Skapa avancerade system för hämtningsförhöjd generation
I föregående artikel diskuterades två alternativ för att skapa ett "chatta över dina data"-program, ett av de främsta användningsfallen för generativ AI i företag:
- Hämtning av utökad generering (RAG) som kompletterar en LLM-utbildning (Large Language Model) med en databas med sökbara artiklar som kan hämtas baserat på likhet med användarnas frågor och skickas till LLM för slutförande.
- Finjustering, vilket utökar LLM:s utbildning för att förstå mer om problemdomänen.
I föregående artikel diskuterades även när varje metod, pro och con ska användas för varje metod och flera andra överväganden.
Den här artikeln utforskar RAG mer ingående, särskilt allt arbete som krävs för att skapa en produktionsklar lösning.
I föregående artikel beskrevs stegen eller faserna i RAG med hjälp av följande diagram.
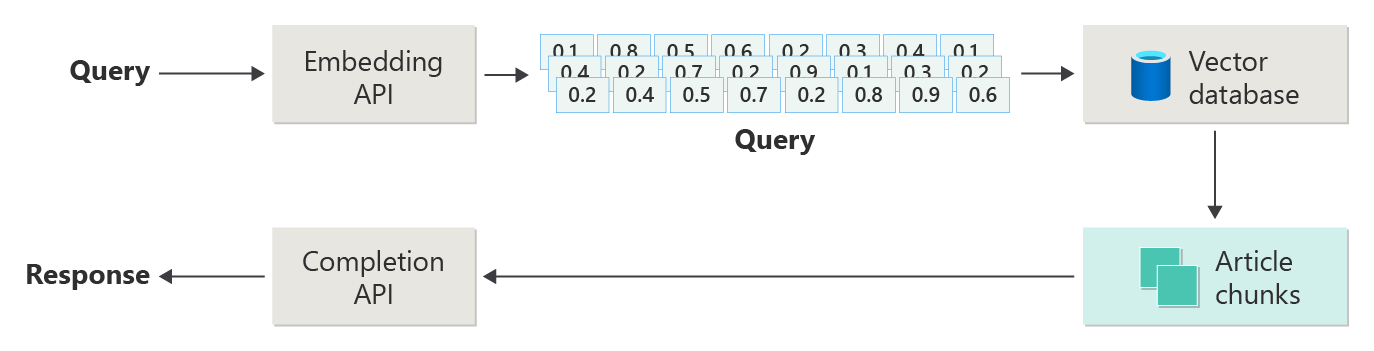
Den här skildringen har kallats "naiv RAG" och är ett användbart sätt att först förstå de mekanismer, roller och ansvarsområden som krävs för att implementera ett RAG-baserat chattsystem.
En mer verklig implementering har dock många fler för- och efterbearbetningssteg för att förbereda artiklarna, frågorna och svaren för användning. Följande diagram är en mer realistisk skildring av en RAG, som ibland kallas "avancerad RAG".

Den här artikeln innehåller ett konceptuellt ramverk för att förstå typerna av för- och efterbearbetningsproblem i ett verkligt RAG-baserat chattsystem, organiserat på följande sätt:
- Inmatningsfas
- Slutsatsdragningspipelinefas
- Utvärderingsfas
Som en konceptuell översikt tillhandahålls nyckelorden och idéerna som kontext och en utgångspunkt för ytterligare utforskning och forskning.
Inmatning
Inmatning handlar främst om att lagra organisationens dokument på ett sådant sätt att de enkelt kan hämtas för att besvara en användares fråga. Utmaningen är att se till att de delar av dokumenten som bäst matchar användarens fråga finns och används under slutsatsdragningen. Matchning utförs främst genom vektoriserade inbäddningar och en cosinélikhetssökning. Det underlättas dock genom att förstå innehållets natur (mönster, formulär osv.) och dataorganisationsstrategin (strukturen för data när de lagras i vektordatabasen).
Därför måste utvecklarna överväga följande:
- Förbearbetning och extrahering av innehåll
- Segmenteringsstrategi
- Segmenteringsorganisation
- Uppdateringsstrategi
Förbearbetning och extrahering av innehåll
Rent och korrekt innehåll är ett av de bästa sätten att förbättra den övergripande kvaliteten på ett RAG-baserat chattsystem. För att åstadkomma detta måste utvecklarna börja med att analysera formen och formen på de dokument som ska indexeras. Överensstämmer dokumenten med angivna innehållsmönster som dokumentation? Om inte, vilka typer av frågor kan dokumenten besvara?
Utvecklare bör åtminstone skapa steg i inmatningspipelinen för att:
- Standardisera textformat
- Hantera specialtecken
- Ta bort orelaterat, inaktuellt innehåll
- Konto för versionsinnehåll
- Konto för innehållsupplevelse (flikar, bilder, tabeller)
- Extrahera metadata
En del av den här informationen (till exempel metadata) kan vara användbar för att spara dokumentet i vektordatabasen för användning under hämtnings- och utvärderingsprocessen i slutsatsdragningspipelinen, eller kombineras med textsegmentet för att övertala segmentets vektorinbäddning.
Segmenteringsstrategi
Utvecklare måste bestämma hur ett längre dokument ska delas upp i mindre segment. Detta kan förbättra relevansen för det kompletterande innehåll som skickas till LLM för att besvara användarens fråga korrekt. Dessutom måste utvecklare överväga hur de ska använda segmenten vid hämtning. Detta är ett område där systemdesigners bör göra viss forskning om tekniker som används i branschen och utföra vissa experiment, till och med testa den i en begränsad kapacitet i organisationen.
Utvecklare måste tänka på:
- Segmentstorleksoptimering – Avgör vilken storlek som passar bäst för segmentet och hur du anger ett segment. Efter avsnitt? Efter stycke? Efter mening?
- Överlappande och glidande fönstersegment – Avgör hur innehållet ska delas upp i diskreta segment. Eller överlappar segmenten? Eller båda (skjutfönster)?
- Small2Big – Kommer innehållet att ordnas på ett sådant sätt att det är enkelt att hitta de närliggande meningarna eller innehåller stycken när du segmenterar på en detaljerad nivå som en enda mening? (Se "Segmenteringsorganisation") Om du hämtar den här ytterligare informationen och skickar den till LLM kan du ge den mer kontext när du svarar på användarens fråga.
Segmenteringsorganisation
I ett RAG-system är organisationen av data i vektordatabasen avgörande för effektiv hämtning av relevant information för att öka genereringsprocessen. Här följer de typer av indexerings- och hämtningsstrategier som utvecklare kan tänka sig:
- Hierarkiska index – Den här metoden innebär att skapa flera indexlager, där ett index på toppnivå (sammanfattningsindex) snabbt begränsar sökutrymmet till en delmängd av potentiellt relevanta segment och ett index på andra nivån (segmentindex) ger mer detaljerade pekare till faktiska data. Den här metoden kan avsevärt påskynda hämtningsprocessen eftersom den minskar antalet poster som ska genomsökas i det detaljerade indexet genom att filtrera igenom sammanfattningsindexet först.
- Specialiserade index – Specialiserade index som grafbaserade databaser eller relationsdatabaser kan användas beroende på typen av data och relationerna mellan segment. Till exempel:
- Grafbaserade index är användbara när segmenten har sammankopplad information eller relationer som kan förbättra hämtningen, till exempel källhänvisningsnätverk eller kunskapsdiagram.
- Relationsdatabaser kan vara effektiva om segmenten är strukturerade i ett tabellformat där SQL-frågor kan användas för att filtrera och hämta data baserat på specifika attribut eller relationer.
- Hybridindex – En hybridmetod kombinerar flera indexeringsstrategier för att utnyttja fördelarna med var och en. Utvecklare kan till exempel använda ett hierarkiskt index för inledande filtrering och ett grafbaserat index för att utforska relationer mellan segment dynamiskt under hämtningen.
Justeringsoptimering
För att förbättra relevansen och noggrannheten för de hämtade segmenten kan det vara fördelaktigt att justera dem närmare med de typer av frågor eller frågor som de är avsedda att besvara. En strategi för att åstadkomma detta är att generera och infoga en hypotetisk fråga för varje segment som representerar vilken fråga segmentet passar bäst att besvara. Detta hjälper på flera sätt:
- Förbättrad matchning: Under hämtningen kan systemet jämföra den inkommande frågan med dessa hypotetiska frågor för att hitta den bästa matchningen, vilket förbättrar relevansen för de segment som hämtas.
- Träningsdata för Mašinsko učenje-modeller: Dessa parkopplingar av frågor och segment kan fungera som träningsdata för att förbättra maskininlärningsmodellerna som ligger bakom RAG-systemet, vilket hjälper det att lära sig vilka typer av frågor som bäst besvaras av vilka segment.
- Direktfrågehantering: Om en riktig användarfråga matchar en hypotetisk fråga kan systemet snabbt hämta och använda motsvarande segment, vilket påskyndar svarstiden.
Varje segments hypotetiska fråga fungerar som en typ av "etikett" som vägleder hämtningsalgoritmen, vilket gör den mer fokuserad och sammanhangsberoende medveten. Detta är användbart i scenarier där segmenten täcker en mängd olika ämnen eller typer av information.
Uppdatera strategier
Om din organisation behöver indexera dokument som uppdateras ofta är det viktigt att underhålla en uppdaterad corpus för att säkerställa att retrieverkomponenten (logiken i systemet som ansvarar för att köra frågan mot vektordatabasen och returnera resultaten) kan komma åt den senaste informationen. Här följer några strategier för att uppdatera vektordatabasen i sådana system:
- Inkrementella uppdateringar:
- Regelbundna intervall: Schemalägg uppdateringar med jämna mellanrum (till exempel varje dag, varje vecka) beroende på hur ofta dokumentändringarna ändras. Den här metoden säkerställer att databasen uppdateras regelbundet.
- Utlösarbaserade uppdateringar: Implementera ett system där uppdateringar utlöser omindexering. Till exempel kan ändringar eller tillägg av ett dokument automatiskt initiera en omindexering av de berörda avsnitten.
- Partiella uppdateringar:
- Selektiv omindexering: I stället för att indexera om hela databasen uppdaterar du selektivt endast de delar av corpus som har ändrats. Detta kan vara effektivare än fullständig omindexering, särskilt för stora datamängder.
- Deltakodning: Lagra endast skillnaderna mellan befintliga dokument och deras uppdaterade versioner. Den här metoden minskar databearbetningsbelastningen genom att undvika behovet av att bearbeta oförändrade data.
- Versionshantering:
- Ögonblicksbilder: Underhålla versioner av dokument corpus vid olika tidpunkter. Detta gör att systemet kan återställa eller referera till tidigare versioner om det behövs och tillhandahåller en säkerhetskopieringsmekanism.
- Dokumentversionskontroll: Använd ett versionskontrollsystem för att spåra ändringar i dokument systematiskt. Detta bidrar till att upprätthålla historiken för ändringar och kan förenkla uppdateringsprocessen.
- Realtidsuppdateringar:
- Dataströmbearbetning: Använd dataströmbearbetningstekniker för att uppdatera vektordatabasen i realtid när ändringar görs i dokumenten. Detta kan vara viktigt för program där informationstimelalitet är av största vikt.
- Live-frågor: I stället för att enbart förlita sig på förindexerade vektorer implementerar du en mekanism för att fråga efter livedata för de senaste svaren, vilket möjligen kombinerar detta med cachelagrade resultat för effektivitet.
- Optimeringstekniker:
- Batchbearbetning: Ackumulera ändringar och bearbeta dem i batchar för att optimera användningen av resurser och minska kostnaderna som orsakas av frekventa uppdateringar.
- Hybridmetoder: Kombinera olika strategier, till exempel att använda inkrementella uppdateringar för mindre ändringar och fullständig omindexering för större uppdateringar eller strukturella ändringar i dokument corpus.
Att välja rätt uppdateringsstrategi eller kombination av strategier beror på specifika krav, till exempel storleken på dokument corpus, uppdateringsfrekvensen, behovet av realtidsdata och resurstillgänglighet. Varje metod har sina kompromisser när det gäller komplexitet, kostnad och svarstid för uppdateringar, så det är viktigt att utvärdera dessa faktorer baserat på programmets specifika behov.
Slutsatsdragningspipeline
Nu när artiklarna har segmenterats, vektoriserats och lagrats i en vektordatabas övergår fokus till utmaningar i slutförande.
- Skrivs användarens fråga på ett sådant sätt att resultatet hämtas från systemet som användaren letar efter?
- Bryter användarens fråga mot någon av våra principer?
- Hur skriver vi om användarens fråga för att förbättra dess chanser att hitta närmaste matchningar i vektordatabasen?
- Hur utvärderar vi frågeresultatet för att säkerställa att artikelsegmenten är anpassade till frågan?
- Hur utvärderar och ändrar vi frågeresultatet innan vi skickar dem till LLM för att säkerställa att den mest relevanta informationen ingår i LLM:s slutförande?
- Hur utvärderar vi LLM:s svar för att säkerställa att LLM:s slutförande svarar på användarens ursprungliga fråga?
- Hur ser vi till att LLM:s svar följer våra principer?
Som du ser finns det många uppgifter som utvecklare måste ta hänsyn till, främst i form av:
- Förbearbetning av indata för att optimera sannolikheten för att få önskat resultat
- Efterbearbetningsutdata för att säkerställa önskade resultat
Tänk på att hela slutsatsdragningspipelinen körs i realtid. Det finns inget rätt sätt att utforma logiken som utför för- och efterbearbetningsstegen, men det är troligt att det är en kombination av programmeringslogik och ytterligare anrop till en LLM. En av de viktigaste övervägandena då är kompromissen mellan att bygga den mest exakta och kompatibla pipelinen som är möjlig och den kostnad och svarstid som krävs för att få det att hända.
Nu ska vi titta på varje steg för att identifiera specifika strategier.
Förbearbetningssteg för frågor
Förbearbetning av frågor sker omedelbart efter att användaren har skickat sin fråga, enligt beskrivningen i det här diagrammet:

Målet med de här stegen är att se till att användaren ställer frågor inom omfånget för vårt system (och inte försöker "jailbreaka" systemet för att göra något oavsiktligt) och förbereda användarens fråga för att öka sannolikheten för att det kommer att hitta bästa möjliga artikelsegment med hjälp av cosinélikhet / "närmaste granne"-sökning.
Principkontroll – Det här steget kan omfatta logik som identifierar, tar bort, flaggar eller avvisar visst innehåll. Några exempel kan vara att ta bort personligt identifierbar information, ta bort expletives och identifiera "jailbreak"-försök. Jailbreaking avser de metoder som användare kan använda för att kringgå eller manipulera modellens inbyggda riktlinjer för säkerhet, etiska eller operativa åtgärder.
Omskrivning av frågor – Det kan vara allt från att expandera förkortningar och ta bort slang till att formulera om frågan för att ställa den mer abstrakt för att extrahera övergripande begrepp och principer ("step-back prompting").
En variant av steg-tillbaka-fråga är hypotetiska inbäddningar av dokument (HyDE) som använder LLM för att besvara användarens fråga, skapar en inbäddning för det svaret (den hypotetiska dokumentinbäddningen) och använder den inbäddningen för att utföra en sökning mot vektordatabasen.
Underfrågor
Det här bearbetningssteget gäller den ursprungliga frågan. Om den ursprungliga frågan är lång och komplex kan det vara användbart att programmatiskt dela upp den i flera mindre frågor och sedan kombinera alla svar.
Tänk dig till exempel en fråga som rör vetenskapliga upptäckter, särskilt inom fysiken. Användarens fråga kan vara: "Vem gjorde mer betydande bidrag till modern fysik, Albert Einstein eller Niels Bohr?"
Den här frågan kan vara komplex att hantera direkt eftersom "betydande bidrag" kan vara subjektiva och mångfacetterade. Om du delar upp det i underfrågor kan det bli mer hanterbart:
- Underfråga 1: "Vilka är albert Einsteins viktigaste bidrag till modern fysik?"
- Underfråga 2: "Vilka är niels Bohrs viktigaste bidrag till modern fysik?"
Resultaten av dessa underfrågor skulle beskriva de stora teorierna och upptäckterna av varje fysiker. Till exempel:
- För Einstein kan bidrag inkludera relativitetsteorin, den fotoelektriska effekten och E=mc^2.
- För Bohr kan bidrag inkludera hans modell av väteatomen, hans arbete med kvantmekanik och hans princip om komplementaritet.
När dessa bidrag har beskrivits kan de utvärderas för att fastställa:
- Underfråga 3: "Hur har Einsteins teorier påverkat utvecklingen av modern fysik?"
- Underfråga 4: "Hur har Bohrs teorier påverkat utvecklingen av modern fysik?"
Dessa underfrågor skulle utforska påverkan av varje forskares arbete på fältet, till exempel hur Einsteins teorier ledde till framsteg inom kosmologi och kvantteori, och hur Bohrs arbete bidrog till förståelsen av atomstruktur och kvantmekanik.
Att kombinera resultaten av dessa underfrågor kan hjälpa språkmodellen att bilda ett mer omfattande svar om vem som gjorde mer betydande bidrag till modern fysik, baserat på omfattningen och effekten av deras teoretiska framsteg. Den här metoden förenklar den ursprungliga komplexa frågan genom att hantera mer specifika, svarsbara komponenter och sedan syntetisera dessa resultat till ett sammanhängande svar.
Frågerouter
Det är möjligt att din organisation bestämmer sig för att dela upp sitt innehåll i flera vektorlager eller hela hämtningssystem. I så fall kan utvecklare använda en frågerouter, vilket är en mekanism som på ett intelligent sätt avgör vilka index eller hämtningsmotorer som ska användas baserat på den angivna frågan. Den primära funktionen för en frågerouter är att optimera hämtningen av information genom att välja den lämpligaste databasen eller indexet som kan ge de bästa svaren på en specifik fråga.
Frågeroutern fungerar vanligtvis vid en punkt efter att frågan har formulerats av användaren, men innan den skickas till några hämtningssystem. Här är ett förenklat arbetsflöde:
- Frågeanalys: LLM eller en annan komponent analyserar den inkommande frågan för att förstå dess innehåll, kontext och vilken typ av information som sannolikt behövs.
- Indexval: Baserat på analysen väljer frågeroutern en eller flera av potentiellt flera tillgängliga index. Varje index kan vara optimerat för olika typer av data eller frågor, till exempel kan vissa vara mer lämpade för faktafrågor, medan andra kanske utmärker sig för att tillhandahålla åsikter eller subjektivt innehåll.
- Frågesändning: Frågan skickas sedan till det valda indexet.
- Resultatsammanfattning: Svar från de valda indexen hämtas och eventuellt aggregeras eller bearbetas ytterligare för att bilda ett omfattande svar.
- Svarsgenerering: Det sista steget innebär att generera ett sammanhängande svar baserat på den hämtade informationen, eventuellt integrera eller syntetisera innehåll från flera källor.
Din organisation kan använda flera hämtningsmotorer eller index för följande användningsfall:
- Specialisering av datatyp: Vissa index kan specialisera sig på nyhetsartiklar, andra i akademiska artiklar och andra i allmänt webbinnehåll eller specifika databaser som de för medicinsk eller juridisk information.
- Optimering av frågetyp: Vissa index kan vara optimerade för snabba faktasökningar (till exempel datum, händelser), medan andra kan vara bättre för komplexa resonemangsuppgifter eller frågor som kräver djup domänkunskap.
- Algoritmiska skillnader: Olika hämtningsalgoritmer kan användas i olika motorer, till exempel vektorbaserade likhetssökningar, traditionella nyckelordsbaserade sökningar eller mer avancerade semantiska förståelsemodeller.
Föreställ dig ett RAG-baserat system som används i en medicinsk rådgivningskontext. Systemet har åtkomst till flera index:
- Ett medicinskt forskningspappersindex optimerat för detaljerade och tekniska förklaringar.
- Ett index för kliniska fallstudier som ger verkliga exempel på symtom och behandlingar.
- Ett allmänt hälsoinformationsindex för grundläggande frågor och information om folkhälsan.
Om en användare ställer en teknisk fråga om de biokemiska effekterna av ett nytt läkemedel kan frågeroutern prioritera indexet för medicinsk forskning på grund av dess djup och tekniska fokus. För en fråga om typiska symtom på en vanlig sjukdom kan dock det allmänna hälsoindexet väljas för sitt breda och lättförstålliga innehåll.
Steg för bearbetning efter hämtning
Bearbetning efter hämtning sker när komponenten retriever hämtar relevanta innehållssegment från vektordatabasen enligt diagrammet:

När kandidatinnehållssegment hämtas är nästa steg att verifiera att artikelsegmenten är användbara när du utökar LLM-prompten och sedan börjar förbereda uppmaningen som ska visas för LLM.
Utvecklare måste överväga flera aspekter av uppmaningen. En uppmaning som innehåller för mycket tilläggsinformation och vissa (kanske den viktigaste informationen) kan ignoreras. På samma sätt kan en uppmaning som innehåller irrelevant information i onödan påverka svaret.
Ett annat övervägande är nålen i ett höstacksproblem , en term som refererar till en känd egenhet hos vissa LLM där innehållet i början och slutet av en prompt har större vikt för LLM än innehållet i mitten.
Slutligen måste LLM:s maximala längd på kontextfönstret och antalet token som krävs för att slutföra utomordentligt långa uppmaningar (särskilt vid hantering av frågor i stor skala) beaktas.
För att hantera dessa problem kan en pipeline för bearbetning efter hämtning innehålla följande steg:
- Filtreringsresultat – I det här steget ser utvecklare till att artikelsegmenten som returneras av vektordatabasen är relevanta för frågan. Annars ignoreras resultatet när du skapar uppmaningen för LLM.
- Rangordna om – Rangordna artikelsegmenten som hämtats från vektorlagret för att säkerställa att relevant information finns nära kanterna (början och slutet) av prompten.
- Snabbkomprimering – Använda en liten, billig modell som är utformad för att kombinera och sammanfatta flera artikelsegment i en enda komprimerad fråga innan den skickas till LLM.
Bearbetningssteg efter slutförande
Bearbetning efter slutförande sker efter att användarens fråga och alla innehållssegment har skickats till LLM, enligt beskrivningen i följande diagram:

När uppmaningen har slutförts av LLM är det dags att verifiera slutförandet för att säkerställa att svaret är korrekt. En pipeline för bearbetning efter slutförande kan innehålla följande steg:
- Faktakontroll – Detta kan ta många former, men avsikten är att identifiera specifika anspråk som görs i artikeln som presenteras som fakta och sedan kontrollera dessa fakta för noggrannhet. Om faktakontrollsteget misslyckas kan det vara lämpligt att fråga om LLM i hopp om ett bättre svar eller returnera ett felmeddelande till användaren.
- Principkontroll – Det här är den sista försvarslinjen för att säkerställa att svaren inte innehåller skadligt innehåll, oavsett om det gäller användaren eller organisationen.
Utvärdering
Att utvärdera resultatet av ett icke-deterministiskt system är inte så enkelt som exempelvis enhets- eller integrationstester som de flesta utvecklare är bekanta med. Det finns flera faktorer att tänka på:
- Är användarna nöjda med de resultat de får?
- Får användarna korrekta svar på sina frågor?
- Hur samlar vi in feedback från användare? Har vi några principer som begränsar vilka data vi kan samla in om användardata?
- För diagnos av otillfredsställande svar, har vi insyn i allt arbete som gick till att besvara frågan? Har vi en logg över varje steg i slutsatsdragningspipelinen för indata och utdata så att vi kan utföra rotorsaksanalys?
- Hur kan vi göra ändringar i systemet utan regression eller försämring av resultaten?
Samla in och agera på feedback från användare
Som tidigare nämnts kan utvecklare behöva samarbeta med organisationens sekretessteam för att utforma mekanismer för feedbackinsamling och telemetri, loggning osv. för att möjliggöra kriminalteknik och rotorsaksanalys i en viss frågesession.
Nästa steg är att utveckla en utvärderingspipeline. Behovet av en utvärderingspipeline beror på komplexiteten och den tidsintensiva karaktären av att analysera ordagrant feedback och de bakomliggande orsakerna till svaren från ett AI-system. Den här analysen är avgörande eftersom det handlar om att undersöka varje svar för att förstå hur AI-frågan producerade resultaten, kontrollera lämpligheten i de innehållssegment som används i dokumentationen och de strategier som används för att dela upp dessa dokument.
Dessutom handlar det om att överväga eventuella extra för- eller efterbearbetningssteg som kan förbättra resultaten. Den här detaljerade undersökningen avslöjar ofta innehållsluckor, särskilt när det inte finns någon lämplig dokumentation som svar på en användares fråga.
Det är därför viktigt att skapa en utvärderingspipeline för att kunna hantera omfattningen av dessa uppgifter på ett effektivt sätt. En effektiv pipeline skulle använda anpassade verktyg för att utvärdera mått som approximerar kvaliteten på svaren från AI:n. Det här systemet skulle effektivisera processen för att avgöra varför ett specifikt svar gavs på en användares fråga, vilka dokument som användes för att generera det svaret och effektiviteten i den slutsatsdragningspipeline som bearbetar frågorna.
Gyllene datauppsättning
En strategi för att utvärdera resultatet av ett icke-deterministiskt system som ett RAG-chattsystem är att implementera en "gyllene datamängd". En gyllene datamängd är en kuraterad uppsättning frågor med godkända svar, metadata (t.ex. ämne och typ av fråga), referenser till källdokument som kan fungera som grundsanning för svar och till och med varianter (olika fraser för att fånga mångfalden av hur användare kan ställa samma frågor).
Den "gyllene datamängden" representerar det "bästa scenariot" och gör det möjligt för utvecklare att utvärdera systemet för att se hur bra det presterar och utföra regressionstester när de implementerar nya funktioner eller uppdateringar.
Bedöma skada
Skademodellering är en metod som syftar till att förutse potentiella skador, upptäcka brister i en produkt som kan utgöra risker för individer och utveckla proaktiva strategier för att minska sådana risker.
Till verktyg som utformats för att bedöma teknikens inverkan, särskilt AI-system, skulle ha flera viktiga komponenter baserade på principerna för skademodellering enligt beskrivningen i de tillhandahållna resurserna.
Viktiga funktioner i ett verktyg för utvärdering av skador kan vara:
Identifiering av intressenter: Verktyget skulle hjälpa användare att identifiera och kategorisera olika intressenter som påverkas av tekniken, inklusive direkta användare, indirekt berörda parter och andra enheter som framtida generationer eller icke-mänskliga faktorer som miljöfrågor (.
Skadekategorier och beskrivningar: Den skulle innehålla en omfattande lista över potentiella skador, till exempel förlust av integritet, känslomässigt lidande eller ekonomiskt utnyttjande. Verktyget kan vägleda användaren genom olika scenarier som illustrerar hur tekniken kan orsaka dessa skador, vilket hjälper till att utvärdera både avsedda och oavsiktliga konsekvenser.
Allvarlighetsgrad och sannolikhetsbedömningar: Verktyget gör det möjligt för användare att bedöma allvarlighetsgraden och sannolikheten för varje identifierad skada, så att de kan prioritera vilka problem som ska åtgärdas först. Detta kan omfatta kvalitativa utvärderingar och kan stödjas av data där det är tillgängligt.
Riskreduceringsstrategier: När du identifierar och utvärderar skador föreslår verktyget potentiella riskreduceringsstrategier. Detta kan omfatta ändringar i systemdesignen, fler skyddsåtgärder eller alternativa tekniska lösningar som minimerar identifierade risker.
Feedbackmekanismer: Verktyget bör innehålla mekanismer för att samla in feedback från intressenter, vilket säkerställer att skadeutvärderingsprocessen är dynamisk och lyhörd för ny information och perspektiv.
Dokumentation och rapportering: För att underlätta öppenhet och ansvarsskyldighet skulle verktyget underlätta skapandet av detaljerade rapporter som dokumenterar skadebedömningsprocessen, resultaten och åtgärder som vidtagits för att minska potentiella risker.
Dessa funktioner skulle inte bara hjälpa till att identifiera och minska risker, utan också bidra till att utforma mer etiska och ansvarsfulla AI-system genom att överväga ett brett spektrum av effekter redan från början.
Mer information finns i:
Testa och verifiera skyddsåtgärderna
I den här artikeln beskrivs flera processer som syftar till att minska risken för att det RAG-baserade chattsystemet kan utnyttjas eller komprometteras. Red-teaming spelar en avgörande roll för att säkerställa att minskningarna är effektiva. Red-teaming innebär att simulera en angripares åtgärder som syftar till programmet för att upptäcka potentiella svagheter eller sårbarheter. Detta tillvägagångssätt är särskilt viktigt för att ta itu med den betydande risken för jailbreaking.
För att effektivt testa och verifiera skyddet för ett RAG-baserat chattsystem måste utvecklarna noggrant utvärdera dessa system i olika scenarier där dessa riktlinjer kan testas. Detta garanterar inte bara robusthet utan hjälper också till att finjustera systemets svar för att strikt följa definierade etiska standarder och operativa förfaranden.
Slutliga överväganden som kan påverka dina beslut om programdesign
Här är en kort lista över saker att tänka på och andra lärdomar från den här artikeln som påverkar dina beslut om programdesign:
- Bekräfta den icke-deterministiska karaktären hos generativ AI i din design, planera för variabilitet i utdata och konfigurera mekanismer för att säkerställa konsekvens och relevans i svar.
- Utvärdera fördelarna med förbearbetning av användarfrågor mot den potentiella ökningen av svarstider och kostnader. Om du förenklar eller ändrar frågor innan du skickas kan svarskvaliteten förbättras, men det kan ge svarscykeln komplexitet och tid.
- Undersök strategier för parallellisering av LLM-begäranden för att förbättra prestanda. Den här metoden kan minska svarstiden men kräver noggrann hantering för att undvika ökad komplexitet och potentiella kostnadskonsekvenser.
Om du vill börja experimentera med att skapa en generativ AI-lösning omedelbart rekommenderar vi att du tar en titt på Kom igång med chatten med ditt eget dataexempel för Python. Det finns även versioner av självstudien i .NET, Java och JavaScript.