Skapa och köra maskininlärningspipelines med hjälp av komponenter med Azure Mašinsko učenje CLI
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
Azure CLI ml-tillägget v2 (aktuellt)
I den här artikeln får du lära dig hur du skapar och kör maskininlärningspipelines med hjälp av Azure CLI och komponenter. Du kan skapa pipelines utan att använda komponenter, men komponenter erbjuder största möjliga flexibilitet och återanvändning. Azure Mašinsko učenje Pipelines kan definieras i YAML och köras från CLI, redigeras i Python eller skapas i Azure Mašinsko učenje studio Designer med ett dra och släpp-användargränssnitt. Det här dokumentet fokuserar på CLI.
Förutsättningar
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Mašinsko učenje.
En Azure Machine Learning-arbetsyta. Skapa arbetsyteresurser.
Installera och konfigurera Azure CLI-tillägget för Mašinsko učenje.
Klona exempellagringsplatsen:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Föreslagen förläsning
Skapa din första pipeline med komponent
Nu ska vi skapa din första pipeline med komponenter med hjälp av ett exempel. Det här avsnittet syftar till att ge dig ett första intryck av hur en pipeline och komponent ser ut i Azure Mašinsko učenje med ett konkret exempel.
cli/jobs/pipelines-with-components/basics Från katalogen på lagringsplatsenazureml-examples navigerar du till underkatalogen3b_pipeline_with_data. Det finns tre typer av filer i den här katalogen. Det är de filer som du behöver skapa när du skapar en egen pipeline.
pipeline.yml: Den här YAML-filen definierar maskininlärningspipelinen. Den här YAML-filen beskriver hur du delar upp en fullständig maskininlärningsuppgift i ett arbetsflöde med flera steg. Om du till exempel överväger en enkel maskininlärningsuppgift att använda historiska data för att träna en modell för försäljningsprognoser, kanske du vill skapa ett sekventiellt arbetsflöde med databearbetning, modellträning och modellutvärderingssteg. Varje steg är en komponent som har ett väldefinierat gränssnitt och som kan utvecklas, testas och optimeras oberoende av varandra. YAML-pipelinen definierar också hur de underordnade stegen ansluter till andra steg i pipelinen, till exempel genererar modellträningssteget en modellfil och modellfilen skickas till ett modellutvärderingssteg.
component.yml: Den här YAML-filen definierar komponenten. Den paketar följande information:
- Metadata: namn, visningsnamn, version, beskrivning, typ osv. Metadata hjälper till att beskriva och hantera komponenten.
- Gränssnitt: indata och utdata. En modellträningskomponent tar till exempel träningsdata och antalet epoker som indata och genererar en tränad modellfil som utdata. När gränssnittet har definierats kan olika team utveckla och testa komponenten oberoende av varandra.
- Kommando, kod och miljö: kommandot, koden och miljön för att köra komponenten. Kommandot är kommandot shell för att köra komponenten. Kod refererar vanligtvis till en källkodskatalog. Miljön kan vara en Azure Mašinsko učenje-miljö (kuraterad eller kundskapad), docker-avbildning eller conda-miljö.
component_src: Det här är källkodskatalogen för en specifik komponent. Den innehåller källkoden som körs i komponenten. Du kan använda önskat språk (Python, R...). Koden måste köras av ett gränssnittskommando. Källkoden kan ta några indata från kommandoraden för att styra hur det här steget ska köras. Ett träningssteg kan till exempel ta träningsdata, inlärningshastighet, antal epoker för att styra träningsprocessen. Argumentet för ett gränssnittskommando används för att skicka indata och utdata till koden.
Nu ska vi skapa en pipeline med hjälp av 3b_pipeline_with_data exemplet. Vi förklarar den detaljerade innebörden av varje fil i följande avsnitt.
Ange först dina tillgängliga beräkningsresurser med följande kommando:
az ml compute list
Om du inte har det skapar du ett kluster med namnet cpu-cluster genom att köra:
Kommentar
Hoppa över det här steget om du vill använda serverlös beräkning.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
Skapa nu ett pipelinejobb som definierats i filen pipeline.yml med följande kommando. Beräkningsmålet refereras i filen pipeline.yml som azureml:cpu-cluster. Om beräkningsmålet använder ett annat namn ska du komma ihåg att uppdatera det i filen pipeline.yml.
az ml job create --file pipeline.yml
Du bör få en JSON-ordlista med information om pipelinejobbet, inklusive:
| Nyckel | beskrivning |
|---|---|
name |
Det GUID-baserade namnet på jobbet. |
experiment_name |
Namnet under vilket jobb ska organiseras i studio. |
services.Studio.endpoint |
En URL för övervakning och granskning av pipelinejobbet. |
status |
Jobbets status. Detta kommer sannolikt att vara Preparing vid denna tidpunkt. |
services.Studio.endpoint Öppna URL:en för att se en grafvisualisering av pipelinen.
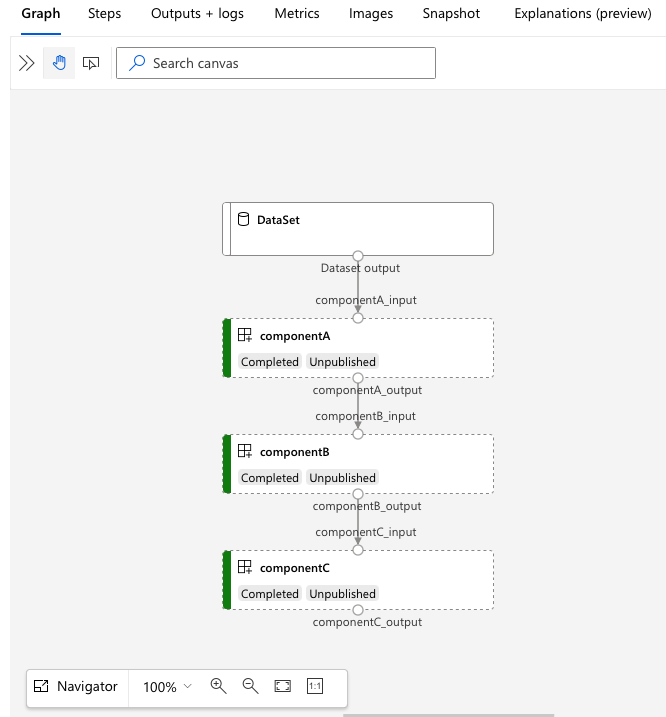
Förstå pipelinedefinitionen YAML
Nu ska vi ta en titt på pipelinedefinitionen i filen 3b_pipeline_with_data/pipeline.yml .
Kommentar
Om du vill använda serverlös beräkning ersätter du default_compute: azureml:cpu-cluster med default_compute: azureml:serverless i den här filen.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
Tabellen beskriver de vanligaste fälten i YAML-schema för pipeline. Mer information finns i yaml-schemat för hela pipelinen.
| key | description |
|---|---|
| type | Obligatoriska. Jobbtypen måste vara pipeline för pipelinejobb. |
| display_name | Visningsnamn för pipelinejobbet i studiogränssnittet. Redigerbart i studiogränssnittet. Behöver inte vara unikt för alla jobb på arbetsytan. |
| Jobb | Obligatoriska. Ordlista över den uppsättning enskilda jobb som ska köras som steg i pipelinen. Dessa jobb betraktas som underordnade jobb för det överordnade pipelinejobbet. I den här versionen är command jobbtyper som stöds i pipeline och sweep |
| Ingångar | Ordlista över indata till pipelinejobbet. Nyckeln är ett namn på indata i jobbets kontext och värdet är indatavärdet. Dessa pipelineindata kan refereras till av indata för ett enskilt stegjobb i pipelinen med hjälp av ${{ parent.inputs.<> input_name }} uttryck. |
| Utgångar | Ordlista över utdatakonfigurationer för pipelinejobbet. Nyckeln är ett namn på utdata i jobbets kontext och värdet är utdatakonfigurationen. Dessa pipelineutdata kan refereras till av utdata från ett enskilt stegjobb i pipelinen med hjälp av ${{ parents.outputs.<> output_name }}-uttryck. |
I det 3b_pipeline_with_data exemplet har vi skapat en pipeline i tre steg.
- De tre stegen definieras under
jobs. Alla tre steg är kommandojobb. Varje stegs definition finns i motsvarandecomponent.ymlfil. Du kan se YAML-komponentfilerna under 3b_pipeline_with_data katalog. Vi förklarar componentA.yml i nästa avsnitt. - Den här pipelinen har databeroende, vilket är vanligt i de flesta verkliga pipelines. Component_a tar dataindata från den lokala mappen under
./data(rad 17–20) och skickar utdata till componentB (rad 29). Component_a utdata kan refereras till som${{parent.jobs.component_a.outputs.component_a_output}}. computeDefinierar standardberäkningen för den här pipelinen. Om en komponent underjobsdefinierar en annan beräkning för den här komponenten respekterar systemet komponentspecifik inställning.

Läsa och skriva data i pipeline
Ett vanligt scenario är att läsa och skriva data i din pipeline. I Azure Mašinsko učenje använder vi samma schema för att läsa och skriva data för alla typer av jobb (pipelinejobb, kommandojobb och svepjobb). Följande är exempel på pipelinejobb för att använda data för vanliga scenarier.
- lokala data
- webbfil med offentlig URL
- Azure Mašinsko učenje datalager och sökväg
- Azure Mašinsko učenje datatillgång
Förstå komponentdefinitionen YAML
Nu ska vi titta på componentA.yml som ett exempel för att förstå komponentdefinitionen YAML.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
Det vanligaste använda schemat för komponenten YAML beskrivs i tabellen. Mer information finns i YAML-schemat för den fullständiga komponenten.
| key | description |
|---|---|
| name | Obligatoriska. Komponentens namn. Måste vara unikt i hela Azure Mašinsko učenje-arbetsytan. Måste börja med gemener. Tillåt gemener, siffror och understreck(_). Maximal längd är 255 tecken. |
| display_name | Visningsnamn för komponenten i studiogränssnittet. Kan vara icke-substantiv i arbetsytan. |
| kommando | Krävde att kommandot skulle köras |
| kod | Lokal sökväg till källkodskatalogen som ska laddas upp och användas för komponenten. |
| -miljö | Obligatoriska. Den miljö som används för att köra komponenten. |
| Ingångar | Ordlista över komponentindata. Nyckeln är ett namn på indata i komponentens kontext och värdet är komponentens indatadefinition. Indata kan refereras till i kommandot med hjälp av ${{ indata.<> input_name }} uttryck. |
| Utgångar | Ordlista över komponentutdata. Nyckeln är ett namn på utdata i komponentens kontext och värdet är komponentens utdatadefinition. Utdata kan refereras till i kommandot med hjälp av ${{ utdata.<> output_name }}-uttryck. |
| is_deterministic | Om det tidigare jobbets resultat ska återanvändas om komponentindata inte har ändrats. Standardvärdet är true, även kallat återanvändning som standard. Det vanliga scenariot när du anger som false är att framtvinga omläsning av data från en molnlagring eller URL. |
För exemplet i 3b_pipeline_with_data/componentA.yml har componentA en datainmatning och en datautdata, som kan anslutas till andra steg i den överordnade pipelinen. Alla filer under code avsnittet i komponenten YAML laddas upp till Azure Mašinsko učenje när du skickar pipelinejobbet. I det här exemplet laddas filer under ./componentA_src upp (rad 16 i componentA.yml). Du kan se den uppladdade källkoden i Studio-användargränssnittet: dubbelklicka på komponentA-steget och gå till fliken Ögonblicksbild, som du ser i följande skärmbild. Vi kan se att det är ett hello-world-skript som bara gör några enkla utskrifter och skriver aktuell datetime till componentA_output sökvägen. Komponenten tar indata och utdata via kommandoradsargument och hanteras i hello.py med hjälp av argparse.

Indata och utdata
Indata och utdata definierar gränssnittet för en komponent. Indata och utdata kan vara antingen av ett literalvärde (av typen string,number,integer eller ) eller booleanett objekt som innehåller indataschema.
Objektindata (av typen uri_file, uri_folder,mltable,mlflow_model,custom_model) kan ansluta till andra steg i det överordnade pipelinejobbet och därmed skicka data/modell till andra steg. I pipelinediagrammet återges objekttypens indata som en anslutningspunkt.
Literala värdeindata (string,number,integer,boolean) är de parametrar som du kan skicka till komponenten vid körning. Du kan lägga till standardvärdet för literalindata under default fält. För number och integer typ kan du också lägga till lägsta och högsta värde för det godkända värdet med hjälp av min och max fält. Om indatavärdet överskrider min och max misslyckas pipelinen vid valideringen. Verifieringen sker innan du skickar ett pipelinejobb för att spara tid. Valideringen fungerar för CLI, Python SDK och designergränssnittet. Följande skärmbild visar ett valideringsexempel i designergränssnittet. På samma sätt kan du definiera tillåtna värden i enum fältet.

Kom ihåg att redigera tre platser om du vill lägga till indata till en komponent:
inputsfält i komponenten YAMLcommandi komponenten YAML.- Komponentkällkod för att hantera kommandoradsindata. Den är markerad i grön ruta i föregående skärmbild.
Mer information om indata och utdata finns i Hantera indata och utdata för komponent och pipeline.
Environment
Miljön definierar miljön för att köra komponenten. Det kan vara en Azure Mašinsko učenje-miljö (kuraterad eller anpassad registrerad), docker-avbildning eller conda-miljö. Se följande exempel.
- Azure Mašinsko učenje registrerad miljötillgång. Den refereras i komponenten efter
azureml:<environment-name>:<environment-version>syntaxen. - offentlig docker-avbildning
- conda-filen Conda-filen måste användas tillsammans med en basavbildning.
Registrera komponent för återanvändning och delning
Vissa komponenter är specifika för en viss pipeline, men den verkliga fördelen med komponenter kommer från återanvändning och delning. Registrera en komponent i din Mašinsko učenje arbetsyta för att göra den tillgänglig för återanvändning. Registrerade komponenter stöder automatisk versionshantering så att du kan uppdatera komponenten, men se till att pipelines som kräver en äldre version fortsätter att fungera.
Gå till cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components katalogen på lagringsplatsen azureml-examples.
Om du vill registrera en komponent använder du az ml component create kommandot:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
När dessa kommandon har körts kan du se komponenterna i Studio under Tillgång –> Komponenter:

Välj en komponent. Du ser detaljerad information för varje version av komponenten.
Under fliken Information ser du grundläggande information om komponenten som namn, skapad av, version osv. Du ser redigerbara fält för Taggar och Beskrivning. Taggarna kan användas för att lägga till snabbt sökta nyckelord. Beskrivningsfältet stöder Markdown-formatering och bör användas för att beskriva komponentens funktioner och grundläggande användning.
Under fliken Jobb visas historiken för alla jobb som använder den här komponenten.
Använda registrerade komponenter i en YAML-fil för pipelinejobb
Nu ska vi använda 1b_e2e_registered_components för att demonstrera hur du använder den registrerade komponenten i YAML-pipelinen. Gå till 1b_e2e_registered_components katalogen och öppna pipeline.yml filen. Nycklarna och värdena i fälten inputs och outputs liknar de som redan har diskuterats. Den enda signifikanta skillnaden är värdet för component fältet i posterna jobs.<JOB_NAME>.component . Värdet component är av formuläret azureml:<COMPONENT_NAME>:<COMPONENT_VERSION>. Definitionen train-job anger till exempel att den senaste versionen av den registrerade komponenten my_train ska användas:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Hantera komponenter
Du kan kontrollera komponentinformationen och hantera komponenten med hjälp av CLI (v2). Använd az ml component -h för att få detaljerade instruktioner om komponentkommandot. I följande tabell visas alla tillgängliga kommandon. Se fler exempel i Azure CLI-referens.
| kommandon | description |
|---|---|
az ml component create |
Skapa en komponent |
az ml component list |
Visa en lista över komponenter i en arbetsyta |
az ml component show |
Visa information om en komponent |
az ml component update |
Uppdatera en komponent. Endast ett fåtal fält (beskrivning, display_name) stöder uppdatering |
az ml component archive |
Arkivera en komponentcontainer |
az ml component restore |
Återställa en arkiverad komponent |
Nästa steg
- Prova CLI v2-komponentexempel