledning körs på befintliga <interactive> kluster måste synkroniseringsklienten koppla till motsvarande cluster_id i den sekundära arbetsytan. |
| Åtkomstkontrollistorna (ACL) | Kan vara mallar i Git. Distribuera till huvud- och sekundärdistributioner av notebooks, mappar och kluster. Lagra dock data för jobb tills haveriberedskapshändelsen. | Permissions API kan ange åtkomstkontroller för kluster, jobb, pooler, anteckningsböcker och mappar. En synkroniseringsklient måste mappa till motsvarande objekt-ID:er för varje objekt på den sekundära arbetsytan. Databricks rekommenderar att du skapar en karta över objekt-ID:t från den primära till den sekundära arbetsytan medan du synkroniserar objekten innan du replikerar åtkomstkontrollerna. |
| Bibliotek | Inkludera i källkods- och kluster-/jobbmallar. | Synkronisera anpassade bibliotek från centraliserade lagringsplatser, DBFS eller molnlagring (kan monteras). |
| Init-skript för kluster | Inkludera i källkoden om du vill. | För enklare synkronisering lagrar du init-skript på den primära arbetsytan i en gemensam mapp eller i en liten uppsättning mappar om möjligt. |
| Monteringspunkter | Inkludera i källkoden om den bara skapas via notebook-baserade jobb eller kommando-API. | Använd jobb som kan köras som Azure Data Factory-aktiviteter (ADF). Observera att lagringsslutpunkterna kan ändras med tanke på att arbetsytor finns i olika regioner. Detta beror också mycket på din strategi för datakatastrofåterställning. |
| Metadata för tabell | Inkludera med källkod om det bara skapas via notebook-baserade jobb eller kommando-API. Detta gäller både internt Azure Databricks-metaarkiv eller externt konfigurerat metaarkiv. | Jämför metadatadefinitionerna mellan metaarkiven med hjälp av Spark Catalog-API :et eller Visa skapa tabell via en notebook-fil eller skript. Observera att tabellerna för underliggande lagring kan vara regionbaserade och skiljer sig mellan metaarkivinstanser. |
| Hemligheter | Inkludera i källkoden om den bara skapas via Kommando-API. Observera att visst hemlighetsinnehåll kan behöva ändras mellan det primära och det sekundära. | Hemligheter skapas på båda arbetsytorna via API:et. Observera att visst hemlighetsinnehåll kan behöva ändras mellan det primära och det sekundära. |
| Klusterkonfigurationer | Kan vara mallar i Git. Samtida distribution till primära och sekundära distributioner, även om de i den sekundära distributionen bör avslutas tills katastrofåterställningshändelsen. | Kluster skapas när de har synkroniserats till den sekundära arbetsytan med hjälp av API:et eller CLI. De kan uttryckligen avslutas om du vill, beroende på inställningar för automatisk avslutning. |
| Behörigheter för anteckningsbok-, jobb- och mapp | Kan vara mallar i Git. Samdistribuera till primära och sekundära utplaceringar. | Replikera med hjälp av API:et Behörigheter. |
Välj regioner och flera sekundära arbetsytor
Du behöver fullständig kontroll över din haveriberedskapsutlösare. Du kan välja att utlösa detta när som helst eller av någon anledning. Du måste ta ansvar för katastrofåterställningsstabilisering innan du kan starta om driften i återställningsläge till normal produktion. Det innebär vanligtvis att du måste skapa flera Azure Databricks-arbetsytor för att hantera dina behov av produktions- och haveriberedskap och välja din sekundära redundansregion.
I Azure kontrollerar du din datareplikering samt tillgängligheten för produkt- och VM-typer.
Steg 3: Förbereda arbetsytor och göra en engångskopia
Om en arbetsyta redan är i produktion är det vanligt att köra en engångskopieringsåtgärd för att synkronisera din passiva distribution med din aktiva distribution. Den här engångskopian hanterar följande:
- Datareplikering: Replikera med hjälp av en molnreplikeringslösning eller en djupkloningsåtgärd för Delta.
- Tokengenerering: Använd tokengenerering för att automatisera replikeringen och framtida arbetsbelastningar.
- Replikering av arbetsyta: Använd replikering av arbetsytor med hjälp av de metoder som beskrivs i steg 4: Förbered dina datakällor.
- Validering av arbetsyta: – testa för att se till att arbetsytan och processen kan köras korrekt och ge förväntade resultat.
Efterföljande kopierings- och synkroniseringsåtgärder går snabbare efter den första engångskopieringsåtgärden. All loggning från dina verktyg registrerar även vad som har ändrats och när.
Steg 4: Förbereda dina datakällor
Azure Databricks kan bearbeta en mängd olika datakällor med hjälp av batchbearbetning eller dataströmmar.
Batchbearbetning från datakällor
När data bearbetas i batchar finns de vanligtvis i en datakälla som enkelt kan replikeras eller levereras till en annan region.
Data kan till exempel regelbundet laddas upp till en molnlagringsplats. I haveriberedskapsläge för den sekundära regionen måste du se till att filerna laddas upp till lagringen i den sekundära regionen. Arbetsbelastningar måste läsa från den sekundära regionens lagring och skriva till den sekundära regionens lagring.
Dataströmmar
Att bearbeta en dataström är en större utmaning. Strömmande data kan matas in från olika källor, bearbetas och skickas till en strömningslösning:
- Meddelandekö, till exempel Kafka
- Datainsamlingsström för databasändring
- Filbaserad kontinuerlig bearbetning
- Filbaserad schemalagd bearbetning, även kallad att aktivera en gång
I alla dessa fall måste du konfigurera dina datakällor för att hantera återställningsläge vid katastrof och använda din sekundära distribution i den sekundära regionen.
En strömskrivare lagrar en kontrollpunkt med information om de data som har bearbetats. Den här kontrollpunkten kan innehålla en dataplats (vanligtvis molnlagring) som måste ändras till en ny plats för att säkerställa en lyckad omstart av strömmen. Undermappen source under kontrollpunkten kan till exempel lagra den filbaserade molnmappen.
Den här kontrollpunkten måste replikeras i tid. Överväg att synkronisera kontrollpunktsintervallet med valfri ny molnreplikeringslösning.
Kontrollpunktsuppdateringen är en funktion av skrivaren och gäller därför för dataströminmatning eller bearbetning och lagring på en annan strömningskälla.
För strömningsarbetsbelastningar kontrollerar du att kontrollpunkter konfigureras i kundhanterad lagring så att de kan replikeras till den sekundära regionen för arbetsbelastningens återupptagande från tidpunkten för det senaste felet. Du kan också välja att köra den sekundära strömningsprocessen parallellt med den primära processen.
Steg 5: Implementera och testa din lösning
Testa regelbundet konfigurationen av katastrofåterställningen för att säkerställa att den fungerar korrekt. Det finns inget värde i att underhålla en haveriberedskapslösning om du inte kan använda den när du behöver den. Vissa företag byter mellan regioner med några månaders mellanrum. Om du byter region enligt ett regelbundet schema testas dina antaganden och processer och ser till att de uppfyller dina återställningsbehov. Detta säkerställer också att din organisation är bekant med principer och procedurer för nödsituationer.
Viktigt!
Testa regelbundet din haveriberedskapslösning under verkliga förhållanden.
Om du upptäcker att du saknar ett objekt eller en mall och fortfarande måste förlita dig på den information som lagras på den primära arbetsytan kan du ändra planen för att ta bort dessa hinder, replikera den här informationen i det sekundära systemet eller göra den tillgänglig på något annat sätt.
Testa eventuella nödvändiga organisationsändringar i dina processer och konfigurationen i allmänhet. Din haveriberedskapsplan påverkar distributionspipelinen och det är viktigt att ditt team vet vad som behöver synkroniseras. När du har konfigurerat dina arbetsytor för haveriberedskap måste du se till att din infrastruktur (manuell eller kod), jobb, notebook-fil, bibliotek och andra arbetsyteobjekt är tillgängliga i den sekundära regionen.
Prata med ditt team om hur du expanderar standardarbetsprocesser och konfigurationspipelines för att distribuera ändringar till alla arbetsytor. Hantera användaridentiteter på alla arbetsytor. Kom ihåg att konfigurera verktyg som jobbautomatisering och övervakning för nya arbetsytor.
Planera för och testa ändringar i konfigurationsverktyget:
- Inmatning: Förstå var dina datakällor finns och var dessa källor hämtar sina data. Om möjligt parametriserar du källan och ser till att du har en separat konfigurationsmall för att arbeta med dina sekundära distributioner och sekundära regioner. Förbered en plan för redundans och testa alla antaganden.
- Körningsändringar: Om du har en schemaläggare som utlöser jobb eller andra åtgärder kan du behöva konfigurera en separat schemaläggare som fungerar med den sekundära distributionen eller dess datakällor. Förbered en plan för redundans och testa alla antaganden.
- Interaktiv anslutning: Överväg hur konfigurations-, autentiserings- och nätverksanslutningar kan påverkas av regionala störningar för all användning av REST-API:er, CLI-verktyg eller andra tjänster som JDBC/ODBC. Förbered en plan för redundans och testa alla antaganden.
- Automatiseringsändringar: Förbered en plan för redundans och testa alla antaganden för alla automatiseringsverktyg.
- Utdata: För verktyg som genererar utdata eller loggar förbereder du en plan för redundans och testar alla antaganden.
Testa felövergång
Haveriberedskap kan utlösas av många olika scenarier. Det kan utlösas av en oväntad paus. Vissa kärnfunktioner kan vara nere, inklusive molnnätverk, molnlagring eller en annan kärntjänst. Du har inte åtkomst till att stänga av systemet på ett korrekt sätt och måste försöka återställa. "Processen kan dock triggas av ett avstängnings- eller planerat avbrott, eller till och med genom periodiska växlingar av dina aktiva utplaceringar mellan två regioner."
När du testar redundans ansluter du till systemet och kör en avstängningsprocess. Kontrollera att alla jobb är slutförda och att klustren avslutas.
En synkroniseringsklient (eller CI/CD-verktyg) kan replikera relevanta Azure Databricks-objekt och resurser till den sekundära arbetsytan. För att aktivera den sekundära arbetsytan kan processen innehålla några eller alla av följande:
- Kör tester för att bekräfta att plattformen är uppdaterad.
- Inaktivera pooler och kluster i den primära regionen så att den primära regionen inte börjar bearbeta nya data om den misslyckade tjänsten returnerar online.
- Återställningsprocess:
- Kontrollera datumet för de senaste synkroniserade data. Referera till [_](# dr-terminologi). Informationen om det här steget varierar beroende på hur du synkroniserar data och dina unika affärsbehov.
- Stabilisera dina datakällor och se till att alla är tillgängliga. Inkludera alla externa datakällor, till exempel Azure Cloud SQL, delta lake, parquet eller andra filer.
- Hitta din återställningspunkt för direktuppspelning. Konfigurera processen för att starta om därifrån och ha en process redo att identifiera och eliminera potentiella dubbletter (Delta Lake gör det enklare).
- Slutför dataflödesprocessen och informera användarna.
- Starta relevanta pooler (eller öka
min_idle_instancestill ett relevant tal). - Starta relevanta kluster (om de inte har avslutats).
- Ändra den parallella körningen för jobb och utför de relevanta jobben. Det kan vara engångskörningar eller periodiska körningar.
- För alla externa verktyg som använder en URL eller ett domännamn för din Azure Databricks-arbetsyta uppdaterar du konfigurationerna för att ta hänsyn till det nya kontrollplanet. Du kan till exempel uppdatera URL:er för REST-API:er och JDBC/ODBC-anslutningar. Azure Databricks-webbprogrammets kundriktade URL ändras när kontrollplanet ändras, så meddela organisationens användare om den nya URL:en.
Teståterställning (failback)
Återställning efter fel är enklare att kontrollera och kan utföras i ett underhållsfönster. Den här planen kan innehålla några eller alla av följande:
- Få en bekräftelse på att den primära regionen har återställts.
- Inaktivera pooler och kluster i den sekundära regionen så att de inte börjar bearbeta nya data.
- Synkronisera alla nya eller ändrade tillgångar på den sekundära arbetsytan tillbaka till den primära distributionen. Beroende på utformningen av dina redundansskript kan du kanske köra samma skript för att synkronisera objekten från den sekundära regionen (haveriberedskap) till den primära regionen (produktionsregionen).
- Synkronisera eventuella nya datauppdateringar tillbaka till den primära distributionen. Du kan använda granskningsspår av loggar och Delta-tabeller för att garantera att ingen data går förlorad.
- Stäng av alla arbetslaster i katastrofåterställningsregionen.
- Ändra jobben och användarnas URL till den primära regionen.
- Kör tester för att bekräfta att plattformen är uppdaterad.
- Starta relevanta pooler (eller öka
min_idle_instancestill ett relevant tal). - Starta relevanta kluster (om de inte har avslutats).
- Ändra den samtidiga körningen för jobb och kör relevanta jobb. Det kan vara engångskörningar eller periodiska körningar.
- Vid behov konfigurerar du den sekundära regionen igen för framtida katastrofåterställning.
Automation-skript, exempel och prototyper
Automation-skript att tänka på för dina haveriberedskapsprojekt:
- Databricks rekommenderar att du använder Databricks Terraform-providern för att utveckla din egen synkroniseringsprocess.
- Se även Databricks Workspace Migration Tools för exempel- och prototypskript. Utöver Azure Databricks-objekt replikerar du alla relevanta Azure Data Factory-pipelines så att de refererar till en länkad tjänst som är mappad till den sekundära arbetsytan.
- Projektet Databricks Sync (DBSync) är ett objektsynkroniseringsverktyg som säkerhetskopierar, återställer och synkroniserar Databricks-arbetsytor.