Maskininlärningsregister för MLOps
Den här artikeln beskriver hur Azure Machine Learning-register frikopplar maskininlärningstillgångar från arbetsytor, så att du kan använda MLOps i utvecklings-, testnings- och produktionsmiljöer. Dina miljöer kan variera beroende på komplexiteten i dina IT-system. Följande faktorer påverkar antalet och typen av miljöer som du behöver:
- Säkerhets- och efterlevnadsprinciper. Produktionsmiljöer kan behöva isoleras från utvecklingsmiljöer när det gäller åtkomstkontroller, nätverksarkitektur och dataexponering.
- Prenumerationer. Utvecklingsmiljöer och produktionsmiljöer använder ofta separata prenumerationer för fakturering, budgetering och kostnadshantering.
- Regioner. Du kan behöva distribuera till olika Azure-regioner för att stödja svarstider och redundanskrav.
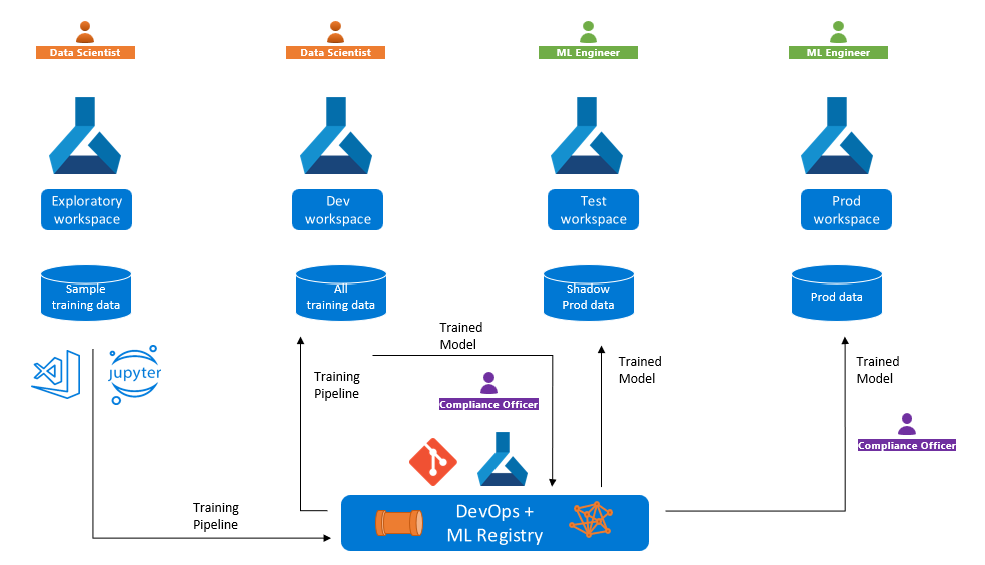
I föregående scenarier kan du använda olika Azure Machine Learning-arbetsytor för utveckling, testning och produktion. Den här konfigurationen utgör följande potentiella utmaningar för modellträning och distribution:
Du kan behöva träna en modell på en utvecklingsarbetsyta, men distribuera den till en slutpunkt på en produktionsarbetsyta, eventuellt i en annan Azure-prenumeration eller region. I det här fallet måste du kunna spåra träningsjobbet. Om du till exempel stöter på noggrannhets- eller prestandaproblem med produktionsdistributionen måste du analysera de mått, loggar, kod, miljö och data som du använde för att träna modellen.
Du kan behöva utveckla en träningspipeline med testdata eller anonymiserade data på arbetsytan utveckling, men träna om modellen med produktionsdata på produktionsarbetsytan. I det här fallet kan du behöva jämföra träningsmått på exempeldata jämfört med produktionsdata för att säkerställa att träningsoptimeringarna fungerar bra med faktiska data.
MLOps för flera arbetsytor med register
Ett register, ungefär som en Git-lagringsplats, frikopplar maskininlärningstillgångar från arbetsytor och är värd för tillgångarna på en central plats, vilket gör dem tillgängliga för alla arbetsytor i din organisation. Du kan använda register för att lagra och dela tillgångar som modeller, miljöer, komponenter och datauppsättningar.
För att främja modeller i utvecklings-, test- och produktionsmiljöer kan du börja med att iterativt utveckla en modell i utvecklingsmiljön. När du har en bra kandidatmodell kan du publicera den i ett register. Du kan sedan distribuera modellen från registret till slutpunkter på olika arbetsytor.
Dricks
Om du redan har modeller registrerade på en arbetsyta kan du flytta upp modellerna till ett register. Du kan också registrera en modell direkt i ett register från utdata från ett träningsjobb.
Om du vill utveckla en pipeline på en arbetsyta och sedan köra den på andra arbetsytor börjar du med att registrera de komponenter och miljöer som utgör byggstenarna i pipelinen. När du skickar pipelinejobbet avgör beräknings- och träningsdata, som är unika för varje arbetsyta, vilken arbetsyta som ska köras.
Följande diagram visar befordran av träningspipelines mellan undersökande arbetsytor och utvecklingsarbetsytor och sedan tränad modellhöjning för testning och produktion.