Fallstudie om lösningsarkitektur med hög tillgänglighet i Azure HDInsight
Azure HDInsights replikeringsmekanismer kan integreras i en lösningsarkitektur med hög tillgänglighet. I den här artikeln används en fiktiv fallstudie för Contoso Retail för att förklara möjliga haveriberedskapsmetoder med hög tillgänglighet, kostnadsöverväganden och deras motsvarande design.
Rekommendationer för haveriberedskap med hög tillgänglighet kan ha många permutationer och kombinationer. Dessa lösningar ska uppnås efter att för- och nackdelarna med varje alternativ har övervägts. I den här artikeln beskrivs bara en möjlig lösning.
Kundarkitektur
Följande bild visar contoso Retails primära arkitektur. Arkitekturen består av en strömningsarbetsbelastning, en batcharbetsbelastning, ett serverlager, ett förbrukningslager, ett lagringslager och en versionskontroll.
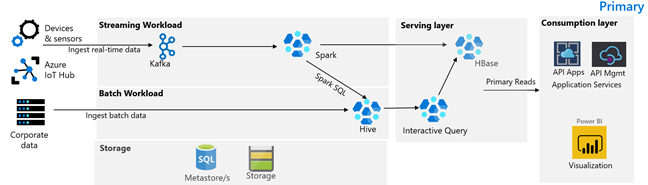
Strömningsarbetsbelastning
Enheter och sensorer producerar data till HDInsight Kafka, som utgör meddelanderamverket. En HDInsight Spark-konsument läser från Kafka Topics. Spark transformerar inkommande meddelanden och skriver det till ett HDInsight HBase-kluster på serveringsskiktet.
Batch-arbetsbelastning
Ett HDInsight Hadoop-kluster som kör Hive och MapReduce matar in data från lokala transaktionssystem. Rådata som transformeras av Hive och MapReduce lagras i Hive-tabeller på en logisk partition av datasjön som backas upp av Azure Data Lake Storage Gen2. Data som lagras i Hive-tabeller görs också tillgängliga för Spark SQL, som gör batchtransformeringar innan de kurerade data lagras i HBase för servering.
Betjänande lager
Ett HDInsight HBase-kluster med Apache Phoenix används för att hantera data till webbprogram och instrumentpaneler för visualisering. Ett HDInsight LLAP-kluster används för att uppfylla interna rapporteringskrav.
Förbrukningslager
Ett Azure API Apps- och API Management-lager på en offentlig webbsida. Interna rapporteringskrav uppfylls av Power BI.
Lagringslager
Logiskt partitionerad Azure Data Lake Storage Gen2 används som en företagsdatasjö. HDInsight-metaarkiven backas upp av Azure SQL DB.
System för versionskontroll
Ett versionskontrollsystem som är integrerat i en Azure Pipelines och som finns utanför Azure.
Krav på affärskontinuitet för kunder
Det är viktigt att fastställa den minimala affärsfunktion som du behöver om det uppstår en katastrof.
Contoso Retails krav på affärskontinuitet
- Vi måste skyddas mot ett regionalt fel eller ett regionalt servicehälsoproblem.
- Mina kunder får aldrig se ett 404-fel. Offentligt innehåll måste alltid hanteras. (RTO = 0)
- Under större delen av året kan vi visa offentligt innehåll som är inaktuellt med 5 timmar. (RPO = 5 timmar)
- Under semesterperioden måste vårt offentliga innehåll alltid vara uppdaterat. (RPO = 0)
- Mina interna rapporteringskrav anses inte vara viktiga för affärskontinuitet.
- Optimera kostnader för affärskontinuitet.
Föreslagen lösning
Följande bild visar Contoso Retails arkitektur för haveriberedskap med hög tillgänglighet.
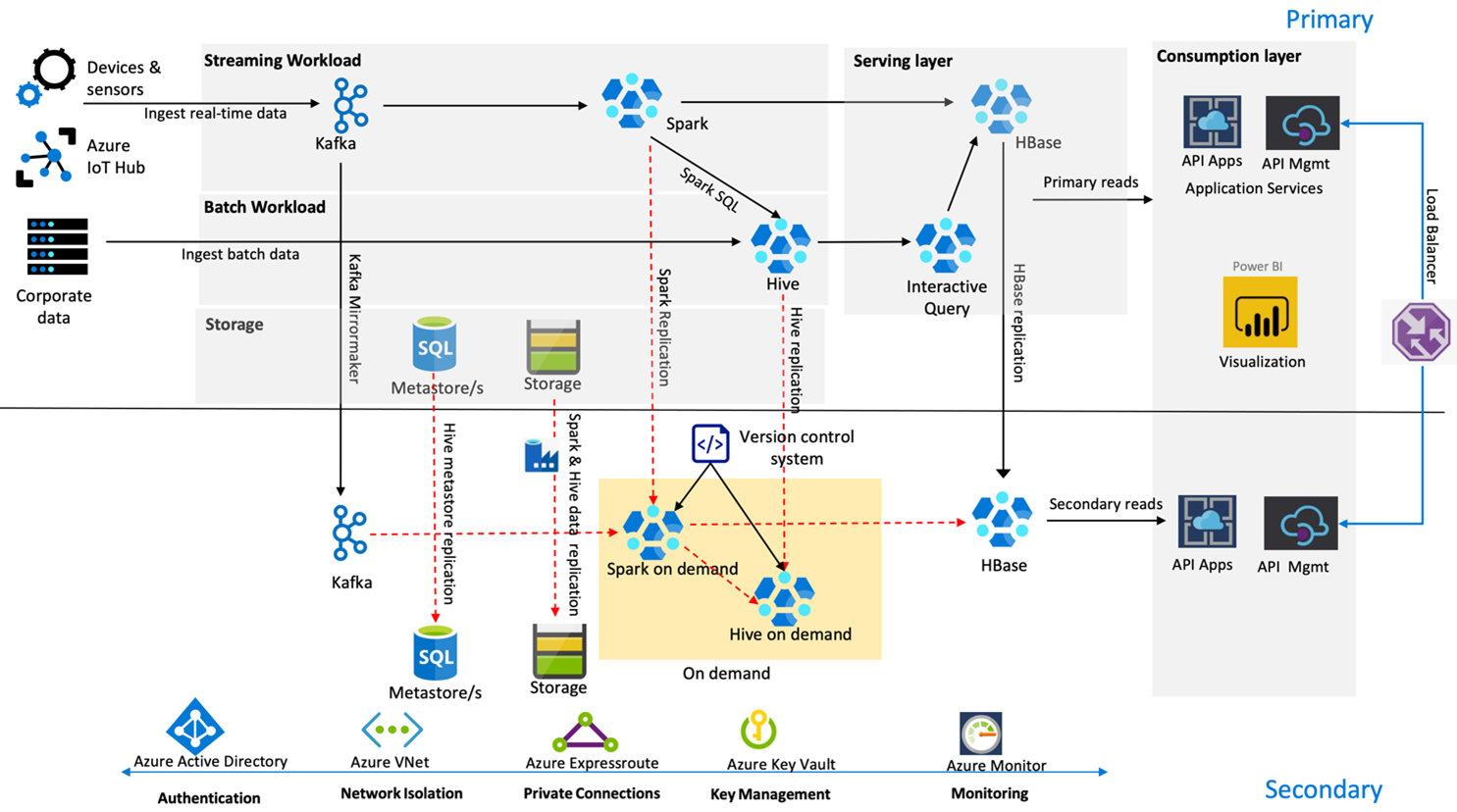
Kafka använder Aktiv – passiv replikering för att spegla Kafka-ämnen från den primära regionen till den sekundära regionen. Ett alternativ till Kafka-replikering kan vara att skapa till Kafka i båda regionerna.
Hive och Spark använder active primary – sekundära replikeringsmodeller på begäran under normala tider. Hive-replikeringsprocessen körs regelbundet och medföljer Hive Azure SQL-metaarkivet och Hive-lagringskontoreplikeringen. Spark-lagringskontot replikeras regelbundet med hjälp av ADF DistCP. De här klustrens tillfälliga karaktär hjälper till att optimera kostnaderna. Replikering schemaläggs var 4:e timme för att komma fram till ett RPO som ligger långt inom femtimmarskravet.
HBase-replikering använder modellen Leader – Follower under normala tider för att säkerställa att data alltid hanteras oavsett region och att RPO är mycket lågt.
Om det uppstår ett regionalt fel i den primära regionen hanteras webbsidan och serverdelsinnehållet från den sekundära regionen i 5 timmar med en viss grad av inaktuellhet. Om azure-tjänstens hälsoinstrumentpanel inte anger en återställnings-ETA i femtimmarsfönstret skapar Contoso Retail Hive- och Spark-transformeringslagret i den sekundära regionen och pekar sedan alla överordnade datakällor till den sekundära regionen. Att göra den sekundära regionen skrivbar skulle orsaka en återställningsprocess som omfattar replikering tillbaka till den primära regionen.
Under en hög shoppingsäsong är hela den sekundära pipelinen alltid aktiv och körs. Kafka-producenter producerar till båda regionerna och HBase-replikeringen skulle ändras från Leader-Follower till Leader-Leader för att säkerställa att offentligt innehåll alltid är uppdaterat.
Ingen redundanslösning behöver utformas för intern rapportering eftersom den inte är viktig för affärskontinuitet.
Nästa steg
Mer information om de objekt som beskrivs i den här artikeln finns i:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för