Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I den här artikeln får du lära dig hur du skapar Apache Hadoop-kluster i HDInsight med Azure-portalen och sedan kör Apache Hive-jobb i HDInsight. De flesta Hadoop-jobb är batchjobb. Du skapar ett kluster, kör vissa jobb och tar sedan bort klustret. I den här artikeln utför du alla tre aktiviteterna. Detaljerade förklaringar av tillgängliga konfigurationer finns i Konfigurera kluster i HDInsight. Mer information om hur du använder portalen för att skapa kluster finns i Skapa kluster i portalen.
I den här snabbstarten använder du Azure Portal för att skapa ett HDInsight Hadoop-kluster. Du kan också skapa ett kluster med hjälp av Azure Resource Manager-mallen.
För närvarande levereras HDInsight med sju olika klustertyper. Varje typ av kluster har stöd för olika komponentuppsättningar. Samtliga klustertyper stöder Hive. En lista över komponenter som stöds och som hanteras i HDInsight finns i Vad är nytt i de Apache Hadoop-klusterversioner som tillhandahålls av HDInsight?
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Skapa ett Apache Hadoop-kluster
I det här avsnittet skapar du ett Hadoop-kluster i HDInsight med hjälp av Azure Portal.
Logga in på Azure-portalen.
Välj + Skapa en resurs från menyn högst upp.
Välj Analytics>Azure HDInsight för att gå till sidan Skapa HDInsight-kluster.
På fliken Grundläggande anger du följande information:
Property Beskrivning Prenumeration I listrutan väljer du den Azure-prenumeration som används för klustret. Resursgrupp Välj din befintliga resursgrupp i listrutan eller välj Skapa ny. Klusternamn Ange ett globalt unikt namn. Namnet kan bestå av upp till 59 tecken, inklusive bokstäver, siffror och bindestreck. Det första och sista tecknen i namnet får inte vara bindestreck. Region I listrutan väljer du en region där klustret skapas. Välj en plats närmare så får du bättre prestanda. Klustertyp Välj Välj klustertyp. Välj sedan Hadoop som klustertyp. Version I listrutan väljer du en version. Använd standardversionen om du inte vet vad du ska välja. Användarnamn och lösenord för klusterinloggning Standardnamnet för inloggning är administratör. Lösenordet måste vara minst 10 tecken långt och måste innehålla minst en siffra, en versal och en gemen bokstav, ett icke-numeriskt tecken (förutom tecken ' ` "). Se till att du inte anger vanliga lösenord, till exempel "Pass@word1".Secure Shell (SSH)-användarnamn Standardanvändarnamnet är sshuser. Du kan ange ett annat namn som SSH-användarnamn.Använda klusterinloggningslösenord för SSH Markera den här kryssrutan om du vill använda samma lösenord för SSH-användare som det du angav för klusterinloggningsanvändaren. 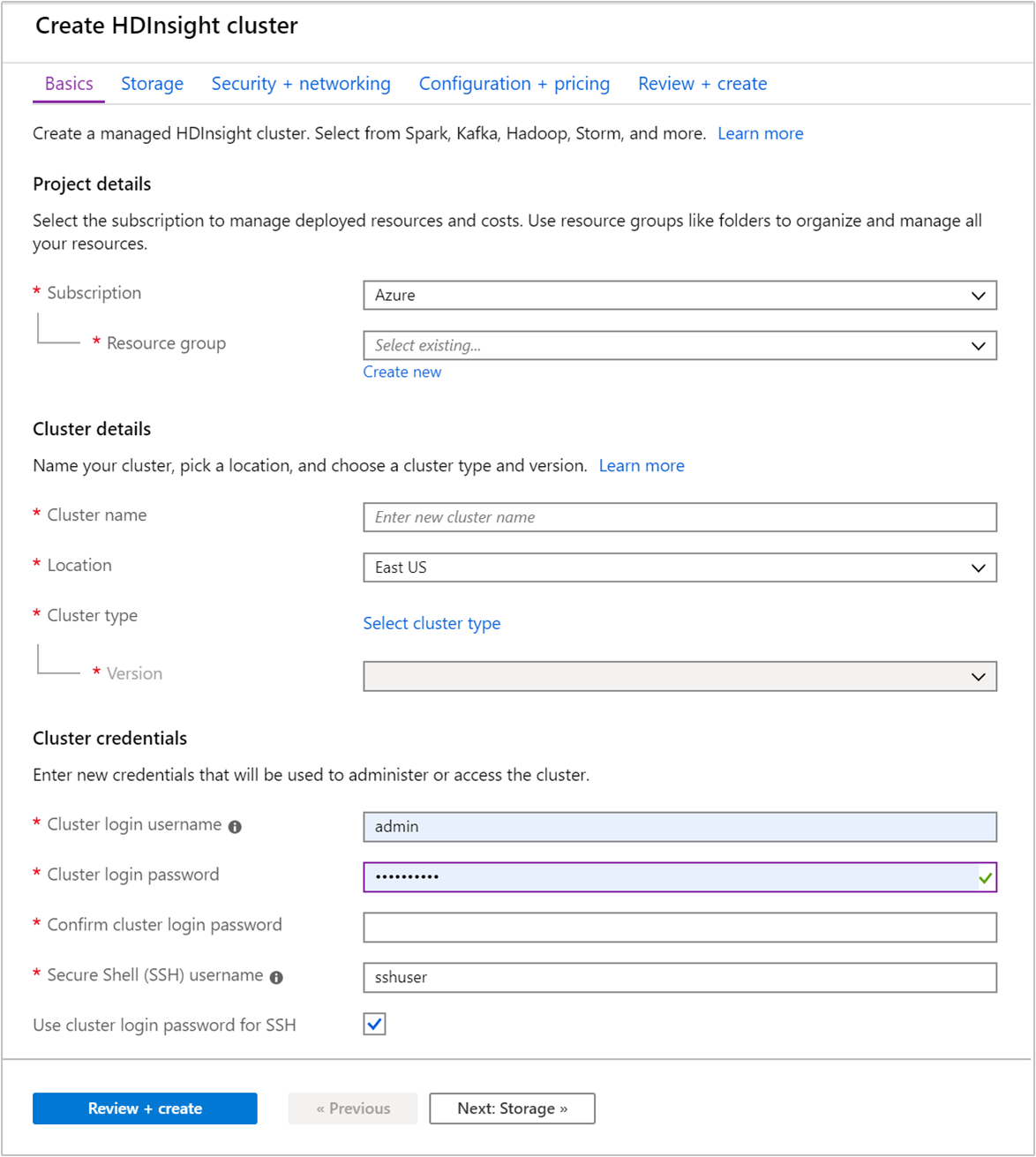
Välj Nästa: Lagring >> för att gå vidare till lagringsinställningarna.
På fliken Lagring anger du följande värden:
Property Beskrivning Primär lagringstyp Använd standardvärdet Azure Storage. Urvalsmetod Använd standardvärdet Välj från lista. Primärt lagringskonto Använd listrutan för att välja ett befintligt lagringskonto eller välj Skapa nytt. Om du skapar ett nytt konto måste namnet vara mellan 3 och 24 tecken och kan bara innehålla siffror och små bokstäver. Behållare Använd det automatiskt ifyllda värdet. 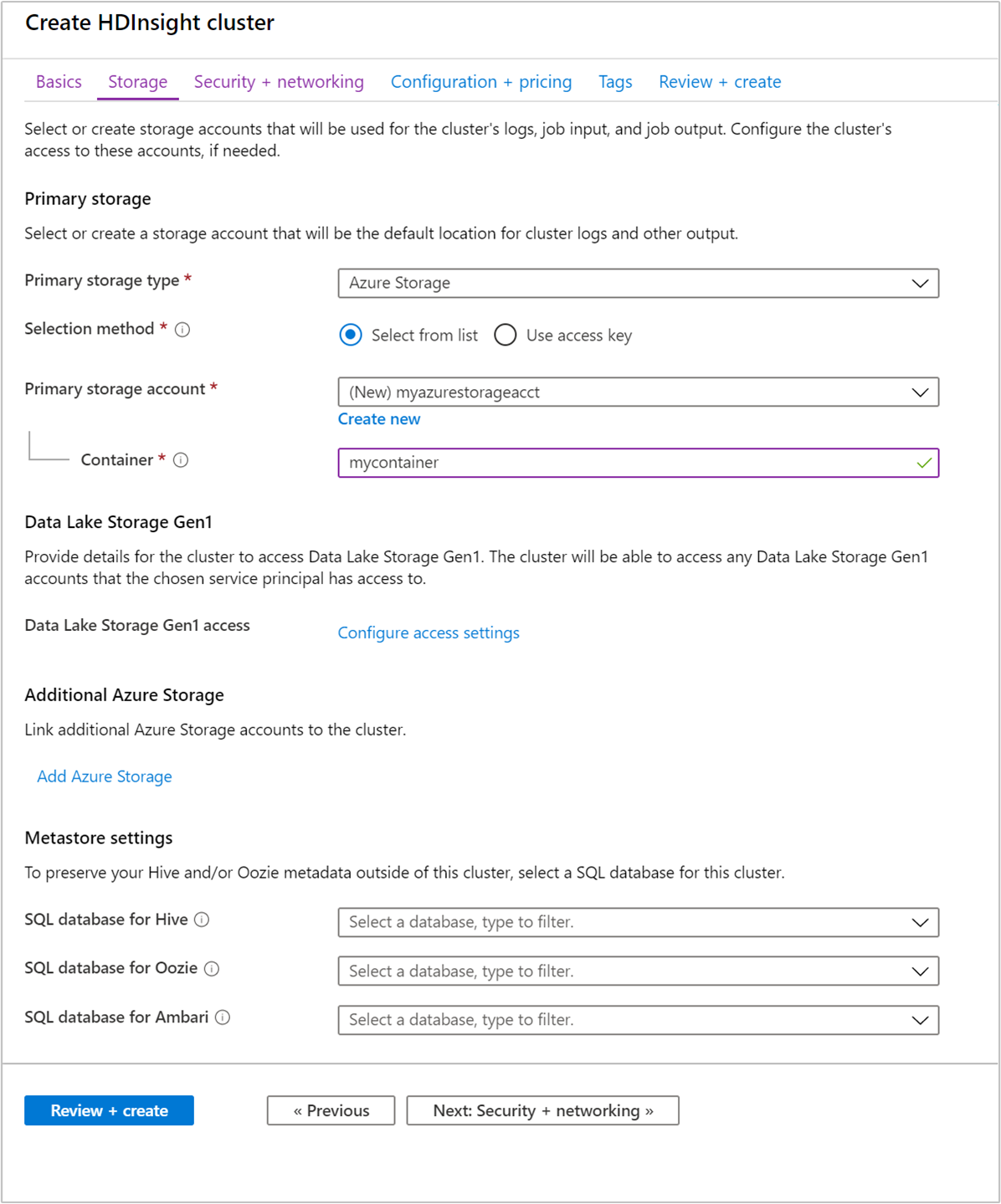
Varje kluster har ett Azure Storage-konto eller ett
Azure Data Lake Storage Gen2beroende. Det kallas standardlagringskontot. HDInsight-klustret och dess standardlagringskonto måste vara samlokaliserade i samma Azure-region. När du tar bort kluster tas inte lagringskontot bort.Välj fliken Granska + skapa .
På fliken Granska + skapa kontrollerar du de värden som du valde i de tidigare stegen.
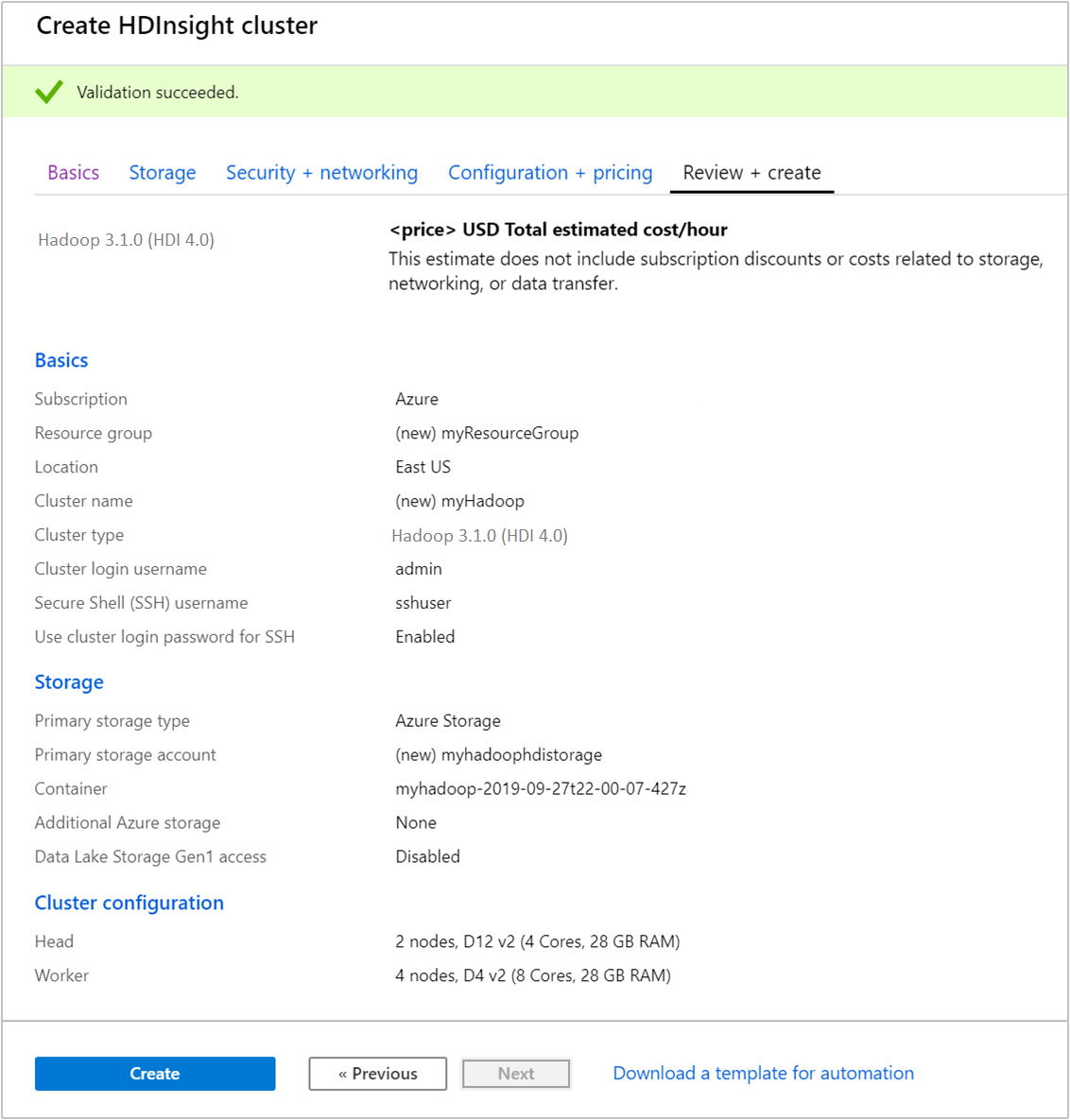
Välj Skapa. Det tar cirka 20 minuter att skapa ett kluster.
När klustret har skapats visas en klusteröversiktssida i Azure Portal.
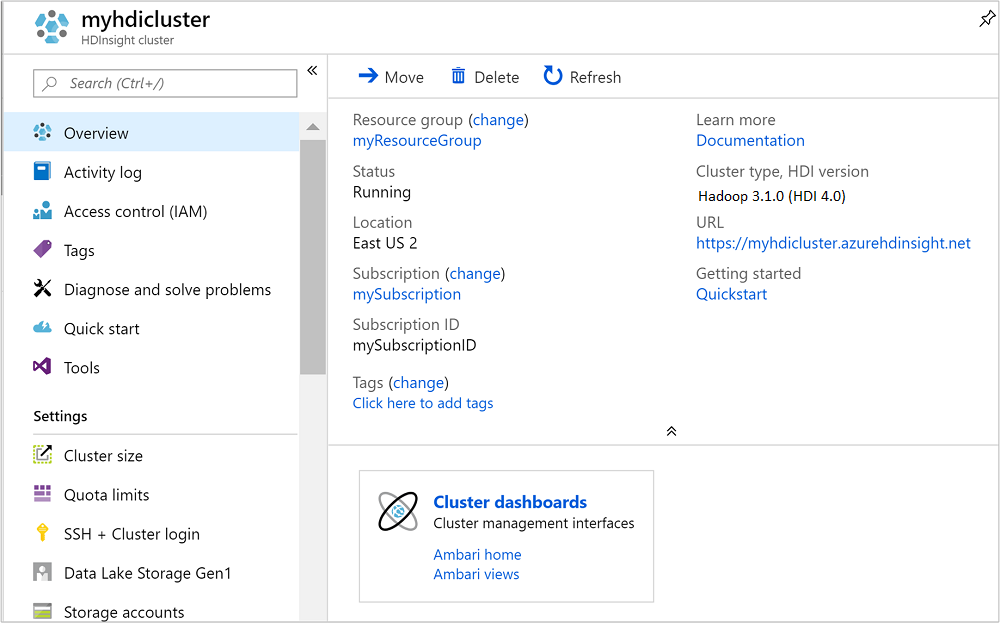
Kör Apache Hive-frågor
Apache Hive är den populäraste komponenten som används i HDInsight. Det finns många sätt att köra Hive-jobb i HDInsight. I den här snabbstarten använder du Ambari Hive-vyn från portalen. Andra metoder för att skicka Hive-jobb beskrivs i Använda Hive-data i HDInsight.
Kommentar
Apache Hive View är inte tillgänglig i HDInsight 4.0.
Öppna Ambari genom att välja Klusterinstrumentpanel i föregående skärmbild. Du kan också bläddra till
https://ClusterName.azurehdinsight.netvarClusterNameär klustret som du skapade i föregående avsnitt.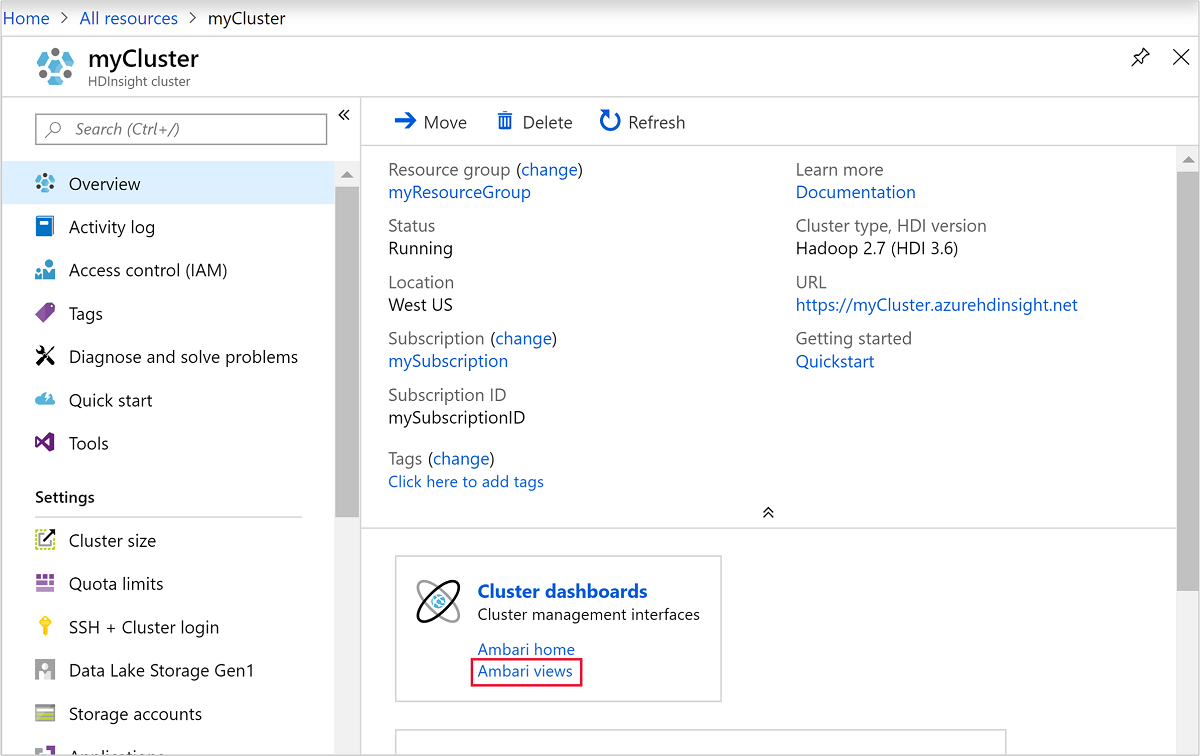
Ange det Hadoop-användarnamn och -lösenord som du angav när du skapade klustret. Standardanvändarnamnet är
admin.Öppna Hive-vyn som visas på följande skärmavbild:
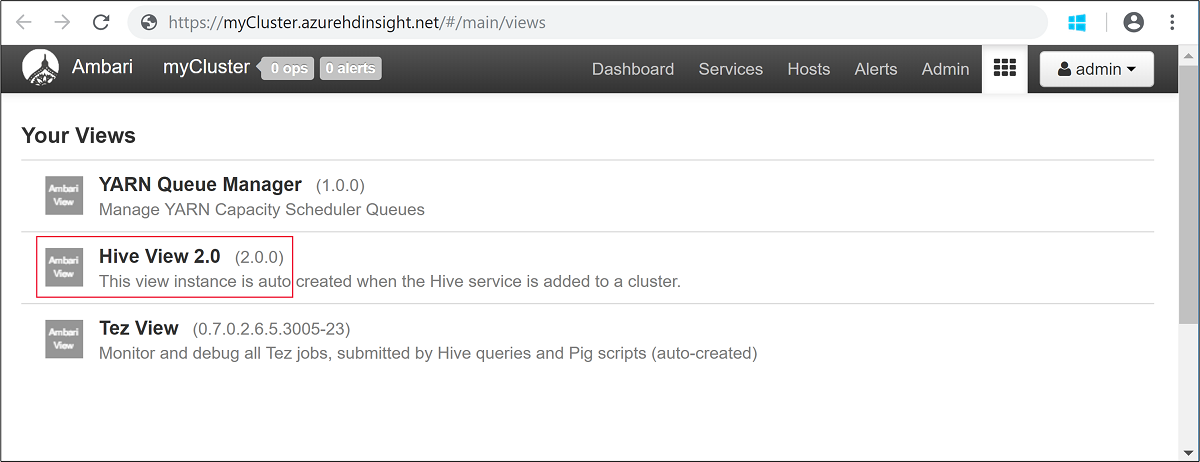
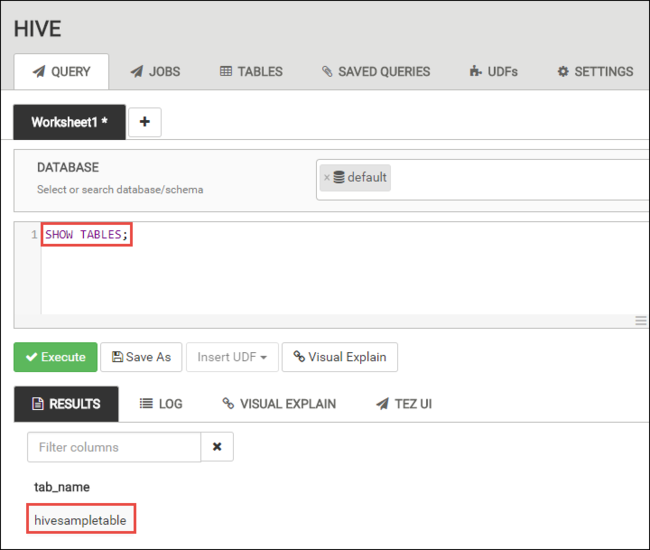
På fliken FRÅGA klistrar du in följande HiveQL-instruktioner i kalkylbladet:
SHOW TABLES;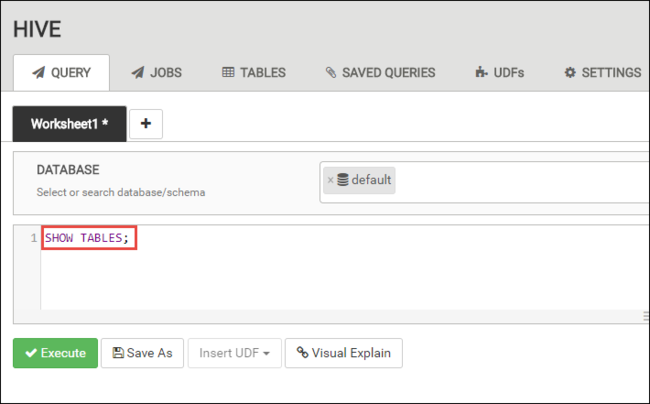
Välj Kör. Fliken RESULTAT visas under fliken FRÅGA och visar information om jobbet.
När frågan har slutförts visas resultatet av åtgärden på fliken FRÅGA. En tabell med namnet hivesampletable bör visas. Detta exempel på en Hive-tabell kommer med alla HDInsight-kluster.
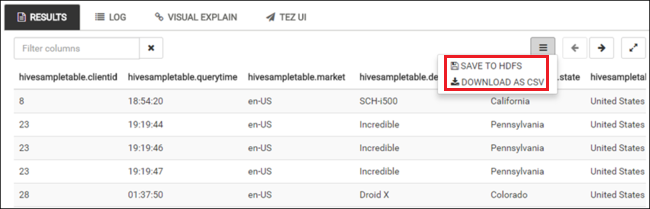
Upprepa steg 4 och 5 för att köra följande fråga:
SELECT * FROM hivesampletable;Du kan också spara frågans resultat. Välj menyknappen till höger och ange om du vill ladda ned resultatet som en CSV-fil eller lagra den på lagringskontot som är associerat till klustret.
När du har slutfört ett Hive-jobb kan du exportera resultaten till Azure SQL Database eller SQL Server-databasen. Du kan också visualisera resultaten med excel. Mer information om hur du använder Hive i HDInsight finns i Använda Apache Hive och HiveQL med Apache Hadoop i HDInsight för att analysera en Apache Log4j-exempelfil.
Rensa resurser
När du har slutfört snabbstarten kanske du vill ta bort klustret. Med HDInsight lagras dina data i Azure Storage, så att du på ett säkert sätt kan ta bort ett kluster när de inte används. Du debiteras också för ett HDInsight-kluster, även om det inte används. Eftersom avgifterna för klustret är många gånger högre än avgifterna för lagring är det ekonomiskt klokt att ta bort kluster när de inte används.
Kommentar
Om du omedelbart fortsätter till nästa artikel för att lära dig hur du kör ETL-åtgärder med Hadoop i HDInsight kanske du vill ha klustret igång. Anledningen är att du i handledningen måste skapa ett Hadoop-kluster igen. Men om du inte går igenom nästa artikel direkt måste du ta bort klustret nu.
Ta bort klustret och/eller Storage-kontot av standardtyp
Gå tillbaka till webbläsarfliken där du har Azure-portalen. Du ska vara på klustrets översiktssida. Om du endast vill ta bort klustret men behålla standardlagringskontot kan du klicka på Ta bort.
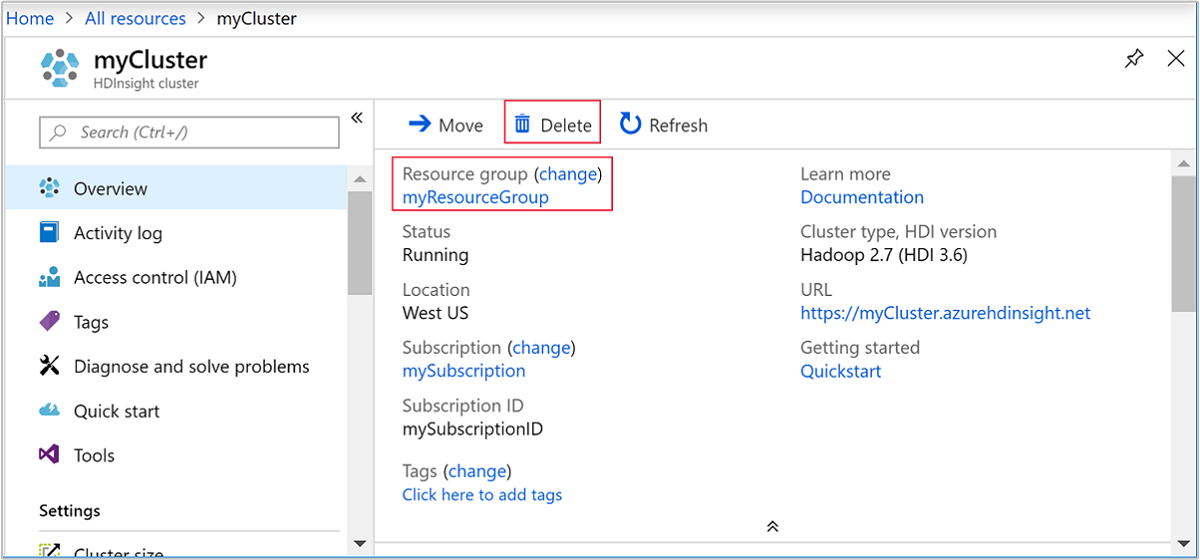
Om du vill ta bort klustret och standardlagringskontot väljer du resursgruppens namn (markerat i föregående skärmbild) för att öppna resursgruppssidan.
Ta bort resursgruppen som innehåller klustret och standardlagringskontot genom att välja Ta bort resursgrupp. Tänk på att lagringskontot tas bort om du tar bort resursgruppen. Välj att bara ta bort klustret om du vill behålla Storage-kontot.
Nästa steg
I den här snabbstarten har du lärt dig hur du skapar ett Linux-baserat HDInsight-kluster med hjälp av en Resource Manager-mall och hur du utför grundläggande Hive-frågor. I nästa artikel får du lära dig hur du utför en extraktions-, transformations- eller inläsningsåtgärd (ETL) med Hadoop på HDInsight.