Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Använd vektorsökning i Azure DocumentDB med Python-klientbiblioteket. Lagra och fråga vektordata effektivt.
Denna introduktion använder ett exempel på en hotell-datasamling i en JSON-fil med förberäknade vektorer från modellen. Datamängden innehåller hotellnamn, platser, beskrivningar och vektorinbäddningar.
Hitta exempelkoden på GitHub.
Prerequisites
En prenumeration på Azure
- Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto
Ett befintligt Azure DocumentDB-kluster
Om du inte har något kluster skapar du ett nytt kluster
Brandvägg konfigurerad för att tillåta åtkomst till klientens IP-adress
-
Anpassad domän konfigurerad
text-embedding-3-smallmodell implementerad
Använd Bash-miljön i Azure Cloud Shell. Mer information finns i Kom igång med Azure Cloud Shell.

Om du föredrar att köra CLI-referenskommandon lokalt installerar du Azure CLI. Om du kör på Windows eller macOS, överväg att köra Azure CLI i en Docker-container. För mer information, se Hur man kör Azure CLI i en Docker-container.
Om du använder en lokal installation loggar du in på Azure CLI med hjälp av kommandot az login. För att avsluta autentiseringsprocessen, följ stegen som visas i din terminal. Andra inloggningsalternativ finns i Autentisera till Azure med Azure CLI.
När du blir uppmanad, installera Azure CLI-tillägget vid första användning. Mer information om tillägg finns i Använda och hantera tillägg med Azure CLI.
Kör az version för att ta reda på versionen och de beroende bibliotek som är installerade. Om du vill uppgradera till den senaste versionen kör du az upgrade.
- Python 3.9 eller senare
Skapa datafil med vektorer
Skapa en ny datakatalog för hotelldatafilen:
mkdir dataHotels_Vector.jsonKopiera rådatafilen med vektorer till dindatakatalog.
Skapa ett Python-projekt
Skapa en ny katalog för projektet och öppna den i Visual Studio Code:
mkdir vector-search-quickstart code vector-search-quickstartSkapa och aktivera en virtuell miljö i terminalen:
För Windows:
python -m venv venv venv\\Scripts\\activateFör macOS/Linux:
python -m venv venv source venv/bin/activateInstallera de paket som krävs:
pip install pymongo azure-identity openai python-dotenv-
pymongo: MongoDB-drivrutin för Python -
azure-identity: Azure Identity-bibliotek för lösenordslös autentisering -
openai: OpenAI-klientbibliotek för att skapa vektorer -
python-dotenv: Miljövariabelhantering från .env-filer
-
Skapa en
.envfil för miljövariabler ivector-search-quickstart:# Identity for local developer authentication with Azure CLI AZURE_TOKEN_CREDENTIALS=AzureCliCredential # Azure OpenAI configuration AZURE_OPENAI_EMBEDDING_ENDPOINT= AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small AZURE_OPENAI_EMBEDDING_API_VERSION=2023-05-15 # Azure DocumentDB configuration MONGO_CLUSTER_NAME= # Data Configuration (defaults should work) DATA_FILE_WITH_VECTORS=../data/Hotels_Vector.json EMBEDDED_FIELD=DescriptionVector EMBEDDING_DIMENSIONS=1536 EMBEDDING_SIZE_BATCH=16 LOAD_SIZE_BATCH=50För lösenordslös autentisering som används i den här artikeln ersätter du platshållarvärdena
.envi filen med din egen information:-
AZURE_OPENAI_EMBEDDING_ENDPOINT: Url för Din Azure OpenAI-resursslutpunkt -
MONGO_CLUSTER_NAME: Ditt Azure DocumentDB-resursnamn
Du bör alltid föredra lösenordslös autentisering, men det kräver ytterligare konfiguration. Mer information om hur du konfigurerar hanterad identitet och alla dina autentiseringsalternativ finns i Autentisera Python-appar till Azure-tjänster med hjälp av Azure SDKs för Python.
-
Skapa kodfiler för vektorsökning
Fortsätt projektet genom att skapa kodfiler för vektorsökning. När du är klar bör projektstrukturen se ut så här:
├── data/
│ ├── Hotels.json # Source hotel data (without vectors)
│ └── Hotels_Vector.json # Hotel data with vector embeddings
└── vector-search-quickstart/
├── src/
│ ├── diskann.py # DiskANN vector search implementation
│ ├── hnsw.py # HNSW vector search implementation
│ ├── ivf.py # IVF vector search implementation
│ └── utils.py # Shared utility functions
├── requirements.txt # Python dependencies
├── .env # Environment variables template
Skapa en src katalog för dina Python-filer. Lägg till två filer: diskann.py och utils.py för DiskANN-indeximplementeringen:
mkdir src
touch src/diskann.py
touch src/utils.py
Skapa kod för vektorsökning
Klistra in följande kod i diskann.py filen.
import os
from typing import List, Dict, Any
from utils import get_clients, get_clients_passwordless, read_file_return_json, insert_data, print_search_results, drop_vector_indexes
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
def create_diskann_vector_index(collection, vector_field: str, dimensions: int) -> None:
print(f"Creating DiskANN vector index on field '{vector_field}'...")
# Drop any existing vector indexes on this field first
drop_vector_indexes(collection, vector_field)
# Use the native MongoDB command for DocumentDB vector indexes
index_command = {
"createIndexes": collection.name,
"indexes": [
{
"name": f"diskann_index_{vector_field}",
"key": {
vector_field: "cosmosSearch" # DocumentDB vector search index type
},
"cosmosSearchOptions": {
# DiskANN algorithm configuration
"kind": "vector-diskann",
# Vector dimensions must match the embedding model
"dimensions": dimensions,
# Vector similarity metric - cosine is good for text embeddings
"similarity": "COS",
# Maximum degree: number of edges per node in the graph
# Higher values improve accuracy but increase memory usage
"maxDegree": 20,
# Build parameter: candidates evaluated during index construction
# Higher values improve index quality but increase build time
"lBuild": 10
}
}
]
}
try:
# Execute the createIndexes command directly
result = collection.database.command(index_command)
print("DiskANN vector index created successfully")
except Exception as e:
print(f"Error creating DiskANN vector index: {e}")
# Check if it's a tier limitation and suggest alternatives
if "not enabled for this cluster tier" in str(e):
print("\nDiskANN indexes require a higher cluster tier.")
print("Try one of these alternatives:")
print(" • Upgrade your DocumentDB cluster to a higher tier")
print(" • Use HNSW instead: python src/hnsw.py")
print(" • Use IVF instead: python src/ivf.py")
raise
def perform_diskann_vector_search(collection,
azure_openai_client,
query_text: str,
vector_field: str,
model_name: str,
top_k: int = 5) -> List[Dict[str, Any]]:
print(f"Performing DiskANN vector search for: '{query_text}'")
try:
# Generate embedding for the query text
embedding_response = azure_openai_client.embeddings.create(
input=[query_text],
model=model_name
)
query_embedding = embedding_response.data[0].embedding
# Construct the aggregation pipeline for vector search
# DocumentDB uses $search with cosmosSearch
pipeline = [
{
"$search": {
# Use cosmosSearch for vector operations in DocumentDB
"cosmosSearch": {
# The query vector to search for
"vector": query_embedding,
# Field containing the document vectors to compare against
"path": vector_field,
# Number of final results to return
"k": top_k
}
}
},
{
# Add similarity score to the results
"$project": {
"document": "$$ROOT",
# Add search score from metadata
"score": {"$meta": "searchScore"}
}
}
]
# Execute the aggregation pipeline
results = list(collection.aggregate(pipeline))
return results
except Exception as e:
print(f"Error performing DiskANN vector search: {e}")
raise
def main():
# Load configuration from environment variables
config = {
'cluster_name': os.getenv('MONGO_CLUSTER_NAME'),
'database_name': 'Hotels',
'collection_name': 'hotels_diskann',
'data_file': os.getenv('DATA_FILE_WITH_VECTORS', '../data/Hotels_Vector.json'),
'vector_field': os.getenv('EMBEDDED_FIELD', 'DescriptionVector'),
'model_name': os.getenv('AZURE_OPENAI_EMBEDDING_MODEL', 'text-embedding-3-small'),
'dimensions': int(os.getenv('EMBEDDING_DIMENSIONS', '1536')),
'batch_size': int(os.getenv('LOAD_SIZE_BATCH', '100'))
}
try:
# Initialize clients
print("\nInitializing MongoDB and Azure OpenAI clients...")
mongo_client, azure_openai_client = get_clients_passwordless()
# Get database and collection
database = mongo_client[config['database_name']]
collection = database[config['collection_name']]
# Load data with embeddings
print(f"\nLoading data from {config['data_file']}...")
data = read_file_return_json(config['data_file'])
print(f"Loaded {len(data)} documents")
# Verify embeddings are present
documents_with_embeddings = [doc for doc in data if config['vector_field'] in doc]
if not documents_with_embeddings:
raise ValueError(f"No documents found with embeddings in field '{config['vector_field']}'. "
"Please run create_embeddings.py first.")
# Insert data into collection
print(f"\nInserting data into collection '{config['collection_name']}'...")
# Insert the hotel data
stats = insert_data(
collection,
documents_with_embeddings,
batch_size=config['batch_size']
)
if stats['inserted'] == 0 and not stats.get('skipped'):
raise ValueError("No documents were inserted successfully")
# Create DiskANN vector index (skip if data was already present)
if not stats.get('skipped'):
create_diskann_vector_index(
collection,
config['vector_field'],
config['dimensions']
)
# Wait briefly for index to be ready
import time
print("Waiting for index to be ready...")
time.sleep(2)
# Perform sample vector search
query = "quintessential lodging near running trails, eateries, retail"
results = perform_diskann_vector_search(
collection,
azure_openai_client,
query,
config['vector_field'],
config['model_name'],
top_k=5
)
# Display results
print_search_results(results, max_results=5, show_score=True)
except Exception as e:
print(f"\nError during DiskANN demonstration: {e}")
raise
finally:
# Close the MongoDB client
if 'mongo_client' in locals():
mongo_client.close()
if __name__ == "__main__":
main()
Den här huvudmodulen innehåller följande funktioner:
Innehåller verktygsfunktioner
Skapar ett konfigurationsobjekt för miljövariabler
Skapar klienter för Azure OpenAI och Azure DocumentDB
Ansluter till MongoDB, skapar en databas och samling, infogar data och skapar standardindex
Skapar ett vektorindex med IVF, HNSW eller DiskANN
Skapar en inbäddning för en exempelfrågetext med hjälp av OpenAI-klienten. Du kan ändra frågan överst i filen
Kör en vektorsökning med inbäddningen och skriver ut resultatet
Skapa verktygsfunktioner
Klistra in följande kod i utils.py:
import json
import os
import time
import warnings
from typing import Dict, List, Any, Optional, Tuple
# Suppress the PyMongo CosmosDB cluster detection warning
# Must be set before importing pymongo
warnings.filterwarnings(
"ignore",
message="You appear to be connected to a CosmosDB cluster.*",
)
from pymongo import MongoClient, InsertOne
from pymongo.collection import Collection
from pymongo.errors import BulkWriteError
from azure.identity import DefaultAzureCredential
from pymongo.auth_oidc import OIDCCallback, OIDCCallbackContext, OIDCCallbackResult
from openai import AzureOpenAI
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
class AzureIdentityTokenCallback(OIDCCallback):
def __init__(self, credential):
self.credential = credential
def fetch(self, context: OIDCCallbackContext) -> OIDCCallbackResult:
token = self.credential.get_token(
"https://ossrdbms-aad.database.windows.net/.default").token
return OIDCCallbackResult(access_token=token)
def get_clients() -> Tuple[MongoClient, AzureOpenAI]:
# Get MongoDB connection string - required for DocumentDB access
mongo_connection_string = os.getenv("MONGO_CONNECTION_STRING")
if not mongo_connection_string:
raise ValueError("MONGO_CONNECTION_STRING environment variable is required")
# Create MongoDB client with optimized settings for DocumentDB
mongo_client = MongoClient(
mongo_connection_string,
maxPoolSize=50, # Allow up to 50 connections for better performance
minPoolSize=5, # Keep minimum 5 connections open
maxIdleTimeMS=30000, # Close idle connections after 30 seconds
serverSelectionTimeoutMS=5000, # 5 second timeout for server selection
socketTimeoutMS=20000 # 20 second socket timeout
)
# Get Azure OpenAI configuration
azure_openai_endpoint = os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT")
azure_openai_key = os.getenv("AZURE_OPENAI_EMBEDDING_KEY")
if not azure_openai_endpoint or not azure_openai_key:
raise ValueError("Azure OpenAI endpoint and key are required")
# Create Azure OpenAI client for generating embeddings
azure_openai_client = AzureOpenAI(
azure_endpoint=azure_openai_endpoint,
api_key=azure_openai_key,
api_version=os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION", "2023-05-15")
)
return mongo_client, azure_openai_client
def get_clients_passwordless() -> Tuple[MongoClient, AzureOpenAI]:
# Get MongoDB cluster name for passwordless authentication
cluster_name = os.getenv("MONGO_CLUSTER_NAME")
if not cluster_name:
raise ValueError("MONGO_CLUSTER_NAME environment variable is required")
# Create credential object for Azure authentication
credential = DefaultAzureCredential()
authProperties = {"OIDC_CALLBACK": AzureIdentityTokenCallback(credential)}
# Create MongoDB client with Azure AD token callback
mongo_client = MongoClient(
f"mongodb+srv://{cluster_name}.global.mongocluster.cosmos.azure.com/",
connectTimeoutMS=120000,
tls=True,
retryWrites=True,
authMechanism="MONGODB-OIDC",
authMechanismProperties=authProperties
)
# Get Azure OpenAI endpoint
azure_openai_endpoint = os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT")
if not azure_openai_endpoint:
raise ValueError("AZURE_OPENAI_EMBEDDING_ENDPOINT environment variable is required")
# Create Azure OpenAI client with credential-based authentication
azure_openai_client = AzureOpenAI(
azure_endpoint=azure_openai_endpoint,
azure_ad_token_provider=lambda: credential.get_token("https://cognitiveservices.azure.com/.default").token,
api_version=os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION", "2023-05-15")
)
return mongo_client, azure_openai_client
def azure_identity_token_callback(credential: DefaultAzureCredential) -> str:
# DocumentDB requires this specific scope
token_scope = "https://cosmos.azure.com/.default"
# Get token from Azure AD
token = credential.get_token(token_scope)
return token.token
def read_file_return_json(file_path: str) -> List[Dict[str, Any]]:
try:
with open(file_path, 'r', encoding='utf-8') as file:
return json.load(file)
except FileNotFoundError:
print(f"Error: File '{file_path}' not found")
raise
except json.JSONDecodeError as e:
print(f"Error: Invalid JSON in file '{file_path}': {e}")
raise
def write_file_json(data: List[Dict[str, Any]], file_path: str) -> None:
try:
with open(file_path, 'w', encoding='utf-8') as file:
json.dump(data, file, indent=2, ensure_ascii=False)
print(f"Data successfully written to '{file_path}'")
except IOError as e:
print(f"Error writing to file '{file_path}': {e}")
raise
def insert_data(collection: Collection, data: List[Dict[str, Any]],
batch_size: int = 100, index_fields: Optional[List[str]] = None) -> Dict[str, int]:
total_documents = len(data)
# Check if data already exists in the collection
existing_count = collection.count_documents({})
if existing_count >= total_documents:
print(f"Collection already has {existing_count} documents, skipping insert and index creation")
return {'total': total_documents, 'inserted': 0, 'failed': 0, 'skipped': True}
# Clear existing data if counts don't match to ensure clean state
if existing_count > 0:
print(f"Collection has {existing_count} documents but expected {total_documents}, clearing and re-inserting...")
collection.delete_many({})
inserted_count = 0
failed_count = 0
print(f"Starting batch insertion of {total_documents} documents...")
# Create indexes if specified
if index_fields:
for field in index_fields:
try:
collection.create_index(field)
print(f"Created index on field: {field}")
except Exception as e:
print(f"Warning: Could not create index on {field}: {e}")
# Process data in batches to manage memory and error recovery
for i in range(0, total_documents, batch_size):
batch = data[i:i + batch_size]
batch_num = (i // batch_size) + 1
total_batches = (total_documents + batch_size - 1) // batch_size
try:
# Prepare bulk insert operations
operations = [InsertOne(document) for document in batch]
# Execute bulk insert
result = collection.bulk_write(operations, ordered=False)
inserted_count += result.inserted_count
print(f"Batch {batch_num} completed: {result.inserted_count} documents inserted")
except BulkWriteError as e:
# Handle partial failures in bulk operations
inserted_count += e.details.get('nInserted', 0)
failed_count += len(batch) - e.details.get('nInserted', 0)
print(f"Batch {batch_num} had errors: {e.details.get('nInserted', 0)} inserted, "
f"{failed_count} failed")
# Print specific error details for debugging
for error in e.details.get('writeErrors', []):
print(f" Error: {error.get('errmsg', 'Unknown error')}")
except Exception as e:
# Handle unexpected errors
failed_count += len(batch)
print(f"Batch {batch_num} failed completely: {e}")
# Small delay between batches to avoid overwhelming the database
time.sleep(0.1)
# Return summary statistics
stats = {
'total': total_documents,
'inserted': inserted_count,
'failed': failed_count
}
return stats
def drop_vector_indexes(collection, vector_field: str) -> None:
try:
# Get all indexes for the collection
indexes = list(collection.list_indexes())
# Find vector indexes on the specified field
vector_indexes = []
for index in indexes:
if 'key' in index and vector_field in index['key']:
if index['key'][vector_field] == 'cosmosSearch':
vector_indexes.append(index['name'])
# Drop each vector index found
for index_name in vector_indexes:
print(f"Dropping existing vector index: {index_name}")
collection.drop_index(index_name)
if vector_indexes:
print(f"Dropped {len(vector_indexes)} existing vector index(es)")
else:
print("No existing vector indexes found to drop")
except Exception as e:
print(f"Warning: Could not drop existing vector indexes: {e}")
# Continue anyway - the error might be that no indexes exist
def print_search_resultsx(results: List[Dict[str, Any]],
max_results: int = 5,
show_score: bool = True) -> None:
if not results:
print("No search results found.")
return
print(f"\nSearch Results (showing top {min(len(results), max_results)}):")
print("=" * 80)
for i, result in enumerate(results[:max_results], 1):
# Display hotel name and ID
print(f"HotelName: {result['HotelName']}, Score: {result['score']:.4f}")
def print_search_results(results: List[Dict[str, Any]],
max_results: int = 5,
show_score: bool = True) -> None:
if not results:
print("No search results found.")
return
print(f"\nSearch Results (showing top {min(len(results), max_results)}):")
print("=" * 80)
for i, result in enumerate(results[:max_results], 1):
# Check if results are nested under 'document' (when using $$ROOT)
if 'document' in result:
doc = result['document']
else:
doc = result
# Display hotel name and ID
print(f"HotelName: {doc['HotelName']}, Score: {result['score']:.4f}")
if len(results) > max_results:
print(f"\n... and {len(results) - max_results} more results")
Den här verktygsmodulen innehåller följande funktioner:
-
get_clients: Skapar och returnerar klienter för Azure OpenAI och Azure DocumentDB -
get_clients_passwordless: Skapar och returnerar klienter för Azure OpenAI och Azure DocumentDB med lösenordslös autentisering -
azure_identity_token_callback: Hämtar en Azure AD-token som används av MongoDB OIDC-autentisering -
read_file_return_json: Läser en JSON-fil och returnerar dess innehåll som en matris med objekt -
write_file_json: Skriver en matris med objekt till en JSON-fil -
insert_data: Infogar data i batchar i en MongoDB-samling och skapar standardindex för angivna fält -
drop_vector_indexes: Släpper befintliga vektorindex i målvektorfältet -
print_search_results: Skriver ut vektorsökresultat, inklusive poäng och hotellnamn
Autentisera med Azure CLI
Logga in på Azure CLI innan du kör programmet så att det kan komma åt Azure-resurser på ett säkert sätt.
az login
Koden använder din lokala utvecklarautentisering för att få åtkomst till Azure DocumentDB och Azure OpenAI. När du anger AZURE_TOKEN_CREDENTIALS=AzureCliCredentialanger den här inställningen att funktionen ska använda Azure CLI-autentiseringsuppgifter för autentisering deterministiskt. Autentiseringen förlitar sig på DefaultAzureCredential från azure-identity för att hitta dina Azure-autentiseringsuppgifter i miljön. Läs mer om hur du autentiserar Python-appar till Azure-tjänster med hjälp av Azure Identity-biblioteket.
Starta programmet
Så här kör du Python-skripten:
Du ser de fem bästa hotellen som matchar vektorsökningsfrågan och deras likhetspoäng.
Visa och hantera data i Visual Studio Code
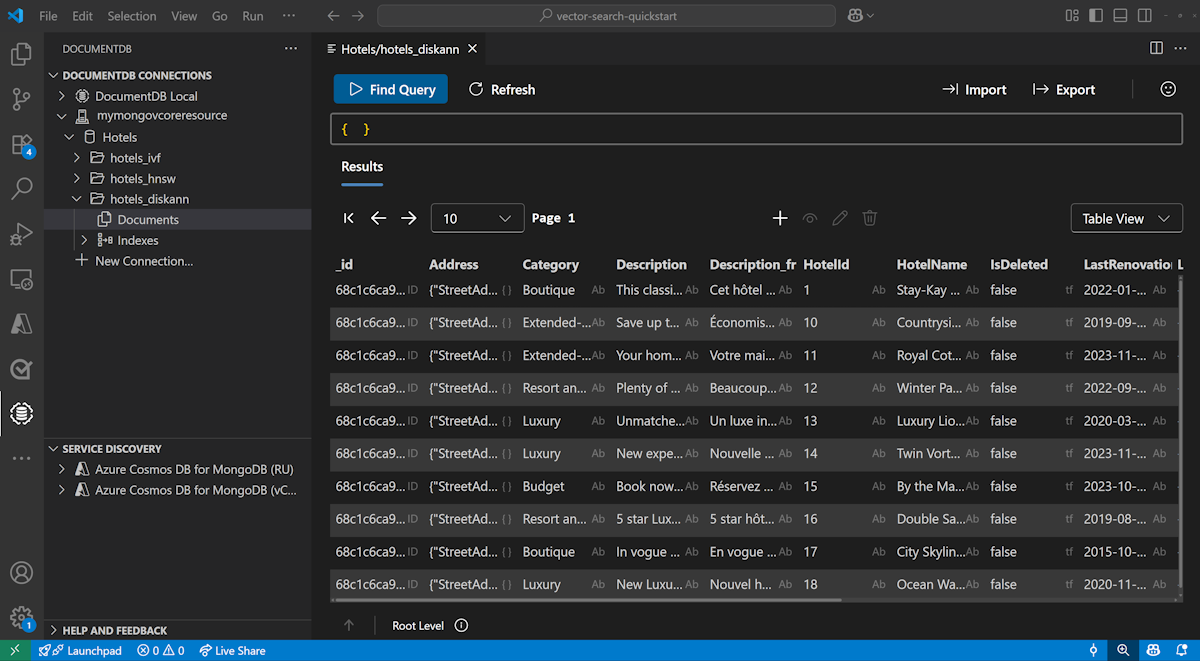
Välj DocumentDB-tillägget i Visual Studio Code för att ansluta till ditt Azure DocumentDB-konto.
Visa data och index i databasen Hotell.

Rensa resurser
Ta bort resursgruppen, Azure DocumentDB-kontot och Azure OpenAI-resursen när du inte behöver dem för att undvika extra kostnader.