Dela modeller, komponenter och miljöer mellan arbetsytor med register
Med Azure Machine Learning-registret kan du samarbeta mellan arbetsytor i din organisation. Med hjälp av register kan du dela modeller, komponenter och miljöer.
Det finns två scenarier där du vill använda samma uppsättning modeller, komponenter och miljöer på flera arbetsytor:
-
MLOps för flera arbetsytor: Du tränar en modell på en
devarbetsyta och behöver distribuera den tilltestochprodarbetsytor. I det här fallet vill du ha ursprung från slutpunkt till slutpunkt mellan slutpunkter som modellen distribuerastesttill ellerprodarbetsytor och träningsjobbet, mått, kod, data och miljö som användes för att träna modellen pådevarbetsytan. - Dela och återanvända modeller och pipelines i olika team: Delning och återanvändning förbättrar samarbete och produktivitet. I det här scenariot kanske du vill publicera en tränad modell och de associerade komponenter och miljöer som används för att träna den till en central katalog. Därifrån kan kollegor från andra team söka efter och återanvända de tillgångar som du delade i sina egna experiment.
I den här artikeln får du lära dig att:
- Skapa en miljö och komponent i registret.
- Använd komponenten från registret för att skicka ett modellträningsjobb på en arbetsyta.
- Registrera den tränade modellen i registret.
- Distribuera modellen från registret till en onlineslutpunkt på arbetsytan och skicka sedan en slutsatsdragningsbegäran.
Förutsättningar
Innan du följer stegen i den här artikeln kontrollerar du att du har följande förutsättningar:
- En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning.
Ett Azure Machine Learning-register för att dela modeller, komponenter och miljöer. Information om hur du skapar ett register finns i Lär dig hur du skapar ett register.
En Azure Machine Learning-arbetsyta. Om du inte har någon använder du stegen i artikeln Snabbstart: Skapa arbetsyteresurser för att skapa en.
Viktigt!
Den Azure-region (plats) där du skapar din arbetsyta måste finnas i listan över regioner som stöds för Azure Machine Learning-registret
Azure CLI och
mltillägget eller Azure Machine Learning Python SDK v2:Information om hur du installerar Azure CLI och tillägget finns i Installera, konfigurera och använda CLI (v2).
Viktigt!
CLI-exemplen i den här artikeln förutsätter att du använder Bash-gränssnittet (eller det kompatibla). Till exempel från ett Linux-system eller Windows-undersystem för Linux.
Exemplen förutsätter också att du har konfigurerat standardvärden för Azure CLI så att du inte behöver ange parametrarna för din prenumeration, arbetsyta, resursgrupp eller plats. Om du vill ange standardinställningar använder du följande kommandon. Ersätt följande parametrar med värdena för konfigurationen:
- Ersätt
<subscription>med ditt Azure-prenumerations-ID. - Ersätt
<workspace>med namnet på din Azure Machine Learning-arbetsyta. - Ersätt
<resource-group>med den Azure-resursgrupp som innehåller din arbetsyta. - Ersätt
<location>med Den Azure-region som innehåller din arbetsyta.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Du kan se vilka dina aktuella standardvärden är med hjälp
az configure -lav kommandot .- Ersätt
Lagringsplats för klonexempel
Kodexemplen i den här artikeln baseras på nyc_taxi_data_regression exemplet på exempellagringsplatsen. Om du vill använda dessa filer i utvecklingsmiljön använder du följande kommandon för att klona lagringsplatsen och ändra kataloger till exemplet:
git clone https://github.com/Azure/azureml-examples
cd azureml-examples
I CLI-exemplet ändrar du kataloger till cli/jobs/pipelines-with-components/nyc_taxi_data_regression i din lokala klon av exempellagringsplatsen.
cd cli/jobs/pipelines-with-components/nyc_taxi_data_regression
Skapa SDK-anslutning
Dricks
Det här steget behövs bara när du använder Python SDK.
Skapa en klientanslutning till både Azure Machine Learning-arbetsytan och registret:
ml_client_workspace = MLClient( credential=credential,
subscription_id = "<workspace-subscription>",
resource_group_name = "<workspace-resource-group",
workspace_name = "<workspace-name>")
print(ml_client_workspace)
ml_client_registry = MLClient(credential=credential,
registry_name="<REGISTRY_NAME>",
registry_location="<REGISTRY_REGION>")
print(ml_client_registry)
Skapa miljö i registret
Miljöer definierar den dockercontainer och Python-beroenden som krävs för att köra träningsjobb eller distribuera modeller. Mer information om miljöer finns i följande artiklar:
Dricks
Samma CLI-kommando az ml environment create kan användas för att skapa miljöer i en arbetsyta eller ett register. När du kör kommandot med --workspace-name kommandot skapas miljön på en arbetsyta medan du kör kommandot med --registry-name skapar miljön i registret.
Vi skapar en miljö som använder docker-avbildningen python:3.8 och installerar Python-paket som krävs för att köra ett träningsjobb med hjälp av SciKit Learn-ramverket. Om du har klonat exempel-lagringsplatsen och finns i mappen cli/jobs/pipelines-with-components/nyc_taxi_data_regressionbör du kunna se miljödefinitionsfilen env_train.yml som refererar till docker-filen env_train/Dockerfile. Visas env_train.yml nedan för din referens:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: SKLearnEnv
version: 1
build:
path: ./env_train
Skapa miljön med hjälp av följande az ml environment create
az ml environment create --file env_train.yml --registry-name <registry-name>
Om du får ett fel om att det redan finns en miljö med det här namnet och versionen i registret kan du antingen redigera version fältet i env_train.yml eller ange en annan version på CLI som åsidosätter versionsvärdet i env_train.yml.
# use shell epoch time as the version
version=$(date +%s)
az ml environment create --file env_train.yml --registry-name <registry-name> --set version=$version
Dricks
version=$(date +%s) fungerar bara i Linux. Ersätt $version med ett slumptal om det inte fungerar.
name Anteckna miljön och version från kommandots az ml environment create utdata och använd dem med az ml environment show kommandon på följande sätt. Du behöver name och version i nästa avsnitt när du skapar en komponent i registret.
az ml environment show --name SKLearnEnv --version 1 --registry-name <registry-name>
Dricks
Om du har använt ett annat miljönamn eller en annan version ersätter du parametrarna --name och --version därefter.
Du kan också använda az ml environment list --registry-name <registry-name> för att visa en lista över alla miljöer i registret.
Du kan bläddra bland alla miljöer i Azure Machine Learning-studio. Kontrollera att du navigerar till det globala användargränssnittet och letar efter posten Registries .

Skapa en komponent i registret
Komponenter är återanvändbara byggstenar i Machine Learning-pipelines i Azure Machine Learning. Du kan paketera koden, kommandot, miljön, indatagränssnittet och utdatagränssnittet för ett enskilt pipelinesteg i en komponent. Sedan kan du återanvända komponenten i flera pipelines utan att behöva oroa dig för portning av beroenden och kod varje gång du skriver en annan pipeline.
När du skapar en komponent i en arbetsyta kan du använda komponenten i alla pipelinejobb på arbetsytan. När du skapar en komponent i ett register kan du använda komponenten i valfri pipeline på valfri arbetsyta i din organisation. Att skapa komponenter i ett register är ett bra sätt att skapa modulära återanvändbara verktyg eller delade träningsuppgifter som kan användas för experimentering av olika team i din organisation.
Mer information om komponenter finns i följande artiklar:
Så här använder du komponenter i pipelines (SDK)
Viktigt!
Registret stöder endast namngivna tillgångar (data/modell/komponent/miljö). Om du ska referera till en tillgång i ett register måste du först skapa den i registret. Särskilt för pipelinekomponentfall behöver du först skapa komponenten eller miljön i registret om du vill ha referenskomponenten eller miljön i pipelinekomponenten.
Kontrollera att du är i mappen cli/jobs/pipelines-with-components/nyc_taxi_data_regression. Du hittar komponentdefinitionsfilen train.yml som paketerade ett Scikit Learn-träningsskript train_src/train.py och den kurerade miljönAzureML-sklearn-0.24-ubuntu18.04-py37-cpu. Vi använder Scikit Learn-miljön som skapats i ett genomgripande steg i stället för den kurerade miljön. Du kan redigera environment fältet i train.yml för att referera till din Scikit Learn-miljö. Den resulterande komponentdefinitionsfilen train.yml liknar följande exempel:
# <component>
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_linear_regression_model
display_name: TrainLinearRegressionModel
version: 1
type: command
inputs:
training_data:
type: uri_folder
test_split_ratio:
type: number
min: 0
max: 1
default: 0.2
outputs:
model_output:
type: mlflow_model
test_data:
type: uri_folder
code: ./train_src
environment: azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1`
command: >-
python train.py
--training_data ${{inputs.training_data}}
--test_data ${{outputs.test_data}}
--model_output ${{outputs.model_output}}
--test_split_ratio ${{inputs.test_split_ratio}}
Om du använde ett annat namn eller en annan version ser den mer generiska representationen ut så här: environment: azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>, så se till att du ersätter <registry-name>och <sklearn-environment-name><sklearn-environment-version> därefter. Sedan kör az ml component create du kommandot för att skapa komponenten på följande sätt.
az ml component create --file train.yml --registry-name <registry-name>
Dricks
Samma CLI-kommando az ml component create kan användas för att skapa komponenter i en arbetsyta eller ett register. När du kör kommandot med --workspace-name kommandot skapas komponenten i en arbetsyta medan du kör kommandot med --registry-name skapar komponenten i registret.
Om du föredrar att inte redigera train.ymlkan du åsidosätta miljönamnet på CLI på följande sätt:
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1
# or if you used a different name or version, replace `<sklearn-environment-name>` and `<sklearn-environment-version>` accordingly
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>
Dricks
Om du får ett felmeddelande om att namnet på komponenten redan finns i registret kan du antingen redigera versionen i train.yml eller åsidosätta versionen på CLI med en slumpmässig version.
Anteckna komponenten name och version från kommandots az ml component create utdata och använd dem med az ml component show kommandon på följande sätt. Du behöver name och version i nästa avsnitt när du skapar skicka ett träningsjobb på arbetsytan.
az ml component show --name <component_name> --version <component_version> --registry-name <registry-name>
Du kan också använda az ml component list --registry-name <registry-name> för att visa en lista över alla komponenter i registret.
Du kan bläddra bland alla komponenter i Azure Machine Learning-studio. Kontrollera att du navigerar till det globala användargränssnittet och letar efter posten Registries .

Köra ett pipelinejobb på en arbetsyta med hjälp av komponenten från registret
När du kör ett pipelinejobb som använder en komponent från ett register är beräkningsresurserna och träningsdata lokala för arbetsytan. Mer information om hur du kör jobb finns i följande artiklar:
- Jobb som körs (CLI)
- Jobb som körs (SDK)
- Pipelinejobb med komponenter (CLI)
- Pipelinejobb med komponenter (SDK)
Vi kör ett pipelinejobb med träningskomponenten Scikit Learn som skapades i föregående avsnitt för att träna en modell. Kontrollera att du är i mappen cli/jobs/pipelines-with-components/nyc_taxi_data_regression. Träningsdatauppsättningen data_transformed finns i mappen . Redigera avsnittet component i under train_job avsnittet i single-job-pipeline.yml filen för att referera till träningskomponenten som skapades i föregående avsnitt. Resultatet single-job-pipeline.yml visas nedan.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: nyc_taxi_data_regression_single_job
description: Single job pipeline to train regression model based on nyc taxi dataset
jobs:
train_job:
type: command
component: azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
compute: azureml:cpu-cluster
inputs:
training_data:
type: uri_folder
path: ./data_transformed
outputs:
model_output:
type: mlflow_model
test_data:
Den viktigaste aspekten är att den här pipelinen kommer att köras på en arbetsyta med hjälp av en komponent som inte finns på den specifika arbetsytan. Komponenten finns i ett register som kan användas med valfri arbetsyta i din organisation. Du kan köra det här träningsjobbet på alla arbetsytor som du har åtkomst till utan att behöva oroa dig för att göra träningskoden och miljön tillgänglig på den arbetsytan.
Varning
- Innan du kör pipelinejobbet kontrollerar du att arbetsytan där du ska köra jobbet finns i en Azure-region som stöds av registret där du skapade komponenten.
- Bekräfta att arbetsytan har ett beräkningskluster med namnet
cpu-clustereller redigeracomputefältet underjobs.train_job.computemed namnet på din beräkning.
Kör pipelinejobbet az ml job create med kommandot .
az ml job create --file single-job-pipeline.yml
Dricks
Om du inte har konfigurerat standardarbetsytan och resursgruppen enligt beskrivningen i avsnittet förutsättningar måste du ange parametrarna --workspace-name och --resource-group för az ml job create att arbeta.
Du kan också hoppa över redigering single-job-pipeline.yml och åsidosätta komponentnamnet som används av train_job i CLI.
az ml job create --file single-job-pipeline.yml --set jobs.train_job.component=azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
Eftersom komponenten som används i träningsjobbet delas via ett register kan du skicka jobbet till alla arbetsytor som du har åtkomst till i din organisation, även i olika prenumerationer. Om du till exempel har dev-workspace, test-workspace och prod-workspace, är det lika enkelt att köra träningsjobbet på dessa tre arbetsytor som att köra tre az ml job create kommandon.
az ml job create --file single-job-pipeline.yml --workspace-name dev-workspace --resource-group <resource-group-of-dev-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name test-workspace --resource-group <resource-group-of-test-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name prod-workspace --resource-group <resource-group-of-prod-workspace>
I Azure Machine Learning-studio väljer du slutpunktslänken i jobbutdata för att visa jobbet. Här kan du analysera träningsmått, kontrollera att jobbet använder komponenten och miljön från registret och granska den tränade modellen.
name Anteckna jobbet från utdata eller hitta samma information från jobböversikten i Azure Machine Learning-studio. Du behöver den här informationen för att ladda ned den tränade modellen i nästa avsnitt om hur du skapar modeller i registret.

Skapa en modell i registret
Du får lära dig hur du skapar modeller i ett register i det här avsnittet. Läs hantera modeller om du vill veta mer om modellhantering i Azure Machine Learning. Vi tittar på två olika sätt att skapa en modell i ett register. Först kommer från lokala filer. För det andra är att kopiera en modell som är registrerad på arbetsytan till ett register.
I båda alternativen skapar du modellen med MLflow-formatet, vilket hjälper dig att distribuera den här modellen för slutsatsdragning utan att skriva någon slutsatskod.
Skapa en modell i registret från lokala filer
Ladda ned modellen, som är tillgänglig som utdata från train_job genom att <job-name> ersätta med namnet från jobbet från föregående avsnitt. Modellen tillsammans med MLflow-metadatafiler ska vara tillgänglig i ./artifacts/model/.
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --query [0].name | sed 's/\"//g')
# download the default outputs of the train_job
az ml job download --name $train_job_name
# review the model files
ls -l ./artifacts/model/
Dricks
Om du inte har konfigurerat standardarbetsytan och resursgruppen enligt beskrivningen i avsnittet förutsättningar måste du ange parametrarna --workspace-name och --resource-group för az ml model create att arbeta.
Varning
Utdata az ml job list för skickas till sed. Detta fungerar bara på Linux-gränssnitt. Om du använder Windows kan du köra az ml job list --parent-job-name <job-name> --query [0].name och ta bort citattecken som du ser i namnet på träningsjobbet.
Om du inte kan ladda ned modellen kan du hitta en MLflow-exempelmodell som tränats av träningsjobbet i föregående avsnitt i cli/jobs/pipelines-with-components/nyc_taxi_data_regression/artifacts/model/ mappen.
Skapa modellen i registret:
# create model in registry
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path ./artifacts/model/ --registry-name <registry-name>
Dricks
- Använd ett slumptal för parametern
versionom du får ett fel om att modellnamnet och versionen finns. - Samma CLI-kommando
az ml model createkan användas för att skapa modeller i en arbetsyta eller ett register. När du kör kommandot med--workspace-namekommandot skapas modellen på en arbetsyta medan du kör kommandot med--registry-nameskapar modellen i registret.
Dela en modell från arbetsyta till register
I det här arbetsflödet skapar du först modellen på arbetsytan och delar den sedan till registret. Det här arbetsflödet är användbart när du vill testa modellen på arbetsytan innan du delar den. Distribuera den till slutpunkter, prova slutsatsdragning med vissa testdata och kopiera sedan modellen till ett register om allt ser bra ut. Det här arbetsflödet kan också vara användbart när du utvecklar en serie modeller med olika tekniker, ramverk eller parametrar och bara vill flytta upp en av dem till registret som produktionskandidat.
Kontrollera att du har namnet på pipelinejobbet från föregående avsnitt och ersätt det i kommandot för att hämta namnet på träningsjobbet nedan. Sedan registrerar du modellen från utdata från träningsjobbet till arbetsytan. Observera hur parametern --path refererar till utdata train_job med syntaxen azureml://jobs/$train_job_name/outputs/artifacts/paths/model .
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --workspace-name <workspace-name> --resource-group <workspace-resource-group> --query [0].name | sed 's/\"//g')
# create model in workspace
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path azureml://jobs/$train_job_name/outputs/artifacts/paths/model
Dricks
- Använd ett slumptal för parametern
versionom du får ett fel om att modellnamnet och versionen finns." - Om du inte har konfigurerat standardarbetsytan och resursgruppen enligt beskrivningen i avsnittet förutsättningar måste du ange parametrarna
--workspace-nameoch--resource-groupföraz ml model createatt arbeta.
Anteckna modellnamnet och versionen. Du kan kontrollera om modellen är registrerad på arbetsytan genom att bläddra i den i Studio-användargränssnittet eller med hjälp av az ml model show --name nyc-taxi-model --version $model_version kommandot .
Nu ska du dela modellen från arbetsytan till registret.
# share model registered in workspace to registry
az ml model share --name nyc-taxi-model --version 1 --registry-name <registry-name> --share-with-name <new-name> --share-with-version <new-version>
Dricks
- Se till att använda rätt modellnamn och version om du har ändrat den i
az ml model createkommandot . - Kommandot ovan har två valfria parametrar "--share-with-name" och "--share-with-version". Om dessa inte anges har den nya modellen samma namn och version som den modell som delas.
nameAnteckna modellen ochversionfrån kommandotsaz ml model createutdata och använd dem medaz ml model showkommandon på följande sätt. Du behövernameochversioni nästa avsnitt när du distribuerar modellen till en onlineslutpunkt för slutsatsdragning.
az ml model show --name <model_name> --version <model_version> --registry-name <registry-name>
Du kan också använda az ml model list --registry-name <registry-name> för att visa en lista över alla modeller i registret eller bläddra bland alla komponenter i Azure Machine Learning-studio användargränssnittet. Se till att du navigerar till det globala användargränssnittet och letar efter navet Registries.
Följande skärmbild visar en modell i ett register i Azure Machine Learning-studio. Om du har skapat en modell från jobbutdata och sedan kopierat modellen från arbetsytan till registret ser du att modellen har en länk till det jobb som tränade modellen. Du kan använda den länken för att navigera till träningsjobbet för att granska koden, miljön och data som används för att träna modellen.
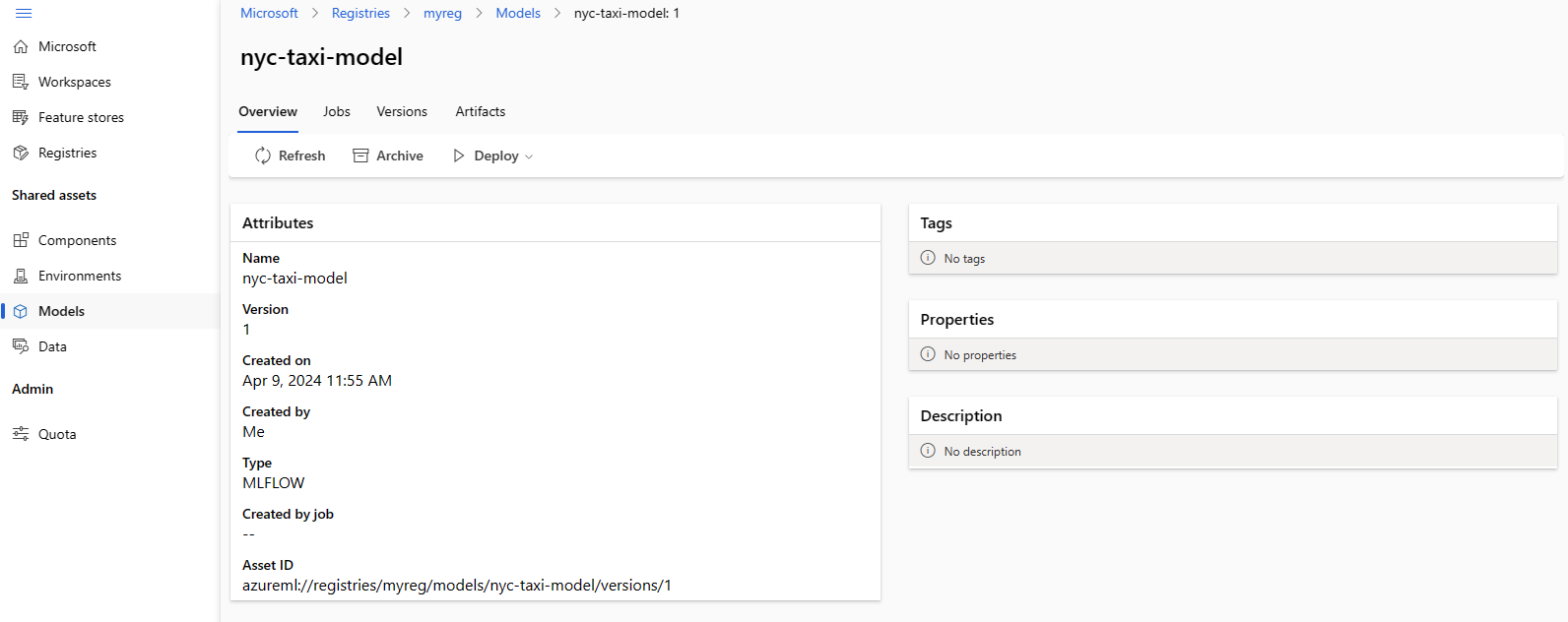
Distribuera modellen från registret till onlineslutpunkten på arbetsytan
I det sista avsnittet distribuerar du en modell från registret till en onlineslutpunkt på en arbetsyta. Du kan välja att distribuera valfri arbetsyta som du har åtkomst till i din organisation, förutsatt att arbetsytans plats är en av de platser som stöds av registret. Den här funktionen är användbar om du har tränat en modell på en dev arbetsyta och nu behöver distribuera modellen till test eller prod arbetsytan, samtidigt som du bevarar ursprungsinformationen kring koden, miljön och data som används för att träna modellen.
Med onlineslutpunkter kan du distribuera modeller och skicka slutsatsdragningsbegäranden via REST-API:erna. Mer information finns i Distribuera och poängsätta en maskininlärningsmodell med hjälp av en onlineslutpunkt.
Skapa en onlineslutpunkt.
az ml online-endpoint create --name reg-ep-1234
Uppdatera raden model:deploy.yml som är tillgänglig i cli/jobs/pipelines-with-components/nyc_taxi_data_regression mappen för att referera till modellnamnet och versionen från det skadliga steget. Skapa en onlinedistribution till onlineslutpunkten. Visas deploy.yml nedan som referens.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: demo
endpoint_name: reg-ep-1234
model: azureml://registries/<registry-name>/models/nyc-taxi-model/versions/1
instance_type: Standard_DS2_v2
instance_count: 1
Skapa onlinedistributionen. Distributionen tar normalt flera minuter för att slutföras.
az ml online-deployment create --file deploy.yml --all-traffic
Hämta bedömnings-URI:n och skicka en exempelbedömningsbegäran. Exempeldata för bedömningsbegäran är tillgängliga i scoring-data.json mappen i cli/jobs/pipelines-with-components/nyc_taxi_data_regression .
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n reg-ep-1234 -o tsv --query primaryKey)
SCORING_URI=$(az ml online-endpoint show -n reg-ep-1234 -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @./scoring-data.json
Dricks
-
curlkommandot fungerar bara på Linux. - Om du inte har konfigurerat standardarbetsytan och resursgruppen enligt beskrivningen i avsnittet krav måste du ange parametrarna
--workspace-nameoch--resource-groupföraz ml online-endpointatt kommandona ochaz ml online-deploymentska fungera.
Rensa resurser
Om du inte använder distributionen bör du ta bort den för att minska kostnaderna. I följande exempel tas slutpunkten och alla underliggande distributioner bort:
az ml online-endpoint delete --name reg-ep-1234 --yes --no-wait