Distribuera en modell till ett Azure Kubernetes Service-kluster med v1
Viktigt!
Den här artikeln beskriver hur du använder Azure Machine Learning CLI (v1) och Azure Machine Learning SDK för Python (v1) för att distribuera en modell. Den rekommenderade metoden för v2 finns i Distribuera och poängsätta en maskininlärningsmodell med hjälp av en onlineslutpunkt.
Lär dig hur du använder Azure Machine Learning för att distribuera en modell som en webbtjänst på Azure Kubernetes Service (AKS). AKS är bra för storskaliga produktionsdistributioner. Använd AKS om du behöver en eller flera av följande funktioner:
- Snabb svarstid
- Automatisk skalning av den distribuerade tjänsten
- Loggning
- Modelldatainsamling
- Autentisering
- TLS-avslutning
- Alternativ för maskinvaruacceleration , till exempel GPU och fältprogrammerbara gatematriser (FPGA)
När du distribuerar till AKS distribuerar du till ett AKS-kluster som är anslutet till din arbetsyta. Information om hur du ansluter ett AKS-kluster till din arbetsyta finns i Skapa och koppla ett Azure Kubernetes Service-kluster.
Viktigt!
Vi rekommenderar att du felsöker lokalt innan du distribuerar till webbtjänsten. Mer information finns i Felsöka med en lokal modelldistribution.
Du kan också läsa Distribuera till lokal notebook-fil på GitHub.
Kommentar
Azure Machine Learning-slutpunkter (v2) ger en förbättrad och enklare distributionsupplevelse. Slutpunkter stöder scenarier för både realtids- och batchinferens. Slutpunkter ger ett enhetligt gränssnitt för att anropa och hantera modelldistributioner mellan beräkningstyper. Se Vad är Azure Machine Learning-slutpunkter?.
Förutsättningar
En Azure Machine Learning-arbetsyta. Mer information finns i Skapa en Azure Machine Learning-arbetsyta.
En maskininlärningsmodell som är registrerad på din arbetsyta. Om du inte har någon registrerad modell kan du läsa Distribuera maskininlärningsmodeller till Azure.
Azure CLI-tillägget (v1) för Machine Learning-tjänsten, Azure Machine Learning Python SDK eller Azure Machine Learning Visual Studio Code-tillägget.
Viktigt!
Några av Azure CLI-kommandona i den här artikeln använder
azure-cli-mltillägget , eller v1, för Azure Machine Learning. Stödet för v1-tillägget upphör den 30 september 2025. Du kommer att kunna installera och använda v1-tillägget fram till det datumet.Vi rekommenderar att du övergår till
mltillägget , eller v2, före den 30 september 2025. Mer information om v2-tillägget finns i Azure ML CLI-tillägget och Python SDK v2.Python-kodfragmenten i den här artikeln förutsätter att följande variabler anges:
ws– Ange till din arbetsyta.model– Ange till din registrerade modell.inference_config– Ange inferenskonfigurationen för modellen.
Mer information om hur du ställer in dessa variabler finns i Hur och var du distribuerar modeller.
CLI-kodfragmenten i den här artikeln förutsätter att du redan har skapat ett inferenceconfig.json dokument. Mer information om hur du skapar det här dokumentet finns i Distribuera maskininlärningsmodeller till Azure.
Ett AKS-kluster som är anslutet till din arbetsyta. Mer information finns i Skapa och koppla ett Azure Kubernetes Service-kluster.
- Om du vill distribuera modeller till GPU-noder eller FPGA-noder (eller någon specifik produkt) måste du skapa ett kluster med den specifika produkten. Det finns inget stöd för att skapa en sekundär nodpool i ett befintligt kluster och distribuera modeller i den sekundära nodpoolen.
Förstå distributionsprocesser
Ordet distribution används i både Kubernetes och Azure Machine Learning. Distributionen har olika betydelser i dessa två kontexter. I Kubernetes är en distribution en konkret entitet som anges med en deklarativ YAML-fil. En Kubernetes-distribution har en definierad livscykel och konkreta relationer till andra Kubernetes-entiteter som Pods och ReplicaSets. Du kan lära dig mer om Kubernetes från dokument och videor på Vad är Kubernetes?.
I Azure Machine Learning används distributionen i den mer allmänna bemärkelsen att göra tillgängliga och rensa dina projektresurser. De steg som Azure Machine Learning tar hänsyn till en del av distributionen är:
- Zippa filerna i projektmappen och ignorera de som anges i .amlignore eller .gitignore
- Skala upp beräkningsklustret (relaterar till Kubernetes)
- Skapa eller ladda ned dockerfile till beräkningsnoden (relaterar till Kubernetes)
- Systemet beräknar en hash av:
- Basavbildningen
- Anpassade docker-steg (se Distribuera en modell med en anpassad Docker-basavbildning)
- Conda-definitionen YAML (se Skapa och använda programvarumiljöer i Azure Machine Learning)
- Systemet använder den här hashen som nyckel i en sökning på arbetsytans Azure Container Registry (ACR)
- Om den inte hittas letar den efter en matchning i den globala ACR
- Om det inte hittas skapar systemet en ny avbildning som cachelagras och skickas till arbetsytans ACR
- Systemet beräknar en hash av:
- Ladda ned den zippade projektfilen till tillfällig lagring på beräkningsnoden
- Packa upp projektfilen
- Körningen av beräkningsnoden
python <entry script> <arguments> - Spara loggar, modellfiler och andra filer som skrivits till ./outputs till lagringskontot som är associerat med arbetsytan
- Skala ned beräkning, inklusive att ta bort tillfällig lagring (gäller Kubernetes)
Azure Machine Learning-router
Klientdelskomponenten (azureml-fe) som dirigerar inkommande slutsatsdragningsbegäranden till distribuerade tjänster skalar automatiskt efter behov. Skalning av azureml-fe baseras på AKS-klustrets syfte och storlek (antal noder). Klustersyftet och noderna konfigureras när du skapar eller kopplar ett AKS-kluster. Det finns en azureml-fe-tjänst per kluster som kan köras på flera poddar.
Viktigt!
När du använder ett kluster som konfigurerats som dev-testinaktiveras självskalningen. Även för FastProd-/DenseProd-kluster aktiveras Self-Scaler endast när telemetri visar att det behövs.
Kommentar
Den maximala nyttolasten för begäran är 100 MB.
Azureml-fe skalas upp (lodrätt) för att använda fler kärnor och ut (vågrätt) för att använda fler poddar. När du fattar beslutet att skala upp används den tid det tar att dirigera inkommande slutsatsdragningsbegäranden. Om den här tiden överskrider tröskelvärdet sker en uppskalning. Om tiden för att dirigera inkommande begäranden fortsätter att överskrida tröskelvärdet sker en utskalning.
Vid nedskalning och inskalning används CPU-användning. Om tröskelvärdet för cpu-användning uppfylls skalas klientdelen först ned. Om CPU-användningen sjunker till tröskelvärdet för inskalning sker en inskalningsåtgärd. Upp- och utskalning sker bara om det finns tillräckligt med klusterresurser tillgängliga.
Vid uppskalning eller nedskalning startas azureml-fe-poddar om för att tillämpa cpu-/minnesändringarna. Omstarter påverkar inte slutsatsdragningsbegäranden.
Förstå anslutningskraven för slutsatsdragningskluster i AKS
När Azure Machine Learning skapar eller kopplar ett AKS-kluster distribueras AKS-klustret med någon av följande två nätverksmodeller:
- Kubenet-nätverk: Nätverksresurserna skapas och konfigureras vanligtvis när AKS-klustret distribueras.
- CNI-nätverk (Azure Container Networking Interface): AKS-klustret är anslutet till en befintlig virtuell nätverksresurs och konfigurationer.
För Kubenet-nätverk skapas och konfigureras nätverket korrekt för Azure Machine Learning-tjänsten. För CNI-nätverk måste du förstå anslutningskraven och säkerställa DNS-matchning och utgående anslutning för AKS-slutsatsdragning. Du kanske till exempel använder en brandvägg för att blockera nätverkstrafik.
Följande diagram visar anslutningskraven för AKS-slutsatsdragning. Svarta pilar representerar faktisk kommunikation och blå pilar representerar domännamnen. Du kan behöva lägga till poster för dessa värdar i brandväggen eller till din anpassade DNS-server.
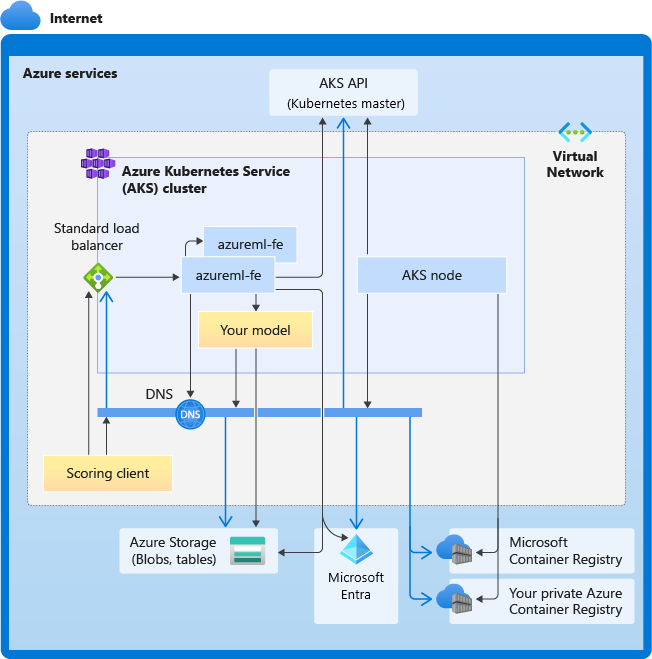
Allmänna KRAV för AKS-anslutning finns i Begränsa nätverkstrafik med Azure Firewall i AKS.
Information om hur du kommer åt Azure Machine Learning-tjänster bakom en brandvägg finns i Konfigurera inkommande och utgående nätverkstrafik.
Övergripande KRAV för DNS-matchning
DNS-matchning i ett befintligt virtuellt nätverk är under din kontroll. Till exempel en brandvägg eller anpassad DNS-server. Följande värdar måste kunna nås:
| Värdnamn | Används av |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS API-server |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Ditt Azure Container Registry (ACR) |
<account>.table.core.windows.net |
Azure Storage-konto (Table Storage) |
<account>.blob.core.windows.net |
Azure Storage-konto (Blob Storage) |
api.azureml.ms |
Microsoft Entra-autentisering |
ingest-vienna<region>.kusto.windows.net |
Kusto-slutpunkt för uppladdning av telemetri |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
Slutpunktsdomännamn om du har genererats automatiskt med Azure Machine Learning. Om du har använt ett anpassat domännamn behöver du inte den här posten. |
Anslut ivitetskrav i kronologisk ordning
När AKS skapar eller ansluter distribueras Azure Machine Learning-routern (azureml-fe) till AKS-klustret. För att kunna distribuera Azure Machine Learning-routern bör AKS-noden kunna:
- Lösa DNS för AKS API-server
- Lösa DNS för MCR för att ladda ned Docker-avbildningar för Azure Machine Learning-routern
- Ladda ned avbildningar från MCR, där utgående anslutning krävs
Direkt efter att azureml-fe har distribuerats försöker den starta och detta kräver att du:
- Lösa DNS för AKS API-server
- Fråga AKS API-servern för att identifiera andra instanser av sig själv (det är en tjänst med flera poddar)
- Anslut till andra instanser av sig själv
När azureml-fe har startats krävs följande anslutning för att fungera korrekt:
- Anslut till Azure Storage för att ladda ned dynamisk konfiguration
- Lös DNS för Microsoft Entra-autentiseringsservern api.azureml.ms och kommunicera med den när den distribuerade tjänsten använder Microsoft Entra-autentisering.
- Fråga AKS API-servern för att identifiera distribuerade modeller
- Kommunicera med distribuerade modell-POD:er
Vid modelldistributionens tid bör AKS-noden för en lyckad modelldistribution kunna:
- Lösa DNS för kundens ACR
- Ladda ned bilder från kundens ACR
- Lösa DNS för Azure BLOB där modellen lagras
- Ladda ned modeller från Azure BLOBs
När modellen har distribuerats och tjänsten startar identifierar azureml-fe den automatiskt med hjälp av AKS-API:et och är redo att dirigera begäran till den. Den måste kunna kommunicera med modell-POD:er.
Kommentar
Om den distribuerade modellen kräver någon anslutning (till exempel fråga extern databas eller annan REST-tjänst eller ladda ned en BLOB) bör både DNS-matchning och utgående kommunikation för dessa tjänster aktiveras.
Distribuera till AKS
Om du vill distribuera en modell till AKS skapar du en distributionskonfiguration som beskriver de beräkningsresurser som behövs. Till exempel antalet kärnor och minne. Du behöver också en slutsatsdragningskonfiguration som beskriver den miljö som behövs för att vara värd för modellen och webbtjänsten. Mer information om hur du skapar inferenskonfigurationen finns i Hur och var du distribuerar modeller.
Kommentar
Antalet modeller som ska distribueras är begränsat till 1 000 modeller per distribution (per container).
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Mer information om de klasser, metoder och parametrar som används i det här exemplet finns i följande referensdokument:
Automatisk skalning
GÄLLER FÖR:Python SDK azureml v1
Komponenten som hanterar automatisk skalning för azure machine learning-modelldistributioner är azureml-fe, som är en router för smart begäran. Eftersom alla slutsatsdragningsbegäranden går igenom den har den nödvändiga data för att automatiskt skala de distribuerade modellerna.
Viktigt!
Aktivera inte Kubernetes Horizontal Pod Autoscaler (HPA) för modelldistributioner. Detta gör att de två komponenterna för automatisk skalning konkurrerar med varandra. Azureml-fe är utformat för automatisk skalning av modeller som distribueras av Azure Machine Learning, där HPA skulle behöva gissa eller ungefärlig modellanvändning från ett allmänt mått som CPU-användning eller en anpassad måttkonfiguration.
Azureml-fe skalar inte antalet noder i ett AKS-kluster, eftersom detta kan leda till oväntade kostnadsökningar. I stället skalar den antalet repliker för modellen inom de fysiska klustergränserna. Om du behöver skala antalet noder i klustret kan du skala klustret manuellt eller konfigurera autoskalning av AKS-kluster.
Autoskalning kan styras genom att ange autoscale_target_utilization, autoscale_min_replicasoch autoscale_max_replicas för AKS-webbtjänsten. I följande exempel visas hur du aktiverar automatisk skalning:
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
Beslut om att skala upp eller ned baseras på användningen av de aktuella containerreplikerna. Antalet repliker som är upptagna (bearbetar en begäran) dividerat med det totala antalet aktuella repliker är den aktuella användningen. Om det här antalet överskrider autoscale_target_utilizationskapas fler repliker. Om den är lägre minskas replikerna. Som standard är målanvändningen 70 %.
Beslut om att lägga till repliker är ivriga och snabba (cirka 1 sekund). Beslut om att ta bort repliker är konservativa (cirka 1 minut).
Du kan beräkna de repliker som krävs med hjälp av följande kod:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Mer information om hur du anger autoscale_target_utilization, autoscale_max_replicasoch autoscale_min_replicas, finns i referensen för AksWebservice-modulen .
Autentisering av webbtjänst
När du distribuerar till Azure Kubernetes Service aktiveras nyckelbaserad autentisering som standard. Du kan också aktivera tokenbaserad autentisering. Tokenbaserad autentisering kräver att klienter använder ett Microsoft Entra-konto för att begära en autentiseringstoken, som används för att göra begäranden till den distribuerade tjänsten.
Om du vill inaktivera autentisering anger du parametern auth_enabled=False när du skapar distributionskonfigurationen. I följande exempel inaktiveras autentisering med hjälp av SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
Information om autentisering från ett klientprogram finns i Använda en Azure Machine Learning-modell som distribuerats som en webbtjänst.
Autentisering med nycklar
Om nyckelautentisering är aktiverat kan du använda get_keys metoden för att hämta en primär och sekundär autentiseringsnyckel:
primary, secondary = service.get_keys()
print(primary)
Viktigt!
Om du behöver återskapa en nyckel använder du service.regen_key.
Autentisering med token
Om du vill aktivera tokenautentisering anger du parametern token_auth_enabled=True när du skapar eller uppdaterar en distribution. I följande exempel aktiveras tokenautentisering med hjälp av SDK:
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
Om tokenautentisering är aktiverat kan du använda get_token metoden för att hämta en JWT-token och den tokens förfallotid:
token, refresh_by = service.get_token()
print(token)
Viktigt!
Du måste begära en ny token efter tokens refresh_by tid.
Microsoft rekommenderar starkt att du skapar din Azure Machine Learning-arbetsyta i samma region som ditt AKS-kluster. För att autentisera med en token gör webbtjänsten ett anrop till den region där din Azure Machine Learning-arbetsyta skapas. Om arbetsytans region inte är tillgänglig kan du inte hämta en token för webbtjänsten även om klustret finns i en annan region än din arbetsyta. Detta resulterar i att tokenbaserad autentisering blir otillgänglig tills arbetsytans region är tillgänglig igen. Ju större avståndet mellan klustrets region och arbetsytans region är, desto längre tid tar det att hämta en token.
Om du vill hämta en token måste du använda Azure Machine Learning SDK eller kommandot az ml service get-access-token .
Sårbarhetsgenomsökning
Microsoft Defender för molnet ger enhetlig säkerhetshantering och avancerat skydd mot hot i hybridmolnarbetsbelastningar. Du bör låta Microsoft Defender för molnet genomsöka dina resurser och följa dess rekommendationer. Mer information finns i Containersäkerhet i Microsoft Defender för containrar.
Relaterat innehåll
- Använda rollbaserad åtkomstkontroll i Azure för Kubernetes-auktorisering
- Skydda en Azure Machine Learning-miljö för slutsatsdragning med virtuella nätverk
- Använda en anpassad container för att distribuera en modell till en onlineslutpunkt
- Felsöka distribution av fjärrmodeller
- Uppdatera en distribuerad webbtjänst
- Använda TLS för att skydda en webbtjänst via Azure Machine Learning
- Konsumera en Azure Machine Learning-modell som distribuerats som en webbtjänst
- Se Övervaka och samla in data från webbtjänstslutpunkter i ML
- Samla in data från modeller i produktion