Ansluta till data med Azure Machine Learning-studio
I den här artikeln får du lära dig hur du kommer åt dina data med Azure Machine Learning-studio. Anslut till dina data i lagringstjänster i Azure med Azure Machine Learning-datalager och paketera sedan dessa data för uppgifter i dina ML-arbetsflöden med Azure Machine Learning-datauppsättningar.
I följande tabell definieras och sammanfattas fördelarna med datalager och datauppsättningar.
| Objekt | beskrivning | Förmåner |
|---|---|---|
| Datalager | Anslut säkert till lagringstjänsten i Azure genom att lagra din anslutningsinformation, till exempel ditt prenumerations-ID och tokenauktorisering i ditt Key Vault som är associerat med arbetsytan | Eftersom din information lagras på ett säkert sätt kan du |
| Datauppsättningar | Genom att skapa en datamängd skapar du en referens till datakällans plats, tillsammans med en kopia av dess metadata. Med datauppsättningar kan du |
Eftersom datauppsättningar utvärderas lazily och data finns kvar på den befintliga platsen kan du |
Information om var datalager och datauppsättningar får plats i Azure Machine Learnings övergripande arbetsflöde för dataåtkomst finns i artikeln Om säker åtkomst till data .
En första kodupplevelse finns i följande artiklar om du vill använda Azure Machine Learning Python SDK för att:
Förutsättningar
En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning.
Åtkomst till Azure Machine Learning-studio.
En Azure Machine Learning-arbetsyta. Skapa arbetsyteresurser.
- När du skapar en arbetsyta registreras automatiskt en Azure-blobcontainer och en Azure-filresurs som datalager till arbetsytan. De heter
workspaceblobstorerespektiveworkspacefilestore. Om bloblagring räcker för dina behov anges denworkspaceblobstoresom standarddatalager och har redan konfigurerats för användning. Annars behöver du ett lagringskonto i Azure med en lagringstyp som stöds.
- När du skapar en arbetsyta registreras automatiskt en Azure-blobcontainer och en Azure-filresurs som datalager till arbetsytan. De heter
Skapa datalager
Du kan skapa datalager från dessa Azure Storage-lösningar. För lagringslösningar som inte stöds och för att spara kostnader för utgående data under ML-experiment måste du flytta dina data till en Azure Storage-lösning som stöds. Läs mer om datalager.
Du kan skapa datalager med autentiseringsbaserad åtkomst eller identitetsbaserad åtkomst.
Skapa ett nytt datalager i några få steg med Azure Machine Learning-studio.
Viktigt!
Om ditt datalagringskonto finns i ett virtuellt nätverk krävs ytterligare konfigurationssteg för att säkerställa att studion har åtkomst till dina data. Se Nätverksisolering och sekretess för att säkerställa att lämpliga konfigurationssteg tillämpas.
- Logga in på Azure Machine Learning-studio.
- Välj Data i den vänstra rutan under Tillgångar.
- Längst upp väljer du Datalager.
- Välj + Skapa.
- Fyll i formuläret för att skapa och registrera ett nytt datalager. Formuläret uppdateras på ett intelligent sätt baserat på dina val för Azure-lagringstyp och autentiseringstyp. Se avsnittet åtkomst och behörigheter för lagring för att förstå var du hittar de autentiseringsuppgifter som du behöver för att fylla i det här formuläret.
I följande exempel visas hur formuläret ser ut när du skapar ett Azure-blobdatalager:
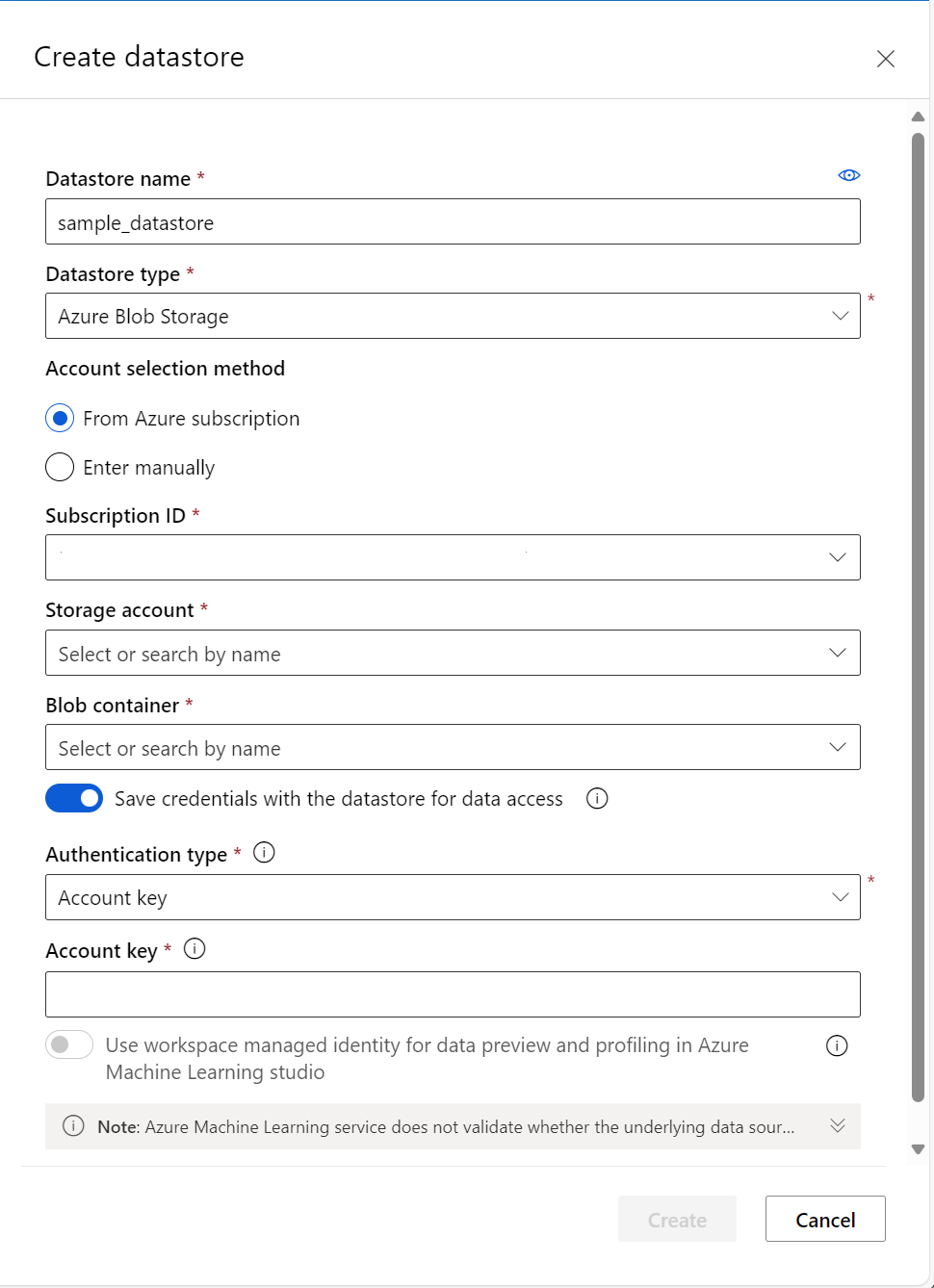
Skapa datatillgångar
När du har skapat ett datalager skapar du en datauppsättning för att interagera med dina data. Datauppsättningar paketera dina data i ett lätt utvärderat förbrukningsobjekt för maskininlärningsuppgifter, till exempel träning. Läs mer om datamängder.
Det finns två typer av datauppsättningar, FileDataset och TabularDataset. FileDatasets skapar referenser till en eller flera filer eller offentliga URL:er. Medan TabularDatasets representerar dina data i tabellformat. Du kan skapa TabularDatasets från .csv, .tsv, .parquet, .jsonl-filer och från SQL-frågeresultat.
Följande steg beskriver hur du skapar en datauppsättning i Azure Machine Learning-studio.
Kommentar
Datauppsättningar som skapas via Azure Machine Learning-studio registreras automatiskt på arbetsytan.
Gå till Azure Machine Learning-studio
Under Tillgångar i det vänstra navigeringsfältet väljer du Data. På fliken Datatillgångar väljer du Skapa
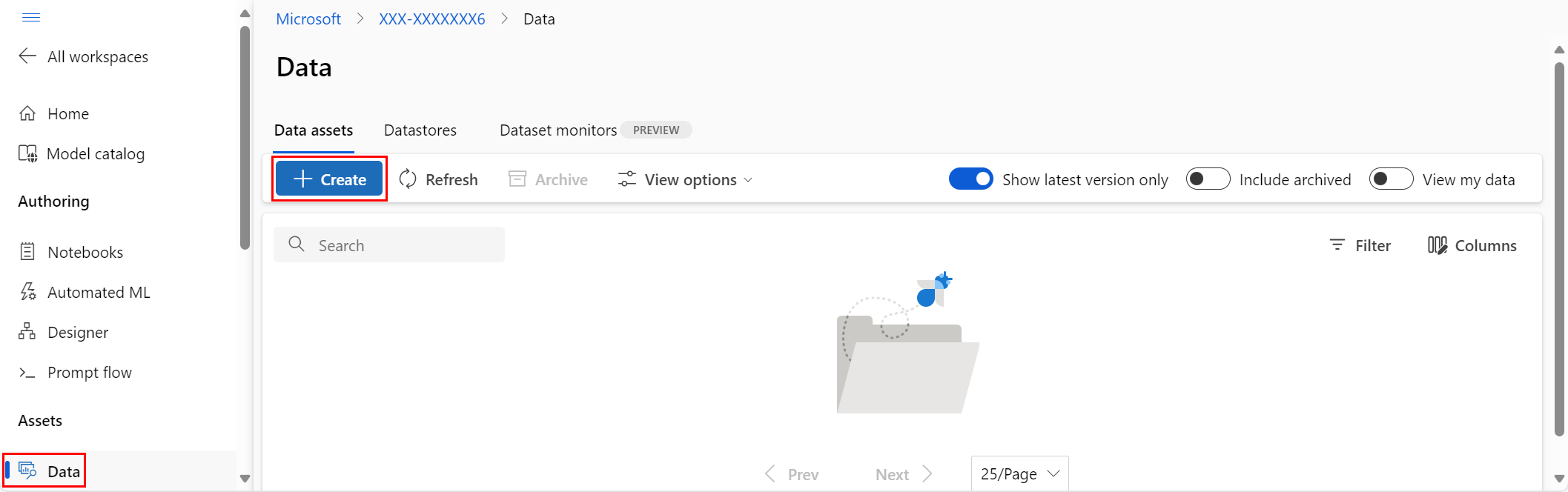
Ge datatillgången ett namn och en valfri beskrivning. Under Typ väljer du sedan någon av datauppsättningstyperna, antingen Arkiv eller Tabell.
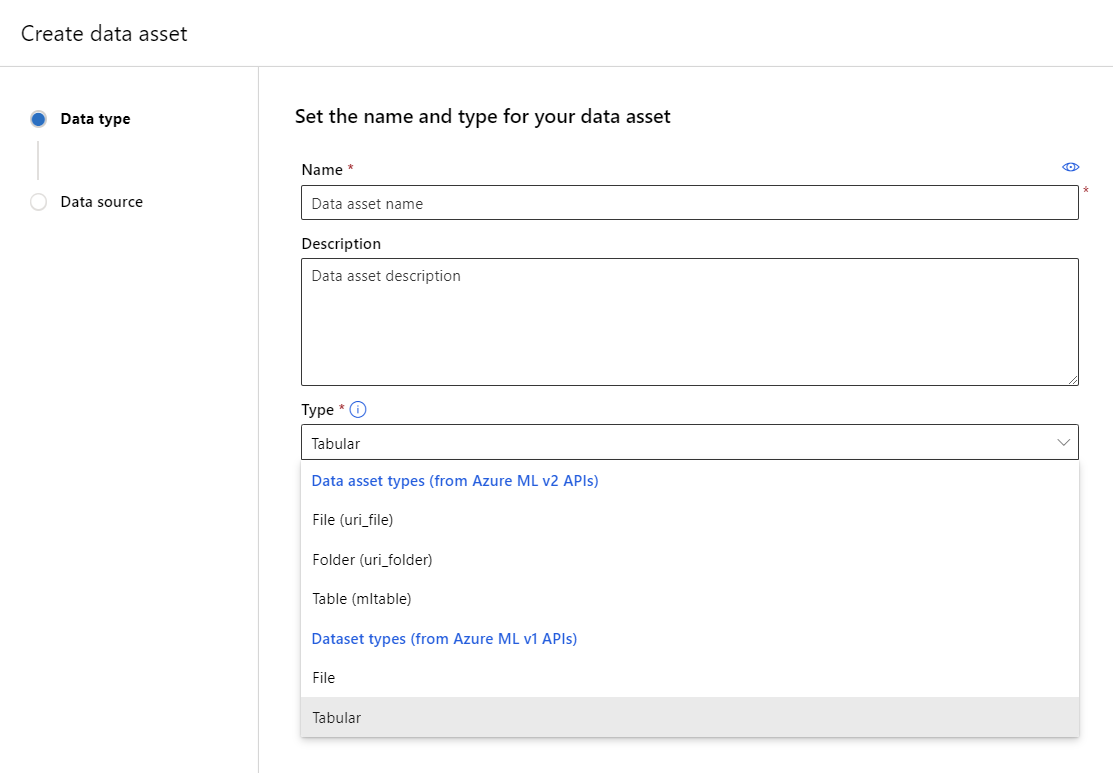
Du har några alternativ för din datakälla. Om dina data redan har lagrats i Azure väljer du "Från Azure Storage". Om du vill ladda upp data från din lokala enhet väljer du "Från lokala filer". Om dina data lagras på en offentlig webbplats väljer du "Från webbfiler". Du kan också skapa en datatillgång från en SQL-databas eller från Azure Open Datasets.
För filvalssteget väljer du var du vill att dina data ska lagras i Azure och vilka datafiler du vill använda.
- Aktivera hoppa över validering om dina data finns i ett virtuellt nätverk. Läs mer om isolering och sekretess för virtuella nätverk.
Följ stegen för att ange dataparsningsinställningar och schema för datatillgången. Inställningarna fylls i i förväg baserat på filtyp och du kan konfigurera inställningarna ytterligare innan du skapar datatillgången.
När du har nått granskningssteget klickar du på Skapa på den sista sidan
Förhandsversion och profil för data
När du har skapat datauppsättningen kontrollerar du att du kan visa förhandsversionen och profilen i studion med följande steg:
- Logga in på Azure Machine Learning-studio
- Under Tillgångar i det vänstra navigeringsfältet väljer du Data.
- Välj namnet på den datauppsättning som du vill visa.
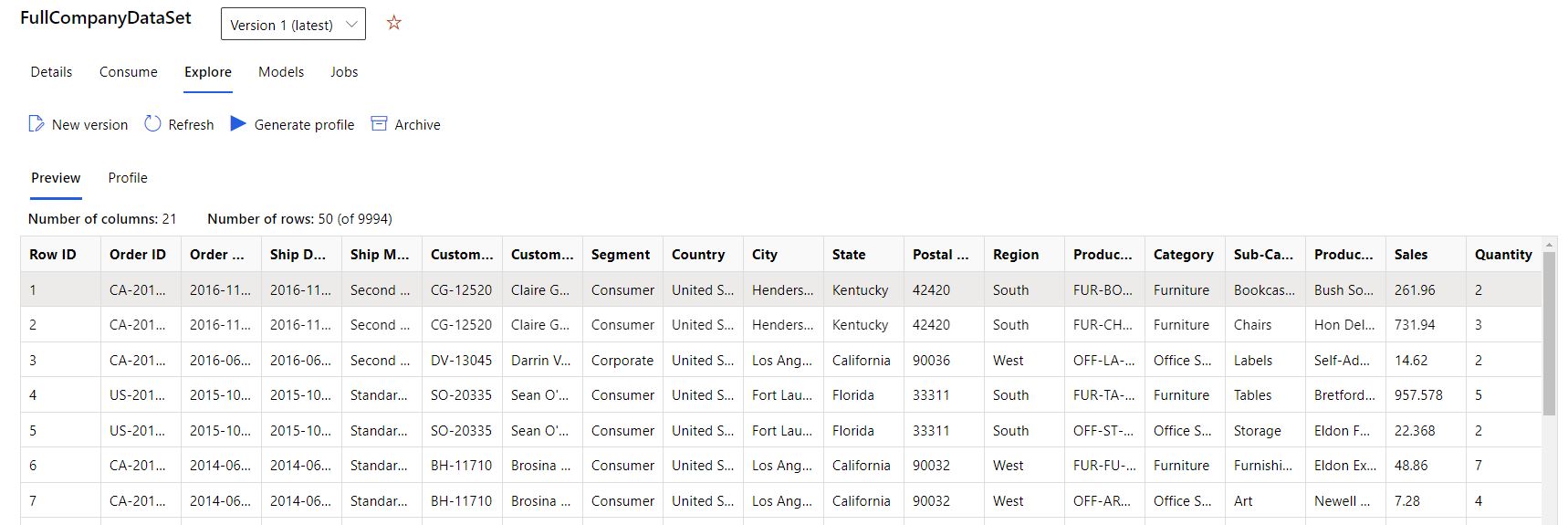
- Välj fliken Utforska .
- Välj fliken Förhandsversion .
- Välj fliken Profil .
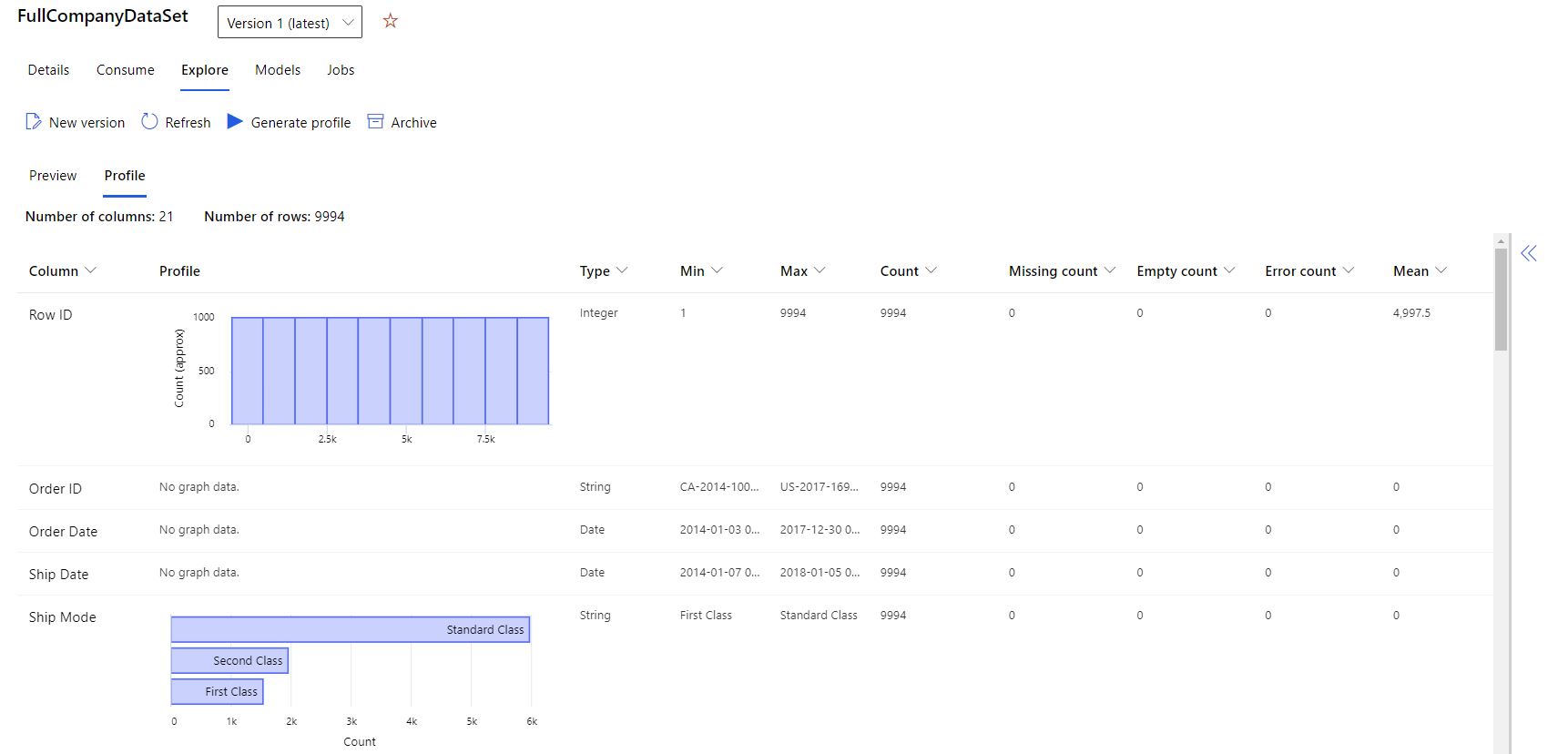
Du kan hämta en mängd olika sammanfattningsstatistik i datauppsättningen för att kontrollera om datauppsättningen är ML-klar. För icke-numeriska kolumner innehåller de endast grundläggande statistik som min, max och felantal. För numeriska kolumner kan du också granska deras statistiska ögonblick och uppskattade kvantantiles.
Mer specifikt omfattar Azure Machine Learning-datauppsättningens dataprofil:
Kommentar
Tomma poster visas för funktioner med irrelevanta typer.
| Statistik | beskrivning |
|---|---|
| Funktion | Namnet på kolumnen som sammanfattas. |
| Profile | Infogad visualisering baserat på den här typen. Till exempel har strängar, booleska värden och datum värdeantal, medan decimaler (numeriska) har ungefärliga histogram. På så sätt kan du få en snabb förståelse för fördelningen av data. |
| Typdistribution | Antal in-line-värden för typer i en kolumn. Null-värden är av egen typ, så den här visualiseringen är användbar för att identifiera udda eller saknade värden. |
| Typ | Härledd typ av kolumnen. Möjliga värden är: strängar, booleska värden, datum och decimaler. |
| Min | Minsta värde för kolumnen. Tomma poster visas för funktioner vars typ inte har någon inbyggd ordning (till exempel booleska objekt). |
| Max | Maximalt värde för kolumnen. |
| Antal | Totalt antal saknade och icke-saknade poster i kolumnen. |
| Antal saknas inte | Antal poster i kolumnen som inte saknas. Tomma strängar och fel behandlas som värden, så de bidrar inte till antalet "saknas inte". |
| Kvantiler | Ungefärliga värden vid varje kvantil för att ge en uppfattning om fördelningen av data. |
| Medelvärde | Aritmetiskt medelvärde eller medelvärde för kolumnen. |
| Standardavvikelse | Mått på mängden spridning eller variation av den här kolumnens data. |
| Varians | Mått på hur långt utspritt den här kolumnens data är från dess genomsnittliga värde. |
| Snedhet | Mått på hur olika den här kolumnens data skiljer sig från en normal distribution. |
| Toppighet | Mått på hur kraftigt skuggade den här kolumnens data jämförs med en normal fördelning. |
Åtkomst och behörigheter för lagring
För att säkerställa att du ansluter säkert till azure-lagringstjänsten kräver Azure Machine Learning att du har behörighet att komma åt motsvarande datalagring. Den här åtkomsten beror på de autentiseringsuppgifter som används för att registrera datalagringen.
Virtuellt nätverk
Om ditt datalagringskonto finns i ett virtuellt nätverk krävs extra konfigurationssteg för att säkerställa att Azure Machine Learning har åtkomst till dina data. Se Använda Azure Machine Learning-studio i ett virtuellt nätverk för att säkerställa att lämpliga konfigurationssteg tillämpas när du skapar och registrerar ditt datalager.
Åtkomstverifiering
Varning
Åtkomst mellan klientorganisationer till lagringskonton stöds inte. Om åtkomst mellan klientorganisationer behövs för ditt scenario kontaktar du Azure Machine Learning Data Support-teamets alias för amldatasupport@microsoft.com att få hjälp med en anpassad kodlösning.
Som en del av den första processen för att skapa och registrera datalager verifierar Azure Machine Learning automatiskt att den underliggande lagringstjänsten finns och att det angivna huvudkontot (användarnamn, tjänstens huvudnamn eller SAS-token) har åtkomst till den angivna lagringen.
När datalager har skapats utförs den här verifieringen endast för metoder som kräver åtkomst till den underliggande lagringscontainern, inte varje gång datalagerobjekt hämtas. Validering sker till exempel om du vill ladda ned filer från ditt datalager. men om du bara vill ändra ditt standarddatalager sker inte verifieringen.
Om du vill autentisera din åtkomst till den underliggande lagringstjänsten kan du ange antingen din kontonyckel, sas-token (signaturer för delad åtkomst) eller tjänstens huvudnamn enligt den datalagertyp som du vill skapa. Lagringstypmatrisen visar de autentiseringstyper som stöds och som motsvarar varje datalagertyp.
Du hittar kontonyckel, SAS-token och information om tjänstens huvudnamn i Azure-portalen.
Om du planerar att använda en kontonyckel eller SAS-token för autentisering väljer du Lagringskonton i den vänstra rutan och väljer det lagringskonto som du vill registrera.
- Sidan Översikt innehåller information som kontonamn, container och filresursnamn.
- För kontonycklar går du till Åtkomstnycklar i fönstret Inställningar.
- För SAS-token går du till Signaturer för delad åtkomst i fönstret Inställningar.
- Sidan Översikt innehåller information som kontonamn, container och filresursnamn.
Om du planerar att använda tjänstens huvudnamn för autentisering går du till din Appregistreringar och väljer vilken app du vill använda.
- Motsvarande översiktssida innehåller nödvändig information som klient-ID och klient-ID.
Viktigt!
- Om du behöver ändra dina åtkomstnycklar för ett Azure Storage-konto (kontonyckel eller SAS-token) ska du synkronisera de nya autentiseringsuppgifterna med din arbetsyta och de datalager som är anslutna till den. Lär dig hur du synkroniserar dina uppdaterade autentiseringsuppgifter.
- Om du avregistrerar och omregistrerar ett datalager med samma namn och det misslyckas kanske Azure Key Vault för din arbetsyta inte har mjuk borttagning aktiverat. Som standard är mjuk borttagning aktiverat för nyckelvalvsinstansen som skapats av din arbetsyta, men den kanske inte är aktiverad om du använde ett befintligt nyckelvalv eller har en arbetsyta som skapats före oktober 2020. Information om hur du aktiverar mjuk borttagning finns i Aktivera mjuk borttagning för ett befintligt nyckelvalv.
Behörigheter
För Azure Blob-container och Azure Data Lake Gen 2-lagring kontrollerar du att dina autentiseringsuppgifter har åtkomst till Storage Blob Data Reader . Läs mer om Storage Blob Data Reader. En SAS-token för kontot har som standard inga behörigheter.
För dataläsningsåtkomst måste dina autentiseringsuppgifter ha minst list- och läsbehörigheter för containrar och objekt.
För åtkomst till dataskrivning krävs även skriv- och tilläggsbehörigheter.
Träna med datauppsättningar
Använd dina datamängder i dina maskininlärningsexperiment för att träna ML-modeller. Läs mer om hur du tränar med datauppsättningar.
Nästa steg
Ett steg för steg-exempel på träning med TabularDatasets och automatiserad maskininlärning.
Fler exempel på datamängdsträning finns i exempelanteckningsböckerna.