Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Apache Kafka är en distribuerad strömningsplattform med öppen källkod. Den används ofta som en asynkron meddelandekö eftersom den innehåller funktioner som påminner om en publicera-prenumerera-meddelandekö.
I den här snabbstarten får du lära dig hur du skapar ett Apache Kafka-kluster med hjälp av Azure Portal. Du kommer också lära dig hur du kan använda de inkluderade verktygen för att skicka och ta emot meddelanden med Apache Kafka. Detaljerade förklaringar av tillgängliga konfigurationer finns i Konfigurera kluster i HDInsight. Mer information om hur du använder portalen för att skapa kluster finns i Skapa kluster i portalen.
Varning
Faktureringen för HDInsight-kluster beräknas proportionellt per minut, oavsett om du använder dem eller inte. Se till att ta bort klustret när du har använt det. Se hur du tar bort ett HDInsight-kluster.
Apache Kafka-API:et kan endast användas av resurser i samma virtuella nätverk. I den här snabbstarten kommer du åt klustret direkt med hjälp av SSH. Om du vill ansluta andra tjänster, nätverk eller virtuella datorer till Apache Kafka måste du först skapa ett virtuellt nätverk och sedan skapa resurser i nätverket. Mer information finns i dokumentet Anslut till Apache Kafka via ett virtuellt nätverk. Mer allmän information om hur du planerar virtuella nätverk för HDInsight finns i Planera ett virtuellt nätverk för Azure HDInsight.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
En SSH-klient. Mer information finns i Ansluta till HDInsight (Apache Hadoop) med hjälp av SSH.
Skapa ett Apache Kafka-kluster
Använd följande steg för att skapa ett Apache Kafka-kluster i HDInsight:
Logga in på Azure-portalen.
Välj + Skapa en resurs från menyn högst upp.
Välj Analytics>Azure HDInsight för att gå till sidan Skapa HDInsight-kluster.
På fliken Grundläggande anger du följande information:
Egendom Beskrivning Prenumeration I listrutan väljer du den Azure-prenumeration som används för klustret. Resursgrupp Skapa en resursgrupp eller välj en befintlig resursgrupp. En resursgrupp är en container med Azure-komponenter. I det här fallet innehåller resursgruppen HDInsight-klustret och det beroende Azure Storage-kontot. Klusternamn Ange ett globalt unikt namn. Namnet kan bestå av upp till 59 tecken, inklusive bokstäver, siffror och bindestreck. De första och sista tecknen i namnet får inte vara bindestreck. Region I listrutan väljer du en region där klustret skapas. Välj en region närmare dig för bättre prestanda. Klustertyp Välj Välj klustertyp för att öppna en lista. I listan väljer du Kafka som klustertyp. Version Standardversionen för klustertypen anges. Välj i listrutan om du vill ange en annan version. Användarnamn och lösenord för klusterinloggning Standardinloggningsnamnet är admin. Lösenordet måste vara minst 10 tecken långt och måste innehålla minst en siffra, en versal och en gemen bokstav, ett icke-alfanumeriskt tecken (förutom tecken' ` "). Se till att du inte anger vanliga lösenord, till exempelPass@word1.Secure Shell (SSH)-användarnamn Standardanvändarnamnet är sshuser. Du kan ange ett annat namn som SSH-användarnamn.Använda lösenord för klusterinloggning för SSH Markera den här kryssrutan om du vill använda samma lösenord för SSH-användare som det du angav för klusterinloggningsanvändaren. 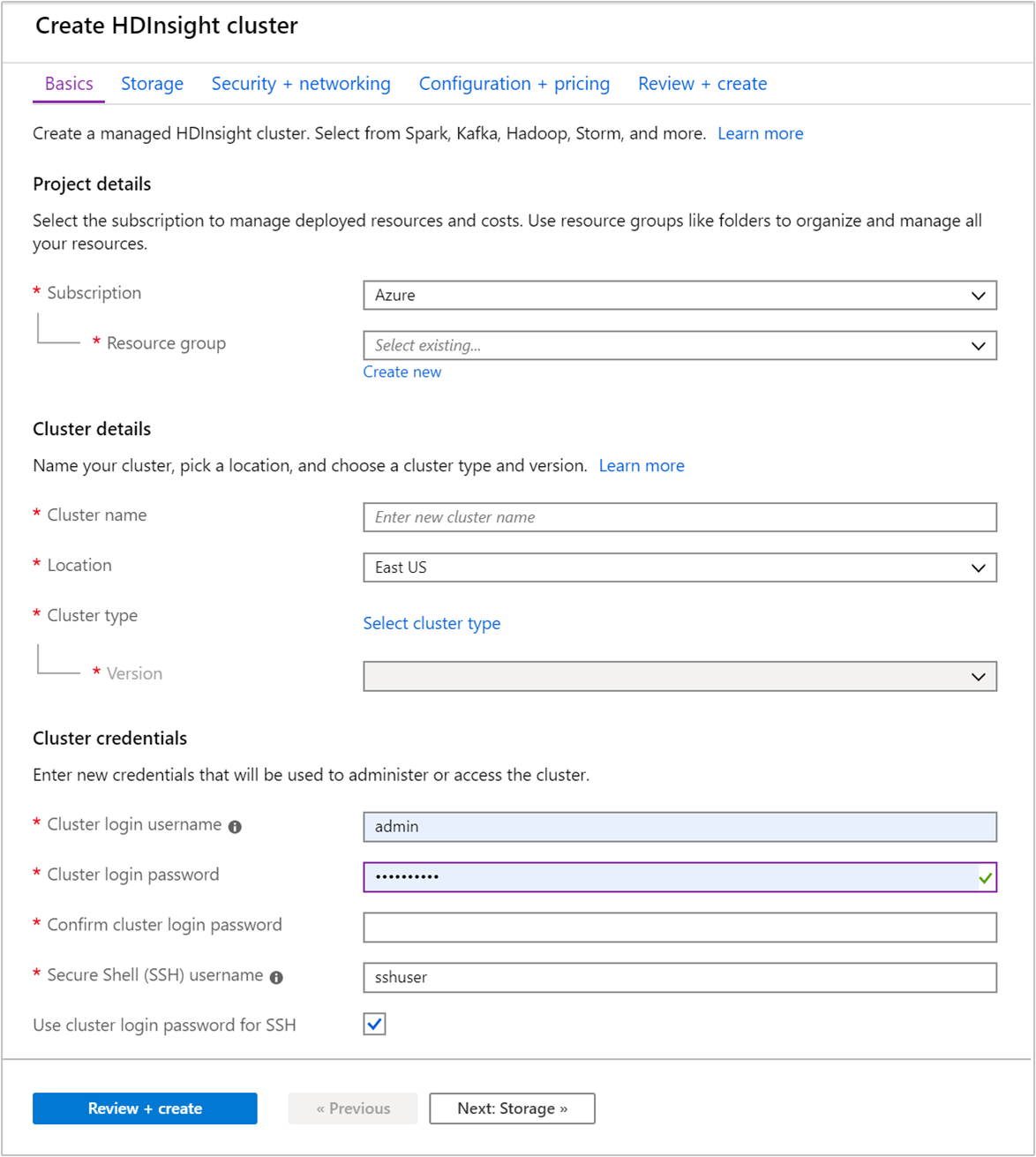
Varje Azure-region (plats) har feldomäner. En feldomän är en logisk gruppering av underliggande maskinvara i ett Azure-datacenter. Varje feldomän delar en gemensam strömkälla och nätverksbrytare. De virtuella datorer och hanterade diskar som implementerar noderna i ett HDInsight-kluster är fördelade mellan dessa feldomäner. Den här arkitekturen begränsar de potentiella problemen vid fysiska maskinvarufel.
För hög datatillgänglighet, välj en plats (region) som innehåller tre feldomäner. Om du vill ha information om antalet feldomäner i en region läser du dokumentet Availability of Linux virtual machines (Tillgänglighet för virtuella Linux-datorer).
Välj fliken Nästa: Lagring >> för att gå vidare till lagringsinställningarna.
På fliken Lagring anger du följande värden:
Egendom Beskrivning Primär lagringstyp Använd standardvärdet Azure Storage. Urvalsmetod Använd standardvärdet Välj från lista. Primärt lagringskonto Använd listrutan för att välja ett befintligt lagringskonto eller välj Skapa nytt. Om du skapar ett nytt konto måste namnet vara mellan 3 och 24 tecken långt och får endast innehålla siffror och små bokstäver. Behållare Använd det automatiskt ifyllda värdet. 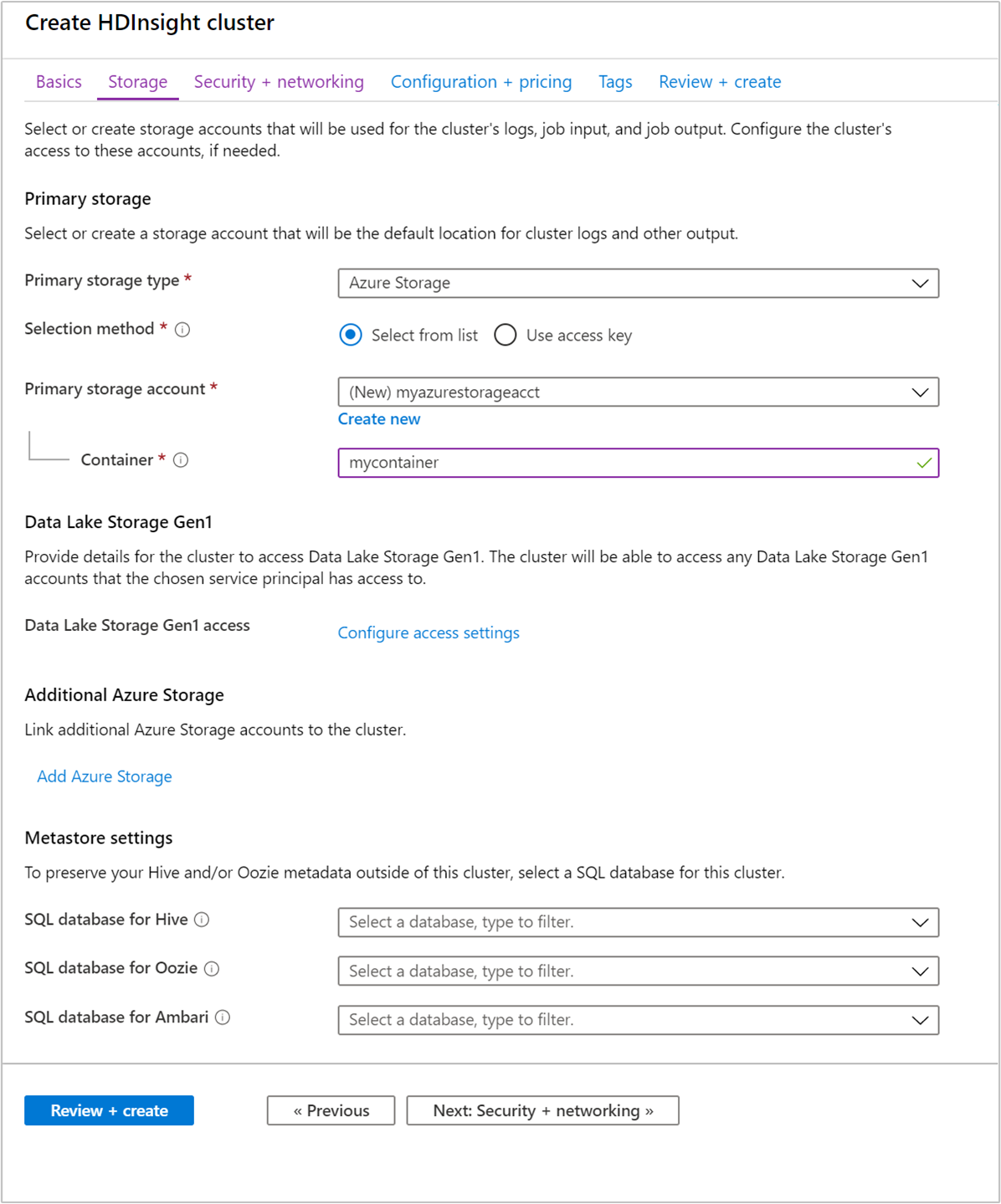
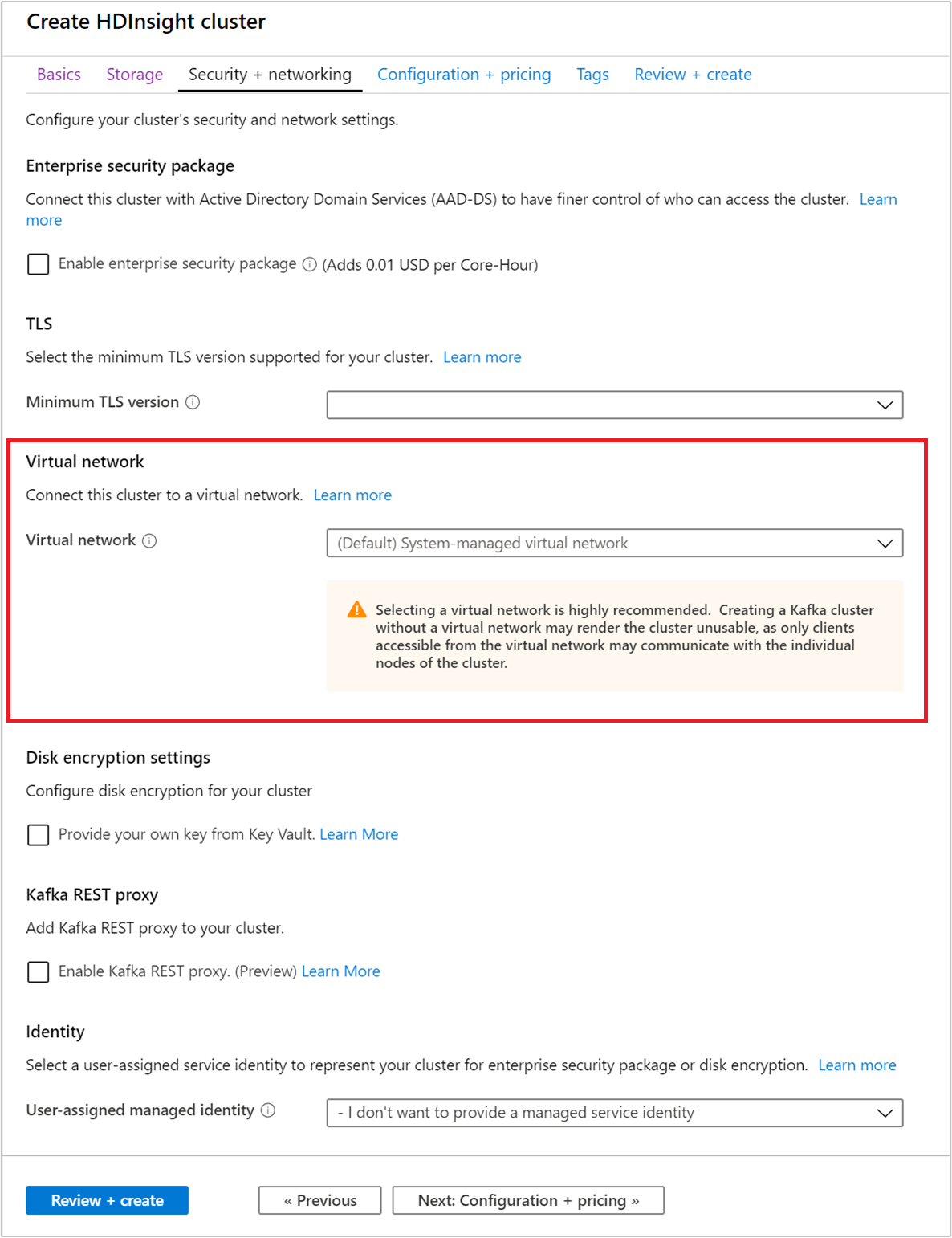
Välj fliken Säkerhet + nätverk .
För den här snabbstarten lämnar du standardsäkerhetsinställningarna. Mer information om Enterprise Security-paketet finns i Konfigurera ett HDInsight-kluster med Enterprise Security Package med hjälp av Microsoft Entra Domain Services. Information om hur du använder din egen nyckel för Apache Kafka-diskkryptering finns i Diskkryptering med kundhanterad nyckel
Om du vill ansluta ditt kluster till ett virtuellt nätverk väljer du ett virtuellt nätverk i listrutan Virtuellt nätverk.
Välj fliken Konfiguration + prissättning .
För att garantera tillgängligheten för Apache Kafka i HDInsight måste antalet noder för arbetsnodenvara inställt på 3 eller högre. Standardvärdet är 4.
Posten Standarddiskar per arbetsnod konfigurerar skalbarheten för Apache Kafka i HDInsight. Apache Kafka på HDInsight använder de virtuella datorernas lokala diskar i klustret för att lagra data. Apache Kafka är I/O-tungt, och därför används Azure Managed Disks för att tillhandahålla hög genomströmning och mer lagringsutrymme per nod. Typen av hanterade diskar kan vara antingen Standard (HDD) eller Premium (SSD). Vilken typ av disk som används beror på vilken VM-storlek arbetsnoderna (Apache Kafka-broker) använder. Premiumdiskar används automatiskt med virtuella datorer i DS- och GS-serien. Alla andra typer av virtuella dator använder standard.
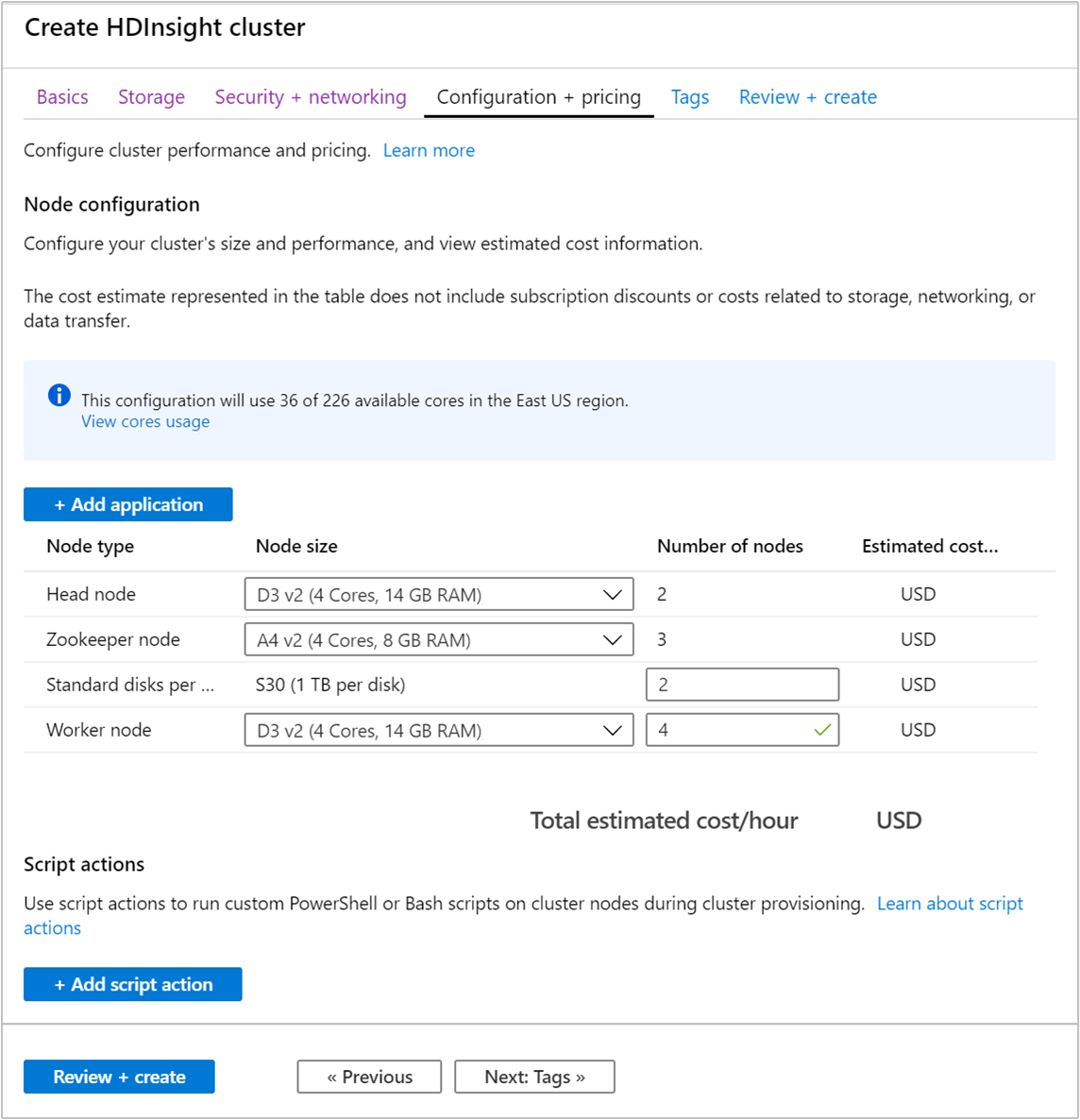
Välj fliken Granska + skapa .
Granska konfigurationen för klustret. Ändra eventuella inställningar som är felaktiga. Välj slutligen Skapa för att skapa klustret.
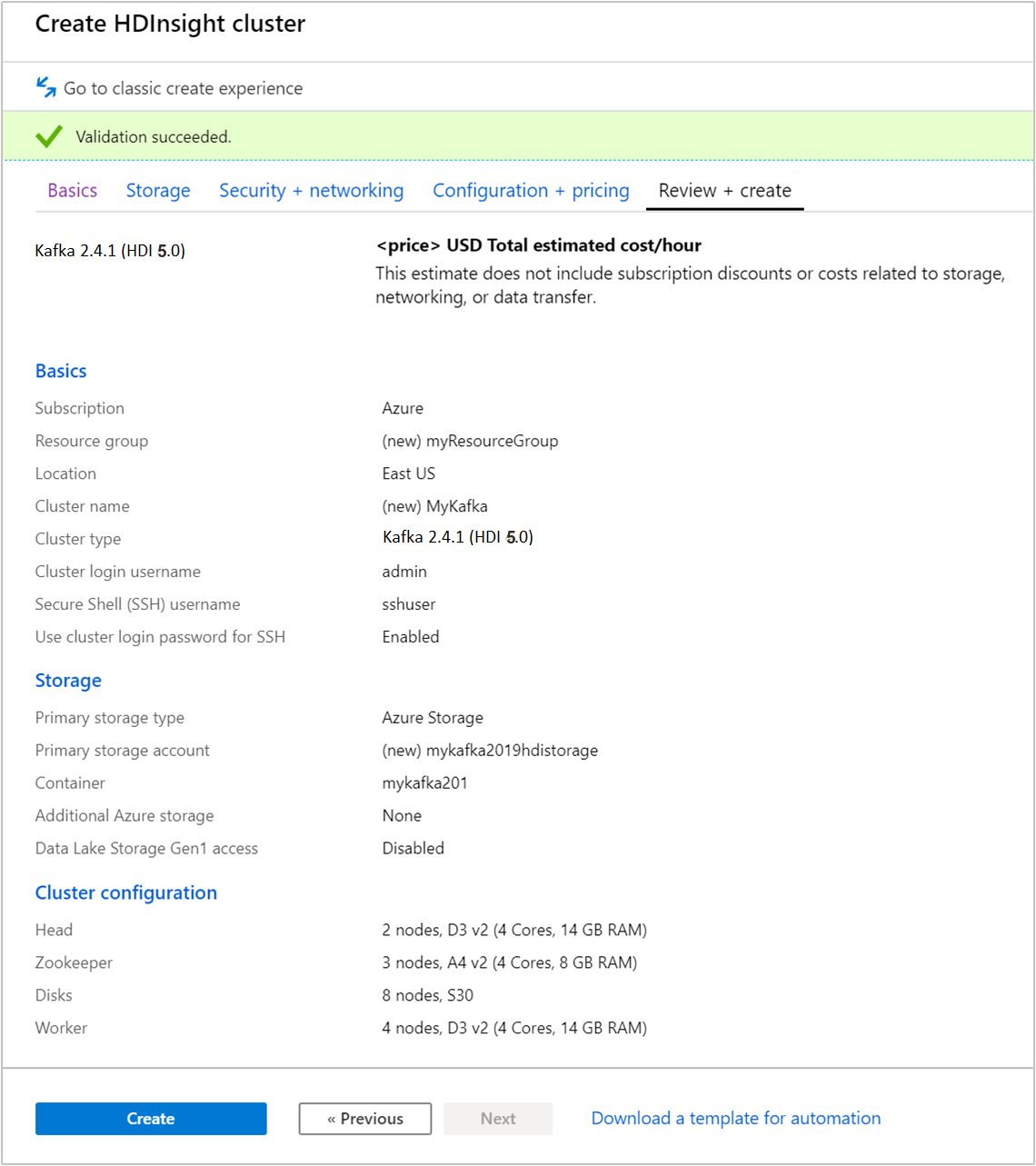
Det kan ta upp till 20 minuter att skapa klustret.
Anslut till klustret
Använd ssh-kommandot för att ansluta till klustret. Redigera kommandot nedan genom att ersätta CLUSTERNAME med namnet på klustret och ange sedan kommandot:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netAnge SSH-användarens lösenord när du uppmanas till detta.
När du är ansluten visas ett meddelande av följande slag:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Hämta värdinformation för Apache Zookeeper och Broker
När du arbetar med Kafka måste du känna till Apache Zookeeper- och Broker-värdarna. Dessa värdar används med Apache Kafka-API och många av de verktyg som levereras med Kafka.
I det här avsnittet hämtar du värdinformation från Apache Ambari REST API på klustret.
Installera jq, en JSON-processor på kommandoraden. Det här verktyget används för att parsa JSON-dokument och är användbart när du parsar värdinformationen. Från den öppna SSH-anslutningen anger du följande kommando för att installera
jq:sudo apt -y install jqKonfigurera lösenordsvariabel. Ersätt
PASSWORDmed lösenordet för klusterinloggning och ange sedan kommandot:export PASSWORD='PASSWORD'Extrahera det korrekt skiftlägesformaterade klusternamnet. Det faktiska höljet för klusternamnet kan skilja sig från förväntat, beroende på hur klustret skapades. Det här kommandot hämtar det faktiska höljet och lagrar det sedan i en variabel. Ange följande kommando:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Anteckning
Om du gör den här processen utanför klustret finns det en annan procedur för att lagra klusternamnet. Hämta klusternamnet i små bokstäver från Azure portal. Ersätt sedan klusternamnet med
<clustername>i följande kommando och kör det:export clusterName='<clustername>'.Om du vill ange en miljövariabel med Zookeeper-värdinformation använder du kommandot nedan. Kommandot hämtar alla Zookeeper-värdar för att därefter returnera endast de två första posterna. Det beror på att det är bra att ha viss redundans ifall en värd inte kan nås.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Anteckning
Det här kommandot kräver Ambari-åtkomst. Om klustret ligger bakom en NSG kör du det här kommandot från en dator som har åtkomst till Ambari.
Använd följande kommando om du vill kontrollera att miljövariabeln är korrekt:
echo $KAFKAZKHOSTSDet här kommandot returnerar information liknande följande text:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Använd följande kommando om du vill ange en miljövariabel med värdinformation för Kafka-broker:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Anteckning
Det här kommandot kräver Ambari-åtkomst. Om klustret ligger bakom en NSG kör du det här kommandot från en dator som har åtkomst till Ambari.
Använd följande kommando om du vill kontrollera att miljövariabeln är korrekt:
echo $KAFKABROKERSDet här kommandot returnerar information liknande följande text:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Hantera Apache Kafka-ämnen
Kafka lagrar dataströmmar i kategorier som kallas ämnen. Du kan hantera ämnena med verktyget kafka-topics.sh.
Du skapar ett ämne med följande kommando i SSH-anslutningen:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERSDet här kommandot ansluter till Broker med hjälp av värdinformationen som lagras i
$KAFKABROKERS. Det skapar ett Apache Kafka-ämne med namnet test.Data som lagras i det här ämnet partitioneras över åtta partitioner.
Varje partition replikeras mellan tre arbetarnoder i klustret.
Om du har skapat klustret i en Azure-region som tillhandahåller tre feldomäner så använd replikeringsfaktorn 3. I annat fall använder du replikeringsfaktorn 4.
I områden med tre feldomäner kan replikeringsfaktorn 3 tillåta att repliker sprids till feldomänerna. I områden med två feldomäner kan replikeringsfaktorn 4 tillåta att repliker sprids jämnt över domänerna.
Om du vill ha information om antalet feldomäner i en region läser du dokumentet Availability of Linux virtual machines (Tillgänglighet för virtuella Linux-datorer).
Apache Kafka har ingen information om Azure-feldomäner. När du skapar partitionsrepliker för ämnen kanske det inte distribueras repliker korrekt för hög tillgänglighet.
Garantera hög tillgänglighet med hjälp av verktyget för partitionsombalansering för Apache Kafka. Du måste köra det här verktyget från en SSH-anslutning till ditt Apache Kafka-klusters huvudnod.
Om du vill ha bästa möjliga tillgänglighet för dina Apache Kafka-data måste du balansera om ämnets partitionsrepliker när:
Du skapar ett nytt ämne eller en ny partition
Du skalar upp ett kluster
Om du vill lista ämnena använder du följande kommando:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERSDet här kommandot listar de ämnen som är tillgängliga på Apache Kafka-klustret.
Om du vill ta bort ett ämne använder du följande kommando:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERSDet här kommandot tar bort ämnet med namnet
topicname.Varning
Om du tar bort ämnet
test, som du skapade tidigare, måste du återskapa det. Det används senare under steg i det här dokumentet.
Om du vill ha mer information om vilka kommandon som är tillgängliga med verktyget kafka-topics.sh använder du följande kommando:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Skapa och konsumera poster
Kafka lagrar poster i topics. Poster produceras av producenter och konsumeras av konsumenter. Producenter och konsumenter kommunicerar med Kafka-koordinatortjänsten. Varje arbetsnod i HDInsight-klustret är en Apache Kafka-brokervärd.
Använd följande steg för att lagra uppgifter i det testtopic som du skapade tidigare och sedan läsa dem med en konsumentapplikation:
Om du vill skriva poster i ämnet använder du verktyget
kafka-console-producer.shfrån SSH-anslutningen:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testEfter det här kommandot kommer du till en tom rad.
Skriv in ett textmeddelande på den tomma raden och tryck på Enter. Ange några meddelanden på det här sättet och använd sedan Ctrl + C för att komma tillbaka till den vanliga kommandotolken. Varje rad skickas som en separat post till en Apache Kafka-topic.
Om du vill läsa poster i ämnet använder du verktyget
kafka-console-consumer.shfrån SSH-anslutningen:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningDetta kommando hämtar poster från ämnet och visar dem. Med hjälp av
--from-beginninganges att konsumenten ska starta från början av strömmen, så att alla uppgifter hämtas.Om du använder en äldre version av Kafka ersätter du
--bootstrap-server $KAFKABROKERSmed--zookeeper $KAFKAZKHOSTS.Använd Ctrl + C om du vill stoppa konsumenten.
Du kan också programmässigt skapa producenter och konsumenter. Ett exempel på användning av detta API finns i dokumentet Apache Kafka-producent- och konsument-API med HDInsight.
Rensa resurser
För att rensa de resurser som har skapats med den här snabbstarten kan du ta bort resursgruppen. När du tar bort resursgruppen raderas även det kopplade HDInsight-klustret och eventuella andra resurser som är associerade med resursgruppen.
Ta bort en resursgrupp med Azure Portal:
- I Azure Portal expanderar du menyn på vänster sida för att öppna tjänstemenyn och väljer sedan Resursgrupper för att visa listan med dina resursgrupper.
- Leta reda på den resursgrupp du vill ta bort och högerklicka på knappen Mer (...) till höger om listan.
- Välj Ta bort resursgrupp och bekräfta.
Varning
Om du tar bort ett Apache Kafka-kluster i HDInsight tas alla data som lagras i Kafka bort.