Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
Lär dig hur du konfigurerar en Python-utvecklingsmiljö för Azure Machine Learning.
I följande tabell visas varje utvecklingsmiljö som beskrivs i den här artikeln, tillsammans med för- och nackdelar.
| Miljö | Fördelar | Nackdelar |
|---|---|---|
| Lokal miljö | Fullständig kontroll över din utvecklingsmiljö och dina beroenden. Kör med valfritt byggverktyg, miljö eller valfri IDE. | Det tar längre tid att komma igång. Nödvändiga SDK-paket måste installeras och en miljö måste också installeras om du inte redan har ett. |
| Azure Machine Learning-beräkningsinstans | Det enklaste sättet att komma igång. SDK:n är redan installerad i din virtuella arbetsyta VM och anteckningsbokens handledningar har redan klonats och är redo att köras. | Brist på kontroll över utvecklingsmiljön och beroenden. Kostnaden uppstår för virtuella Linux-datorer (den virtuella datorn kan stoppas när den inte används för att undvika avgifter). Se prisuppgifter. |
| Datavetenskapens virtuella dator (DSVM) | Liknar den molnbaserade beräkningsinstansen (Python är förinstallerat), men med andra populära datavetenskaps- och maskininlärningsverktyg förinstallerade. Lätt att skala och kombinera med andra anpassade verktyg och arbetsflöden. | En långsammare kom igång-upplevelse jämfört med den molnbaserade beräkningsinstansen. |
Den här artikeln innehåller även andra användningstips för följande verktyg:
Jupyter Notebooks: Om du redan använder Jupyter Notebooks har SDK några extrafunktioner som du bör installera.
Visual Studio Code: Om du använder Visual Studio Code innehåller Azure Machine Learning-tillägget språkstöd för Python och funktioner för att göra det mycket enklare och mer produktivt att arbeta med Azure Machine Learning.
Förutsättningar
- Azure Machine Learning-arbetsyta. Om du inte har någon kan du skapa en Azure Machine Learning-arbetsyta via mallarna Azure Portal, Azure CLI och Azure Resource Manager.
Endast lokal och DSVM: Skapa en konfigurationsfil för arbetsytan
Konfigurationsfilen för arbetsytan är en JSON-fil som talar om för SDK hur du kommunicerar med din Azure Machine Learning-arbetsyta. Filen heter config.json och har följande format:
{
"subscription_id": "<subscription-id>",
"resource_group": "<resource-group>",
"workspace_name": "<workspace-name>"
}
Den här JSON-filen måste finnas i katalogstrukturen som innehåller dina Python-skript eller Jupyter Notebooks. Den kan finnas i samma katalog, en underkatalog med namnet.azureml*, eller i en överordnad katalog.
För att använda den här filen från din kod, använd metoden MLClient.from_config. Den här koden läser in informationen från filen och ansluter till din arbetsyta.
Skapa en konfigurationsfil för arbetsytan i någon av följande metoder:
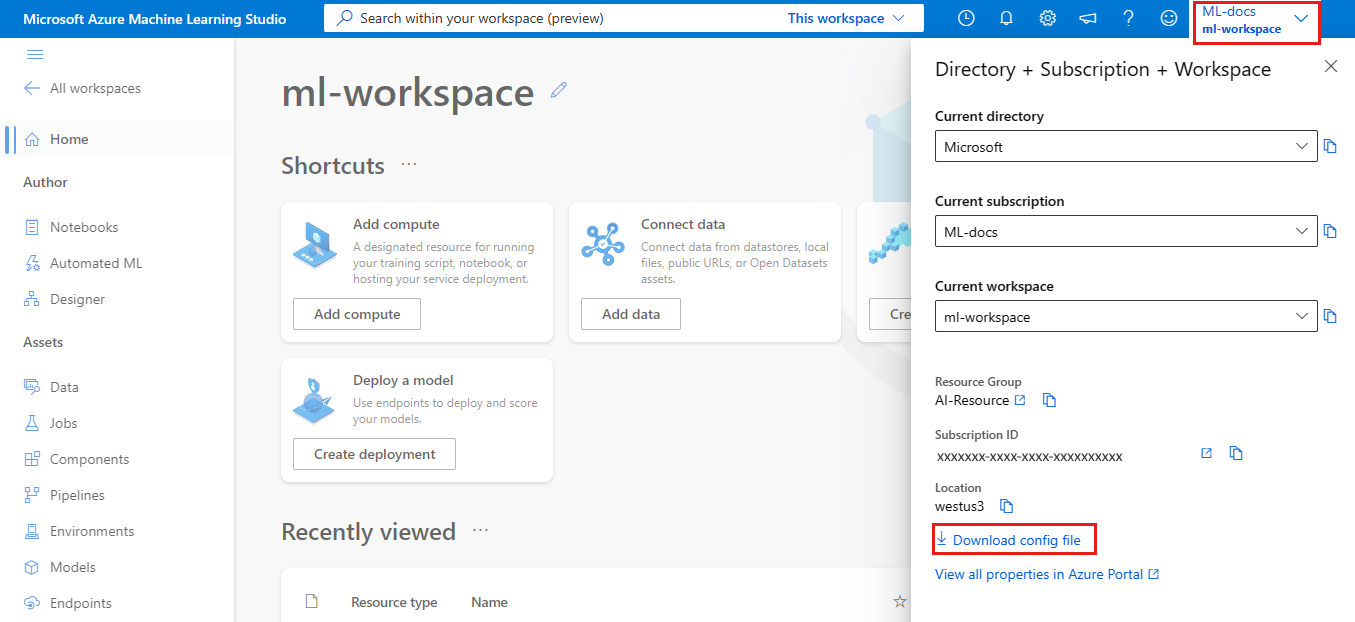
Azure Machine Learning Studio
Ladda ned filen:
- Logga in på Azure Machine Learning-studio
- I det övre högra Azure Machine Learning-studio verktygsfältet väljer du namnet på arbetsytan.
- Välj länken Ladda ned konfigurationsfil.
Python-SDK för Azure Machine Learning
Skapa ett skript för att ansluta till din Azure Machine Learning-arbetsyta. Se till att ersätta
subscription_id,resource_groupochworkspace_namemed din egen.GÄLLER FÖR:
Python SDK azure-ai-ml v2 (aktuell)#import required libraries from azure.ai.ml import MLClient from azure.identity import DefaultAzureCredential #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace = '<AZUREML_WORKSPACE_NAME>' #connect to the workspace ml_client = MLClient(DefaultAzureCredential(), subscription_id, resource_group, workspace)

Lokal dator eller fjärrmiljö för virtuell dator
Du kan konfigurera en miljö på en lokal dator eller en virtuell fjärrdator, till exempel en Azure Machine Learning-beräkningsinstans eller Datavetenskap virtuell dator.
Så här konfigurerar du en lokal utvecklingsmiljö eller en fjärransluten virtuell dator:
Skapa en virtuell Python-miljö (virtualenv, conda).
Kommentar
Även om det inte krävs rekommenderar vi att du använder Anaconda eller Miniconda för att hantera virtuella Python-miljöer och installera paket.
Viktigt!
Om du använder Linux eller macOS och använder ett annat gränssnitt än bash (till exempel zsh) kan du få fel när du kör vissa kommandon. Du kan undvika det här problemet genom att använda
bashkommandot för att starta ett nytt bash-gränssnitt och köra kommandona där.Aktivera den nya virtuella Python-miljön.
Om du vill konfigurera din lokala miljö att använda din Azure Machine Learning-arbetsyta skapar du en konfigurationsfil för arbetsytan eller använder en befintlig.
Nu när du har konfigurerat din lokala miljö är du redo att börja arbeta med Azure Machine Learning. Se Självstudie: Azure Machine Learning på en dag för att komma igång.
Jupyter Notebook
När du kör en lokal Jupyter Notebook-server rekommenderar vi att du skapar en IPython-kernel för din virtuella Python-miljö. Detta säkerställer det förväntade beteendet för kernel- och paketimport.
Aktivera miljöspecifika IPython-kernels
conda install notebook ipykernelSkapa en kernel för din virtuella Python-miljö. Ersätt
<myenv>med namnet på din virtuella Python-miljö.ipython kernel install --user --name <myenv> --display-name "Python (myenv)"Starta Jupyter Notebook-servern
Dricks
Exempel på notebook-filer finns i lagringsplatsen AzureML-Examples . SDK-exempel finns under /sdk/python. Exempel på konfigurationsanteckningsboken.
Visual Studio-koden
Så här använder du Visual Studio Code för utveckling:
- Installera Visual Studio Code.
- Installera Tillägget Azure Machine Learning Visual Studio Code (förhandsversion).
När du har installerat Visual Studio Code-tillägget använder du det för att:
- Hantera dina Azure Machine Learning-resurser
- Ansluta till en Azure Machine Learning-beräkningsinstans
- Felsöka onlineslutpunkter lokalt
- Distribuera tränade modeller.
Azure Machine Learning-beräkningsinstans
Azure Machine Learning-beräkningsinstansen är en säker, molnbaserad Azure-arbetsstation som ger dataforskare en Jupyter Notebook-server, JupyterLab och en fullständigt hanterad maskininlärningsmiljö.
Det finns inget att installera eller konfigurera för en beräkningsinstans.
Skapa en när som helst inifrån din Azure Machine Learning-arbetsyta. Ange bara ett namn och ange en typ av virtuell Azure-dator. Prova nu med Skapa resurser för att komma igång.
Mer information om beräkningsinstanser, inklusive hur du installerar paket, finns i Skapa en Azure Machine Learning-beräkningsinstans.
Dricks
Om du vill förhindra avgifter för en oanvänd beräkningsinstans aktiverar du inaktiv avstängning.
Förutom en Jupyter Notebook-server och JupyterLab kan du använda beräkningsinstanser i den integrerade notebook-funktionen i Azure Machine Learning-studio.
Du kan också använda Tillägget Azure Machine Learning Visual Studio Code för att ansluta till en fjärrberäkningsinstans med VS Code.
Data Science Virtual Machine
Datavetenskaps-VM är en anpassad virtuell maskinavbildning som du kan använda som utvecklingsmiljö. Det är utformat för data science-arbete med förkonfigurerade verktyg och programvara som:
- Paket som TensorFlow, PyTorch, Scikit-learn, XGBoost och Azure Machine Learning SDK
- Populära datavetenskapsverktyg som Spark Standalone och Drill
- Azure-verktyg som Azure CLI, AzCopy och Storage Explorer
- Integrerade utvecklingsmiljöer (IDE:er) som Visual Studio Code och PyCharm
- Jupyter Notebook Server
För en mer omfattande lista över verktygen, se verktygsguiden för Datavetenskap VM.
Viktigt!
Om du planerar att använda den Datavetenskap virtuella datorn som beräkningsmål för dina tränings- eller slutsatsdragningsjobb stöds endast Ubuntu.
För att använda den virtuella datorn för dataanalys som utvecklingsmiljö:
Skapa en Datavetenskap virtuell dator med någon av följande metoder:
Använd Azure Portal för att skapa en Ubuntu eller Windows DSVM.
Använda Azure CLI
Om du vill skapa en virtuell Ubuntu-Datavetenskap virtuell dator använder du följande kommando:
# create a Ubuntu Data Science VM in your resource group # note you need to be at least a contributor to the resource group in order to execute this command successfully # If you need to create a new resource group use: "az group create --name YOUR-RESOURCE-GROUP-NAME --location YOUR-REGION (For example: westus2)" az vm create --resource-group YOUR-RESOURCE-GROUP-NAME --name YOUR-VM-NAME --image microsoft-dsvm:linux-data-science-vm-ubuntu:linuxdsvmubuntu:latest --admin-username YOUR-USERNAME --admin-password YOUR-PASSWORD --generate-ssh-keys --authentication-type passwordOm du vill skapa en Windows DSVM använder du följande kommando:
# create a Windows Server 2016 DSVM in your resource group # note you need to be at least a contributor to the resource group in order to execute this command successfully az vm create --resource-group YOUR-RESOURCE-GROUP-NAME --name YOUR-VM-NAME --image microsoft-dsvm:dsvm-windows:server-2016:latest --admin-username YOUR-USERNAME --admin-password YOUR-PASSWORD --authentication-type password
Skapa en conda-miljö för Azure Machine Learning SDK:
conda create -n py310 python=310När miljön har skapats aktiverar du den och installerar SDK:et
conda activate py310 pip install azure-ai-ml azure-identityOm du vill konfigurera den Datavetenskap virtuella datorn så att den använder din Azure Machine Learning-arbetsyta skapar du en konfigurationsfil för arbetsytan eller använder en befintlig.
Dricks
Precis som i lokala miljöer kan du använda Visual Studio Code och Azure Machine Learning Visual Studio Code-tillägget för att interagera med Azure Machine Learning.
Mer information finns i Datavetenskap Virtuella datorer.
Nästa steg
- Träna och distribuera en modell på Azure Machine Learning med MNIST-datauppsättningen.
- Se Azure Machine Learning SDK för Python-referens.