Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
Azure CLI ml-tillägget v2 (aktuellt)
I den här artikeln får du lära dig hur du skapar och kör maskininlärningspipelines med hjälp av Azure Machine Learning-studio och komponenter. Du kan skapa pipelines utan att använda komponenter, men komponenter ger bättre flexibilitet och återanvändning. Azure Machine Learning-pipelines kan definieras i YAML och köras från CLI, redigeras i Python eller skapas i Azure Machine Learning-studio Designer med ett dra och släpp-användargränssnitt. Det här dokumentet fokuserar på användargränssnittet för Azure Machine Learning-studio designer.
Förutsättningar
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning.
En Azure Machine Learning-arbetsyta Skapa arbetsyteresurser.
Installera och konfigurera Azure CLI-tillägget för Machine Learning.
Klona exempellagringsplatsen:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Kommentar
Designer stöder två typer av komponenter, klassiska fördefinierade komponenter(v1) och anpassade komponenter(v2). Dessa två typer av komponenter är INTE kompatibla.
Klassiska fördefinierade komponenter ger fördefinierade komponenter huvudsakligen för databearbetning och traditionella maskininlärningsuppgifter som regression och klassificering. Klassiska fördefinierade komponenter fortsätter att stödjas men kommer inte att ha några nya komponenter tillagda. Distributionen av klassiska fördefinierade (v1) komponenter stöder inte hanterade onlineslutpunkter (v2).
Med anpassade komponenter kan du omsluta din egen kod som en komponent. Den stöder delning av komponenter mellan arbetsytor och sömlös redigering i studio-, CLI v2- och SDK v2-gränssnitt.
För nya projekt rekommenderar vi starkt att du använder anpassad komponent, som är kompatibel med AzureML V2 och fortsätter att ta emot nya uppdateringar.
Den här artikeln gäller för anpassade komponenter.
Registrera komponenten på din arbetsyta
Om du vill skapa en pipeline med hjälp av komponenter i användargränssnittet måste du först registrera komponenter till din arbetsyta. Du kan använda UI, CLI eller SDK för att registrera komponenter till din arbetsyta, så att du kan dela och återanvända komponenten på arbetsytan. Registrerade komponenter stöder automatisk versionshantering så att du kan uppdatera komponenten, men se till att pipelines som kräver en äldre version fortsätter att fungera.
I följande exempel används användargränssnittet för att registrera komponenter, och komponentkällfilerna finns i katalogen på lagringsplatsencli/jobs/pipelines-with-components/basics/1b_e2e_registered_components.azureml-examples Du måste klona lagringsplatsen till lokal först.
På din Azure Machine Learning-arbetsyta går du till sidan Komponenter och väljer Ny komponent. En av de två formatsidorna visas:
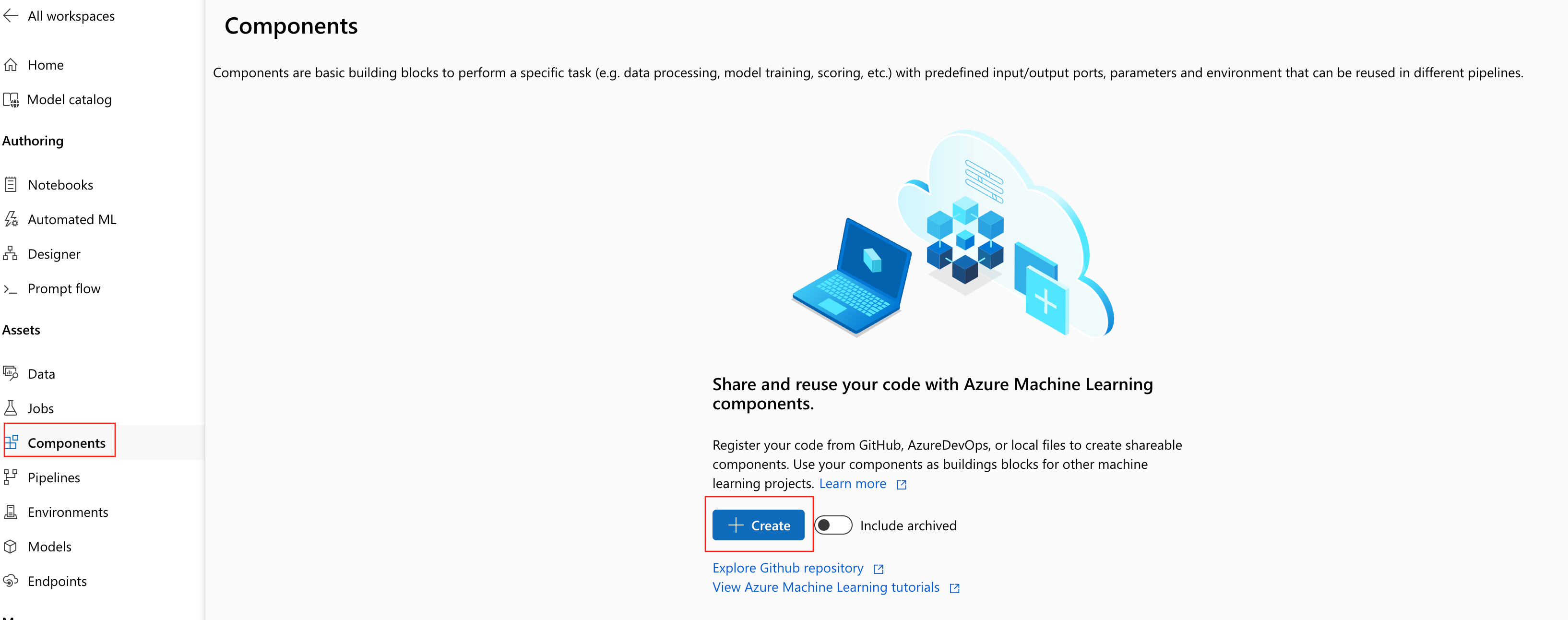
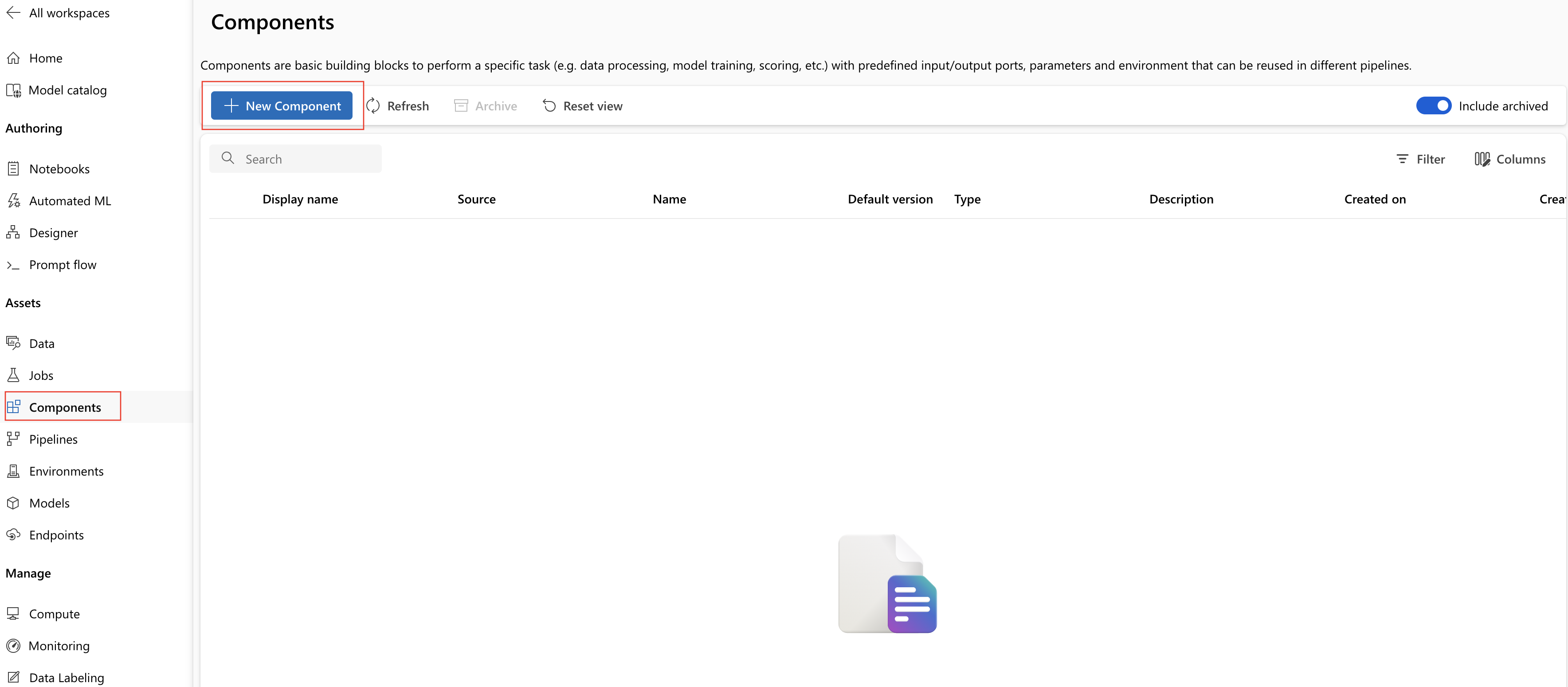


Det här exemplet används train.ymli katalogen 1b_e2e_registered_components. YAML-filen definierar namn, typ, gränssnitt inklusive indata och utdata, kod, miljö och kommando för den här komponenten. Koden för den här komponenten train.py finns under ./train_src mappen, som beskriver körningslogik för den här komponenten. Mer information om komponentschemat finns i yaml-schemareferensen för kommandokomponenten.
Kommentar
När du registrerar komponenter i användargränssnittet code kan det som definieras i yaml-komponentfilen bara peka på den aktuella mappen där YAML-filen hittar eller undermapparna, vilket innebär att du inte kan ange ../ för code eftersom användargränssnittet inte kan identifiera den överordnade katalogen.
additional_includes kan bara peka på den aktuella mappen eller undermappen.
För närvarande stöder användargränssnittet endast registrering av komponenter med command typ.
- Välj Ladda upp från mapp och välj den mapp som
1b_e2e_registered_componentsska laddas upp. Väljtrain.ymli listrutan.

Välj Nästa längst ned och du kan bekräfta informationen om den här komponenten. När du har bekräftat väljer du Skapa för att slutföra registreringsprocessen.
Upprepa föregående steg för att registrera score- och Eval-komponenten med och
score.ymleval.ymlockså.När du har registrerat de tre komponenterna kan du se dina komponenter i studiogränssnittet.

Skapa pipeline med hjälp av en registrerad komponent
Skapa en ny pipeline i designern. Kom ihåg att välja alternativet Anpassad .

Ge pipelinen ett beskrivande namn genom att välja pennikonen förutom det automatiskt genererade namnet.
I designertillgångsbiblioteket kan du se flikarna Data, Modell och Komponenter . Växla till fliken Komponenter . Du kan se de komponenter som registrerats från föregående avsnitt. Om det finns för många komponenter kan du söka med komponentnamnet.
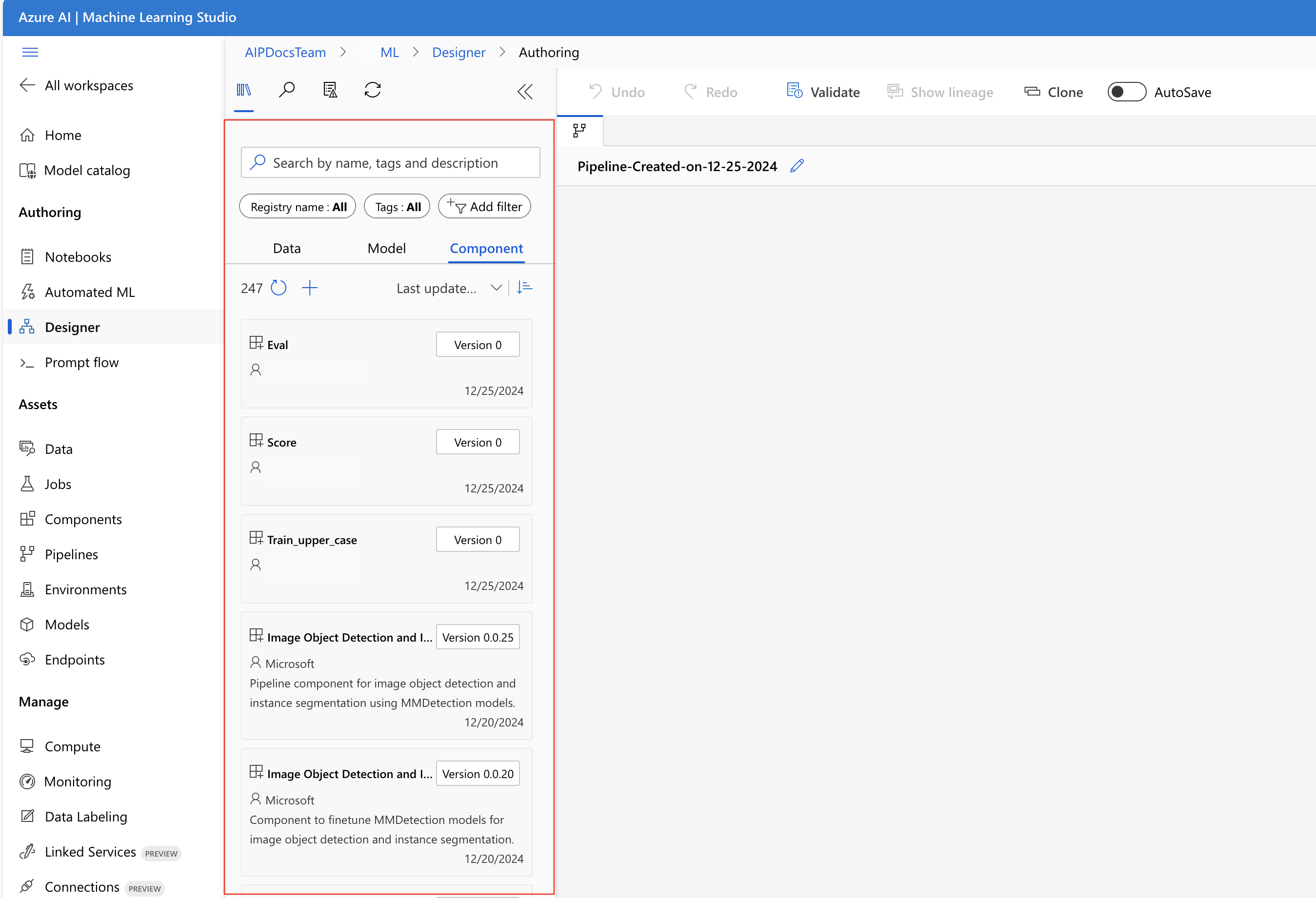
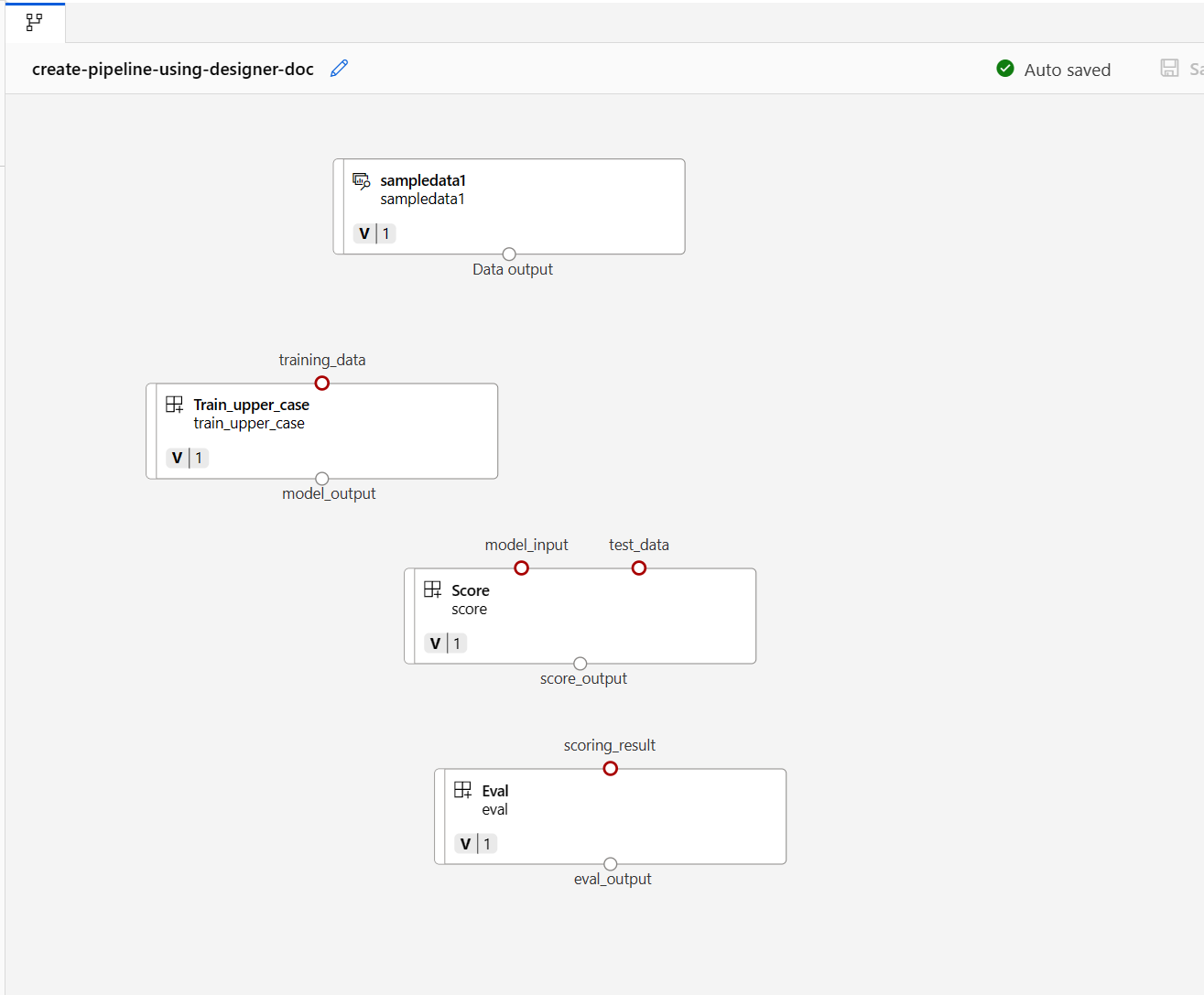
Leta upp komponenterna train, score och eval som registrerades i föregående avsnitt och dra och släpp dem sedan på arbetsytan. Som standard används standardversionen av komponenten. Om du vill ändra till en viss version dubbelklickar du på komponenten för att öppna komponentfönstret.
I det här exemplet använder vi exempeldata i datamappen. Registrera data i arbetsytan genom att välja ikonen Lägg till i designertillgångsbiblioteket –> datafliken, ange Typ = Mapp(uri_folder) och följ sedan guiden för att registrera data. Datatypen måste vara uri_folder för att överensstämma med definitionen för träningskomponenten.

Dra och släpp sedan data till arbetsytan. Pipeline-utseendet bör se ut som på följande skärmbild nu.
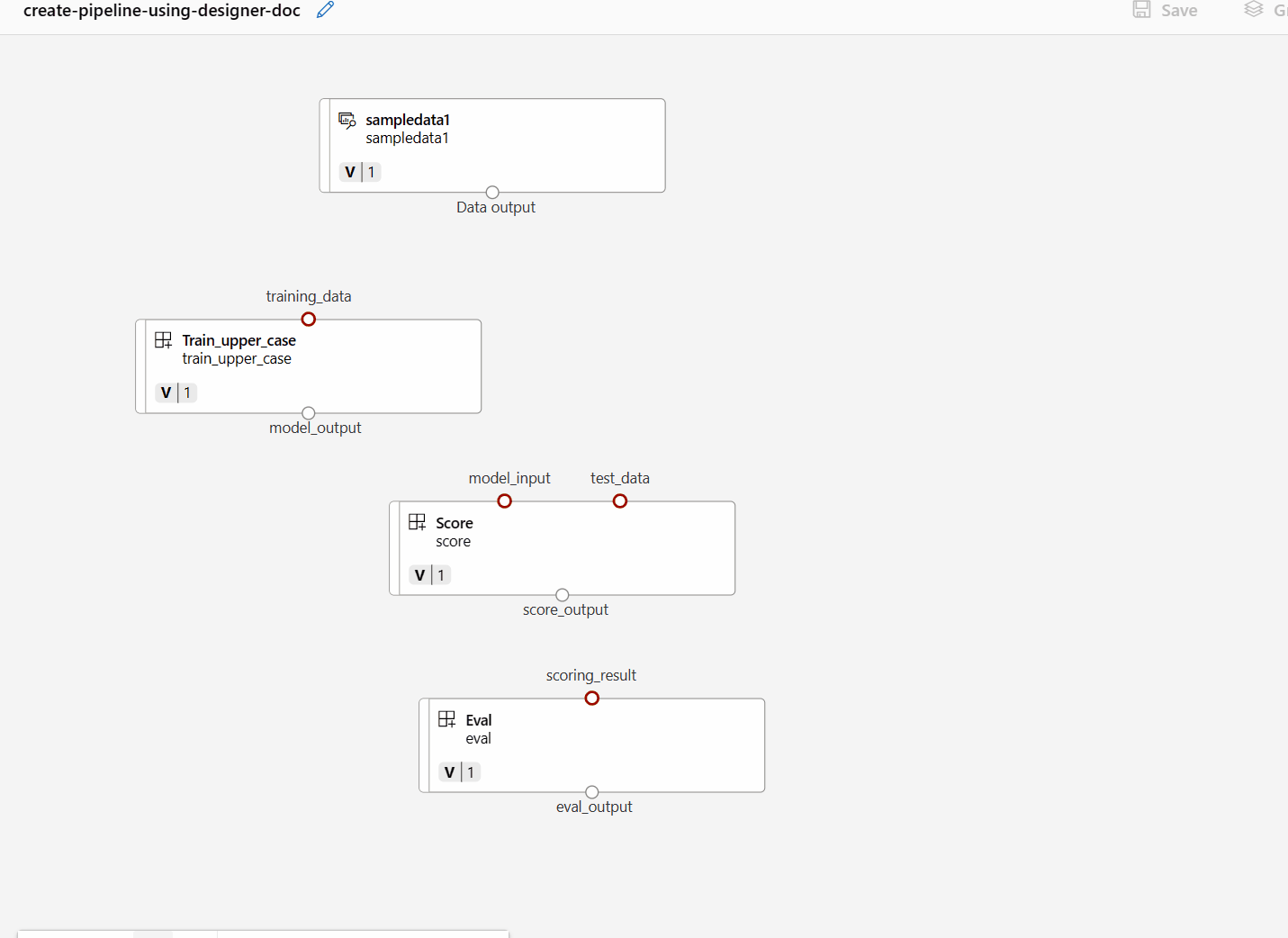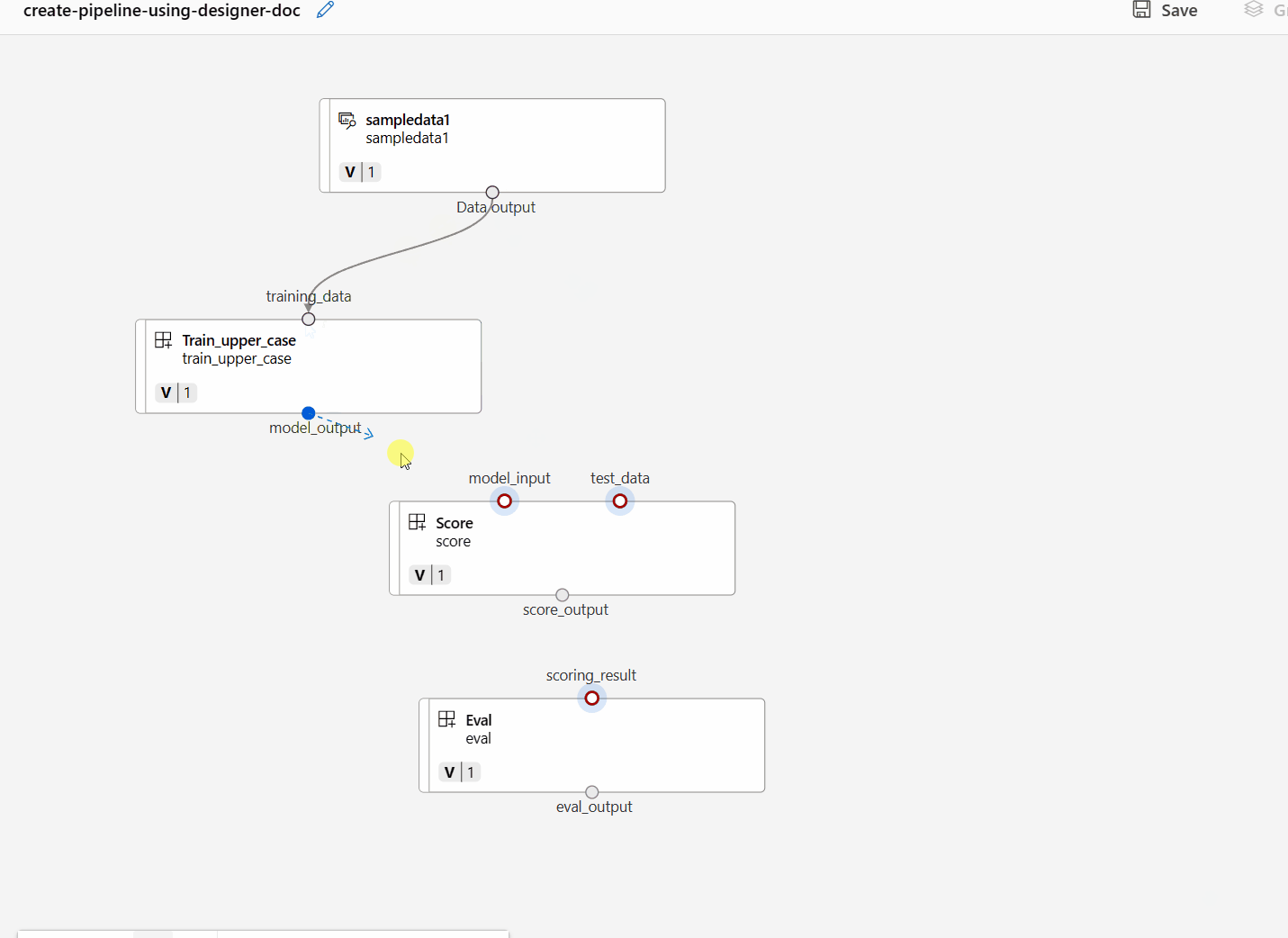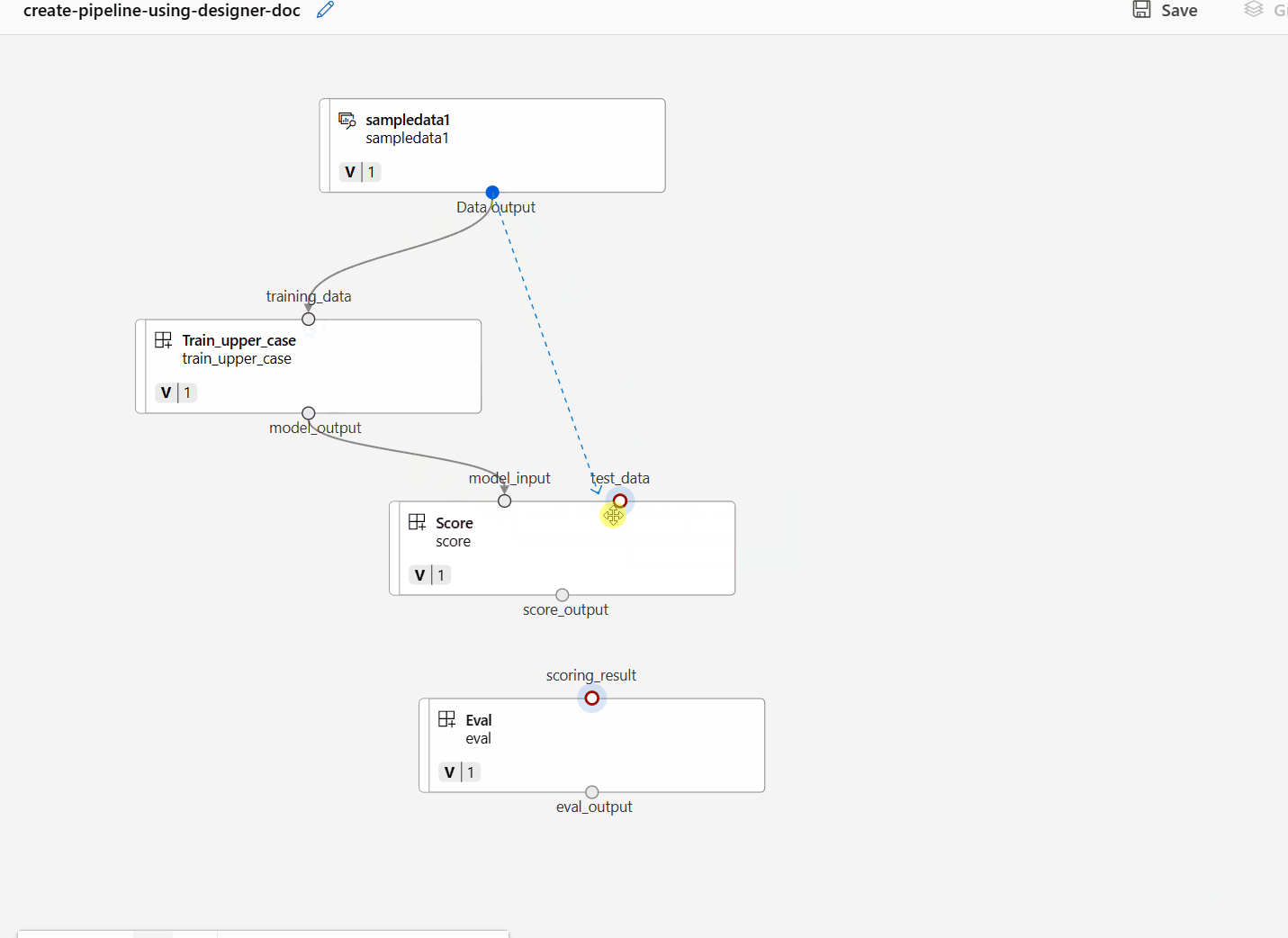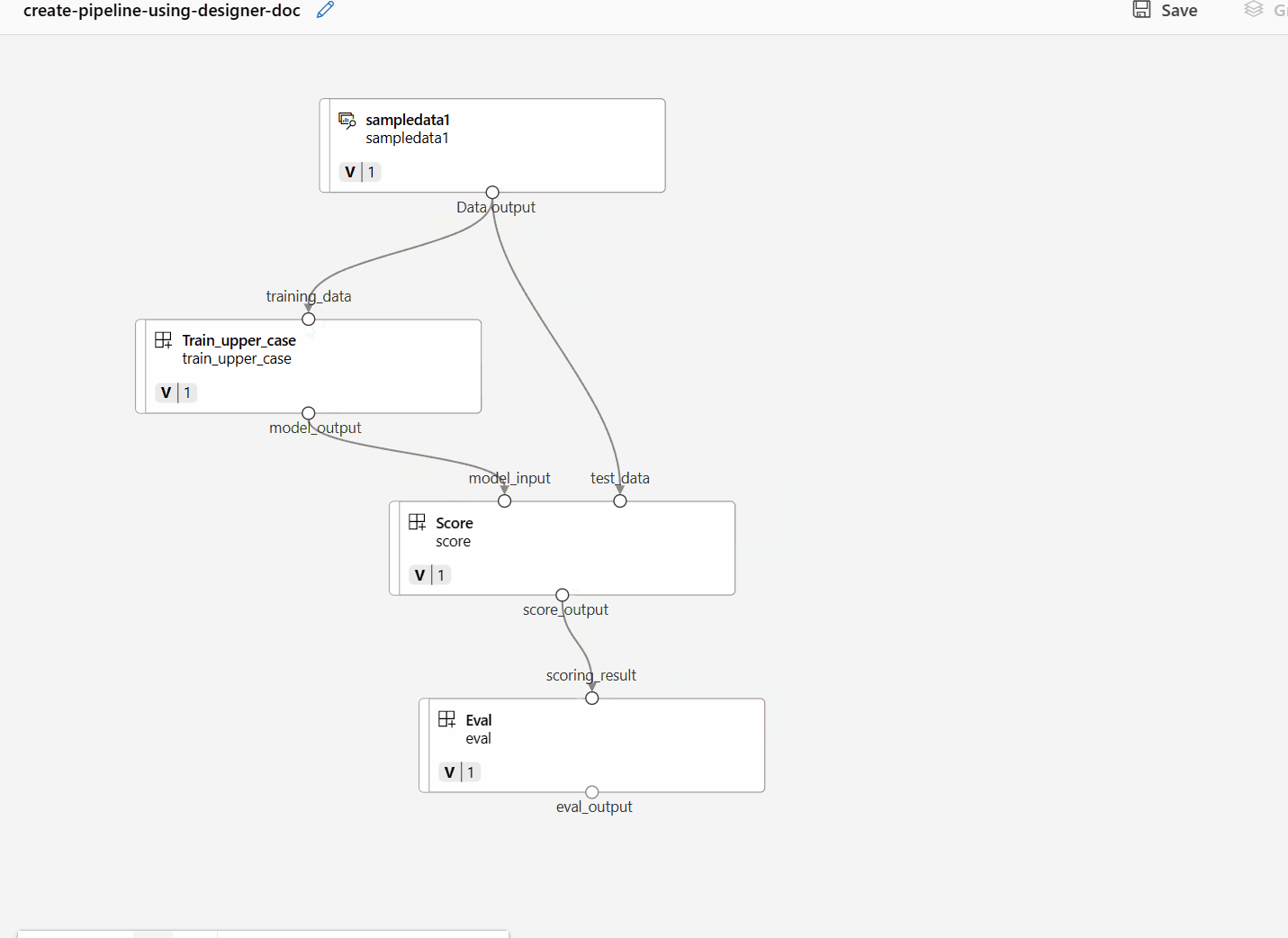
Anslut data och komponenter genom att dra anslutningar på arbetsytan.
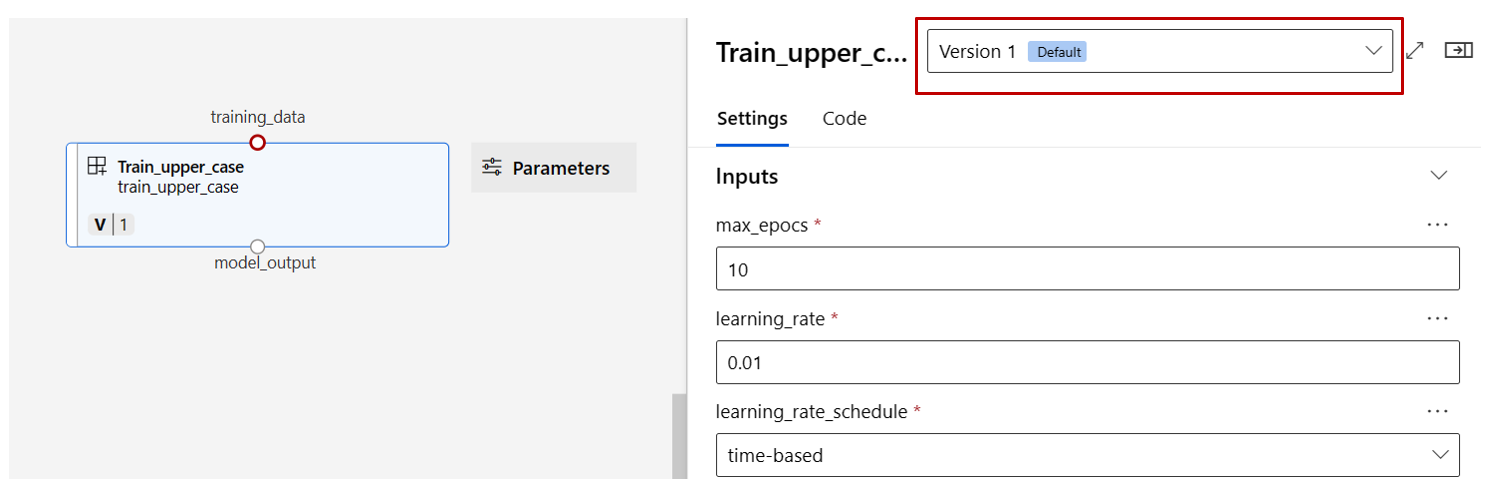
Dubbelklicka på en komponent. Du ser ett högerfönster där du kan konfigurera komponenten.
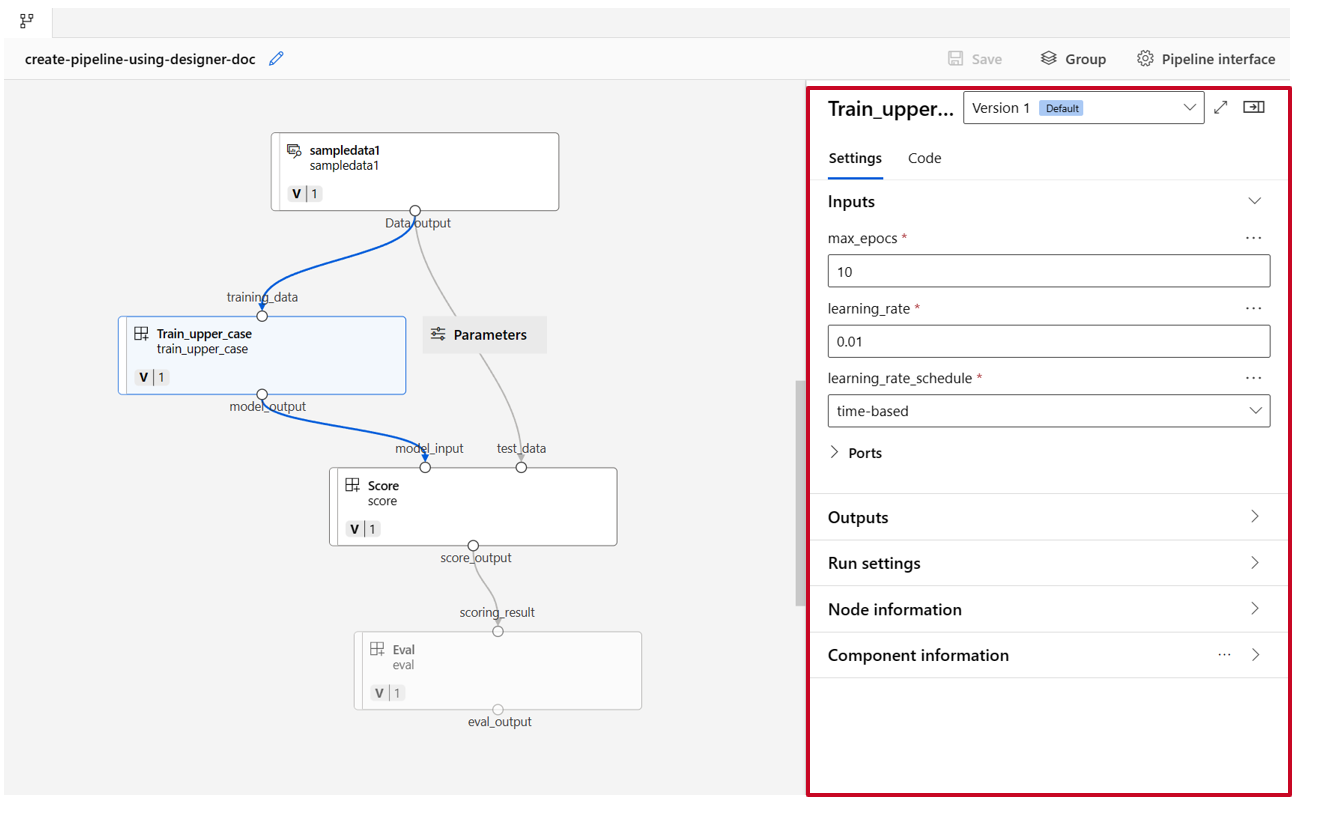
För komponenter med primitiva typindata som tal, heltal, sträng och booleskt värde kan du ändra värdena för sådana indata i den detaljerade komponentfönstret under avsnittet Indata .
Du kan också ändra utdatainställningarna (var komponentens utdata ska lagras) och körningsinställningarna (beräkningsmålet för att köra den här komponenten) i den högra rutan.
Nu ska vi höja upp max_epocs indata för träningskomponenten till indata på pipelinenivå. På så sätt kan du tilldela ett annat värde till den här indatan varje gång innan du skickar pipelinen.
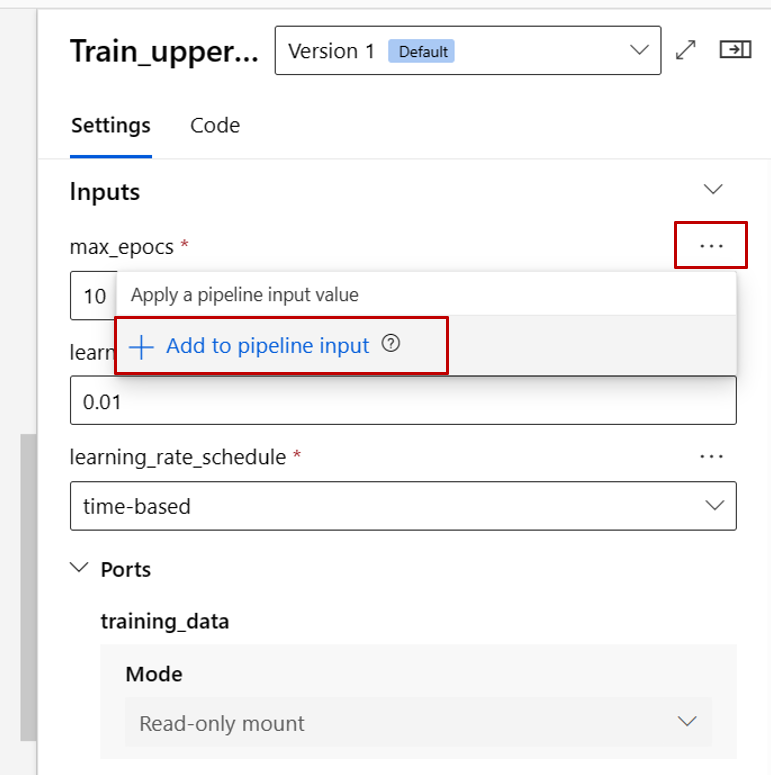









Kommentar
Anpassade komponenter och de klassiska designkomponenterna kan inte användas tillsammans.
Skicka pipeline
Välj Konfigurera och skicka för att skicka pipelinen.

Sedan visas en stegvis guide. Följ guiden för att skicka pipelinejobbet.

I steget Grundläggande kan du konfigurera experimentet, jobbets visningsnamn, jobbbeskrivning osv.
I steget Indata och utdata kan du konfigurera indata/utdata som höjs upp till pipelinenivå. I föregående steg höjde vi max_epocs för träningskomponenten till pipelineindata, så du bör kunna se och tilldela värde till max_epocs här.
I Körningsinställningar kan du konfigurera standarddatalager och standardberäkning av pipelinen. Det är standarddatalager/beräkning för alla komponenter i pipelinen. Observera dock att om du anger en annan beräkning eller ett annat datalager för en komponent uttryckligen respekterar systemet inställningen för komponentnivå. Annars används standardvärdet för pipelinen.
Steget Granska + skicka är det sista steget för att granska alla konfigurationer innan du skickar. Guiden kommer ihåg konfigurationen för senaste gången om du skickar pipelinen.
När du har skickat pipelinejobbet visas ett meddelande längst upp med en länk till jobbinformationen. Du kan välja den här länken för att granska jobbinformationen.

Ange identitet i pipelinejobb
När du skickar pipelinejobbet kan du ange identiteten för att komma åt data under Run settings. Standardidentiteten är AMLToken den som inte använde någon identitet under tiden som vi stöder både UserIdentity och Managed. För UserIdentityanvänds identiteten för jobbinskickare för att komma åt indata och skriva resultatet till utdatamappen. Om du anger Managedanvänder systemet den hanterade identiteten för att komma åt indata och skriva resultatet till utdatamappen.

Nästa steg
- Använd de här Jupyter-notebook-filerna på GitHub för att utforska maskininlärningspipelines ytterligare
- Lär dig hur du använder CLI v2 för att skapa pipeline med hjälp av komponenter.
- Lär dig hur du använder SDK v2 för att skapa pipeline med hjälp av komponenter