Fråga Apache Hive via JDBC-drivrutinen i HDInsight
Lär dig hur du använder JDBC-drivrutinen från ett Java-program. Skicka Apache Hive-frågor till Apache Hadoop i Azure HDInsight. Informationen i det här dokumentet visar hur du ansluter programmatiskt och från SQuirreL SQL klienten.
Mer information om Hive JDBC-gränssnittet finns i HiveJDBCInterface.
Förutsättningar
- Ett HDInsight Hadoop-kluster. Information om hur du skapar en finns i Kom igång med Azure HDInsight. Kontrollera att tjänsten HiveServer2 körs.
- Java Developer Kit (JDK) version 11 eller senare.
- SQuirreL SQL. SQuirreL är ett JDBC-klientprogram.
JDBC-anslutningssträng
JDBC-anslutningar till ett HDInsight-kluster i Azure görs via port 443. Trafiken skyddas med TLS/SSL. Den offentliga gateway som klustren sitter bakom omdirigerar trafiken till den port som HiveServer2 faktiskt lyssnar på. Följande anslutningssträng visar formatet som ska användas för HDInsight:
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
Ersätt CLUSTERNAME med namnet på HDInsight-klustret.
Värdnamn i anslutningssträng
Värdnamnet "CLUSTERNAME.azurehdinsight.net" i anslutningssträng är samma som kluster-URL:en. Du kan hämta den via Azure-portalen.
Port i anslutningssträng
Du kan bara använda port 443 för att ansluta till klustret från vissa platser utanför det virtuella Azure-nätverket. HDInsight är en hanterad tjänst, vilket innebär att alla anslutningar till klustret hanteras via en säker gateway. Du kan inte ansluta till HiveServer 2 direkt på portarna 10001 eller 10000. Dessa portar exponeras inte för utsidan.
Autentisering
När du upprättar anslutningen använder du HDInsight-klusteradministratörens namn och lösenord för att autentisera. Från JDBC-klienter som SQuirreL SQL anger du administratörsnamn och lösenord i klientinställningarna.
Från ett Java-program måste du använda namnet och lösenordet när du upprättar en anslutning. Följande Java-kod öppnar till exempel en ny anslutning:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
Anslut med SQuirreL SQL-klienten
SQuirreL SQL är en JDBC-klient som kan användas för att fjärrköra Hive-frågor med ditt HDInsight-kluster. Följande steg förutsätter att du redan har installerat SQuirreL SQL.
Skapa en katalog som ska innehålla vissa filer som ska kopieras från klustret.
I följande skript ersätter du
sshusermed SSH-användarkontonamnet för klustret. ErsättCLUSTERNAMEmed HDInsight-klusternamnet. Från en kommandorad ändrar du arbetskatalogen till den som skapades i föregående steg och anger sedan följande kommando för att kopiera filer från ett HDInsight-kluster:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .Starta SQuirreL SQL-programmet. Välj Drivrutiner till vänster i fönstret.

Från ikonerna överst i dialogrutan Drivrutiner väljer du + ikonen för att skapa en drivrutin.
I dialogrutan Lägg till drivrutin lägger du till följande information:
Property Värde Name Hive Exempel-URL jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2Extra klasssökväg Använd knappen Lägg till för att lägga till alla jar-filer som laddades ned tidigare. Klassnamn org.apache.hive.jdbc.HiveDriver 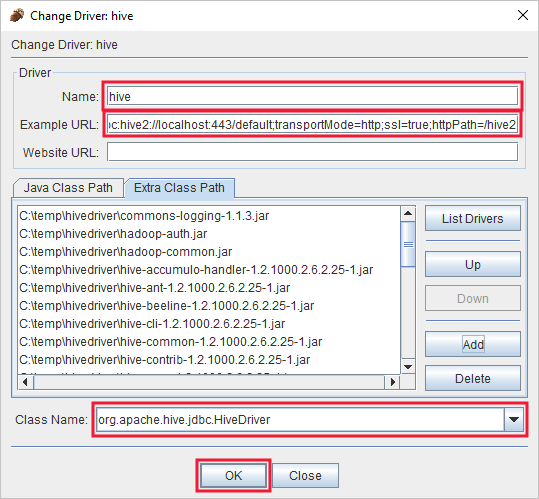
Spara de här inställningarna genom att välja OK .
Till vänster om SQuirreL SQL-fönstret väljer du Alias. Välj + sedan ikonen för att skapa ett anslutningsalias.
Använd följande värden för dialogrutan Lägg till alias :
Property Värde Name Hive på HDInsight Drivrutinen Använd listrutan för att välja Hive-drivrutinen . webbadress jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. Ersätt KLUSTERNAMN med namnet på ditt HDInsight-kluster.Användarnamn Namnet på klusterinloggningskontot för ditt HDInsight-kluster. Standardvärdet är admin. Lösenord Lösenordet för klusterinloggningskontot. 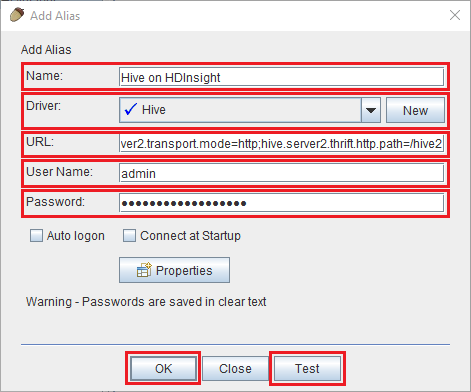
Viktigt!
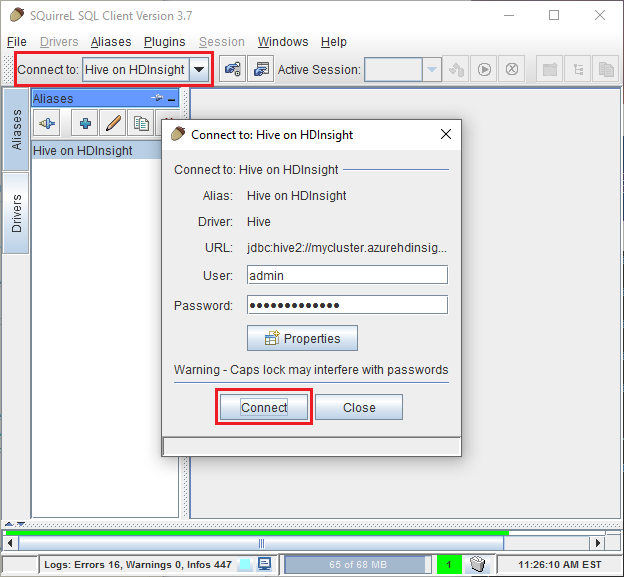
Använd testknappen för att kontrollera att anslutningen fungerar. När Anslut till: Dialogrutan Hive i HDInsight visas väljer du Anslut för att utföra testet. Om testet lyckas visas en dialogruta för Anslut ion lyckades. Om ett fel inträffar kan du läsa Felsökning.
Om du vill spara anslutningsaliaset använder du knappen Ok längst ned i dialogrutan Lägg till alias .
Från listrutan Anslut till överst i SQuirreL SQL väljer du Hive i HDInsight. När du uppmanas till det väljer du Anslut.
När du är ansluten anger du följande fråga i SQL-frågedialogrutan och väljer sedan ikonen Kör (en person som körs). Resultatområdet ska visa resultatet av frågan.
select * from hivesampletable limit 10;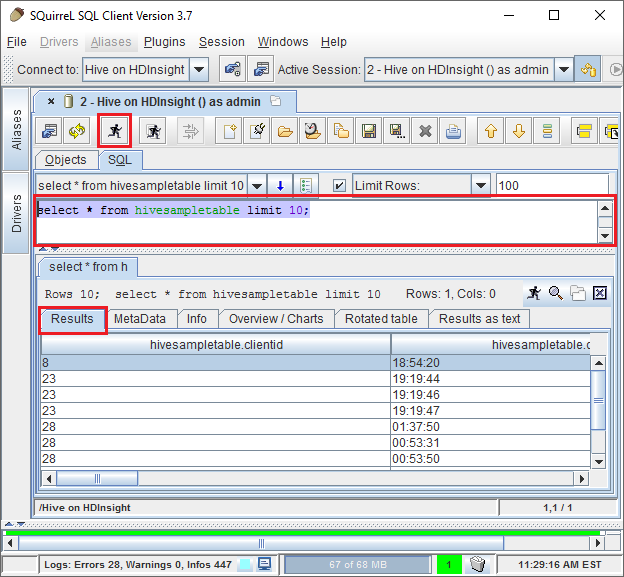
Anslut från ett java-exempelprogram
Ett exempel på hur du använder en Java-klient för att fråga Hive i HDInsight finns på https://github.com/Azure-Samples/hdinsight-java-hive-jdbc. Följ anvisningarna på lagringsplatsen för att skapa och köra exemplet.
Felsökning
Ett oväntat fel inträffade vid försök att öppna en SQL-anslutning
Symptom: När du ansluter till ett HDInsight-kluster som är version 3.3 eller senare kan du få ett felmeddelande om att ett oväntat fel uppstod. Stackspårningen för det här felet börjar med följande rader:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
Orsak: Det här felet orsakas av en äldre version commons-codec.jar fil som ingår i SQuirreL.
Lösning: Åtgärda det här felet med hjälp av följande steg:
Avsluta SQuirreL och gå sedan till katalogen där SQuirreL är installerat på systemet, kanske
C:\Program Files\squirrel-sql-4.0.0\lib. I katalogen SquirreL underlibkatalogen ersätter du den befintliga commons-codec.jar med den som hämtats från HDInsight-klustret.Starta om SQuirreL. Felet bör inte längre inträffa när du ansluter till Hive i HDInsight.
HDInsight kopplade ner anslutningen
Symptom: HDInsight kopplar oväntat från anslutningen när du försöker ladda ned en enorm mängd data (till exempel flera GBs) via JDBC/ODBC.
Orsak: Begränsningen för gatewaynoder orsakar det här felet. När du hämtar data från JDBC/ODBC måste alla data passera genom gatewaynoden. En gateway är dock inte utformad för att ladda ned en enorm mängd data, så gatewayen kan stänga anslutningen om den inte kan hantera trafiken.
Lösning: Undvik att använda JDBC/ODBC-drivrutin för att ladda ned stora mängder data. Kopiera data direkt från bloblagring i stället.
Nästa steg
Nu när du har lärt dig hur du använder JDBC för att arbeta med Hive använder du följande länkar för att utforska andra sätt att arbeta med Azure HDInsight.
- Visualisera Apache Hive-data med Microsoft Power BI i Azure HDInsight.
- Visualisera Interaktiv fråga Hive-data med Power BI i Azure HDInsight.
- Anslut Excel till HDInsight med Microsoft Hive ODBC-drivrutinen.
- Anslut Excel till Apache Hadoop med hjälp av Power Query.
- Använda Apache Hive med HDInsight
- Använda Apache Hive med HDInsight
- Använda MapReduce-jobb med HDInsight