Konfigurera inställningar för Azure Databricks-jobb
Den här artikeln innehåller information om hur du konfigurerar Azure Databricks-jobb och enskilda jobbuppgifter i användargränssnittet för jobb. Om du vill veta mer om hur du använder Databricks CLI för att redigera jobbinställningar kör du CLI-kommandot databricks jobs update -h. Mer information om hur du använder jobb-API:et finns i Jobb-API:et.
Vissa konfigurationsalternativ är tillgängliga för jobbet och andra alternativ är tillgängliga för enskilda uppgifter. De maximala samtidiga körningarna kan till exempel bara anges för jobbet, medan återförsöksprinciper definieras för varje aktivitet.
Redigera ett jobb
Så här ändrar du konfigurationen för ett jobb:
- Klicka på
 Arbetsflöden i sidofältet.
Arbetsflöden i sidofältet. - Klicka på jobbnamnet i kolumnen Namn.
Sidopanelen visar jobbinformationen. Du kan ändra utlösaren för jobbet, beräkningskonfigurationen, meddelanden, det maximala antalet samtidiga körningar, konfigurera tröskelvärden för varaktighet och lägga till eller ändra taggar. Om jobbåtkomstkontroll är aktiverat kan du också redigera jobbbehörigheter.
Lägga till parametrar för alla jobbaktiviteter
Du kan konfigurera parametrar för ett jobb som skickas till någon av jobbets uppgifter som accepterar nyckel/värde-parametrar, inklusive Python-hjulfiler som har konfigurerats för att acceptera nyckelordsargument. Parametrar som anges på jobbnivå läggs till i konfigurerade parametrar på aktivitetsnivå. Jobbparametrar som skickas till aktiviteter visas i aktivitetskonfigurationen, tillsammans med eventuella parametrar som konfigurerats för aktiviteten.
Du kan också skicka jobbparametrar till aktiviteter som inte har konfigurerats med nyckelvärdesparametrar som JAR eller Spark Submit uppgifter. Om du vill skicka jobbparametrar till dessa aktiviteter formaterar du argumenten som {{job.parameters.[name]}}, och [name] ersätter med key parametern som identifierar parametern.
Jobbparametrar har företräde framför aktivitetsparametrar. Om en jobbparameter och en aktivitetsparameter har samma nyckel åsidosätter jobbparametern aktivitetsparametern.
Du kan åsidosätta konfigurerade jobbparametrar eller lägga till nya jobbparametrar när du kör ett jobb med olika parametrar eller reparera en jobbkörning.
Du kan också dela kontext om jobb och aktiviteter med hjälp av en uppsättning referenser för dynamiskt värde.
Om du vill lägga till jobbparametrar klickar du på Redigera parametrar på sidan Jobbinformation och anger nyckeln och standardvärdet för varje parameter. Om du vill visa en lista över tillgängliga referenser för dynamiskt värde klickar du på Bläddra bland dynamiska värden.
Lägga till taggar i ett jobb
Om du vill lägga till etiketter eller key:value-attribut i jobbet kan du lägga till taggar när du redigerar jobbet. Du kan använda taggar för att filtrera jobb i listan Jobb. Du kan till exempel använda en department tagg för att filtrera alla jobb som tillhör en viss avdelning.
Kommentar
Eftersom jobbtaggar inte är utformade för att lagra känslig information, till exempel personligt identifierbar information eller lösenord, rekommenderar Databricks att du endast använder taggar för icke-känsliga värden.
Taggar sprids också till jobbkluster som skapas när ett jobb körs, så att du kan använda taggar med din befintliga klusterövervakning.
Om du vill lägga till eller redigera taggar klickar du på + Tagg på sidan Jobbinformation . Du kan lägga till taggen som en nyckel och ett värde eller en etikett. Om du vill lägga till en etikett anger du etiketten i fältet Nyckel och lämnar fältet Värde tomt.
Konfigurera delade kluster
Om du vill se aktiviteter som är associerade med ett kluster klickar du på fliken Uppgifter och hovra över klustret på sidopanelen. Om du vill ändra klusterkonfigurationen för alla associerade uppgifter klickar du på Konfigurera under klustret. Om du vill konfigurera ett nytt kluster för alla associerade aktiviteter klickar du på Växla under klustret.
Kontrollera åtkomsten till ett jobb
Med åtkomstkontroll för jobb kan jobbägare och administratörer bevilja detaljerad behörighet för sina jobb. Jobbägare kan välja vilka andra användare eller grupper som kan visa jobbresultatet. Ägare kan också välja vem som kan hantera sina jobbkörningar (Kör nu och Avbryt körningsbehörigheter).
Information om jobbbehörighetsnivåer finns i Jobb-ACL:er.
Du måste ha behörigheten KAN HANTERA eller ÄR ÄGARE för jobbet för att kunna hantera behörigheter för det.
I sidofältet klickar du på Jobbkörningar.
Klicka på namnet på ett jobb.
I panelen Jobbinformation klickar du på Redigera behörigheter.
I Behörighetsinställningar klickar du på den nedrullningsbara menyn Välj användare, grupp eller Tjänsthuvudnamn... och väljer en användare, grupp eller tjänstens huvudnamn.
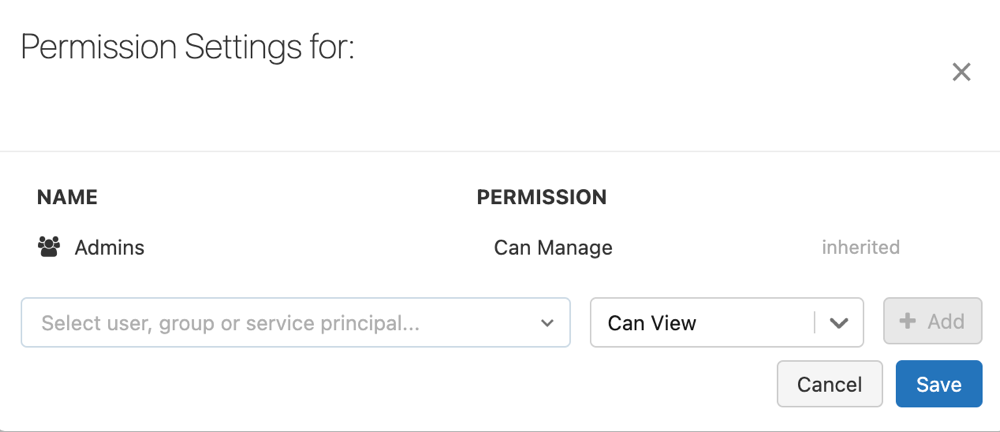
Klicka på Lägg till.
Klicka på Spara.
Hantera jobbägaren
Som standard har skaparen av ett jobb behörigheten IS OWNER och är användaren i jobbets kör som-inställning . Jobbet körs som användarens identitet i inställningen Kör som . Mer information om inställningen Kör som finns i Kör ett jobb som tjänstens huvudnamn.
Arbetsyteadministratörer kan ändra jobbets ägare till sig själva. När ägarskapet överförs beviljas den tidigare ägaren behörigheten CAN MANAGE
Kommentar
RestrictWorkspaceAdmins När inställningen på en arbetsyta är inställd ALLOW ALLpå kan arbetsyteadministratörer ändra en jobbägare till valfri användare eller tjänsthuvudnamn på arbetsytan. Information om hur du begränsar arbetsyteadministratörer till att endast ändra en jobbägare till sig själva finns i Begränsa arbetsyteadministratörer.
Konfigurera maximala samtidiga körningar
Klicka på Redigera samtidiga körningar under Avancerade inställningar för att ange det maximala antalet parallella körningar för det här jobbet. Azure Databricks hoppar över körningen om jobbet redan har nått sitt maximala antal aktiva körningar när du försöker starta en ny körning. Ange det här värdet högre än standardvärdet 1 för att utföra flera körningar av samma jobb samtidigt. Detta är användbart om du till exempel utlöser jobbet enligt ett vanligt schema och vill tillåta att efterföljande körningar överlappar varandra eller om du vill utlösa flera körningar som skiljer sig åt med deras indataparametrar.
Aktivera köning av jobbkörningar
Om du vill att körningar av ett jobb ska placeras i en kö för att köras senare när de inte kan köras omedelbart på grund av samtidighetsgränser klickar du på växlingsknappen Kö under Avancerade inställningar. Se Vad händer om mitt jobb inte kan köras på grund av samtidighetsgränser?.
Kommentar
Köning är aktiverat som standard för jobb som skapades via användargränssnittet efter den 15 april 2024.
Konfigurera en förväntad slutförandetid eller en tidsgräns för ett jobb
Du kan konfigurera valfria tröskelvärden för varaktighet för ett jobb, inklusive en förväntad slutförandetid för jobbet och en maximal slutförandetid för jobbet. Om du vill konfigurera tröskelvärden för varaktighet klickar du på Ange tröskelvärden för varaktighet.
Om du vill konfigurera en förväntad slutförandetid för jobbet anger du den förväntade varaktigheten i fältet Varning . Om jobbet överskrider det här tröskelvärdet kan du konfigurera meddelanden för det jobb som körs långsamt. Se Konfigurera meddelanden för jobb som körs långsamt eller sent.
Om du vill konfigurera en maximal slutförandetid för ett jobb anger du den maximala varaktigheten i fältet Tidsgräns . Om jobbet inte slutförs under den här tiden anger Azure Databricks statusen "Tidsgräns" och jobbet stoppas.
Redigera en uppgift
Så här anger du konfigurationsalternativ för aktiviteter:
- Klicka på Arbetsflöden i sidofältet.
- Klicka på jobbnamnet i kolumnen Namn.
- Klicka på fliken Uppgifter och välj den uppgift som ska redigeras.
Definiera aktivitetsberoenden
Du kan definiera ordningen på körningen av aktiviteter i ett jobb med hjälp av listrutan Beror på . Du kan ange det här fältet till en eller flera aktiviteter i jobbet.
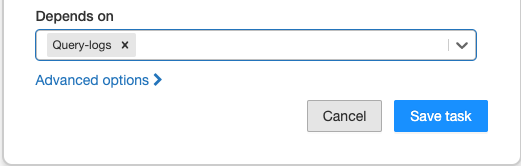
Kommentar
Beroende är inte synligt om jobbet bara består av en uppgift.
När du konfigurerar aktivitetsberoenden skapas en riktad Acyclic Graph (DAG) för aktivitetskörning, ett vanligt sätt att representera körningsordning i jobbschemaläggare. Tänk dig till exempel följande jobb som består av fyra uppgifter:
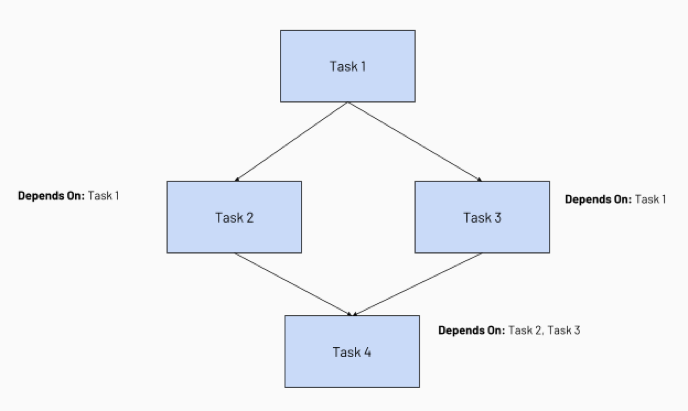
- Uppgift 1 är rotuppgiften och är inte beroende av någon annan aktivitet.
- Uppgift 2 och Uppgift 3 beror på att uppgift 1 slutförs först.
- Slutligen är aktivitet 4 beroende av att uppgift 2 och uppgift 3 slutförs.
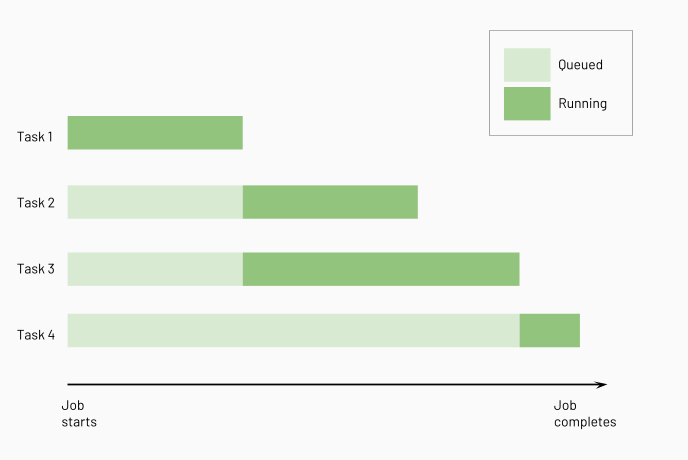
Azure Databricks kör uppströmsaktiviteter innan du kör underordnade aktiviteter och kör så många av dem parallellt som möjligt. Följande diagram illustrerar bearbetningsordningen för dessa uppgifter:
Konfigurera ett kluster för en uppgift
Om du vill konfigurera klustret där en uppgift körs klickar du på den nedrullningsbara menyn Kluster . Du kan redigera ett delat jobbkluster, men du kan inte ta bort ett delat kluster om andra uppgifter fortfarande använder det.
Mer information om hur du väljer och konfigurerar kluster för att köra uppgifter finns i Använda Azure Databricks-beräkning med dina jobb.
Konfigurera beroende bibliotek
Beroende bibliotek installeras i klustret innan aktiviteten körs. Du måste ange alla aktivitetsberoenden för att säkerställa att de installeras innan körningen startar. Följ rekommendationerna i Hantera biblioteksberoenden för att ange beroenden.
Konfigurera en förväntad slutförandetid eller en tidsgräns för en aktivitet
Du kan konfigurera valfria tröskelvärden för varaktighet för en aktivitet, inklusive en förväntad slutförandetid för aktiviteten och en maximal slutförandetid för aktiviteten. Om du vill konfigurera tröskelvärden för varaktighet klickar du på Tröskelvärde för varaktighet.
Om du vill konfigurera aktivitetens förväntade slutförandetid anger du varaktigheten i fältet Varning . Om aktiviteten överskrider det här tröskelvärdet utlöses en händelse. Du kan använda den här händelsen för att meddela när en aktivitet körs långsamt. Se Konfigurera meddelanden för jobb som körs långsamt eller sent.
Om du vill konfigurera en maximal slutförandetid för en aktivitet anger du den maximala varaktigheten i fältet Tidsgräns . Om aktiviteten inte slutförs under den här tiden anger Azure Databricks statusen "Tidsgräns för tidsgräns".
Konfigurera en återförsöksprincip för en uppgift
Om du vill konfigurera en princip som avgör när och hur många gånger misslyckade aktivitetskörningar görs igen klickar du på + Lägg till bredvid Försök igen. Återförsöksintervallet beräknas i millisekunder mellan starten av den misslyckade körningen och den efterföljande återförsökskörningen.
Kommentar
Om du konfigurerar både timeout och återförsök gäller tidsgränsen för varje nytt försök.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för