Skapa Azure Machine Learning-datauppsättningar från Azure Open Datasets
I den här artikeln får du lära dig hur du tar med utvalda berikande data i dina lokala eller fjärranslutna maskininlärningsexperiment med Azure Machine Learning-datauppsättningar och Azure Open Datasets.
Med en Azure Machine Learning-datauppsättning skapar du en referens till datakällans plats, tillsammans med en kopia av dess metadata. Eftersom datauppsättningar utvärderas lazily och eftersom data finns kvar på den befintliga platsen kan du
- Riskera inte oavsiktliga ändringar i dina ursprungliga datakällor
- Medför ingen extra lagringskostnad
- Förbättra prestandahastigheter för ML-arbetsflöde
Mer information om var datauppsättningar får plats i det övergripande arbetsflödet för Azure Machine Learning-dataåtkomst finns i artikeln Om säker åtkomst till data .
Azure Open Datasets är utvalda offentliga datauppsättningar som lägger till scenariospecifika funktioner för att berika dina förutsägelselösningar och förbättra noggrannheten för dessa lösningar. Besök katalogresursen Öppna datauppsättningar för offentliga data som kan hjälpa dig att träna maskininlärningsmodeller – till exempel:
- Hälsa och genomik
- Arbete och ekonomi
- Befolkning och säkerhet
- Kompletterande och vanliga datauppsättningar
- Transport
Öppna datauppsättningar finns i molnet på Microsoft Azure. Både Azure Machine Learning Python SDK och Azure Machine Learning-studio inkludera dem.
Förutsättningar
Du måste:
En Azure-prenumeration Om du inte har ett konto kan du skapa ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning.
Azure Machine Learning SDK för Python installerat, som innehåller
azureml-datasetspaketet.- Skapa en Azure Machine Learning-beräkningsinstans – en fullständigt konfigurerad och hanterad utvecklingsmiljö som innehåller integrerade notebook-filer och SDK som redan har installerats.
OR
- Arbeta i din egen Python-miljö och installera SDK själv med dessa instruktioner.
Kommentar
Vissa datamängdsklasser har beroenden för azureml-dataprep-paketet . Det här paketet är endast kompatibelt med 64-bitars Python. För Linux-användare stöds dessa klasser endast på dessa Linux-distributioner:
- Debian (8, 9)
- Fedora (27, 28)
- Red Hat Enterprise Linux (7, 8)
- Ubuntu (14.04, 16.04, 18.04)
Skapa datauppsättningar med SDK
Om du vill skapa Azure Machine Learning-datauppsättningar via Azure Open Datasets-klasser i Python SDK kontrollerar du att du har installerat paketet med pip install azureml-opendatasets. I SDK representerar klassen för varje diskret datauppsättning den klassen, och vissa klasser är tillgängliga som antingen en Azure Machine Learning-datatyp FileDataset , en Azure Machine Learning-datatyp TabularDataset eller både och. I referensdokumentationen finns en fullständig lista över opendatasets klasser.
Du kan hämta vissa opendatasets klasser som antingen TabularDataset eller FileDataset resurser. Du kan sedan ändra och/eller ladda ned filerna direkt. Andra klasser kan endast hämta datauppsättningen get_tabular_dataset() med hjälp av funktionerna eller get_file_dataset() från Datasetklassen i Python SDK.
Den här koden visar att MNIST-klassen opendatasets kan returnera antingen en TabularDataset eller FileDataset:
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
I det här exemplet är klassen Diabetes opendatasets endast tillgänglig som en TabularDataset. Detta kräver användning av get_tabular_dataset().
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
Registrera datauppsättningar
Registrera en Azure Machine Learning-datauppsättning med din arbetsyta så att du kan dela datauppsättningen med andra och återanvända den i experiment på din arbetsyta. När du registrerar en Azure Machine Learning-datauppsättning som skapats från öppna datauppsättningar laddas inga data ned omedelbart, men data blir tillgängliga senare (till exempel under träning) när de begärs från en central lagringsplats.
Om du vill registrera dina datauppsättningar med en arbetsyta använder du register() metoden .
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
Skapa datauppsättningar med studion
Du kan också skapa Azure Machine Learning-datauppsättningar från Azure Open Datasets med Azure Machine Learning-studio. Det här konsoliderade webbgränssnittet innehåller maskininlärningsverktyg för att utföra datavetenskapsscenarier för datavetenskapsutövare på alla kunskapsnivåer.
Kommentar
Datauppsättningar som skapas via Azure Machine Learning-studio registreras automatiskt på arbetsytan.
I arbetsytan väljer du Data i det vänstra navigeringsfältet. På fliken Datatillgångar väljer du Skapa, som du ser i den här skärmbilden:

Lägg till ett namn och en valfri beskrivning för den nya datatillgången på nästa skärm. Välj sedan Tabell i listrutan Typ , som du ser i den här skärmbilden:

På nästa skärm väljer du Från Azure Open Datasets och väljer sedan Nästa, som du ser i den här skärmbilden:
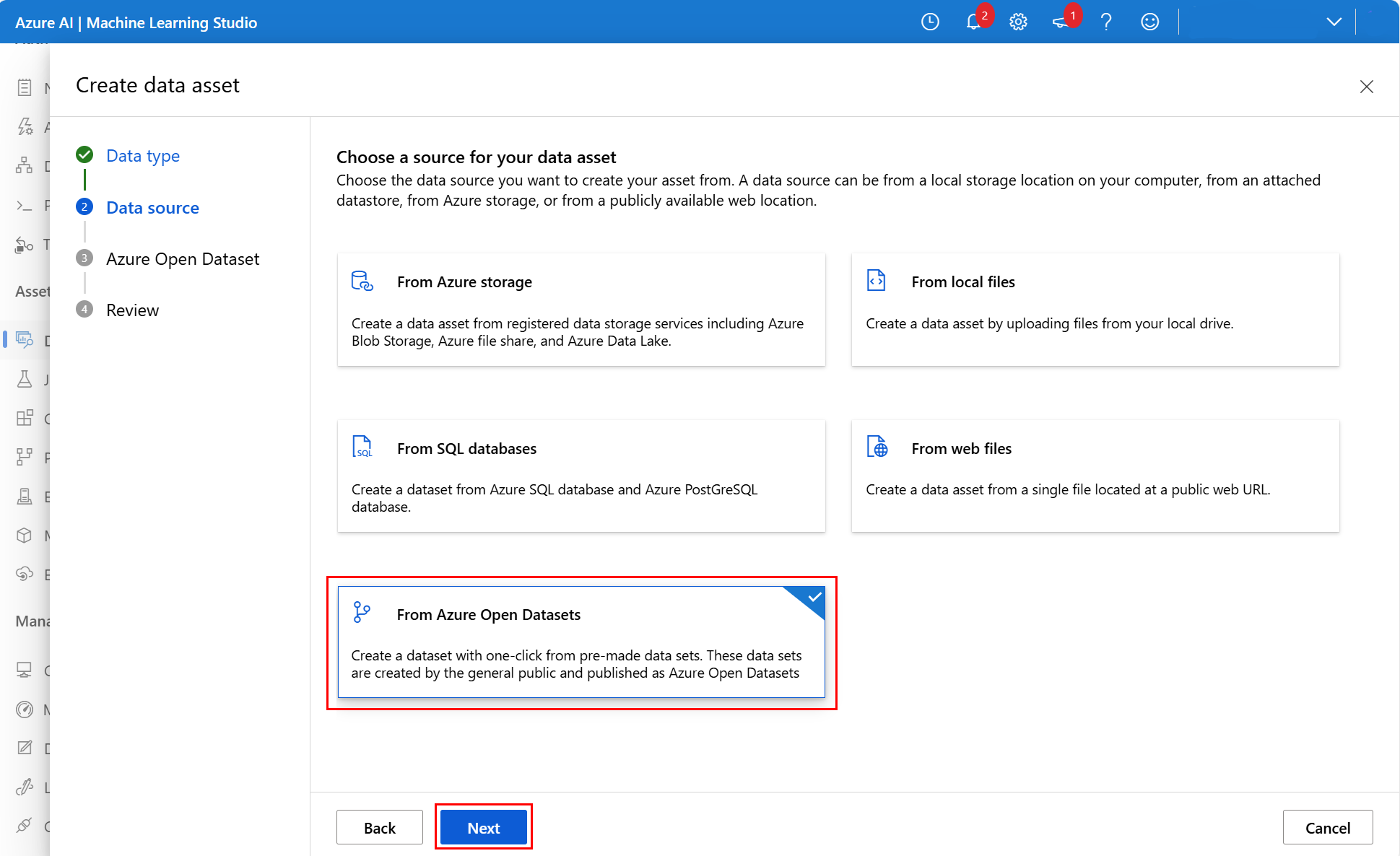
På nästa skärm väljer du en tillgänglig Azure Open Dataset. I den här skärmbilden valde vi Datauppsättningen San Francisco Safety Dataset :

Rulla nedåt om det behövs och välj Nästa, som du ser i den här skärmbilden:

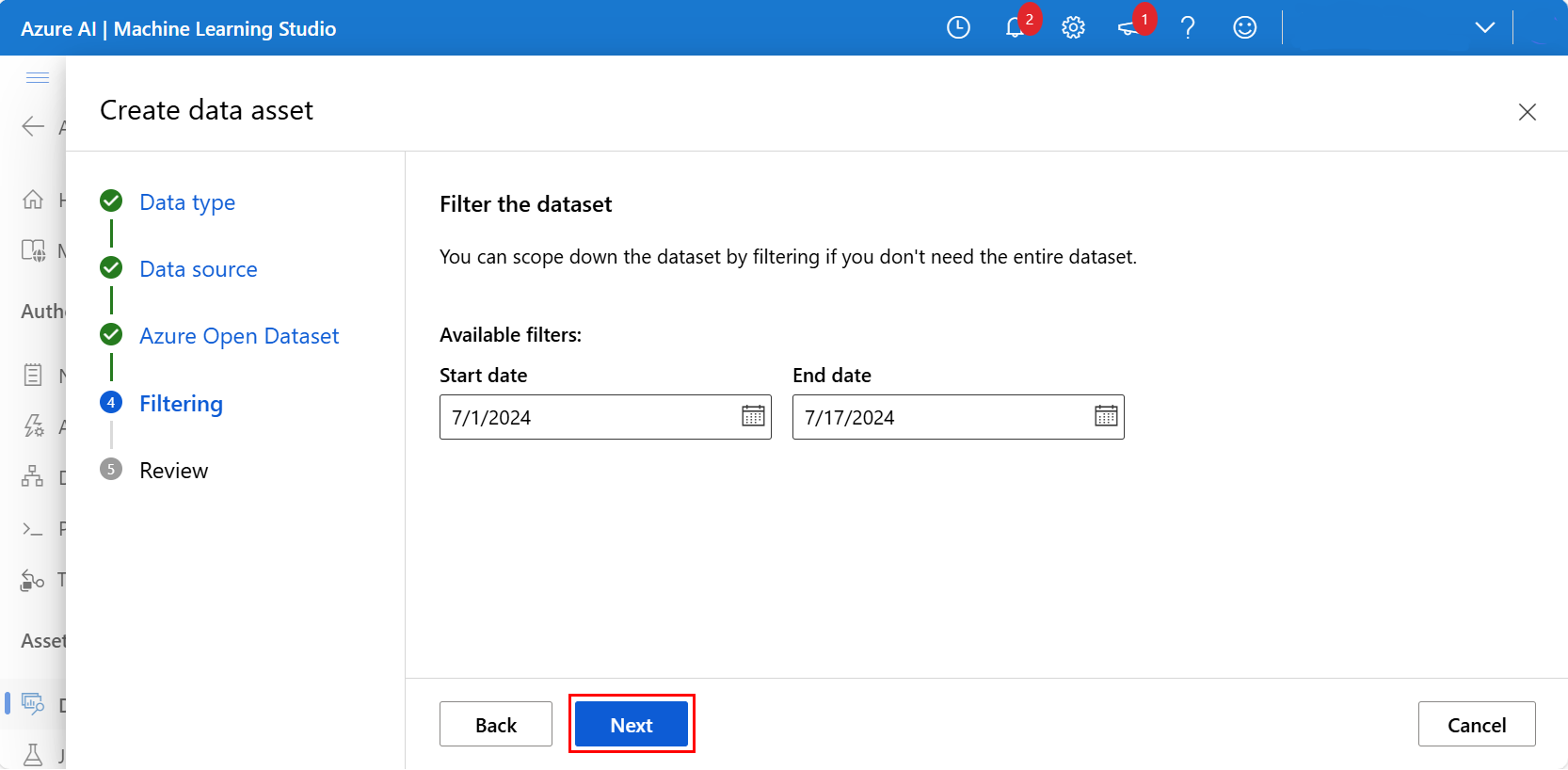
Du kan också filtrera data med de tillgängliga filtren, som är lämpliga för den valda datauppsättningen. För San Francisco Safety Data-datauppsättningen anger vi det filtrerade datumintervallet mellan ett startdatum den 1 juli 2024 och den 17 juli 2024. Välj Nästa, som du ser i den här skärmbilden:
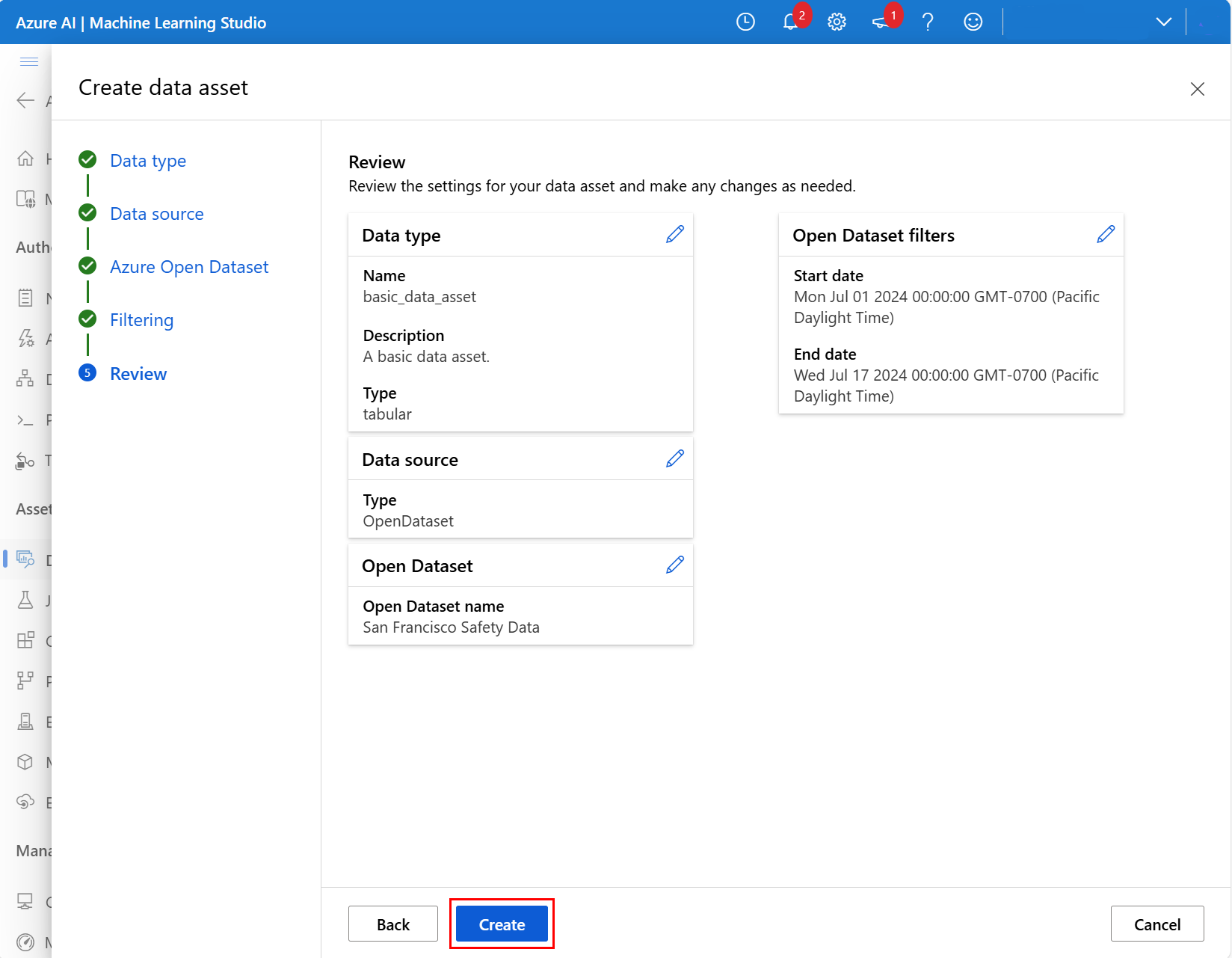
På nästa skärm granskar du inställningarna för den nya datatillgången och gör eventuella nödvändiga ändringar. När det verkar bra väljer du Skapa som det visas i den här skärmbilden:
Mer information om fältbeskrivningar och datumintervall för San Francisco Safety Data-datauppsättningen finns i San Francisco Safety Data-resursen. Mer information om de andra datauppsättningarna finns i resursen Azure Open Datasets Catalog .







Datamängden är nu tillgänglig på din arbetsyta under Datauppsättningar. Du kan använda den på samma sätt som de andra datauppsättningarna som du skapade.
Få åtkomst till datauppsättningar för dina experiment
Använd dina datamängder i dina maskininlärningsexperiment för att träna ML-modeller. Mer information finns i Läs mer om hur du tränar med datauppsättningar.
Exempelnotebook-filer
Exempel och demonstrationer av Open Datasets-funktioner finns i de här exempelanteckningsböckerna.