Arkitekturer för affärskontinuitet i Azure HDInsight
Den här artikeln innehåller några exempel på arkitekturer för affärskontinuitet som du kan överväga för Azure HDInsight. Tolerans för nedsatt funktionalitet under en katastrof är ett affärsbeslut som varierar från ett program till ett annat. Det kan vara acceptabelt för vissa program att vara otillgängliga eller delvis tillgängliga med nedsatt funktionalitet eller fördröjd bearbetning under en period. För andra program kan alla nedsatta funktioner vara oacceptabla.
Kommentar
Arkitekturerna som presenteras i den här artikeln är inte på något sätt uttömmande. Du bör utforma dina egna unika arkitekturer när du har gjort objektiva beslut kring förväntad affärskontinuitet, driftkomplexitet och ägandekostnad.
Apache Hive och Interaktiv fråga
Hive Replication V2 rekommenderas för affärskontinuitet i HDInsight Hive och interaktiva frågekluster. De beständiga avsnitten i ett fristående Hive-kluster som måste replikeras är lagringslagret och Hive-metaarkivet. Hive-kluster i ett scenario med flera användare med Enterprise Security Package behöver Microsoft Entra Domain Services och Ranger Metastore.
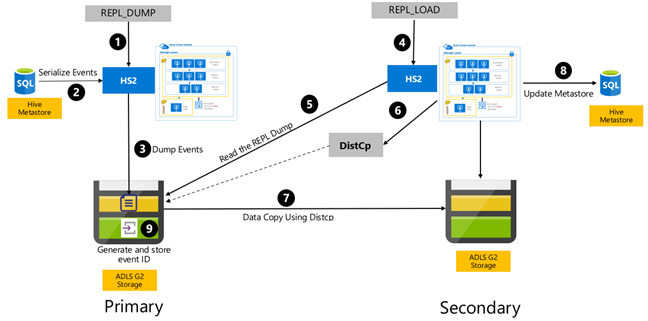
Hive-händelsebaserad replikering konfigureras mellan de primära och sekundära klustren. Detta består av två distinkta faser, bootstrapping och inkrementella körningar:
Bootstrapping replikerar hela Hive-lagret, inklusive Hive-metaarkivinformationen från primär till sekundär.
Inkrementella körningar automatiseras i det primära klustret och de händelser som genereras under de inkrementella körningarna spelas upp på det sekundära klustret. Det sekundära klustret kommer ikapp de händelser som genereras från det primära klustret, vilket säkerställer att det sekundära klustret är konsekvent med det primära klustrets händelser efter replikeringskörningen.
Det sekundära klustret behövs bara vid tidpunkten för replikeringen för att köra distribuerad kopia, DistCp, men lagrings- och metaarkiven måste vara beständiga. Du kan välja att starta ett skriptbaserat sekundärt kluster på begäran före replikering, köra replikeringsskriptet på det och sedan riva ned det efter lyckad replikering.
Det sekundära klustret är vanligtvis skrivskyddat. Du kan göra det sekundära klustret skrivskyddat, men det ger ytterligare komplexitet som innebär att ändringarna replikeras från det sekundära klustret till det primära klustret.
Hive-händelsebaserad replikerings-RPO och RTO
RPO: Dataförlust är begränsad till den senaste lyckade inkrementella replikeringshändelsen från primär till sekundär.
RTO: Tiden mellan felet och återupptagandet av uppströms- och nedströmstransaktioner med den sekundära.
Apache Hive- och Interaktiv fråga-arkitekturer
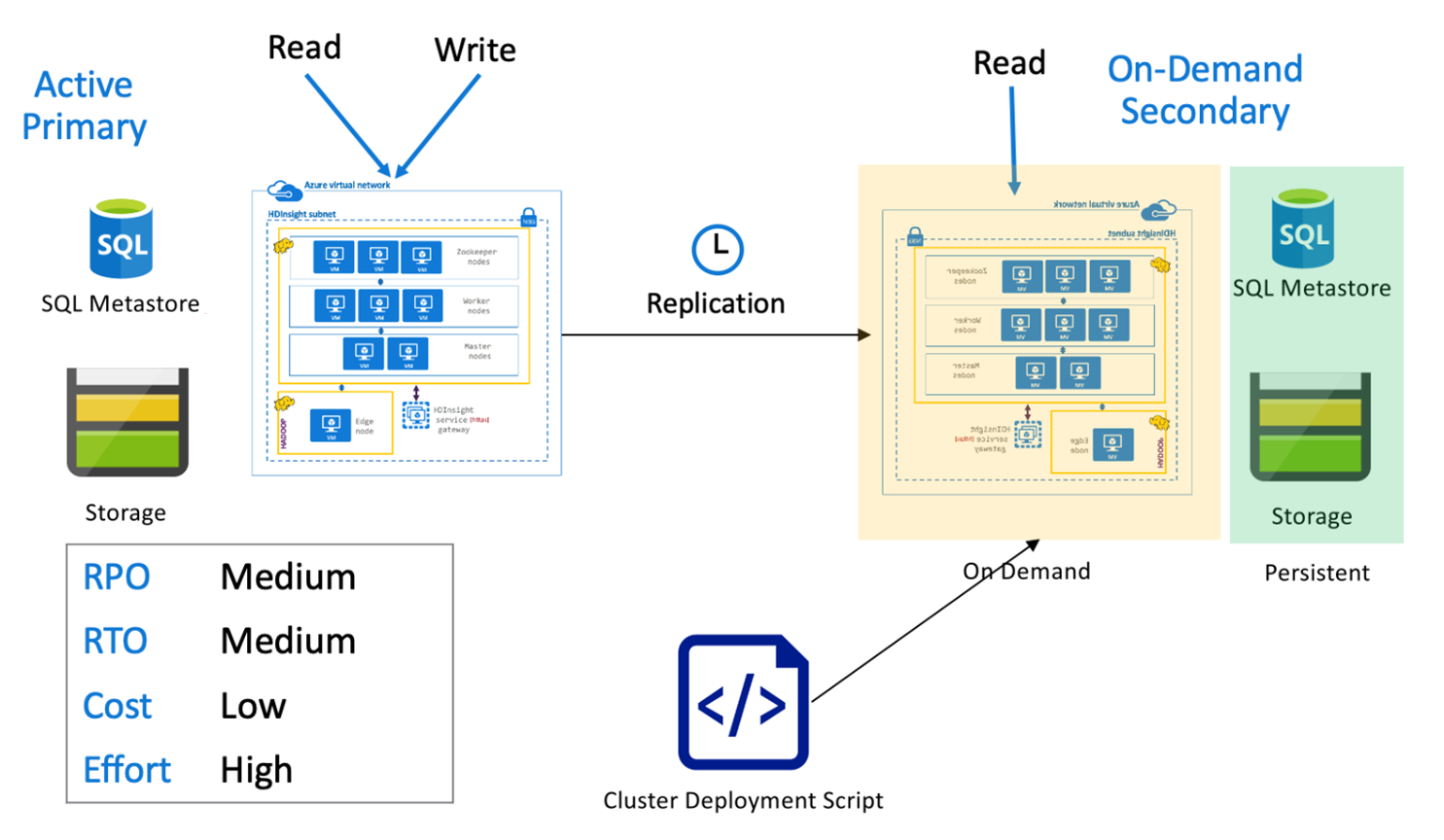
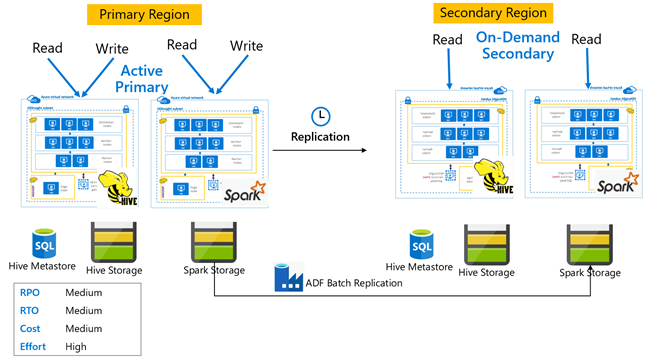
Hive-aktiv primär med sekundär på begäran
I en aktiv primär med sekundär arkitektur på begäran skriver program till den aktiva primära regionen medan inget kluster etableras i den sekundära regionen under normala åtgärder. SQL Metastore och Storage i den sekundära regionen är beständiga, medan HDInsight-klustret skriptas och distribueras endast på begäran innan den schemalagda Hive-replikeringen körs.
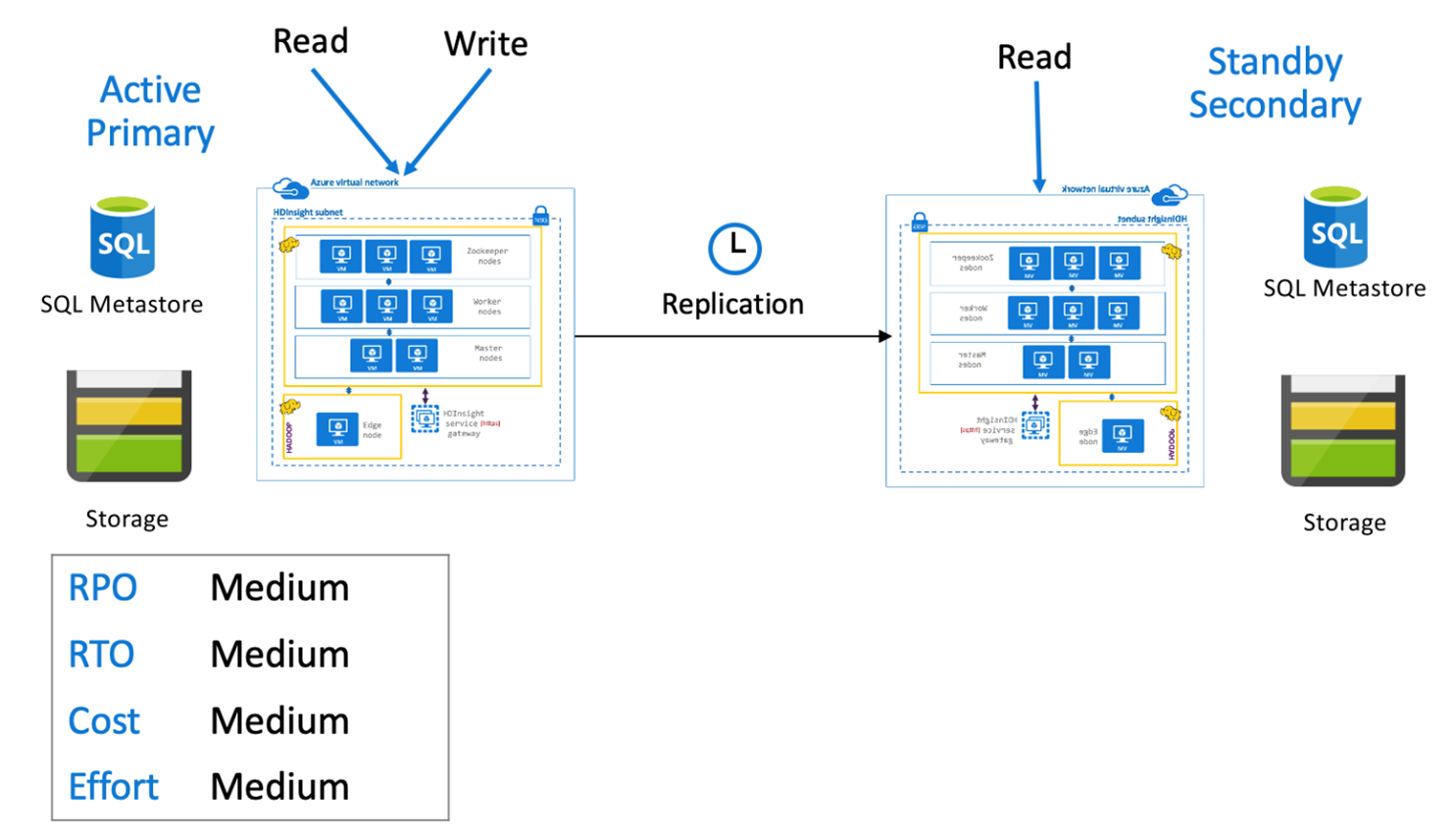
Hive-aktiv primär med sekundär vänteläge
I en aktiv primär med vänteläge sekundärt skriver program till den aktiva primära regionen medan ett vänteläge skalas ned sekundärt kluster i skrivskyddat läge körs under normala åtgärder. Under normala åtgärder kan du välja att avlasta regionspecifika läsåtgärder till sekundära.
Mer information om Hive-replikering och kodexempel finns i Apache Hive-replikering i Azure HDInsight-kluster
Apache Spark
Spark-arbetsbelastningar kan innehålla en Hive-komponent. För att göra det möjligt för Spark SQL-arbetsbelastningar att läsa och skriva data från Hive delar HDInsight Spark-kluster anpassade Hive-metaarkiv från Hive/Interaktiva frågekluster i samma region. I sådana scenarier måste replikering mellan regioner av Spark-arbetsbelastningar också åtfölja replikeringen av Hive-metaarkiv och lagring. Redundansscenarierna i det här avsnittet gäller för båda:
- Spark SQL på ACID-tabeller med hive Warehouse Anslut or(HWC) med hjälp av ett HDInsight-Interaktiv fråga kluster.
- Spark SQL-arbetsbelastning på icke-ACID-tabeller med hjälp av ett HDInsight Hadoop-kluster.
För scenarier där Spark fungerar i fristående läge måste kurerade data och lagrade Spark Jars (för Livy-jobb) replikeras från den primära regionen till den sekundära regionen regelbundet med hjälp av Azure Data Factorys DistCP.
Vi rekommenderar att du använder versionskontrollsystem för att lagra Spark-notebook-filer och bibliotek där de enkelt kan distribueras i primära eller sekundära kluster. Se till att notebook-baserade och icke-notebook-baserade lösningar är beredda att läsa in rätt datamonteringar på den primära eller sekundära arbetsytan.
Om det finns kundspecifika bibliotek som ligger utanför vad HDInsight tillhandahåller internt, måste de spåras och regelbundet läsas in i det sekundära väntelägesklustret.
Apache Spark-replikerings-RPO och RTO
RPO: Dataförlusten är begränsad till den senaste lyckade inkrementella replikeringen (Spark och Hive) från primär till sekundär.
RTO: Tiden mellan felet och återupptagandet av uppströms- och nedströmstransaktioner med den sekundära.
Apache Spark-arkitekturer
Spark-aktiv primär med sekundär på begäran
Program läser och skriver till Spark- och Hive-kluster i den primära regionen medan inga kluster etableras i den sekundära regionen under normala åtgärder. SQL Metastore, Hive Storage och Spark Storage är beständiga i den sekundära regionen. Spark- och Hive-klustren skriptas och distribueras på begäran. Hive-replikering används för att replikera Hive Storage- och Hive-metaarkiv medan Azure Data Factory kan DistCP användas för att kopiera fristående Spark-lagring. Hive-kluster måste distribueras innan varje Hive-replikering körs på grund av beroendeberäkningen DistCp .
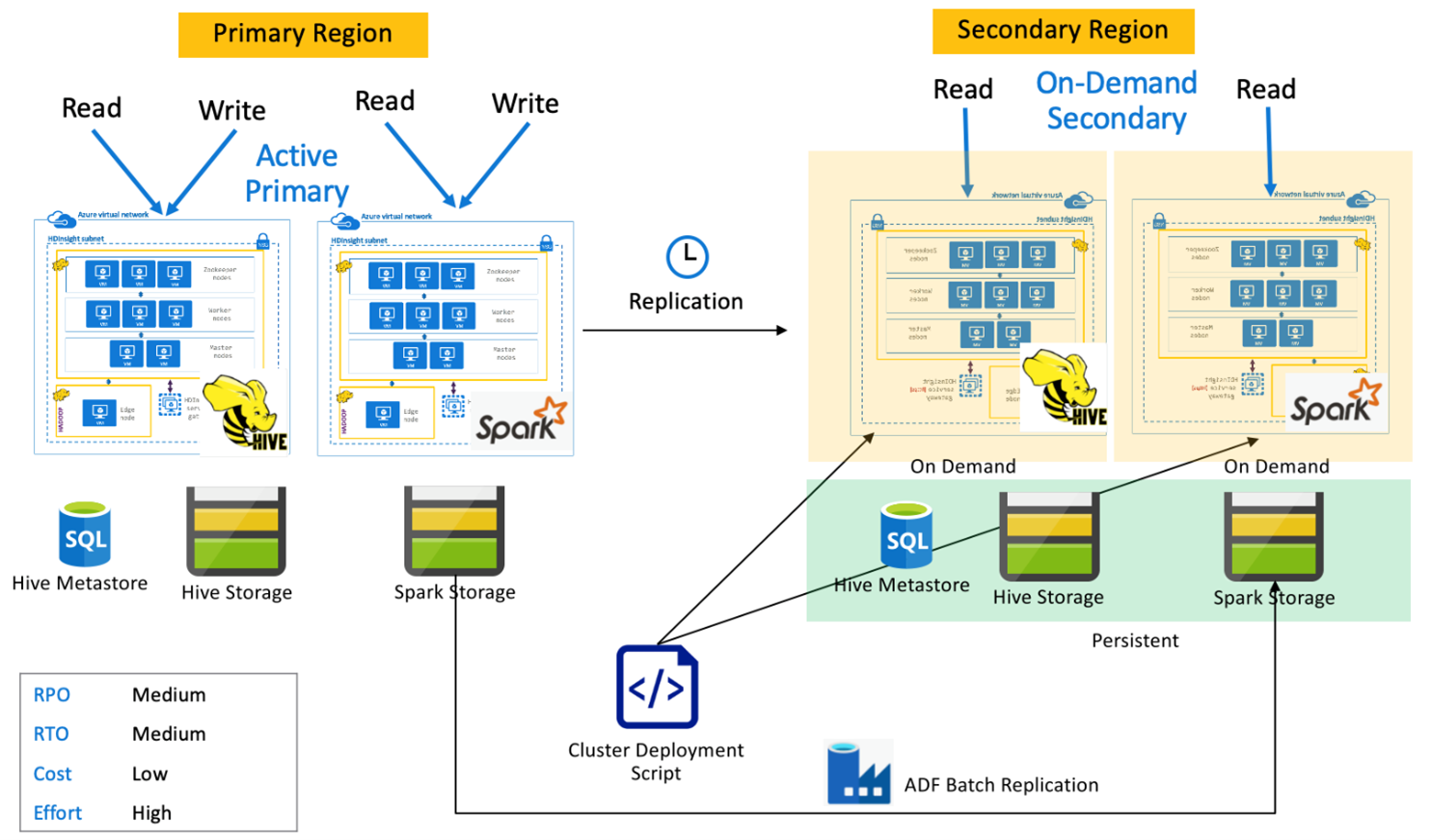
Spark-aktiv primär med sekundär vänteläge
Program läser och skriver till Spark- och Hive-kluster i den primära regionen medan nedskalade Hive- och Spark-kluster i skrivskyddat läge körs i sekundär region under normala åtgärder. Under normala åtgärder kan du välja att avlasta regionspecifika Hive- och Spark-läsåtgärder till sekundära.
Apache HBase
HBase Export och HBase Replication är vanliga sätt att möjliggöra affärskontinuitet mellan HDInsight HBase-kluster.
HBase Export är en batchreplikeringsprocess som använder HBase Export Utility för att exportera tabeller från det primära HBase-klustret till dess underliggande Azure Data Lake Storage Gen 2-lagring. Exporterade data kan sedan nås från det sekundära HBase-klustret och importeras till tabeller som måste finnas i det sekundära. HBase Export erbjuder kornighet på tabellnivå, men i inkrementella uppdateringssituationer styr exportautomatiseringsmotorn intervallet för inkrementella rader som ska inkluderas i varje körning. Mer information finns i HDInsight HBase Backup och Replication.
HBase Replication använder replikering i nära realtid mellan HBase-kluster på ett helt automatiserat sätt. Replikeringen görs på tabellnivå. Antingen kan alla tabeller eller specifika tabeller riktas mot replikering. HBase-replikering är så småningom konsekvent, vilket innebär att de senaste redigeringarna till en tabell i den primära regionen kanske inte är tillgängliga för alla sekundärfiler omedelbart. Sekundärfiler kommer garanterat att så småningom bli konsekventa med den primära. HBase-replikering kan konfigureras mellan två eller flera HDInsight HBase-kluster om:
- Primära och sekundära finns i samma virtuella nätverk.
- Primära och sekundära finns i olika peer-kopplade virtuella nätverk i samma region.
- Primära och sekundära finns i olika peer-kopplade virtuella nätverk i olika regioner.
Mer information finns i Konfigurera Apache HBase-klusterreplikering i virtuella Azure-nätverk.
Det finns några andra sätt att utföra säkerhetskopior av HBase-kluster som att kopiera hbase-mappen, kopiera tabeller och ögonblicksbilder.
HBase RPO och RTO
HBase-export
- RPO: Dataförlust begränsas till den senaste lyckade batchens inkrementella import av den sekundära från den primära.
- RTO: Tiden mellan det primära felet och återupptagandet av I/O-åtgärder på den sekundära.
HBase-replikering
- RPO: Dataförlust är begränsad till den senaste WalEdit-leveransen som togs emot på den sekundära.
- RTO: Tiden mellan det primära felet och återupptagandet av I/O-åtgärder på den sekundära.
HBase-arkitekturer
HBase-replikering kan konfigureras i tre lägen: Leader-Follower, Leader-Leader och Cyclic.
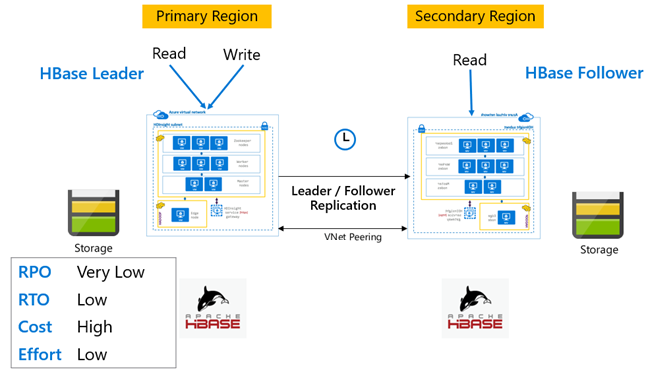
HBase Replication: Leader – Follower model
I den här konfigurationen mellan regioner är replikeringen enkelriktad från den primära regionen till den sekundära regionen. Antingen kan alla tabeller eller specifika tabeller i den primära identifieras för enkelriktad replikering. Under normala åtgärder kan det sekundära klustret användas för att hantera läsbegäranden i den egna regionen.
Det sekundära klustret fungerar som ett normalt HBase-kluster som kan vara värd för sina egna tabeller och som kan hantera läsningar och skrivningar från regionala program. Skrivningar på de replikerade tabellerna eller tabellerna som är inbyggda i sekundärt replikeras dock inte tillbaka till den primära.
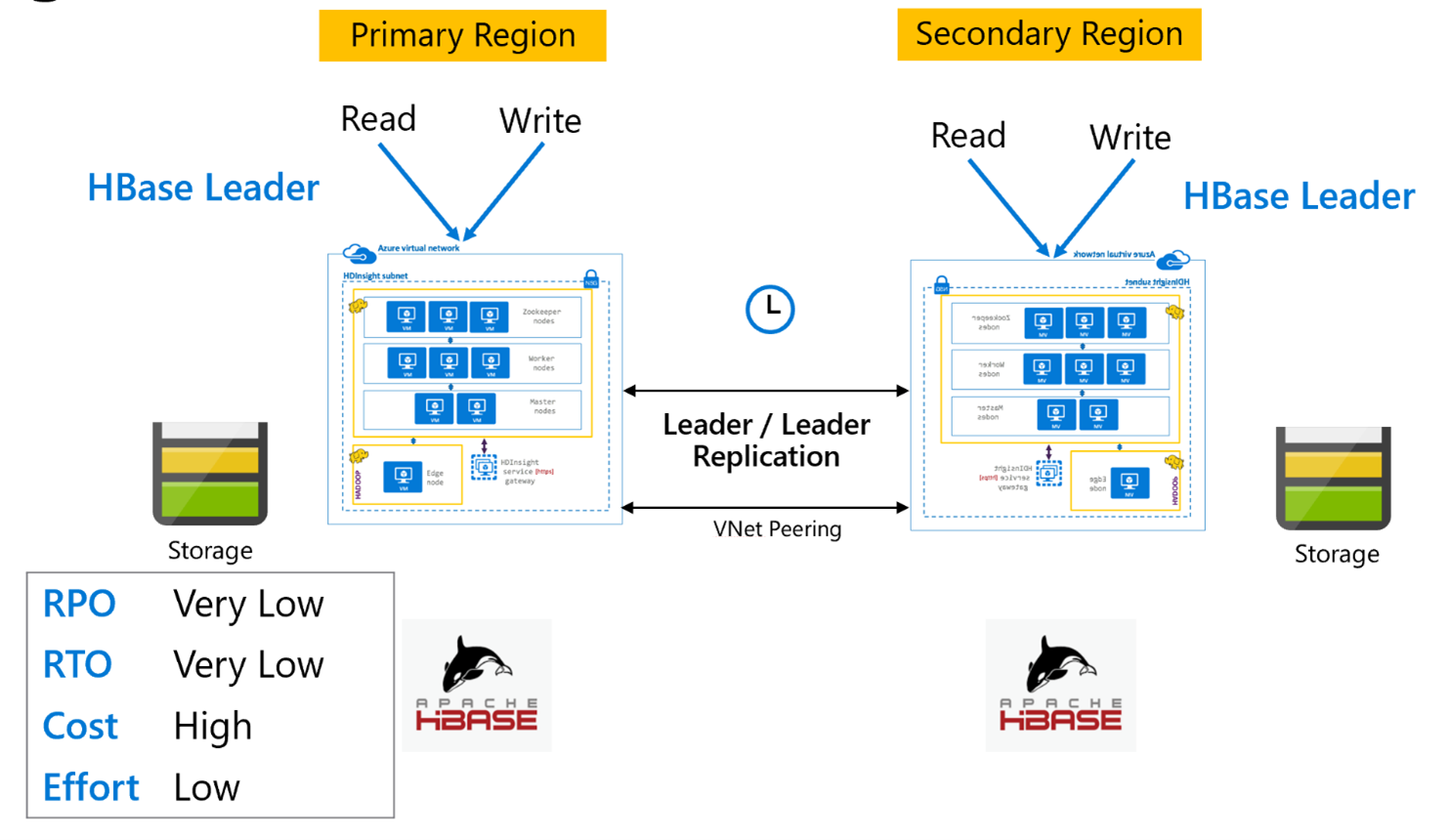
HBase Replication: Leader – Leader-modell
Den här konfigurationen mellan regioner liknar den enkelriktade konfigurationen, förutom att replikeringen sker dubbelriktat mellan den primära regionen och den sekundära regionen. Program kan använda båda kluster i läs- och skrivlägen och uppdateringar byts asynkront mellan dem.
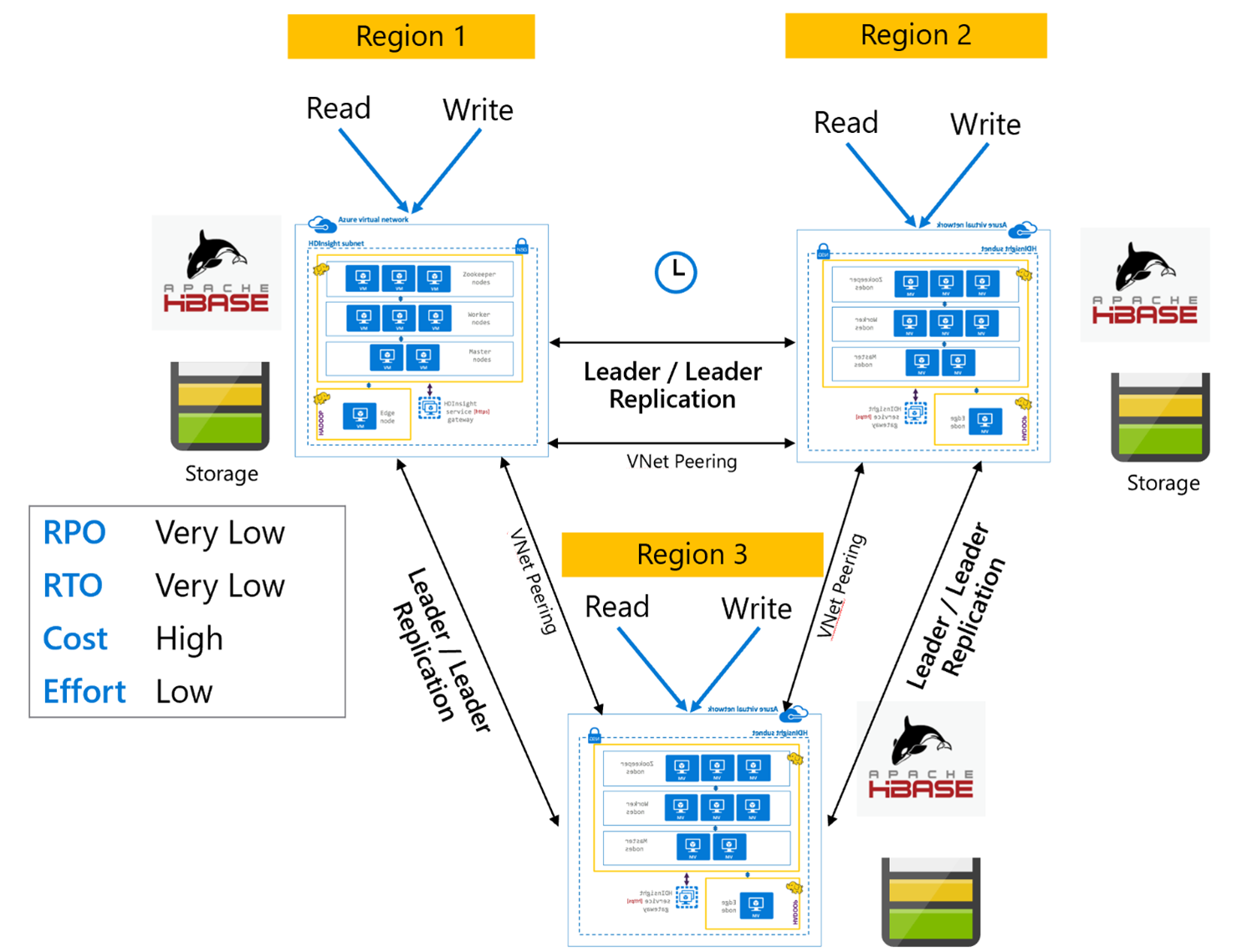
HBase-replikering: Flera regioner eller cykliska
Replikeringsmodellen för flera regioner/cykliska är ett tillägg för HBase Replication och kan användas för att skapa en globalt redundant HBase-arkitektur med flera program som läser och skriver till regionspecifika HBase-kluster. Klustren kan konfigureras i olika kombinationer av Leader/Leader eller Leader/Follower beroende på affärskrav.
Apache Kafka
För att aktivera tillgänglighet mellan regioner stöder HDInsight 4.0 Kafka MirrorMaker som kan användas för att underhålla en sekundär replik av det primära Kafka-klustret i en annan region. MirrorMaker fungerar som ett konsumentproducentpar på hög nivå, förbrukar från ett specifikt ämne i det primära klustret och producerar till ett ämne med samma namn i det sekundära. Korsklusterreplikering för haveriberedskap med hög tillgänglighet med MirrorMaker förutsätter att producenter och konsumenter behöver redundansväxla till replikklustret. Mer information finns i Använda MirrorMaker för att replikera Apache Kafka-ämnen med Kafka i HDInsight
Beroende på ämnets livslängd när replikeringen startade kan MirrorMaker-ämnesreplikering leda till olika förskjutningar mellan käll- och replikämnen. HDInsight Kafka-kluster stöder även replikering av ämnespartitioner, vilket är en funktion med hög tillgänglighet på enskild klusternivå.
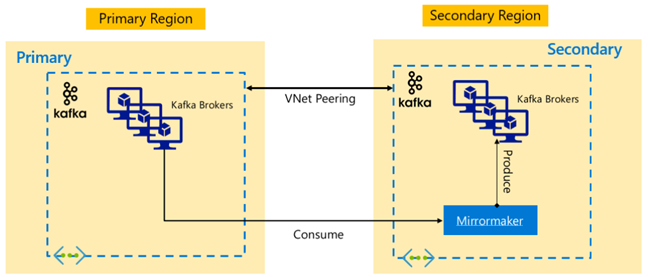
Apache Kafka-arkitekturer
Kafka-replikering: Aktiv – passiv
Aktiv-passiv konfiguration möjliggör asynkron enkelriktad spegling från Aktiv till Passiv. Producenter och konsumenter måste vara medvetna om att det finns ett aktivt och passivt kluster och måste vara redo att redundansväxla till passiva om aktivet misslyckas. Nedan visas några fördelar och nackdelar med aktiv-passiv konfiguration.
Fördelar:
- Nätverksfördröjning mellan kluster påverkar inte det aktiva klustrets prestanda.
- Enkelhet i enkelriktad replikering.
Nackdelar:
- Det passiva klustret kan förbli underutnyttjert.
- Utforma komplexiteten i att införliva redundansmedvetenhet hos programproducenter och konsumenter.
- Möjlig dataförlust vid fel i det aktiva klustret.
- Slutlig konsekvens mellan ämnen mellan aktiva och passiva kluster.
- Återställning efter fel till Primär kan leda till inkonsekvens i meddelanden i ämnen.
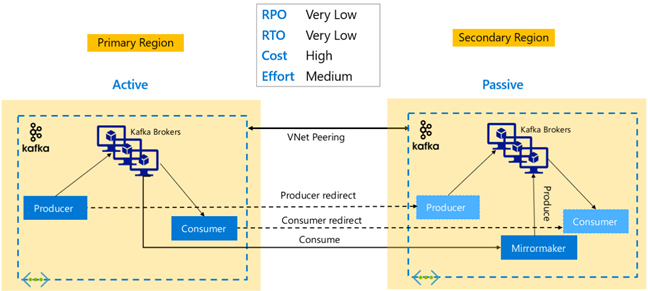
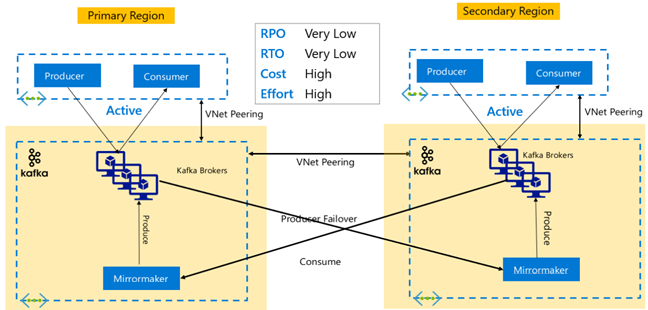
Kafka-replikering: Aktiv – Aktiv
Aktiv-aktiv konfiguration omfattar två regionalt avgränsade, VNet-peerkopplade HDInsight Kafka-kluster med dubbelriktad asynkron replikering med MirrorMaker. I den här designen görs meddelanden som förbrukas av konsumenterna i den primära också tillgängliga för konsumenter i sekundärt och vice versa. Nedan visas några fördelar och nackdelar med aktiv-aktiv-konfiguration.
Fördelar:
- På grund av deras duplicerade tillstånd är redundansväxlingar och återställningar enklare att köra.
Nackdelar:
- Konfiguration, hantering och övervakning är mer komplext än Aktiv-passiv.
- Problemet med cirkulär replikering måste åtgärdas.
- Dubbelriktad replikering leder till högre kostnader för regionala datautgående data.
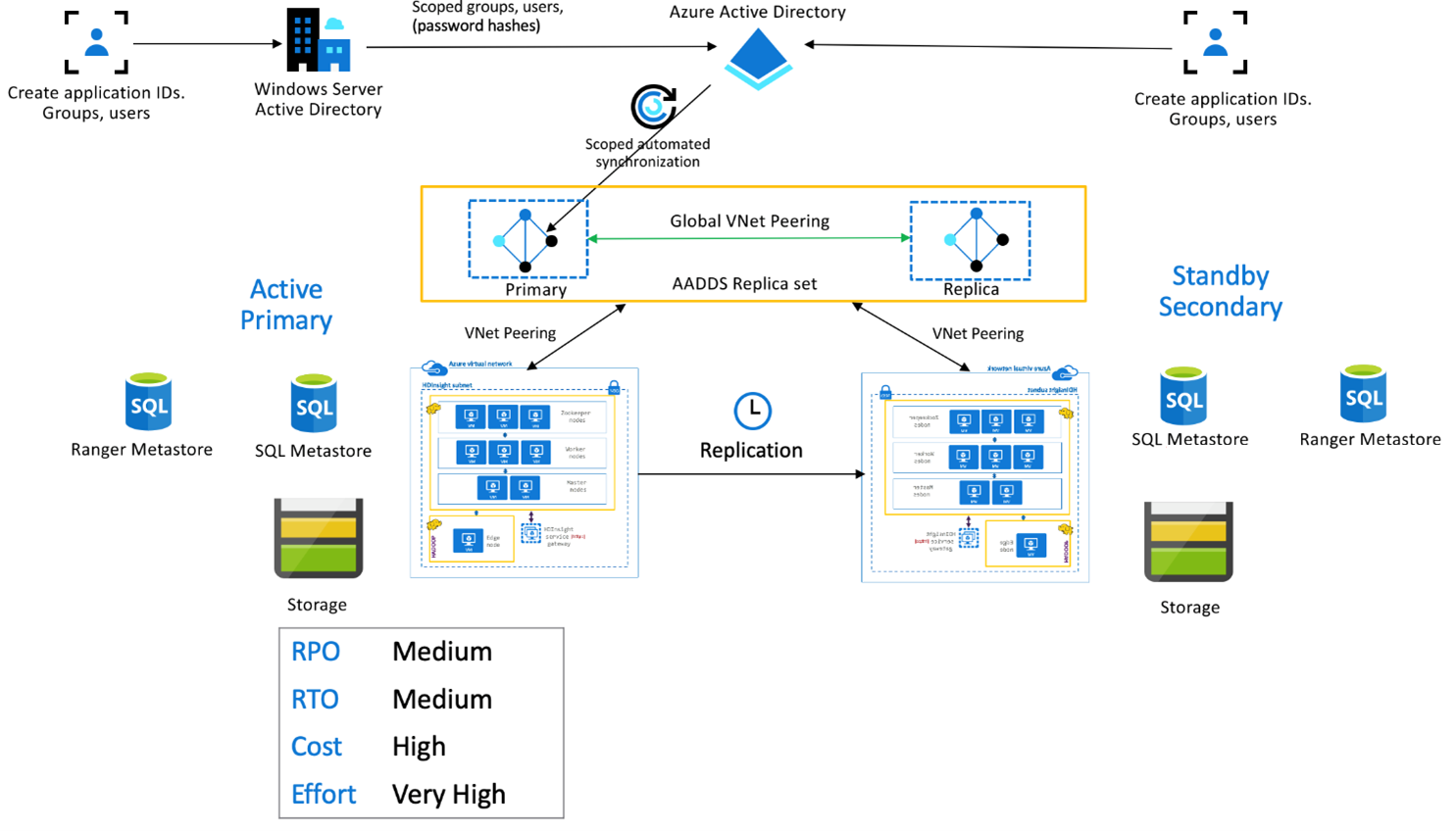
HDInsight Enterprise-säkerhetspaket
Den här konfigurationen används för att aktivera funktioner för flera användare i både primära och sekundära, samt Replikeringsuppsättningar för Microsoft Entra Domain Services för att säkerställa att användarna kan autentisera till båda klustren. Under normala åtgärder måste Ranger-principer konfigureras i den sekundära för att säkerställa att användarna är begränsade till läsåtgärder. Arkitekturen nedan förklarar hur en ESP-aktiverad Hive Active Primary – Standby Secondary-konfiguration kan se ut.
Ranger Metastore-replikering:
Ranger Metastore används för att beständigt lagra och hantera Ranger-principer för att kontrollera dataauktorisering. Vi rekommenderar att du underhåller oberoende Ranger-principer i primär och sekundär och underhåller den sekundära som en läsreplik.
Om kravet är att hålla Ranger-principer synkroniserade mellan primära och sekundära använder du Ranger Import/Export för att regelbundet säkerhetskopiera och importera Ranger-principer från primär till sekundär.
Replikering av Ranger-principer mellan primär och sekundär kan leda till att sekundären blir skrivaktiverad, vilket kan leda till oavsiktliga skrivningar på sekundären som leder till datainkonsekvenser.
Nästa steg
Mer information om de objekt som beskrivs i den här artikeln finns i: