Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Den här artikeln visar hur du skapar och hanterar datatillgångar i Azure Machine Learning.
Datatillgångar kan hjälpa dig när du behöver:
- Versionshantering: Datatillgångar stöder dataversionshantering.
- Reproducerbarhet: När du har skapat en datatillgångsversion är den oföränderlig. Det går inte att ändra eller ta bort den. Därför kan träningsjobb eller pipelines som använder datatillgången återskapas.
- Granskningsbarhet: Eftersom datatillgångsversionen är oföränderlig kan du spåra tillgångsversionerna, vem som uppdaterade en version och när versionsuppdateringarna inträffade.
- Ursprung: För en viss datatillgång kan du visa vilka jobb eller pipelines som använder data.
- Användarvänlighet: En Azure-maskininlärningsdatatillgång liknar webbläsarbokmärken (favoriter). I stället för att komma ihåg långa lagringssökvägar (URI:er) som refererar till
Dricks
För att få åtkomst till dina data i en interaktiv session (till exempel en notebook-fil) eller ett jobb behöver du inte först skapa en datatillgång. Du kan använda Datastore-URI:er för att komma åt data. URI:er för datalager är ett enkelt sätt att komma igång med Azure Machine Learning.
Förutsättningar
Om du vill skapa och arbeta med datatillgångar behöver du:
En Azure-prenumeration Om du inte har ett konto kan du skapa ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning.
En Azure Machine Learning-arbetsyta. Skapa arbetsyteresurser.
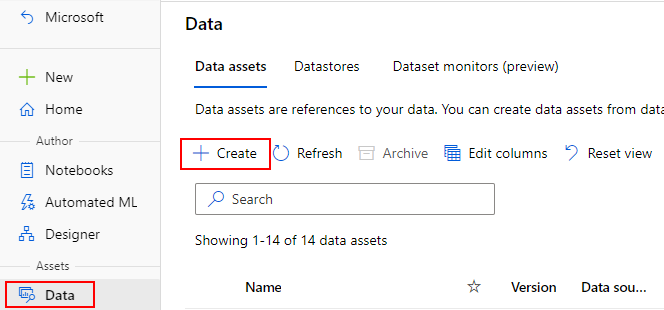
Skapa datatillgångar
När du skapar datatillgången måste du ange datatillgångstypen. Azure Machine Learning stöder tre typer av datatillgång:
| Typ | API (gränssnitt för programmering av applikationer) | Kanoniska scenarier |
|---|---|---|
|
Arkiv Referera till en enskild fil |
uri_file |
Läs en enda fil i Azure Storage (filen kan ha valfritt format). |
|
Mapp Referera till en mapp |
uri_folder |
Läs en mapp med parquet-/CSV-filer till Pandas/Spark. Läs ostrukturerade data (bilder, text, ljud osv.) som finns i en mapp. |
|
Tabell Referera till en datatabell |
mltable |
Du har ett komplext schema som kan ändras ofta, eller så behöver du en delmängd med stora tabelldata. AutoML med tabeller. Läs ostrukturerade data (bilder, text, ljud osv.) data som är spridda över flera lagringsplatser. |
Kommentar
Använd endast inbäddade newlines i csv-filer om du registrerar data som en MLTable. Inbäddade nya radlinjer i csv-filer kan orsaka feljusterade fältvärden när du läser data. MLTable har parametern support_multi_line tillgänglig i omvandlingen read_delimited för att tolka citerade radbrytningar som en post.
När du använder datatillgången i ett Azure Machine Learning-jobb kan du antingen montera eller ladda ned tillgången till beräkningsnoderna. Mer information finns i Lägen.
Du måste också ange en path parameter som pekar på datatillgångens plats. Sökvägar som stöds är:
| Plats | Exempel |
|---|---|
| En sökväg på den lokala datorn | ./home/username/data/my_data |
| En sökväg i ett datalager | azureml://datastores/<data_store_name>/paths/<path> |
| En sökväg på en offentlig https-server | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| En sökväg i Azure Storage | (Blob) wasbs://<containername>@<accountname>.blob.core.windows.net/<path_to_data>/(ADLS gen2) abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> (ADLS gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
Kommentar
När du skapar en datatillgång från en lokal sökväg laddas den automatiskt upp till standardmolnlagringen i Azure Machine Learning.
Skapa en datatillgång: Filtyp
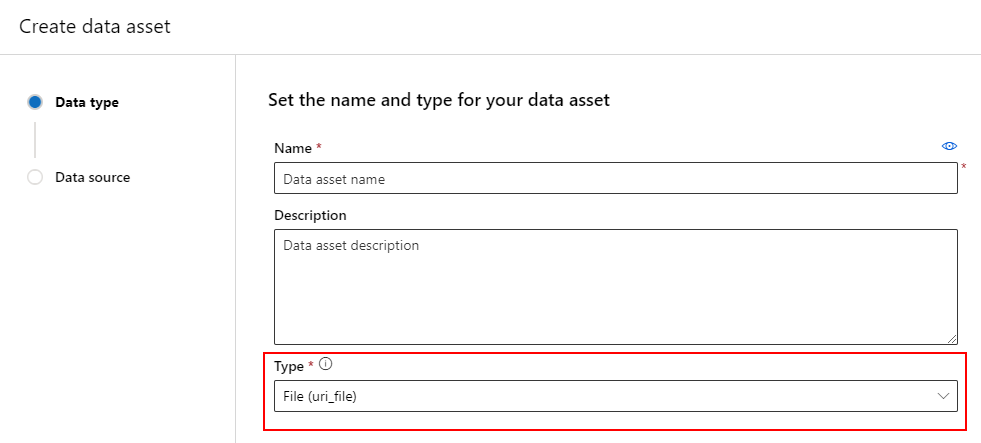
En datatillgång av typen Fil (uri_file) pekar på en enda fil i lagringen (till exempel en CSV-fil). Du kan skapa en filtypad datatillgång med:
Skapa en YAML-fil och kopiera och klistra in följande kodfragment. Se till att uppdatera <> platshållarna med
- namnet på datatillgången
- versionen
- beskrivning
- sökväg till en enda fil på en plats som stöds
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Kör sedan följande kommando i CLI. Se till att uppdatera <filename> platshållaren till YAML-filnamnet.
az ml data create -f <filename>.yml
Skapa en datatillgång: Mapptyp
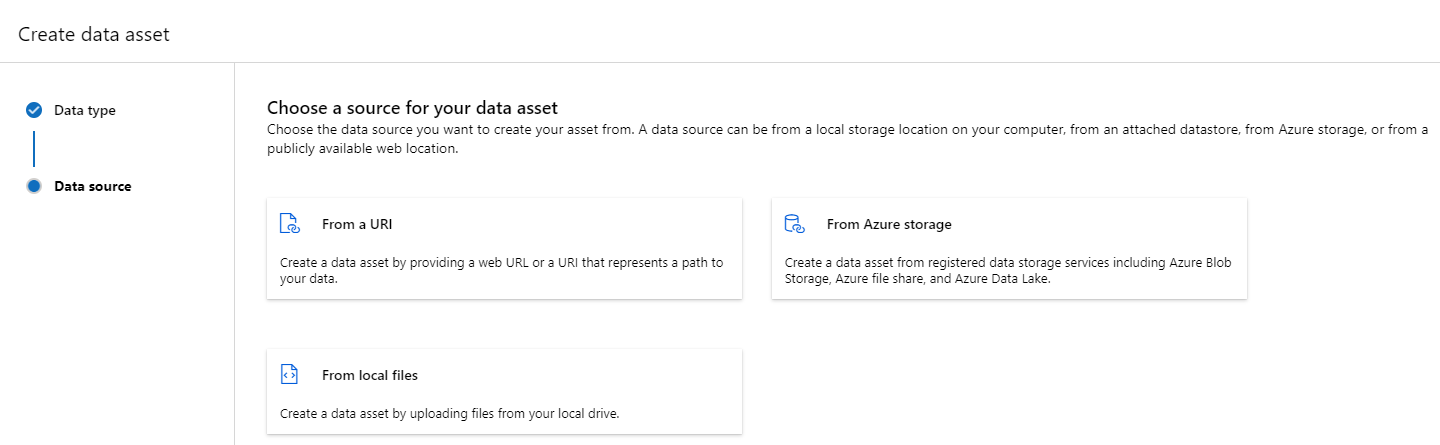
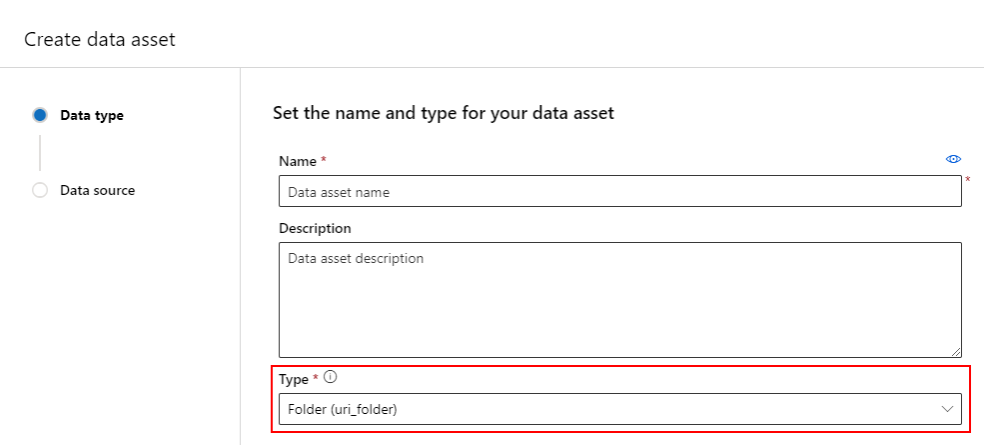
En mapp (uri_folder) skriver datatillgångspunkter till en mapp i en lagringsresurs , till exempel en mapp som innehåller flera undermappar med bilder. Du kan skapa en mapptypad datatillgång med:
Kopiera och klistra in följande kod i en ny YAML-fil. Se till att uppdatera <> platshållarna med
- Namnet på datatillgången
- Versionen
- beskrivning
- Sökväg till en mapp på en plats som stöds
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
Kör sedan följande kommando i CLI. Se till att uppdatera <filename> platshållaren till YAML-filnamnet.
az ml data create -f <filename>.yml
Skapa en datatillgång: Tabelltyp
Azure Machine Learning-tabeller (MLTable) har omfattande funktioner som beskrivs mer detaljerat i Arbeta med tabeller i Azure Machine Learning. I stället för att upprepa dokumentationen här kan du läsa det här exemplet som beskriver hur du skapar en tabelltypad datatillgång med Titanic-data som finns på ett offentligt tillgängligt Azure Blob Storage-konto.
Skapa först en ny katalog med namnet data och skapa en fil med namnet MLTable:
mkdir data
touch MLTable
Kopiera och klistra sedan in följande YAML i MLTable-filen som du skapade i föregående steg:
Varning
Byt . Azure Machine Learning förväntar sig en MLTable fil.
paths:
- file: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
Kör följande kommando i CLI. Se till att uppdatera <> platshållarna med datatillgångens namn och versionsvärden.
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
Viktigt!
path Ska vara en mapp som innehåller en giltig MLTable fil.
Skapa datatillgångar från jobbutdata
Du kan skapa en datatillgång från ett Azure Machine Learning-jobb. Det gör du genom att ange parametern name i utdata. I det här exemplet skickar du ett jobb som kopierar data från ett offentligt bloblager till ditt standarddatalager för Azure Machine Learning och skapar en datatillgång med namnet job_output_titanic_asset.
Skapa en YAML-fil för jobbspecifikation (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
Skicka sedan jobbet med hjälp av CLI:
az ml job create --file <file-name>.yml
Hantera datatillgångar
Radera en datatillgång
Viktigt!
Borttagning av datatillgång stöds inte avsiktligt.
Om Azure Machine Learning tillät borttagning av datatillgånger skulle det ha följande negativa och negativa effekter:
- Produktionsjobb som använder datatillgångar som senare togs bort skulle misslyckas.
- Det skulle bli svårare att återskapa ett ML-experiment.
- Jobbets ursprung skulle brytas eftersom det skulle bli omöjligt att visa den borttagna datatillgångsversionen.
- Du skulle inte kunna spåra och granska korrekt eftersom versioner kan saknas.
Därför ger datatillgångarnas oföränderlighet en skyddsnivå när du arbetar i ett team som skapar produktionsarbetsbelastningar.
För en felaktigt skapad datatillgång – till exempel med ett felaktigt namn, typ eller sökväg – erbjuder Azure Machine Learning lösningar för att hantera situationen utan de negativa konsekvenserna av borttagning:
| Jag vill ta bort den här datatillgången eftersom... | Lösning |
|---|---|
| Namnet är felaktigt | Arkivera datatillgången |
| Teamet använder inte längre datatillgången | Arkivera datatillgången |
| Det belamrar listan över datatillgånger | Arkivera datatillgången |
| Sökvägen är felaktig | Skapa en ny version av datatillgången (samma namn) med rätt sökväg. Mer information finns i Skapa datatillgångar. |
| Den har en felaktig typ | För närvarande tillåter Inte Azure Machine Learning skapandet av en ny version med en annan typ jämfört med den ursprungliga versionen. (1) Arkivera datatillgången (2) Skapa en ny datatillgång under ett annat namn med rätt typ. |
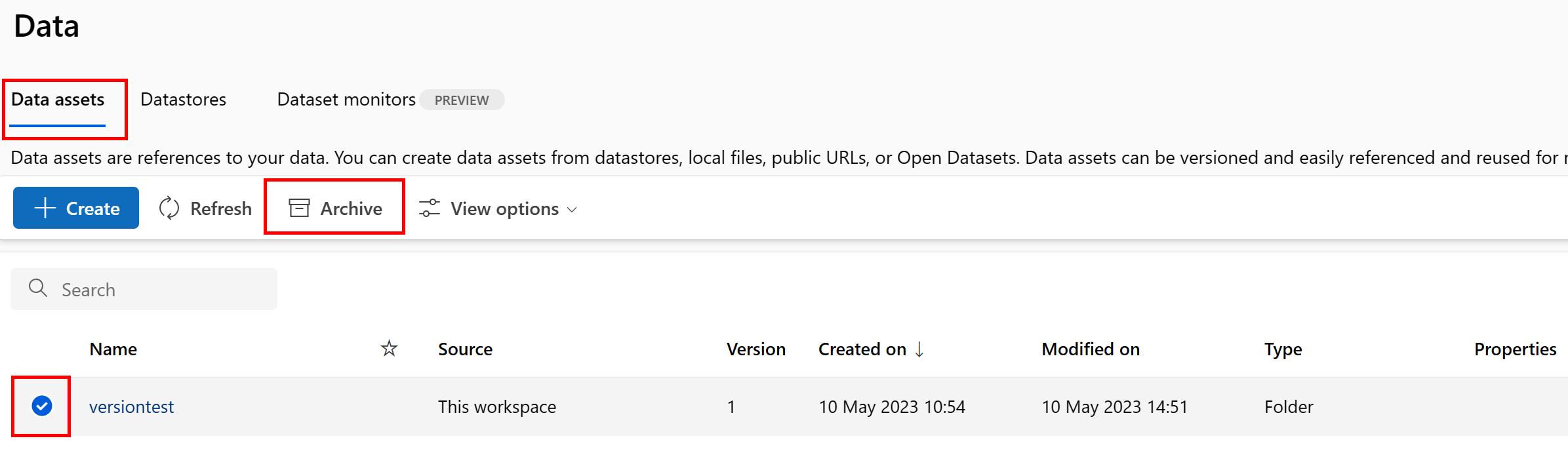
Arkivera en datatillgång
När du arkiverar en datatillgång döljs den som standard från båda listfrågorna (till exempel i CLI az ml data list) och datatillgångslistan i Studio-användargränssnittet. Du kan fortfarande fortsätta att referera till och använda en arkiverad datatillgång i dina arbetsflöden. Du kan arkivera antingen:
- Alla versioner av datatillgången under ett givet namn
Eller
- En specifik datatillgångsversion
Arkivera alla versioner av en datatillgång
Om du vill arkivera alla versioner av datatillgången under ett visst namn använder du:
Kör följande kommando. Se till att uppdatera <> platshållarna med din information.
az ml data archive --name <NAME OF DATA ASSET>
Arkivera en specifik datatillgångsversion
Om du vill arkivera en specifik datatillgångsversion använder du:
Kör följande kommando. Se till att uppdatera <> platshållarna med namnet på din datatillgång och version.
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
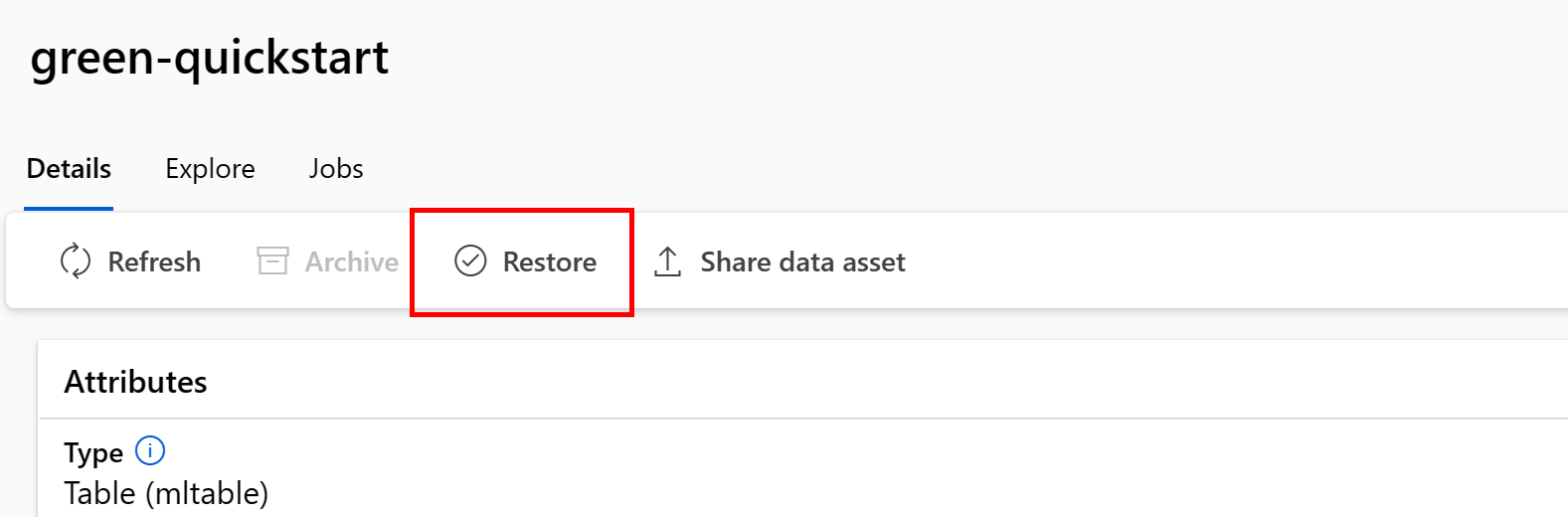
Återställa en arkiverad datatillgång
Du kan återställa en arkiverad datatillgång. Om alla versioner av datatillgången arkiveras kan du inte återställa enskilda versioner av datatillgången – du måste återställa alla versioner.
Återställa alla versioner av en datatillgång
Om du vill återställa alla versioner av datatillgången under ett visst namn använder du:
Kör följande kommando. Se till att uppdatera <> platshållarna med namnet på din datatillgång.
az ml data restore --name <NAME OF DATA ASSET>

Återställa en specifik datatillgångsversion
Viktigt!
Om alla datatillgångsversioner arkiverades kan du inte återställa enskilda versioner av datatillgången – du måste återställa alla versioner.
Om du vill återställa en specifik datatillgångsversion använder du:
Kör följande kommando. Se till att uppdatera <> platshållarna med namnet på din datatillgång och version.
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
Dataursprung
Data härkomst uppfattas i stort sett som den livscykel som sträcker sig över datans ursprung och var de flyttas över tid över lagringen. Olika typer av bakåtblickande scenarier använder det, till exempel
- Felsökning
- Spåra rotorsaker i ML-pipelines
- Felsökning
Datakvalitetsanalys, efterlevnad och "tänk om"-scenarier använder också ursprung. Härkomst representeras visuellt för att visa data som flyttas från källa till mål och omfattar även datatransformeringar. Med tanke på komplexiteten i de flesta företagsdatamiljöer kan dessa vyer bli svåra att förstå utan konsolidering eller maskering av kringutrustningsdatapunkter.
I en Azure Machine Learning-pipeline visar datatillgångar datans ursprung och hur data bearbetades, till exempel:
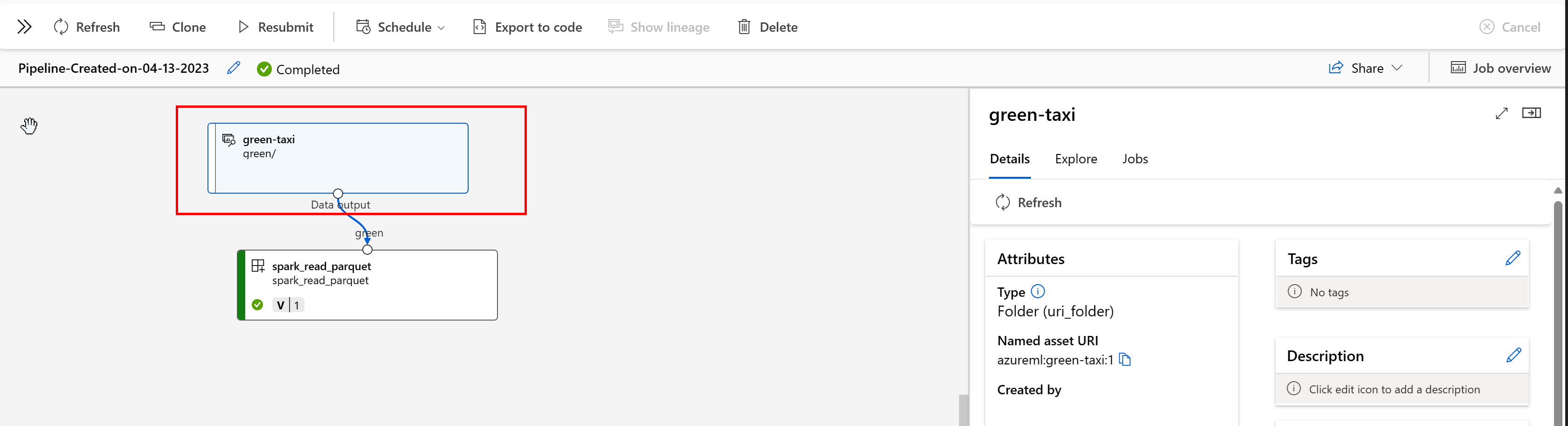
Du kan visa jobben som använder datatillgången i Studio-användargränssnittet. Välj först Data på den vänstra menyn och välj sedan namnet på datatillgången. Observera jobben som använder datatillgången:
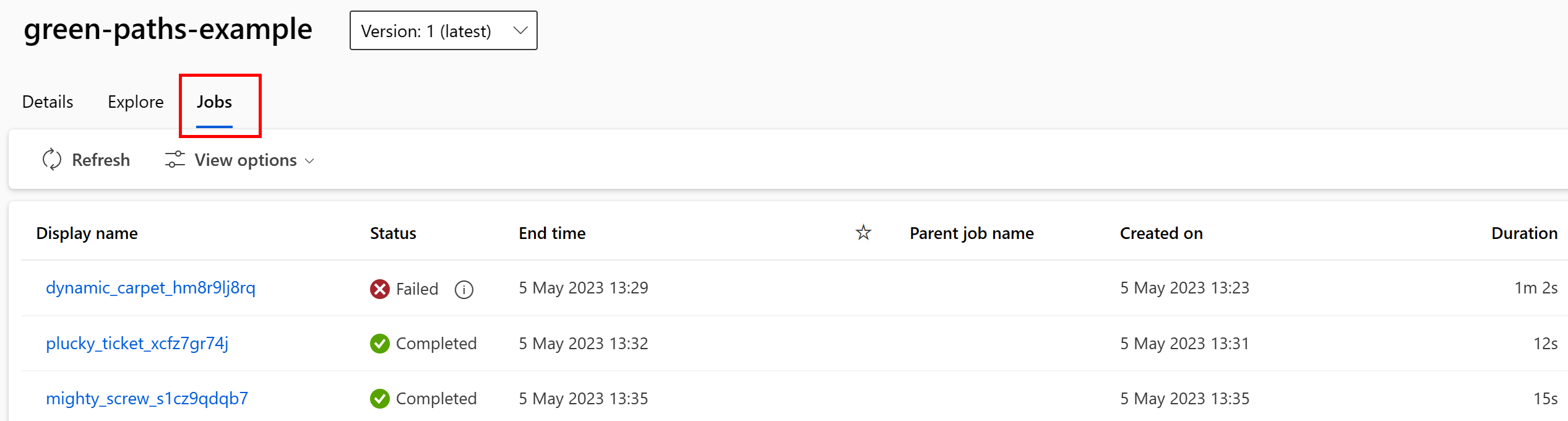
Jobbvyn i Datatillgångar gör det enklare att hitta jobbfel och göra rotorsaksanalyser i DINA ML-pipelines och felsökning.
Taggning av datatillgång
Datatillgångar stöder taggning, vilket är extra metadata som tillämpas på datatillgången som ett nyckel/värde-par. Datataggning ger många fördelar:
- Beskrivning av datakvalitet. Om din organisation till exempel använder en medallion lakehouse-arkitektur kan du tagga tillgångar med
medallion:bronze(rå),medallion:silver(validerad) ochmedallion:gold(berikad). - Effektiv sökning och filtrering av data för att hjälpa dataidentifiering.
- Identifiering av känsliga personuppgifter för korrekt hantering och styrning av dataåtkomst. Exempel:
sensitivity:PII/sensitivity:nonPII - Bestämning av huruvida data godkänns av en ansvarsfull AI-granskning (RAI). Exempel:
RAI_audit:approved/RAI_audit:todo
Du kan lägga till taggar i datatillgångar som en del av deras skapandeflöde, eller så kan du lägga till taggar i befintliga datatillgångar. Det här avsnittet visar båda:
Lägga till taggar som en del av flödet för att skapa datatillgång
Skapa en YAML-fil och kopiera och klistra in följande kod i YAML-filen. Se till att uppdatera <> platshållarna med
- namnet på datatillgången
- versionen
- beskrivning
- taggar (nyckel/värde-par)
- sökväg till en enda fil på en plats som stöds
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
Kör följande kommando i CLI. Se till att uppdatera <filename> platshållaren till YAML-filnamnet.
az ml data create -f <filename>.yml
Lägga till taggar i en befintlig datatillgång
Kör följande kommando i Azure CLI. Se till att uppdatera <> platshållarna med
- Namnet på datatillgången
- Versionen
- Nyckel/värde-par för taggen
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>

Metodtips för versionshantering
Vanligtvis organiserar dina ETL-processer din mappstruktur i Azure Storage efter tid, till exempel:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
Med kombinationen av tids-/versionsstrukturerade mappar och Azure Machine Learning-tabeller (MLTable) kan du konstruera versionsbaserade datauppsättningar. Ett hypotetiskt exempel visar hur du uppnår versionsdata med Azure Machine Learning-tabeller. Anta att du har en process som laddar upp kamerabilder till Azure Blob Storage varje vecka i den här strukturen:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Kommentar
Även om vi visar hur du version av avbildningsdata (jpeg) fungerar samma metod för alla filtyper (till exempel Parquet, CSV).
Med Azure Machine Learning-tabeller (mltable) skapar du en tabell med sökvägar som innehåller data fram till slutet av den första veckan 2023. Skapa sedan en datatillgång:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AZUREML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
I slutet av följande vecka uppdaterade din ETL data så att de innehåller mer data:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
Den första versionen (20230108) fortsätter att endast montera/ladda ned filer från year=2022/week=52 och year=2023/week=1 eftersom sökvägarna deklareras i MLTable filen. Detta säkerställer reproducerbarhet för dina experiment. Om du vill skapa en ny version av datatillgången som innehåller year=2023/week2använder du:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.windows.net/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AZUREML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
Nu har du två versioner av data, där namnet på versionen motsvarar det datum då bilderna laddades upp till lagring:
- 20230108: Bilderna fram till 2023-Jan-08.
- 20230115: Bilderna fram till 2023-Jan-15.
I båda fallen konstruerar MLTable en tabell med sökvägar som endast innehåller avbildningarna fram till dessa datum.
I ett Azure Machine Learning-jobb kan du montera eller ladda ned dessa sökvägar i den versionerade MLTable till beräkningsmålet med hjälp av antingen lägena eval_download eller eval_mount :
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
Kommentar
Lägena eval_mount och eval_download är unika för MLTable. I det här fallet utvärderar MLTable Azure Machine Learning-datakörningsfunktionen filen och monterar sökvägarna på beräkningsmålet.