Köra Apache Hive-frågor med hjälp av Data Lake Tools för Visual Studio
Lär dig hur du använder Data Lake-verktygen för Visual Studio för att fråga Apache Hive. Med Data Lake-verktygen kan du enkelt skapa, skicka och övervaka Hive-frågor till Apache Hadoop i Azure HDInsight.
Förutsättningar
Ett Apache Hadoop-kluster i HDInsight. Information om hur du skapar det här objektet finns i Skapa Apache Hadoop-kluster i Azure HDInsight med resource manager-mall.
Visual Studio. Stegen i den här artikeln använder Visual Studio 2019.
HDInsight-verktyg för Visual Studio eller Azure Data Lake-verktyg för Visual Studio. Information om hur du installerar och konfigurerar verktygen finns i Installera Data Lake Tools för Visual Studio.
Köra Apache Hive-frågor med hjälp av Visual Studio
Det finns två sätt att skapa och köra Hive-frågor:
- Skapa ad hoc-frågor.
- Skapa ett Hive-program.
Skapa en ad hoc Hive-fråga
Ad hoc-frågor kan köras i batch- eller interaktivt läge.
Starta Visual Studio och välj Fortsätt utan kod.
Högerklicka på Azure från Server Explorer, välj Anslut till Microsoft Azure-prenumeration... och slutför inloggningsprocessen.
Expandera HDInsight, högerklicka på klustret där du vill köra frågan och välj sedan Skriv en Hive-fråga.
Ange följande hive-fråga:
SELECT * FROM hivesampletable;Välj Kör. Körningsläget är som standard interaktivt.
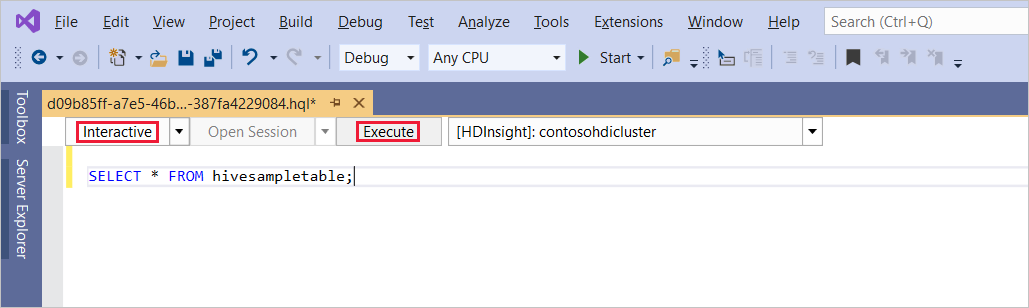
Om du vill köra samma fråga i Batch-läge växlar du listrutan från Interaktiv till Batch. Körningsknappen ändras från Kör till Skicka.

Hive-redigeraren stöder IntelliSense. Data Lake Tools för Visual Studio stöder inläsning av fjärrmetadata när du redigerar Hive-skript. Om du till exempel skriver
SELECT * FROMvisar IntelliSense alla föreslagna tabellnamn. När du anger ett tabellnamn visar IntelliSense en lista över kolumnnamnen. Verktygen stöder de flesta Hive DML-instruktioner, underfrågor och inbyggda UDF. IntelliSense föreslår endast metadata för kluster som valts i verktygsfältet för HDInsight.I frågeverktygsfältet (området under frågefliken och ovanför frågetexten) väljer du antingen Skicka eller väljer pulldown-pilen bredvid Skicka och väljer Avancerat i pulldown-listan. Om du väljer det senare alternativet
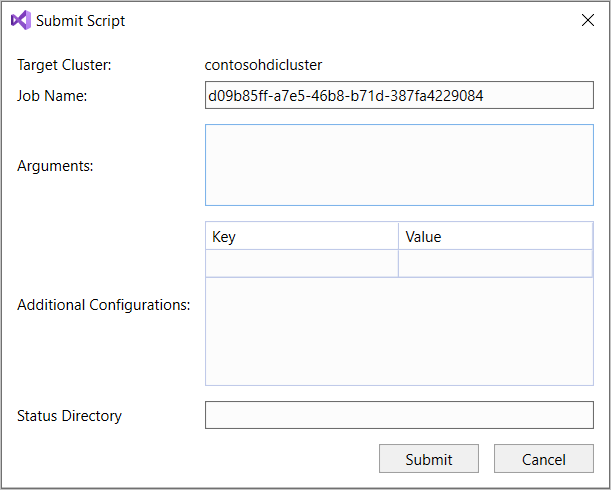
Om du har valt alternativet avancerad sändning konfigurerar du Jobbnamn, Argument, Ytterligare konfigurationer och Statuskatalog i dialogrutan Skicka skript . Välj sedan Skicka.
Skapa ett Hive-program
Följ dessa steg för att köra en Hive-fråga genom att skapa ett Hive-program:
Öppna Visual Studio.
I startfönstret väljer du Skapa ett nytt projekt.
I fönstret Skapa ett nytt projekt går du till rutan Sök efter mallar och anger Hive. Välj sedan Hive-program och välj Nästa.
I fönstret Konfigurera det nya projektet anger du ett projektnamn, väljer eller skapar en plats för det nya projektet och väljer sedan Skapa.
Öppna filen Script.hql som skapas med det här projektet och klistra in följande HiveQL-instruktioner:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Dessa instruktioner utför följande åtgärder:
DROP TABLE: Tar bort tabellen om den finns.CREATE EXTERNAL TABLE: Skapar en ny extern tabell i Hive. Externa tabeller lagrar endast tabelldefinitionen i Hive. (Data finns kvar på den ursprungliga platsen.)Kommentar
Externa tabeller bör användas när du förväntar dig att underliggande data ska uppdateras av en extern källa, till exempel ett MapReduce-jobb eller en Azure-tjänst.
Om du tar bort en extern tabell tas inte data bort, utan endast tabelldefinitionen.
ROW FORMAT: Berättar för Hive hur data formateras. I det här fallet avgränsas fälten i varje logg med ett blanksteg.STORED AS TEXTFILE LOCATION: Meddelar Hive att data lagras i exempel-/datakatalogen och att de lagras som text.SELECT: Väljer ett antal av alla rader där kolumnent4innehåller värdet[ERROR]. Den här instruktionen returnerar värdet3, eftersom tre rader innehåller det här värdet.INPUT__FILE__NAME LIKE '%.log': Uppmanar Hive att endast returnera data från filer som slutar .log. Den här satsen begränsar sökningen till den sample.log fil som innehåller data.
Välj det HDInsight-kluster som du vill använda för den här frågan i verktygsfältet för frågefilen (som liknar verktygsfältet för ad hoc-frågan). Ändra sedan Interaktiv till Batch (om det behövs) och välj Skicka för att köra instruktionerna som ett Hive-jobb.
Hive-jobbsammanfattningen visas och visar information om det jobb som körs. Använd länken Uppdatera för att uppdatera jobbinformationen tills jobbstatusenändras till Slutförd.
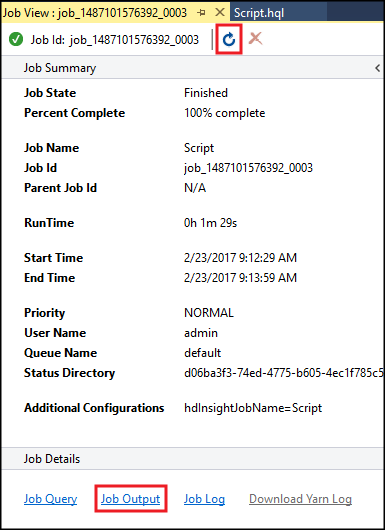
Välj Jobbutdata för att visa utdata för det här jobbet. Den visar
[ERROR] 3, vilket är det värde som returneras av den här frågan.
Ytterligare exempel
I följande exempel används tabellen log4jLogs som skapades i föregående procedur, Skapa ett Hive-program.
Högerklicka på klustret från Server Explorer och välj Skriv en Hive-fråga.
Ange följande hive-fråga:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Dessa instruktioner utför följande åtgärder:
CREATE TABLE IF NOT EXISTS: Skapar en tabell om den inte redan finns. Eftersom nyckelordetEXTERNALinte används skapar den här instruktionen en intern tabell. Interna tabeller lagras i Hive-informationslagret och hanteras av Hive.Kommentar
Till skillnad från
EXTERNALtabeller raderas även underliggande data när en intern tabell tas bort.STORED AS ORC: Lagrar data i optimerat orc-format (row columnar). ORC är ett mycket optimerat och effektivt format för lagring av Hive-data.INSERT OVERWRITE ... SELECT: Väljer rader från tabellenlog4jLogssom innehåller[ERROR]och infogar sedan data ierrorLogstabellen.
Ändra Interaktiv till Batch om det behövs och välj sedan Skicka.
Kontrollera att jobbet skapade tabellen genom att gå till Server Explorer och expandera Azure>HDInsight. Expandera HDInsight-klustret och expandera sedan Standard för Hive Databases>. Tabellen errorLogs och tabellen Log4jLogs visas.
Nästa steg
Som du ser är HDInsight-verktygen för Visual Studio ett enkelt sätt att arbeta med Hive-frågor på HDInsight.
Allmän information om Hive i HDInsight finns i Vad är Apache Hive och HiveQL i Azure HDInsight?
Information om andra sätt att arbeta med Hadoop på HDInsight finns i Använda MapReduce i Apache Hadoop på HDInsight
Mer information om HDInsight-verktygen för Visual Studio finnsi Använda Data Lake Tools för Visual Studio för att ansluta till Azure HDInsight och köra Apache Hive-frågor
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för