Använda Data Lake Tools för Visual Studio för att ansluta till Azure HDInsight och köra Apache Hive-frågor
Lär dig hur du använder Microsoft Azure Data Lake och Stream Analytics Tools för Visual Studio (Data Lake Tools). Använd verktyget för att ansluta till Apache Hadoop-kluster i Azure HDInsight och skicka Hive-frågor.
Mer information om hur du använder HDInsight finns i Kom igång med HDInsight.
Data Lake Tools för Visual Studio kan användas för att komma åt Azure Data Lake Analytics och HDInsight. Information om Data Lake Tools finns i Utveckla U-SQL-skript med hjälp av Data Lake Tools för Visual Studio.
För att slutföra den här artikeln och använda Data Lake Tools för Visual Studio behöver du följande:
Ett Azure HDInsight-kluster. Information om hur du skapar ett HDInsight-kluster finns i Kom igång med hjälp av Apache Hadoop i Azure HDInsight. Om du vill köra interaktiva Apache Hive-frågor behöver du ett HDInsight-Interaktiv fråga kluster.
Visual Studio. Visual Studio Community-utgåvan är kostnadsfri. Anvisningarna som visas här är för Visual Studio 2019.
Följ lämpliga instruktioner för att installera Data Lake Tools för din version av Visual Studio:
För Visual Studio 2017 eller Visual Studio 2019:
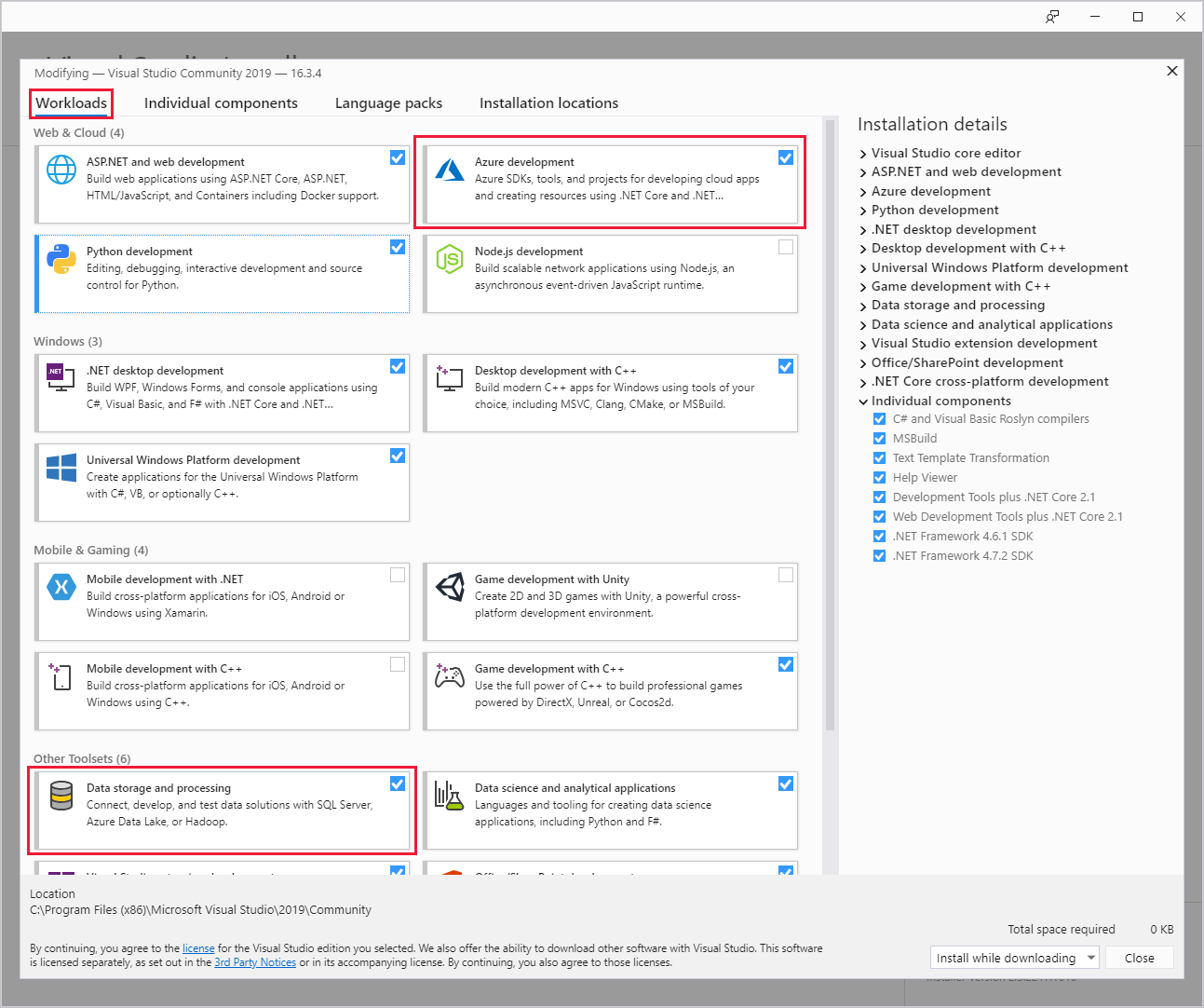
Under Visual Studio-installationen kontrollerar du att du inkluderar arbetsbelastningen För Azure-utveckling eller arbetsbelastningen Datalagring och bearbetning .
För befintliga Visual Studio-installationer går du till IDE-menyraden och väljer Verktyg>Hämta verktyg och funktioner för att öppna Visual Studio Installer. På fliken Arbetsbelastningar väljer du minst arbetsbelastningen För Azure-utveckling (under Webb och moln). Eller välj arbetsbelastningen Datalagring och bearbetning (under Andra verktygsuppsättningar).
För Visual Studio 2015:
Ladda ned Data Lake Tools. Välj den version av Data Lake Tools som matchar din version av Visual Studio.
Se sedan till att du uppdaterar Data Lake Tools till den senaste versionen.
Öppna Visual Studio.
I startfönstret väljer du Fortsätt utan kod.
I menyraden i Visual Studio IDE väljer du Tillägg>Hantera tillägg.
I dialogrutan Hantera tillägg expanderar du noden Uppdateringar.
Om listan över tillgängliga uppdateringar innehåller Azure Data Lake och Stream Analytic Tools väljer du den. Välj sedan knappen Uppdatera . När dialogrutan Ladda ned och installera visas och försvinner lägger Visual Studio till tillägget Azure Data Lake och Stream Analytic Tools i uppdateringsschemat.
Stäng alla Visual Studio-fönster. Dialogrutan VSIX Installer visas.
Välj Licens för att läsa licensvillkoren och välj sedan Stäng för att återgå till dialogrutan VSIX Installer .
Välj Ändra. Installationen av tilläggsuppdateringen påbörjas. Efter ett tag ändras dialogrutan för att visa att den är klar med att göra ändringar. Välj Stäng och starta sedan om Visual Studio för att slutföra installationen.
Anteckning
Du kan endast använda Data Lake Tools i version 2.3.0.0 eller senare för att ansluta till interaktiva frågekluster och köra interaktiva Hive-frågor.
Du kan använda Data Lake Tools för Visual Studio för att ansluta till dina HDInsight-kluster, utföra vissa grundläggande hanteringsåtgärder och köra Hive-frågor.
Anteckning
Information om hur du ansluter till ett allmänt Hadoop-kluster finns i Skriva och skicka Hive-frågor med Hjälp av Visual Studio.
Så här ansluter du till din Azure-prenumeration:
Öppna Visual Studio.
I startfönstret väljer du Fortsätt utan kod.
I IDE-menyraden väljer du Visa>serverutforskaren.
I Server Explorer högerklickar du på Azure, väljer Anslut till Microsoft Azure-prenumeration och slutför autentiseringsprocessen. Från Server Explorer expanderar du Azure>HDInsight för att visa en lista över befintliga HDInsight-kluster.
Om du inte har några kluster skapar du ett med hjälp av Azure Portal, Azure PowerShell eller HDInsight SDK. Mer information finns i Konfigurera kluster i HDInsight.
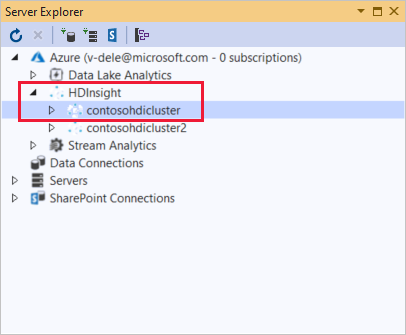
Expandera ett HDInsight-kluster. Klustret innehåller noder för Hive-databaser. Dessutom ett standardlagringskonto, eventuella ytterligare länkade lagringskonton och Hadoop Service Log. Du kan expandera entiteterna ytterligare.
När du har anslutit till din Azure-prenumeration kan du utföra följande uppgifter.
Så här ansluter du till Azure-portalen från Visual Studio:
I Server Explorer expanderar du Azure>HDInsight och väljer ditt kluster.
Högerklicka på ett HDInsight-kluster och välj Hantera kluster i Azure Portal.
Så här ställer du frågor och ger feedback från Visual Studio:
Från Server Explorer väljer du Azure>HDInsight.
Högerklicka på HDInsight och välj antingen MSDN-forum för att ställa frågor eller Ge feedback för att ge feedback.
Anteckning
För närvarande är den enda typen av HDInsight-kluster som du kan länka till en Hive-typ.
Så här länkar du ett HDInsight-kluster:
Högerklicka på HDInsight och välj sedan Länka ett HDInsight-kluster för att visa dialogrutan Länka ett HDInsight-kluster.
Ange en anslutnings-URL i formuläret
https://CLUSTERNAME.azurehdinsight.net. Klusternamnet fylls automatiskt i med klusternamndelen av url:en när du går till ett annat fält. Ange sedan användarnamn och lösenord och välj Nästa.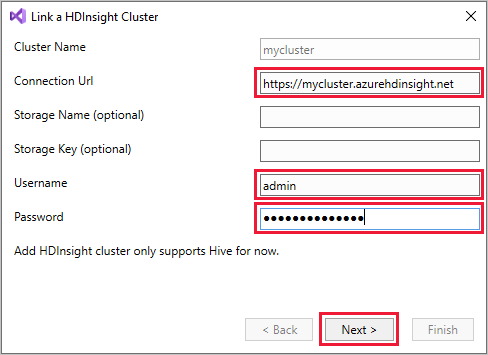
Välj Slutför. Om klusterlänkningen lyckas visas klustret under HDInsight-noden .
Om du vill uppdatera ett länkat kluster högerklickar du på klustret och väljer Redigera. Du kan sedan uppdatera klusterinformationen.
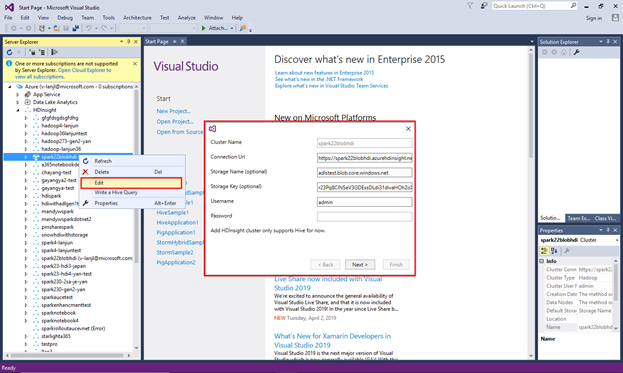
Från Server Explorer kan du se standardkontot för lagring och eventuella länkade lagringskonton. Om du expanderar standardkontot för lagring kan du se containrarna på lagringskontot. Standardlagringskontot och standardcontainern är markerade.
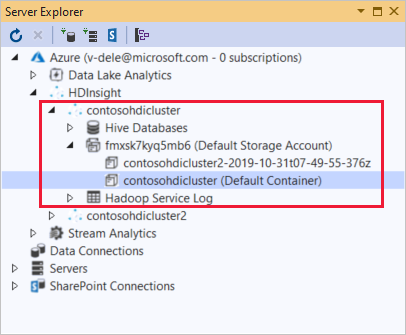
Högerklicka på en container och välj Visa container för att visa containerns innehåll. När du har öppnat en container kan du använda knapparna i verktygsfältet för att uppdatera innehållslistan, ladda upp blob, ta bort markerade blobar, Öppna blob och ladda ned (Spara som) valda blobar.
Apache Hive är en infrastruktur för informationslager som bygger på Hadoop. Hive används för att sammanfatta data, frågor och analys. Du kan använda Data Lake Tools för Visual Studio för att köra Hive-frågor från Visual Studio. Mer information om Hive finns i Vad är Apache Hive och HiveQL på Azure HDInsight?.
Interaktiv fråga i Azure HDInsight använder Hive på LLAP i Apache Hive 2.1. Interaktiv fråga ger interaktivitet till komplexa frågor i informationslagerstil på stora, lagrade datamängder. Det går mycket snabbare att köra Hive-frågor på Interaktiv fråga än traditionella Hive-batchjobb.
Anteckning
Du kan bara köra interaktiva Hive-frågor när du ansluter till ett kluster med en interaktiv HDInsight-fråga.
Du kan också använda Data Lake Tools för Visual Studio för att se vad som finns i ett Hive-jobb. Data Lake Tools för Visual Studio samlar in och hämtar Yarn-loggarna för specifika Hive-jobb.
Från Server Explorer väljer du Azure>HDInsight och väljer ditt kluster. Den här noden är startpunkten i Server Explorer för de avsnitt som ska följas.
Alla HDInsight-kluster har en Hive-standardtabell med namnet hivesampletable.
Från klustret väljer du Hive Databases>standard>hivesampletable.
Så här visar
hivesampletabledu schemat:Expandera hivesampletable. Namnen och datatyperna för kolumnerna
hivesampletablevisas.Så här visar
hivesampletabledu data:Högerklicka på hivesampletable och välj Visa de 100 översta raderna. Listan med 100 resultat visas i fönstret Hive Table: hivesampletable . Den här åtgärden motsvarar att köra följande Hive-fråga med hjälp av Hive ODBC-drivrutinen:
SELECT * FROM hivesampletable LIMIT 100Du kan anpassa radantalet genom att ändra Antal rader. Du kan välja 50, 100, 200 eller 1 000 rader i listrutan.
Du kan använda det grafiska användargränssnittet eller Hive-frågor för att skapa en Hive-tabell. Information om hur du använder Hive-frågor finns i Skapa och köra Hive-frågor.
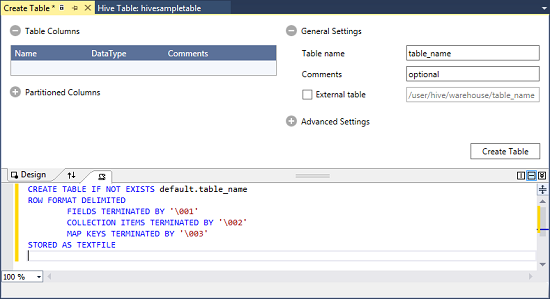
I klustret väljer du Standard för Hive-databaser>.
Högerklicka på standard och välj Skapa tabell.
Konfigurera tabellen.
Välj knappen Skapa tabell för att skicka jobbet, vilket skapar den nya Hive-tabellen.
Det finns två sätt att skapa och köra Hive-frågor:
- Skapa ad hoc-frågor
- Skapa ett Hive-program
Så här skapar och kör du en ad hoc-fråga:
Högerklicka på klustret där du vill köra frågan och välj Skriv en Hive-fråga.
Ange en Hive-fråga.
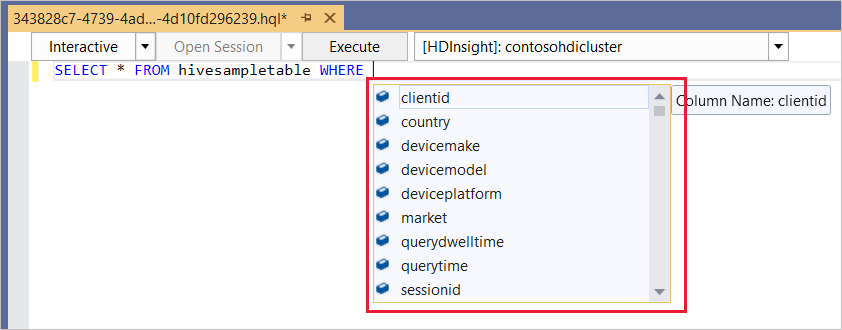
Hive-redigeraren stöder IntelliSense. Data Lake Tools för Visual Studio stöder inläsning av fjärrmetadata när du redigerar Hive-skript. Om du till exempel skriver
SELECT * FROMvisar IntelliSense alla föreslagna tabellnamn. När du anger ett tabellnamn visar IntelliSense en lista över kolumnnamnen. Verktygen stöder de flesta Hive DML-instruktioner, underfrågor och inbyggda UDF.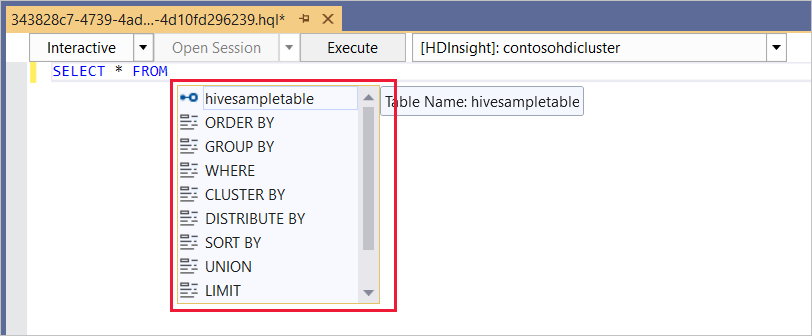
Anteckning
IntelliSense föreslår endast metadata för kluster som valts i verktygsfältet för HDInsight.
Här är en exempelfråga som du kan använda:
SELECT devicemodel, COUNT(devicemodel) AS deviceCount FROM hivesampletable GROUP BY devicemodel ORDER BY devicemodelVälj körningsläge:
Interaktiv
I den första listrutan väljer du Interaktiv och sedan Kör.

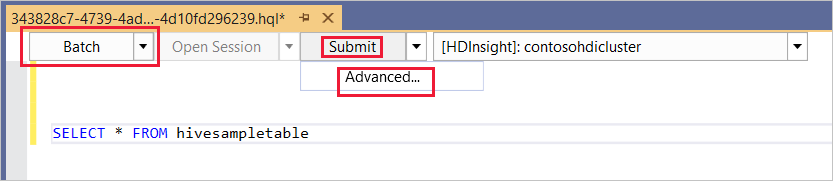
Batch
I den första listrutan väljer du Batch och sedan Skicka. Eller välj listrutan bredvid Skicka och välj Avancerat.
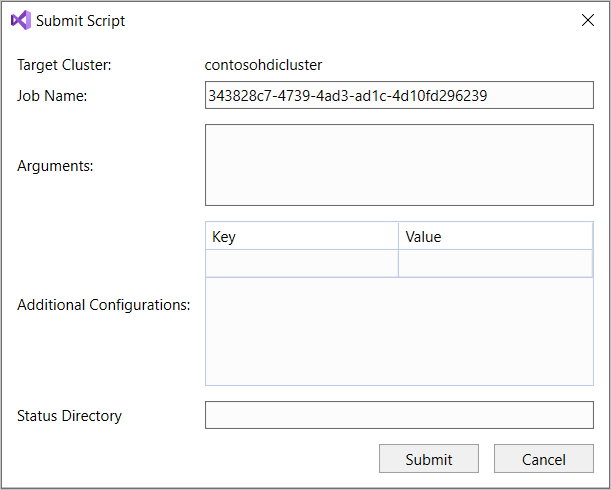
Om du väljer alternativet för avancerad sändning visas dialogrutan Skicka skript . Konfigurera jobbnamn, argument, ytterligare konfigurationer och statuskatalog för skriptet.
Anteckning
Du kan inte skicka batchar till Interaktiv fråga kluster. Du måste använda interaktivt läge.
Så här skapar och kör du en Hive-lösning:
I menyraden väljer du Arkiv>Nytt>projekt.
I fönstret Skapa ett nytt projekt väljer du sökrutan och skriver Hive. Välj sedan Hive-program och välj Nästa.
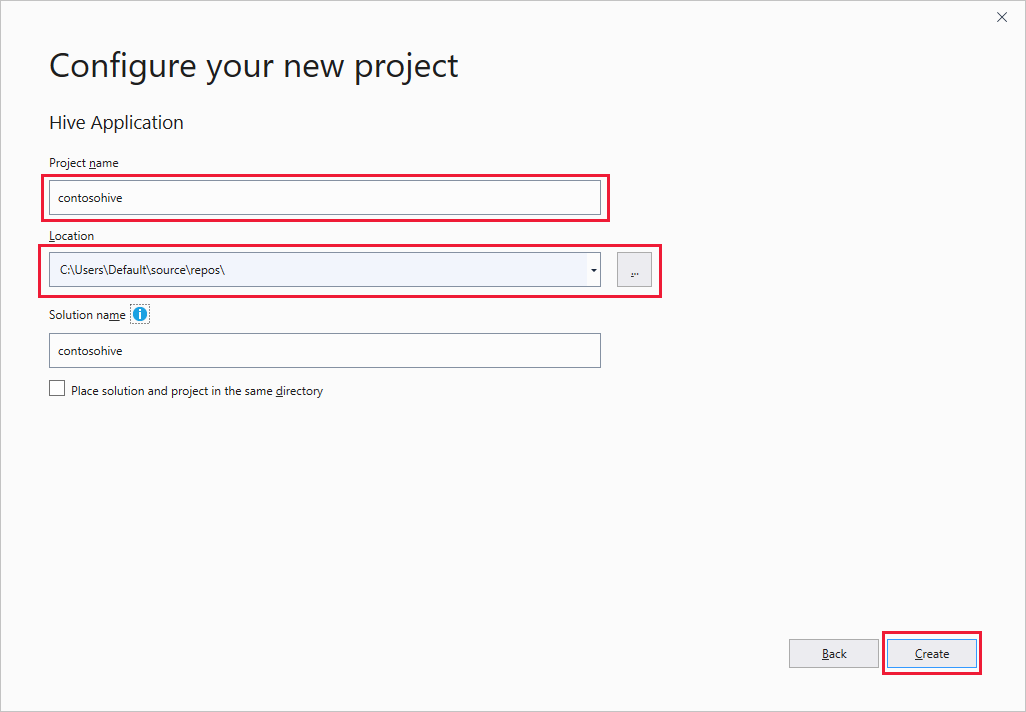
I fönstret Konfigurera det nya projektet anger du ett Projektnamn, väljer eller skapar projektet Plats och väljer sedan Skapa.
Gå till Solution Explorer och dubbelklicka på Script.hql för att öppna skriptet.
Jobbsammanfattningen varierar något mellan batch - och interaktivt läge.
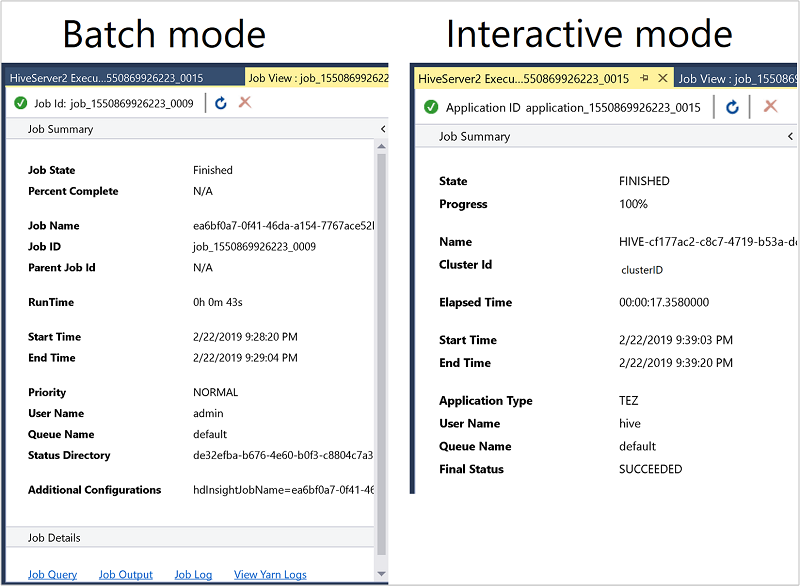
Använd uppdateringsikonen för att uppdatera statusen tills jobbstatusen ändras till Slutförd.
För jobbinformationen från Batch-läget väljer du länkarna längst ned för att se jobbfrågan, jobbutdata eller jobbloggen eller för att visa yarnloggar.
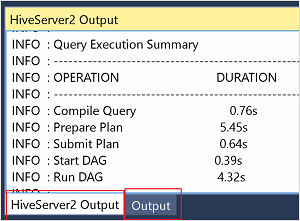
Information om jobb från interaktivt läge finns i fönstret Utdata och HiveServer2-utdata .
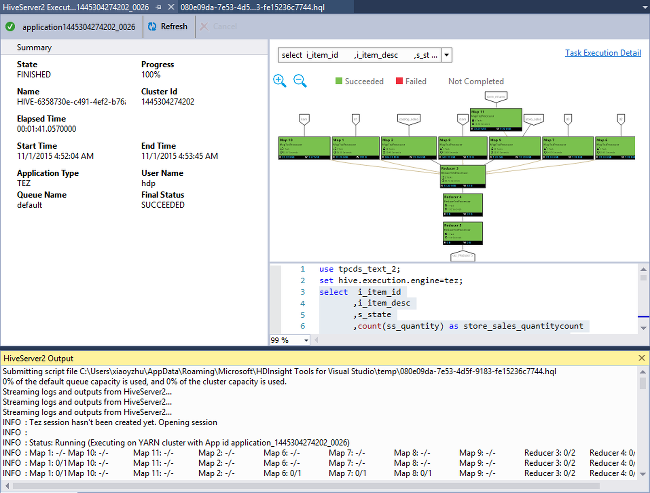
För närvarande visas jobbdiagram endast för Hive-jobb som använder Tez som körningsmotor. Information om hur du aktiverar Tez finns i Vad är Apache Hive och HiveQL på Azure HDInsight?. Se även Använda Apache Tez i stället för Kartreducering.
Om du vill visa alla operatorer i hörnen dubbelklickar du på hörnen i jobbdiagrammet. Du kan också peka på en specifik operator för att se mer information om den.
Även om Tez anges som körningsmotor kanske jobbdiagrammet inte visas om inget Tez-program startas. Den här situationen kan inträffa eftersom jobbet inte innehåller DML-instruktioner. Eller för att DML-uttrycken kan returneras utan att starta ett Tez-program. Till exempel SELECT * FROM table1 startar inte Tez-programmet.
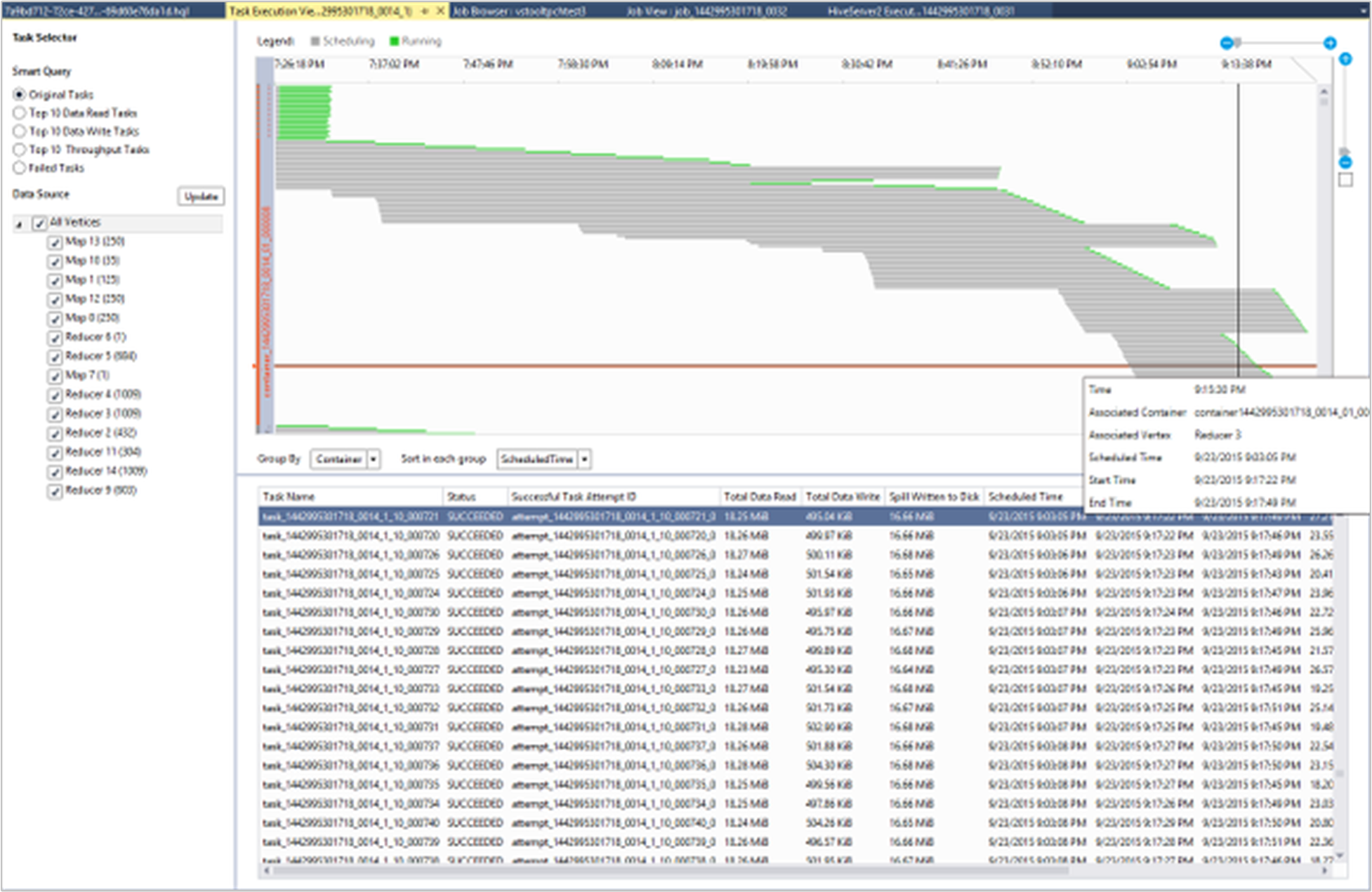
I jobbdiagrammet kan du välja Aktivitetskörningsinformation för att hämta strukturerad och visualiserad information för Hive-jobb. Du kan också få mer jobbinformation. Om det uppstår prestandaproblem kan du använda vyn för att få mer information om problemet. Du kan till exempel hämta information om hur varje aktivitet fungerar och detaljerad information om varje aktivitet (dataläsning/skrivning, schema/start/sluttid med mera). Använd informationen för att finjustera jobbkonfigurationer eller systemarkitektur baserat på den visualiserade informationen.
Du kan visa jobbfrågor, jobbutdata, jobbloggar och Yarn-loggar för Hive-jobb.
I den senaste versionen av verktygen kan du se vad som finns i dina Hive-jobb genom att samla in och visa Yarn-loggar. En Yarn-logg kan hjälpa dig att undersöka prestandaproblem. Mer information om hur HDInsight samlar in Yarn-loggar finns i Åtkomst till Apache Hadoop YARN-programloggar.
Så här visar du Hive-jobb:
Högerklicka på ett HDInsight-kluster och välj Visa jobb.
En lista visas över de Hive-jobb som körts på klustret.
Välj ett jobb. I fönstret Sammanfattning av Hive-jobb väljer du någon av följande länkar:
- Jobbfråga
- Jobbutdata
- Jobblogg
- Yarn-logg
I menyraden väljer du Arkiv>Nytt>projekt.
I startfönstret väljer du sökrutan och anger Pig. Välj sedan Pig Application (Grisprogram) och sedan Nästa.
I fönstret Konfigurera det nya projektet anger du ett projektnamn och väljer eller skapar en plats för projektet. Välj sedan Skapa.
I fönstret IDE Solution Explorer dubbelklickar du på Script.pig för att öppna skriptet.
Ett problem där resultat som har startats med null-värden inte visas har åtgärdats. Om du är blockerad för det här problemet kan du kontakta supportgruppen.
HQL-skriptet som Visual Studio skapar kodas, beroende på användarens lokala regioninställning. Skriptet kan inte köras korrekt om du laddar upp skriptet till ett kluster som en binär fil.
I den här artikeln har du lärt dig hur använder Data Lake Tools för Visual Studio för att ansluta till HDInsight-kluster från Visual Studio. Du har också lärt dig hur du kör en Hive-fråga.