Skriva händelsemeddelanden till Azure Data Lake Storage Gen2 med Apache Flink® DataStream API
Viktigt!
Den här funktionen finns i förhandsgranskning. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller på annat sätt ännu inte har släppts i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS-förhandsversionsinformation. Om du vill ha frågor eller funktionsförslag skickar du en begäran på AskHDInsight med informationen och följer oss för fler uppdateringar i Azure HDInsight Community.
Apache Flink använder filsystem för att använda och beständigt lagra data, både för programresultat och för feltolerans och återställning. I den här artikeln får du lära dig hur du skriver händelsemeddelanden till Azure Data Lake Storage Gen2 med DataStream API.
Förutsättningar
- Apache Flink-kluster i HDInsight på AKS
- Apache Kafka-kluster på HDInsight
- Du måste se till att nätverksinställningarna är noga enligt beskrivningen i Använda Apache Kafka i HDInsight. Kontrollera att HDInsight i AKS- och HDInsight-kluster finns i samma virtuella nätverk.
- Använda MSI för att komma åt ADLS Gen2
- IntelliJ för utveckling på en virtuell Azure-dator i HDInsight i AKS Virtual Network
Apache Flink FileSystem-anslutningsprogram
Den här filsystemanslutningsappen ger samma garantier för både BATCH och STREAMING och är utformad för att tillhandahålla exakt en gång semantik för STREAMING-körning. Mer information finns i Flink DataStream Filesystem.
Apache Kafka Anslut or
Flink tillhandahåller en Apache Kafka-anslutning för att läsa data från och skriva data till Kafka-ämnen med exakt en gång garantier. Mer information finns i Apache Kafka Anslut or.
Skapa projektet för Apache Flink
pom.xml på IntelliJ IDEA
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Program för ADLS Gen2-mottagare
abfsGen2.java
Kommentar
Ersätt Apache Kafka på HDInsight-klusterstartErtrapServers med dina egna mäklare för Kafka 3.2
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
Paketburk och skicka till Apache Flink.
Ladda upp jar-filen till ABFS.
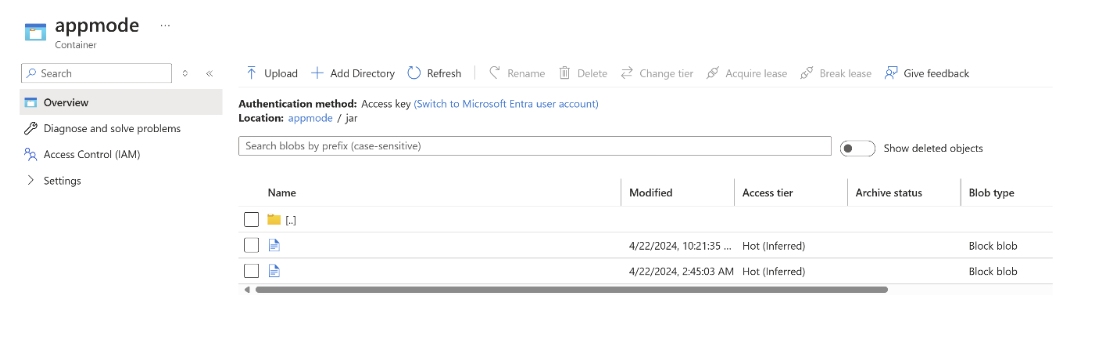
Skicka information om jobbburken när
AppModeklustret skapas.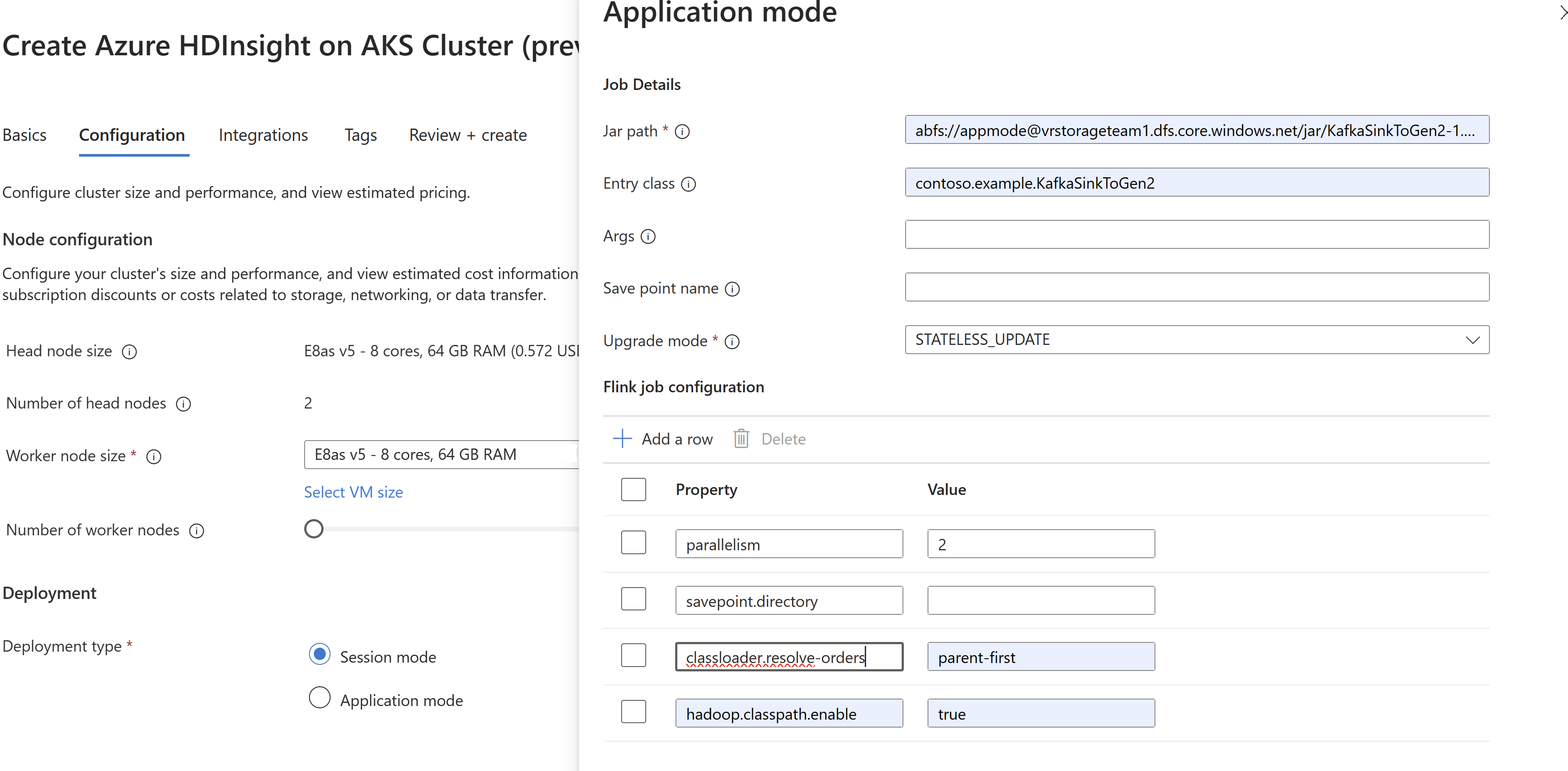
Kommentar
Se till att lägga till classloader.resolve-order som "parent-first" och hadoop.classpath.enable som
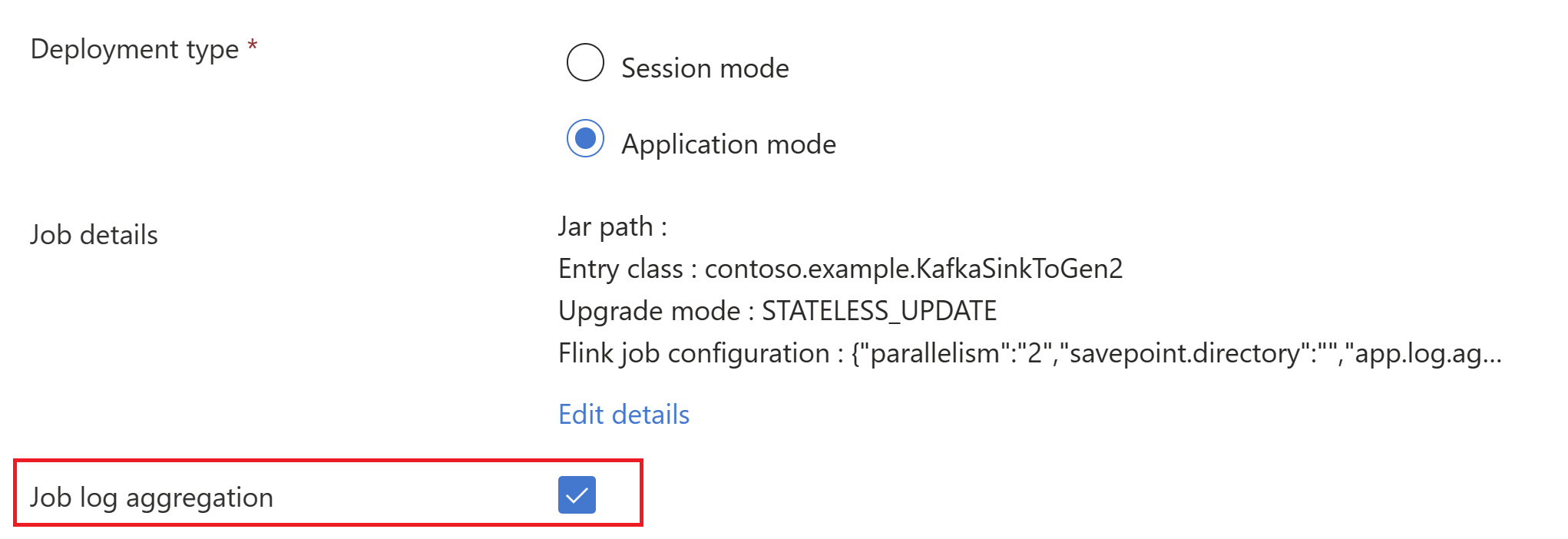
trueVälj Aggregering av jobblogg för att skicka jobbloggar till lagringskontot.
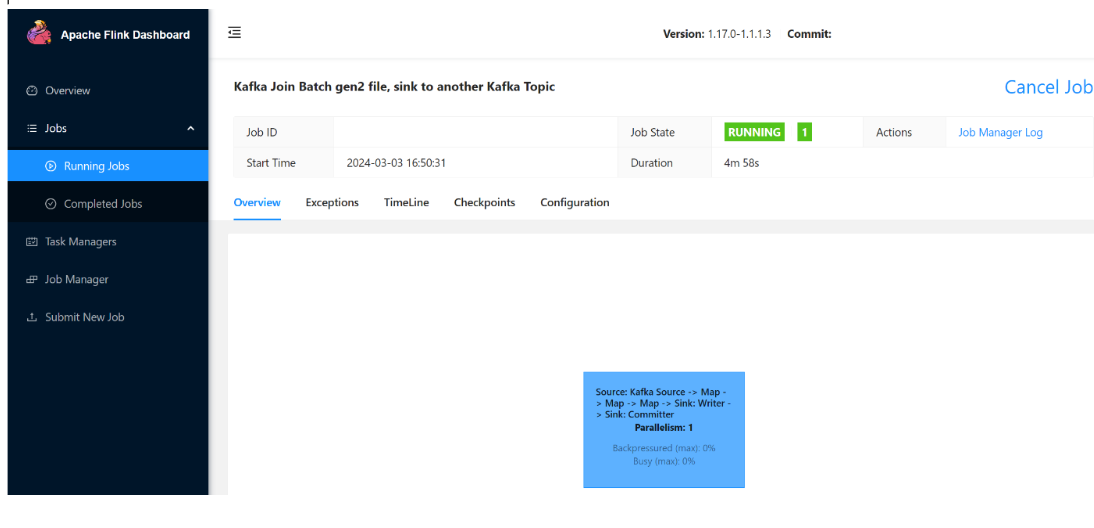
Du kan se att jobbet körs.




Verifiera strömmande data på ADLS Gen2
Vi ser strömningen click_events till ADLS Gen2.

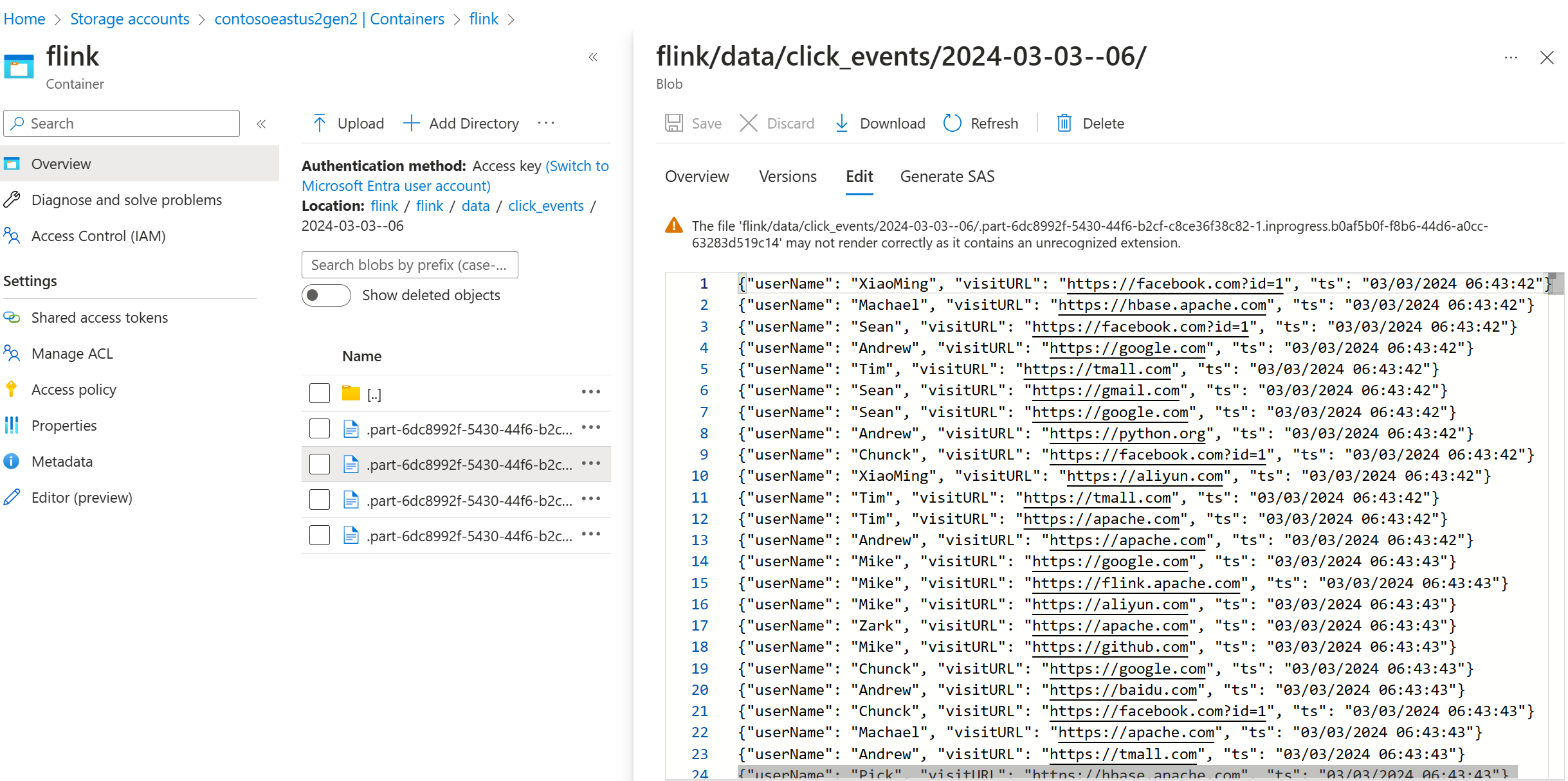
Du kan ange en löpande princip som rullar den pågående delfilen på något av följande tre villkor:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
Referens
- Apache Kafka Anslut or
- Flink DataStream-filsystem
- Apache Flink-webbplats
- Apache, Apache Kafka, Kafka, Apache Flink, Flink och associerade öppen källkod projektnamn är varumärkensom tillhör Apache Software Foundation (ASF).