GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
I den här artikeln lär du dig att distribuera din modell till en onlineslutpunkt för användning i realtidsinferens. Du börjar med att distribuera en modell på den lokala datorn för att felsöka eventuella fel. Sedan distribuerar och testar du modellen i Azure, visar distributionsloggarna och övervakar serviceavtalet (SLA). I slutet av den här artikeln har du en skalbar HTTPS/REST-slutpunkt som du kan använda för slutsatsdragning i realtid.
Onlineslutpunkter är slutpunkter som används för inferens i realtid. Det finns två typer av onlineslutpunkter: hanterade onlineslutpunkter och Kubernetes onlineslutpunkter. Mer information om skillnaderna finns i Hanterade onlineslutpunkter jämfört med Kubernetes onlineslutpunkter.
Med hanterade onlineslutpunkter kan du distribuera användningsklara maskininlärningsmodeller. Hanterade onlineslutpunkter körs skalbart och helt hanterat på datorer med kraftfulla processorer och grafikkort i Azure. Hanterade onlineslutpunkter tar hand om servering, skalning, skydd och övervakning av dina modeller. Den här hjälpen frigör dig från kostnaderna för att konfigurera och hantera den underliggande infrastrukturen.
Huvudexemplet i den här artikeln använder hanterade onlineslutpunkter för distribution. Om du vill använda Kubernetes i stället kan du läsa anteckningarna i det här dokumentet som är infogade i den hanterade onlineslutpunktsdiskussionen.
Förutsättningar
GÄLLER FÖR: Azure CLI ml-tillägget v2 (aktuellt)
Azure CLI och ml tillägget till Azure CLI har installerats och konfigurerats. Mer information finns i Installera och konfigurera CLI (v2).
Ett Bash-gränssnitt eller ett kompatibelt gränssnitt, till exempel ett gränssnitt på ett Linux-system eller Windows-undersystem för Linux. Azure CLI-exemplen i den här artikeln förutsätter att du använder den här typen av gränssnitt.
En Azure Machine Learning-arbetsyta. Anvisningar för hur du skapar en arbetsyta finns i Konfigurera.
Rollbaserad åtkomstkontroll i Azure (Azure RBAC) används för att ge åtkomst till åtgärder i Azure Machine Learning. Om du vill utföra stegen i den här artikeln måste ditt användarkonto tilldelas rollen Ägare eller Deltagare för Azure Machine Learning-arbetsytan, eller så måste en anpassad roll tillåta Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Om du använder Azure Machine Learning Studio för att skapa och hantera onlineslutpunkter eller distributioner behöver du den extra behörigheten Microsoft.Resources/deployments/write från resursgruppens ägare. Mer information finns i Hantera åtkomst till Azure Machine Learning-arbetsytor.
(Valfritt) Om du vill distribuera lokalt måste du installera Docker Engine på den lokala datorn. Vi rekommenderar starkt det här alternativet, vilket gör det enklare att felsöka problem.
GÄLLER FÖR: Python SDK azure-ai-ml v2 (aktuell)
En Azure Machine Learning-arbetsyta. Anvisningar för hur du skapar en arbetsyta finns i Skapa arbetsytan.
Azure Machine Learning SDK för Python v2. Om du vill installera SDK använder du följande kommando:
pip install azure-ai-ml azure-identity
Om du vill uppdatera en befintlig installation av SDK:et till den senaste versionen använder du följande kommando:
pip install --upgrade azure-ai-ml azure-identity
Mer information finns i Klientbiblioteket för Azure Machine Learning Package för Python.
Azure RBAC används för att bevilja åtkomst till åtgärder i Azure Machine Learning. Om du vill utföra stegen i den här artikeln måste ditt användarkonto tilldelas rollen Ägare eller Deltagare för Azure Machine Learning-arbetsytan, eller så måste en anpassad roll tillåta Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Mer information finns i Hantera åtkomst till Azure Machine Learning-arbetsytor.
(Valfritt) Om du vill distribuera lokalt måste du installera Docker Engine på den lokala datorn. Vi rekommenderar starkt det här alternativet, vilket gör det enklare att felsöka problem.
Innan du följer stegen i den här artikeln måste du se till att du har följande förutsättningar:
Azure CLI och CLI-tillägget för maskininlärning används i de här stegen, men de är inte huvudfokus. De används mer som verktyg för att skicka mallar till Azure och kontrollera status för malldistributioner.
Azure CLI och ml tillägget till Azure CLI har installerats och konfigurerats. Mer information finns i Installera och konfigurera CLI (v2).
Ett Bash-gränssnitt eller ett kompatibelt gränssnitt, till exempel ett gränssnitt på ett Linux-system eller Windows-undersystem för Linux. Azure CLI-exemplen i den här artikeln förutsätter att du använder den här typen av gränssnitt.
En Azure Machine Learning-arbetsyta. Anvisningar för hur du skapar en arbetsyta finns i Konfigurera.
- Azure RBAC används för att bevilja åtkomst till åtgärder i Azure Machine Learning. Om du vill utföra stegen i den här artikeln måste ditt användarkonto tilldelas rollen Ägare eller Deltagare för Azure Machine Learning-arbetsytan, eller så måste en anpassad roll tillåta
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Mer information finns i Hantera åtkomst till en Azure Machine Learning-arbetsyta.
Se till att du har tillräckligt med kvoter för virtuella datorer (VM) allokerade för distribution. Azure Machine Learning reserverar 20% av dina beräkningsresurser för att utföra uppgraderingar på vissa vm-versioner. Om du till exempel begär 10 instanser i en distribution måste du ha en kvot på 12 för varje antal kärnor för den virtuella datorns version. Om du inte tar hänsyn till de extra beräkningsresurserna resulterar det i ett fel. Vissa VM-versioner är undantagna från den extra kvotreservationen. Mer information om kvotallokering finns i kvotallokering för virtuella datorer för distribution.
Du kan också använda kvoten från den delade kvotpoolen i Azure Machine Learning under en begränsad tid. Azure Machine Learning tillhandahåller en delad kvotpool från vilken användare i olika regioner kan komma åt kvoten för att utföra testning under en begränsad tid, beroende på tillgänglighet.
När du använder studion för att distribuera Llama-2-, Phi-, Nemotron-, Mistral-, Dolly- och Deci-DeciLM-modeller från modellkatalogen till en hanterad onlineslutpunkt, ger Azure Machine Learning dig åtkomst till dess delade kvotpool under en kort tid så att du kan utföra testning. Mer information om den delade kvotpoolen finns i Delad kvot för Azure Machine Learning.
Förbereda systemet
Ange miljövariabler
Om du inte redan har angett standardinställningarna för Azure CLI sparar du standardinställningarna. Kör den här koden för att undvika att skicka in värdena för din prenumeration, arbetsyta och resursgrupp flera gånger:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Klona exempellagringsplatsen
Om du vill följa med i den här artikeln klonar du först lagringsplatsen azureml-examples och ändrar sedan till lagringsplatsens azureml-examples/cli-katalog :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli
Använd --depth 1 för att endast klona den senaste incheckningen till lagringsplatsen, vilket minskar tiden för att slutföra åtgärden.
Kommandona i den här självstudien finns i filerna deploy-local-endpoint.sh och deploy-managed-online-endpoint.sh i cli-mappen. YAML-konfigurationsfilerna finns i underkatalogen endpoints/online/managed/sample/ .
Kommentar
YAML-konfigurationsfilerna för Kubernetes onlineslutpunkter finns i underkatalogen endpoints/online/kubernetes/ .
Klona exempellagringsplatsen
Om du vill köra träningsexemplen klonar du först lagringsplatsen azureml-examples och ändrar sedan till azureml-examples/sdk/python/endpoints/online/managed directory:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
Använd --depth 1 för att endast klona den senaste incheckningen till lagringsplatsen, vilket minskar tiden för att slutföra åtgärden.
Informationen i den här artikeln baseras på notebook-filen online-endpoints-simple-deployment.ipynb . Den innehåller samma innehåll som den här artikeln, även om kodernas ordning skiljer sig något.
Ansluta till Azure Machine Learning-arbetsytan
Arbetsytan är resursen på den översta nivån för Azure Machine Learning. Det ger en central plats där du kan arbeta med alla artefakter som du skapar när du använder Azure Machine Learning. I det här avsnittet ansluter du till arbetsytan där du utför distributionsuppgifter. Om du vill följa med öppnar du notebook-filen online-endpoints-simple-deployment.ipynb .
Importera de bibliotek som krävs:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration
)
from azure.identity import DefaultAzureCredential
Kommentar
Om du använder Kubernetes onlineslutpunkt, importera klassen KubernetesOnlineEndpoint och KubernetesOnlineDeployment från azure.ai.ml.entities-biblioteket.
Konfigurera information om arbetsytan och få ett handtag till arbetsytan.
För att ansluta till en arbetsyta behöver du följande identifierarparametrar: en prenumeration, en resursgrupp och ett arbetsytenamn. Du använder de här uppgifterna i MLClient från azure.ai.ml för att få en referens till den nödvändiga Azure Machine Learning-arbetsytan. I det här exemplet används standardautentiseringen för Azure.
# enter details of your Azure Machine Learning workspace
subscription_id = "<subscription ID>"
resource_group = "<resource group>"
workspace = "<workspace name>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
Om du har Git installerat på den lokala datorn kan du följa anvisningarna för att klona exempellagringsplatsen. Annars följer du anvisningarna för att ladda ned filer från exempellagringsplatsen.
Klona exempellagringsplatsen
För att följa med i den här artikeln klonar du först lagringsplatsen azureml-examples och går sedan till katalogen azureml-examples/cli/endpoints/online/model-1.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
Använd --depth 1 för att endast klona den senaste incheckningen till lagringsplatsen, vilket minskar tiden för att slutföra åtgärden.
Ladda ned filer från exempellagringsplatsen
Om du klonade exempellagringsplatsen har den lokala datorn redan kopior av filerna för det här exemplet och du kan gå vidare till nästa avsnitt. Om du inte klonade lagringsplatsen, laddar du ned den till din lokala dator.
- Gå till exempellagringsplatsen (azureml-examples).
- Gå till <> knappen Kod på sidan och välj sedan Ladda ned ZIP på fliken Lokal.
- Leta upp mappen /cli/endpoints/online/model-1/model och filen /cli/endpoints/online/model-1/onlinescoring/score.py.
Ange miljövariabler
Ange följande miljövariabler så att du kan använda dem i exemplen i den här artikeln. Ersätt värdena med ditt Azure-prenumerations-ID, Den Azure-region där din arbetsyta finns, resursgruppen som innehåller arbetsytan och namnet på arbetsytan:
export SUBSCRIPTION_ID="<subscription ID>"
export LOCATION="<your region>"
export RESOURCE_GROUP="<resource group>"
export WORKSPACE="<workspace name>"
Ett par mallexempel kräver att du laddar upp filer till Azure Blob Storage för din arbetsyta. Följande steg frågar arbetsytan och lagrar den här informationen i miljövariabler som används i exemplen:
Hämta en åtkomsttoken:
TOKEN=$(az account get-access-token --query accessToken -o tsv)
Ange REST API-versionen:
API_VERSION="2022-05-01"
Hämta lagringsinformationen:
# Get values for storage account
response=$(curl --location --request GET "https://management.azure.com/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices/workspaces/$WORKSPACE/datastores?api-version=$API_VERSION&isDefault=true" \
--header "Authorization: Bearer $TOKEN")
AZUREML_DEFAULT_DATASTORE=$(echo $response | jq -r '.value[0].name')
AZUREML_DEFAULT_CONTAINER=$(echo $response | jq -r '.value[0].properties.containerName')
export AZURE_STORAGE_ACCOUNT=$(echo $response | jq -r '.value[0].properties.accountName')
Klona exempellagringsplatsen
Om du vill följa med i den här artikeln klonar du först lagringsplatsen azureml-examples och ändrar sedan till katalogen azureml-examples :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
Använd --depth 1 för att endast klona den senaste incheckningen till lagringsplatsen, vilket minskar tiden för att slutföra åtgärden.
Definiera slutpunkten
Om du vill definiera en onlineslutpunkt anger du slutpunktsnamnet och autentiseringsläget. Mer information om hanterade onlineslutpunkter finns i Onlineslutpunkter.
Ange ett slutpunktsnamn
Kör följande kommando för att ange slutpunktsnamnet. Ersätt <YOUR_ENDPOINT_NAME> med ett namn som är unikt i Azure-regionen. Mer information om namngivningsreglerna finns i Slutpunktsgränser.
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
Följande kodfragment visar filen endpoints/online/managed/sample/endpoint.yml :
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
Referensen för YAML-formatet för slutpunkten beskrivs i följande tabell. Information om hur du anger dessa attribut finns i YAML-referensen för onlineslutpunkten. Information om begränsningar relaterade till hanterade slutpunkter finns i Azure Machine Learning online-slutpunkter och batchslutpunkter.
| Nyckel |
beskrivning |
$schema |
(Valfritt) YAML-schemat. Om du vill se alla tillgängliga alternativ i YAML-filen kan du visa schemat i föregående kodfragment i en webbläsare. |
name |
Namnet på slutpunkten. |
auth_mode |
Används key för nyckelbaserad autentisering.
Används aml_token för tokenbaserad autentisering i Azure Machine Learning.
Använd aad_token för Microsoft Entra-tokenbaserad autentisering (förhandsversion).
Mer information om autentisering finns i Autentisera klienter för onlineslutpunkter. |
Definiera först namnet på onlineslutpunkten och konfigurera sedan slutpunkten.
Ersätt <YOUR_ENDPOINT_NAME> med ett namn som är unikt i Azure-regionen eller använd exempelmetoden för att definiera ett slumpmässigt namn. Se till att ta bort den metod som du inte använder. Mer information om namngivningsreglerna finns i Slutpunktsgränser.
# method 1: define an endpoint name
endpoint_name = "<YOUR_ENDPOINT_NAME>"
# method 2: example way to define a random name
import datetime
endpoint_name = "endpt-" + datetime.datetime.now().strftime("%m%d%H%M%f")
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name = endpoint_name,
description="this is a sample endpoint",
auth_mode="key"
)
Den tidigare koden använder key för nyckelbaserad autentisering. Om du vill använda tokenbaserad autentisering i Azure Machine Learning använder du aml_token. Om du vill använda Microsoft Entra-tokenbaserad autentisering (förhandsversion) använder du aad_token. Mer information om autentisering finns i Autentisera klienter för onlineslutpunkter.
När du distribuerar till Azure från studion skapar du en slutpunkt och en distribution att lägga till i den. Då uppmanas du att ange namn för slutpunkten och distributionen.
Ange ett slutpunktsnamn
Om du vill ange slutpunktsnamnet kör du följande kommando för att generera ett slumpmässigt namn. Den måste vara unik i Azure-regionen. Mer information om namngivningsreglerna finns i Slutpunktsgränser.
export ENDPOINT_NAME=endpoint-`echo $RANDOM`
För att definiera slutpunkten och distributionen använder den här artikeln Azure Resource Manager-mallar (ARM-mallar) online-endpoint.json och online-endpoint-deployment.json. Om du vill använda mallarna för att definiera en onlineslutpunkt och distribution läser du avsnittet Distribuera till Azure .
Definiera distributionen
En distribution är en uppsättning resurser som krävs för att vara värd för den modell som utför den faktiska inferensen. I det här exemplet distribuerar du en scikit-learn modell som utför regression och använder ett bedömningsskript score.py för att köra modellen på en specifik indatabegäran.
Mer information om nyckelattributen för en distribution finns i Onlinedistributioner.
Distributionskonfigurationen använder platsen för den modell som du vill distribuera.
Följande kodfragment visar filen endpoints/online/managed/sample/blue-deployment.yml , med alla nödvändiga indata för att konfigurera en distribution:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Filen blue-deployment.yml anger följande distributionsattribut:
-
model: Anger modellens egenskaper direkt med parametern path (varifrån filer kan laddas upp). CLI laddar automatiskt upp modellfilerna och registrerar modellen med ett automatiskt genererat namn.
-
environment: Använder infogade definitioner som innehåller var du kan ladda upp filer från. CLI laddar automatiskt upp filen conda.yaml och registrerar miljön. Senare använder distributionen parametern image för basavbildningen för att skapa miljön. I det här exemplet är det mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Beroendena conda_file installeras ovanpå basavbildningen.
-
code_configuration: Laddar upp de lokala filerna, till exempel Python-källan för bedömningsmodellen, från utvecklingsmiljön under distributionen.
Mer information om YAML-schemat finns i YAML-referensen för onlineslutpunkten.
Kommentar
Så här använder du Kubernetes-slutpunkter i stället för hanterade onlineslutpunkter som beräkningsmål:
- Skapa och koppla kubernetes-klustret som beräkningsmål till din Azure Machine Learning-arbetsyta med hjälp av Azure Machine Learning-studio.
- Använd endpoint YAML för att rikta in dig på Kubernetes istället för den hanterade endpoint YAML. Du måste redigera YAML för att ändra värdet
compute för till namnet på ditt registrerade beräkningsmål. Du kan använda den här deployment.yaml som har andra egenskaper som gäller för en Kubernetes-distribution.
Alla kommandon som används i den här artikeln för hanterade onlineslutpunkter gäller även för Kubernetes-slutpunkter, förutom följande funktioner som inte gäller för Kubernetes-slutpunkter:
Använd följande kod för att konfigurera en distribution:
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
-
Model: Anger modellens egenskaper direkt med parametern path (varifrån filer kan laddas upp). SDK laddar automatiskt upp modellfilerna och registrerar modellen med ett automatiskt genererat namn.
-
Environment: Använder infogade definitioner som innehåller var du kan ladda upp filer från. SDK laddar automatiskt upp filen conda.yaml och registrerar miljön. Senare använder distributionen parametern image för basavbildningen för att skapa miljön. I det här exemplet är det mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest. Beroendena conda_file installeras ovanpå basavbildningen.
-
CodeConfiguration: Laddar upp de lokala filerna, till exempel Python-källan för bedömningsmodellen, från utvecklingsmiljön under distributionen.
Mer information om distributionsdefinition online finns i OnlineDeployment-klass.
När du distribuerar till Azure skapar du en slutpunkt och en distribution som ska läggas till i den. Då uppmanas du att ange namn för slutpunkten och distributionen.
Förstå bedömningsskriptet
Formatet för bedömningsskriptet för onlineslutpunkter är samma format som används i föregående version av CLI och i Python SDK.
Bedömningsskriptet som anges i code_configuration.scoring_script måste ha en init() funktion och en run() funktion.
Bedömningsskriptet måste ha en init() funktion och en run() funktion.
Bedömningsskriptet måste ha en init() funktion och en run() funktion.
Bedömningsskriptet måste ha en init() funktion och en run() funktion. I den här artikeln används filen score.py.
När du använder en mall för distribution måste du först ladda upp bedömningsfilen till Blob Storage och sedan registrera den:
Följande kod använder Azure CLI-kommandot az storage blob upload-batch för att ladda upp bedömningsfilen:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/score -s cli/endpoints/online/model-1/onlinescoring --account-name $AZURE_STORAGE_ACCOUNT
Följande kod använder en mall för att registrera koden:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/code-version.json \
--parameters \
workspaceName=$WORKSPACE \
codeAssetName="score-sklearn" \
codeUri="https://$AZURE_STORAGE_ACCOUNT.blob.core.windows.net/$AZUREML_DEFAULT_CONTAINER/score"
I det här exemplet används score.py-filen från lagringsplatsen som du klonade eller laddade ned tidigare:
import os
import logging
import json
import numpy
import joblib
def init():
"""
This function is called when the container is initialized/started, typically after create/update of the deployment.
You can write the logic here to perform init operations like caching the model in memory
"""
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment.
# It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION)
# Please provide your model's folder name if there is one
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# deserialize the model file back into a sklearn model
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
This function is called for every invocation of the endpoint to perform the actual scoring/prediction.
In the example we extract the data from the json input and call the scikit-learn model's predict()
method and return the result back
"""
logging.info("model 1: request received")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()
Funktionen init() anropas när containern initieras eller startas. Initieringen sker vanligtvis strax efter att distributionen har skapats eller uppdaterats. Funktionen init är platsen för att skriva logik för globala initieringsåtgärder som att cachelagra modellen i minnet (som visas i den här score.py filen).
Funktionen run() anropas varje gång slutpunkten anropas. Den gör den faktiska poängsättningen och förutsägelsen. I den här score.py filen run() extraherar funktionen data från en JSON-indata, anropar scikit-learn-modellens predict() metod och returnerar sedan förutsägelseresultatet.
Distribuera och felsöka lokalt med hjälp av en lokal slutpunkt
Vi rekommenderar starkt att du testar att köra slutpunkten lokalt för att verifiera och felsöka din kod och konfiguration innan du distribuerar till Azure. Azure CLI och Python SDK stöder lokala slutpunkter och distributioner, men det gör inte Azure Machine Learning Studio- och ARM-mallar.
Om du vill distribuera lokalt måste Docker Engine installeras och köras. Docker Engine startar vanligtvis när datorn startas. Om den inte gör det kan du felsöka Docker Engine.
Du kan använda Azure Machine Learning-inferens HTTP-server Python-paketet för att felsöka ditt poängskript lokalt utan Docker Engine. Felsökning med slutsatsdragningsservern hjälper dig att felsöka bedömningsskriptet innan du distribuerar till lokala slutpunkter så att du kan felsöka utan att påverkas av konfigurationerna av distributionscontainer.
Mer information om felsökning av onlineslutpunkter lokalt innan du distribuerar till Azure finns i Felsökning av onlineslutpunkter.
Distribuera modellen lokalt
Skapa först en slutpunkt. Om du vill kan du hoppa över det här steget för en lokal slutpunkt. Du kan skapa distributionen direkt (nästa steg), vilket i sin tur skapar nödvändiga metadata. Att distribuera modeller lokalt är användbart i utvecklings- och testsyfte.
az ml online-endpoint create --local -n $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
ml_client.online_endpoints.begin_create_or_update(endpoint, local=True)
Studion stöder inte lokala slutpunkter. Anvisningar för hur du testar slutpunkten lokalt finns i flikarna Azure CLI eller Python.
Mallen stöder inte lokala slutpunkter. Anvisningar för hur du testar slutpunkten lokalt finns i flikarna Azure CLI eller Python.
Skapa nu en distribution med namnet blue under slutpunkten.
az ml online-deployment create --local -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml
Flaggan --local instruerar CLI att distribuera slutpunkten i Docker-miljön.
ml_client.online_deployments.begin_create_or_update(
deployment=blue_deployment, local=True
)
Flaggan local=True instruerar SDK:et att distribuera slutpunkten i Docker-miljön.
Studion stöder inte lokala slutpunkter. Anvisningar för hur du testar slutpunkten lokalt finns i flikarna Azure CLI eller Python.
Mallen stöder inte lokala slutpunkter. Anvisningar för hur du testar slutpunkten lokalt finns i flikarna Azure CLI eller Python.
Kontrollera att den lokala distributionen lyckades
Kontrollera distributionsstatusen för att se om modellen distribuerades utan fel:
az ml online-endpoint show -n $ENDPOINT_NAME --local
Utdata bör se ut ungefär som följande JSON. Parametern provisioning_state är Succeeded.
{
"auth_mode": "key",
"location": "local",
"name": "docs-endpoint",
"properties": {},
"provisioning_state": "Succeeded",
"scoring_uri": "http://localhost:49158/score",
"tags": {},
"traffic": {}
}
ml_client.online_endpoints.get(name=endpoint_name, local=True)
Metoden returnerar ManagedOnlineEndpoint entiteten. Parametern provisioning_state är Succeeded.
ManagedOnlineEndpoint({'public_network_access': None, 'provisioning_state': 'Succeeded', 'scoring_uri': 'http://localhost:49158/score', 'swagger_uri': None, 'name': 'endpt-10061534497697', 'description': 'this is a sample endpoint', 'tags': {}, 'properties': {}, 'id': None, 'Resource__source_path': None, 'base_path': '/path/to/your/working/directory', 'creation_context': None, 'serialize': <msrest.serialization.Serializer object at 0x7ffb781bccd0>, 'auth_mode': 'key', 'location': 'local', 'identity': None, 'traffic': {}, 'mirror_traffic': {}, 'kind': None})
Studion stöder inte lokala slutpunkter. Anvisningar för hur du testar slutpunkten lokalt finns i flikarna Azure CLI eller Python.
Mallen stöder inte lokala slutpunkter. Anvisningar för hur du testar slutpunkten lokalt finns i flikarna Azure CLI eller Python.
Följande tabell innehåller möjliga värden för provisioning_state:
| Värde |
beskrivning |
Creating |
Resursen skapas. |
Updating |
Resursen uppdateras. |
Deleting |
Resursen tas bort. |
Succeeded |
Åtgärden för att skapa eller uppdatera lyckades. |
Failed |
Åtgärden för att skapa, uppdatera eller ta bort misslyckades. |
Anropa den lokala slutpunkten för att poängsätta data med hjälp av din modell
Anropa slutpunkten för att poängsätta modellen med hjälp invoke av kommandot och skicka frågeparametrar som lagras i en JSON-fil:
az ml online-endpoint invoke --local --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Om du vill använda en REST-klient (t.ex. curl) måste du ha bedömnings-URI:n. Kör för att hämta bedömnings-URI az ml online-endpoint show --local -n $ENDPOINT_NAME:n. Leta upp attributet i scoring_uri de returnerade data.
Anropa slutpunkten för att poängsätta modellen med hjälp invoke av kommandot och skicka frågeparametrar som lagras i en JSON-fil.
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
request_file="../model-1/sample-request.json",
local=True,
)
Om du vill använda en REST-klient (t.ex. curl) måste du ha bedömnings-URI:n. Kör följande kod för att hämta bedömnings-URI:n. Leta upp attributet i scoring_uri de returnerade data.
endpoint = ml_client.online_endpoints.get(endpoint_name, local=True)
scoring_uri = endpoint.scoring_uri
Studion stöder inte lokala slutpunkter. Anvisningar för hur du testar slutpunkten lokalt finns i flikarna Azure CLI eller Python.
Mallen stöder inte lokala slutpunkter. Anvisningar för hur du testar slutpunkten lokalt finns i flikarna Azure CLI eller Python.
Granska loggarna för utdata från anropsåtgärden
I exemplet score.py fil run() loggar metoden utdata till konsolen.
Du kan visa dessa utdata med hjälp get-logs av kommandot :
az ml online-deployment get-logs --local -n blue --endpoint $ENDPOINT_NAME
Du kan visa dessa utdata med hjälp get_logs av metoden:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, local=True, lines=50
)
Studion stöder inte lokala slutpunkter. Anvisningar för hur du testar slutpunkten lokalt finns i flikarna Azure CLI eller Python.
Mallen stöder inte lokala slutpunkter. Anvisningar för hur du testar slutpunkten lokalt finns i flikarna Azure CLI eller Python.
Distribuera din onlineslutpunkt till Azure
Distribuera sedan din onlineslutpunkt till Azure. Som bästa praxis för produktion rekommenderar vi att du registrerar den modell och miljö som du använder i distributionen.
Registrera din modell och miljö
Vi rekommenderar att du registrerar din modell och miljö innan du distribuerar till Azure så att du kan ange deras registrerade namn och versioner under distributionen. När du har registrerat dina tillgångar kan du återanvända dem utan att behöva ladda upp dem varje gång du skapar distributioner. Den här metoden ökar reproducerbarheten och spårbarheten.
Till skillnad från distribution till Azure stöder inte lokal distribution användning av registrerade modeller och miljöer. I stället använder lokal distribution lokala modellfiler och använder endast miljöer med lokala filer.
För distribution till Azure kan du använda antingen lokala eller registrerade tillgångar (modeller och miljöer). I det här avsnittet i artikeln använder distributionen till Azure registrerade tillgångar, men du har möjlighet att använda lokala tillgångar i stället. Ett exempel på en distributionskonfiguration som laddar upp lokala filer som ska användas för lokal distribution finns i Konfigurera en distribution.
Om du vill registrera modellen och miljön använder du formuläret model: azureml:my-model:1 eller environment: azureml:my-env:1.
För registrering kan du extrahera YAML-definitionerna för model och environment till separata YAML-filer i mappen endpoints/online/managed/sample och använda kommandona az ml model create och az ml environment create. Om du vill veta mer om dessa kommandon kör az ml model create -h du och az ml environment create -h.
Skapa en YAML-definition för modellen. Ge filen namnet model.yml:
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: my-model
path: ../../model-1/model/
Registrera modellen:
az ml model create -n my-model -v 1 -f endpoints/online/managed/sample/model.yml
Skapa en YAML-definition för miljön. Ge filen namnet environment.yml:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: my-env
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
conda_file: ../../model-1/environment/conda.yaml
Registrera miljön:
az ml environment create -n my-env -v 1 -f endpoints/online/managed/sample/environment.yml
Mer information om hur du registrerar din modell som en tillgång finns i Registrera en modell med hjälp av Azure CLI eller Python SDK. Mer information om hur du skapar en miljö finns i Skapa en anpassad miljö.
Registrera en modell:
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
file_model = Model(
path="../model-1/model/",
type=AssetTypes.CUSTOM_MODEL,
name="my-model",
description="Model created from local file.",
)
ml_client.models.create_or_update(file_model)
Registrera miljön:
from azure.ai.ml.entities import Environment
env_docker_conda = Environment(
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
conda_file="../model-1/environment/conda.yaml",
name="my-env",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env_docker_conda)
Information om hur du registrerar din modell som en tillgång så att du kan ange dess registrerade namn och version under distributionen finns i Registrera en modell med hjälp av Azure CLI eller Python SDK.
Mer information om hur du skapar en miljö finns i Skapa en anpassad miljö.
Registrera modellen
En modellregistrering är en logisk entitet på arbetsytan som kan innehålla en enskild modellfil eller en katalog med flera filer. Som bästa praxis för produktion bör du registrera modellen och miljön. Innan du skapar slutpunkten och distributionen i den här artikeln ska du registrera modellmappen som innehåller modellen.
Följ dessa steg för att registrera exempelmodellen:
Gå till Azure Machine Learning-studio.
Välj sidan Modeller i den vänstra rutan.
Välj Registrera och välj sedan Från lokala filer.
Välj Ospecificerad typ för modelltypen.
Välj Bläddra och välj Bläddra mapp.
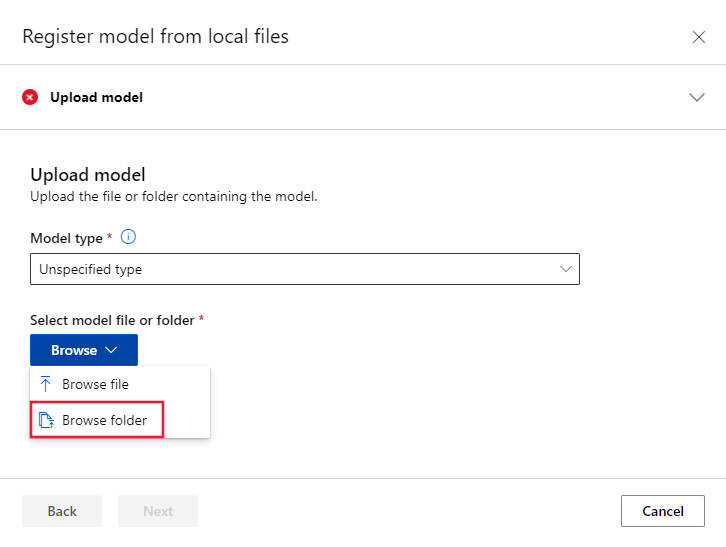
Välj mappen \azureml-examples\cli\endpoints\online\model-1\model från den lokala kopian av lagringsplatsen som du klonade eller laddade ned tidigare. När du uppmanas till det väljer du Ladda upp och väntar tills uppladdningen har slutförts.
Välj Nästa.
Ange ett användarvänligt namn för modellen. Stegen i den här artikeln förutsätter att modellen heter model-1.
Välj Nästa och sedan Registrera för att slutföra registreringen.
Mer information om hur du arbetar med registrerade modeller finns i Arbeta med registrerade modeller.
Skapa och registrera miljön
Välj sidan Miljöer i den vänstra rutan.
Välj fliken Anpassade miljöer och välj sedan Skapa.
På sidan Inställningar anger du ett namn, till exempel my-env för miljön.
För Välj miljökälla väljer du Använd befintlig docker-avbildning med valfri conda-källa.
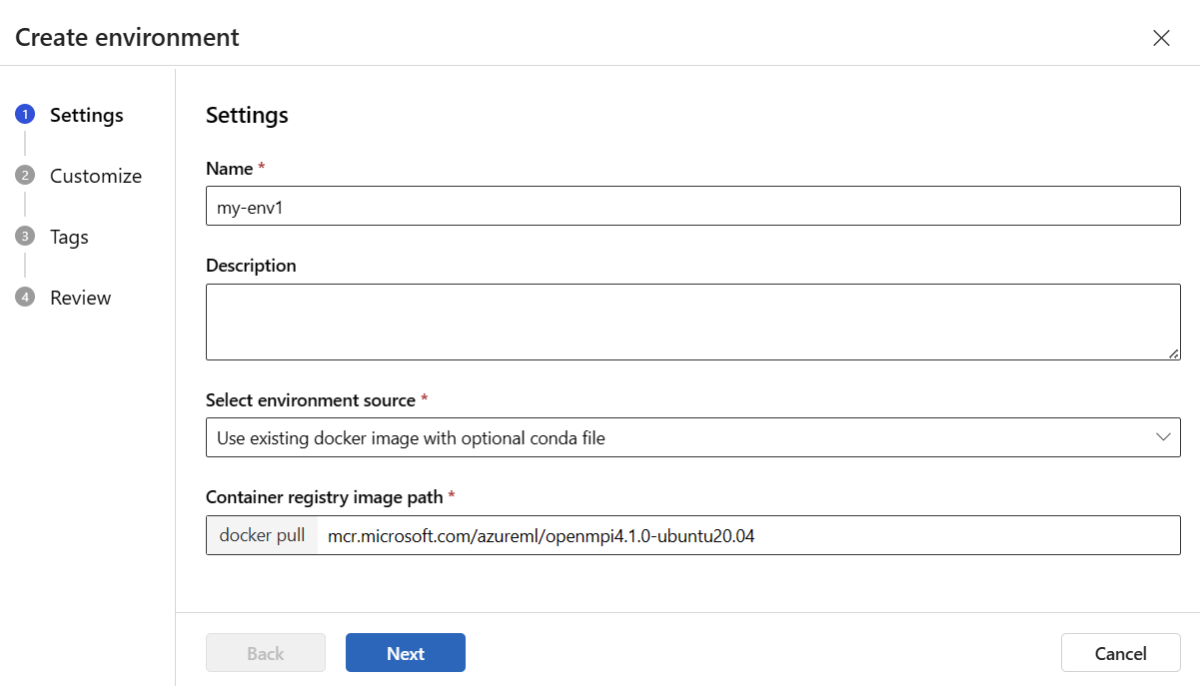
Välj Nästa för att gå till sidan Anpassa .
Kopiera innehållet i filen \azureml-examples\cli\endpoints\online\model-1\environment\conda.yaml från lagringsplatsen som du klonade eller laddade ned tidigare.
Klistra in innehållet i textrutan.

Välj Nästa tills du kommer till sidan Skapa och välj sedan Skapa.
Mer information om hur du skapar en miljö i studion finns i Skapa en miljö.
Om du vill registrera modellen med hjälp av en mall måste du först ladda upp modellfilen till Blob Storage. I följande exempel används az storage blob upload-batch kommandot för att ladda upp en fil till standardlagringen för din arbetsyta:
az storage blob upload-batch -d $AZUREML_DEFAULT_CONTAINER/model -s cli/endpoints/online/model-1/model --account-name $AZURE_STORAGE_ACCOUNT
När du har laddat upp filen använder du mallen för att skapa en modellregistrering. I följande exempel innehåller parametern modelUri sökvägen till modellen:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/model-version.json \
--parameters \
workspaceName=$WORKSPACE \
modelAssetName="sklearn" \
modelUri="azureml://subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/workspaces/$WORKSPACE/datastores/$AZUREML_DEFAULT_DATASTORE/paths/model/sklearn_regression_model.pkl"
En del av miljön är en conda-fil som anger de modellberoenden som behövs för att vara värd för modellen. I följande exempel visas hur du läser innehållet i conda-filen i miljövariabler:
CONDA_FILE=$(cat cli/endpoints/online/model-1/environment/conda.yaml)
I följande exempel visas hur du använder mallen för att registrera miljön. Innehållet i conda-filen från föregående steg skickas till mallen med hjälp av parametern condaFile :
ENV_VERSION=$RANDOM
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/environment-version.json \
--parameters \
workspaceName=$WORKSPACE \
environmentAssetName=sklearn-env \
environmentAssetVersion=$ENV_VERSION \
dockerImage=mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:20210727.v1 \
condaFile="$CONDA_FILE"
Viktigt!
När du definierar en anpassad miljö för distributionen azureml-inference-server-http kontrollerar du att paketet ingår i conda-filen. Det här paketet är viktigt för att slutsatsdragningsservern ska fungera korrekt. Om du inte känner till hur du skapar en egen anpassad miljö använder du en av våra utvalda miljöer, till exempel minimal-py-inference (för anpassade modeller som inte använder mlflow) eller mlflow-py-inference (för modeller som använder mlflow). Du hittar de här utvalda miljöerna på fliken Miljöer i din instans av Azure Machine Learning Studio.
Distributionskonfigurationen använder den registrerade modell som du vill distribuera och din registrerade miljö.
Använd registrerade tillgångar (modell och miljö) i distributionsdefinitionen. Följande kodfragment visar filen endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml , med alla nödvändiga indata för att konfigurera en distribution:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model: azureml:my-model:1
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment: azureml:my-env:1
instance_type: Standard_DS3_v2
instance_count: 1
Om du vill konfigurera en distribution använder du den registrerade modellen och miljön:
model = "azureml:my-model:1"
env = "azureml:my-env:1"
blue_deployment_with_registered_assets = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
När du distribuerar från studion skapar du en slutpunkt och en distribution som ska läggas till i den. Då uppmanas du att ange namn för slutpunkten och distributionen.
Använda olika typer och avbildningar av PROCESSOR- och GPU-instanser
Du kan ange typer och avbildningar för CPU- eller GPU-instanser i distributionsdefinitionen för både lokal distribution och distribution till Azure.
Din distributionsdefinition i blue-deployment-with-registered-assets.yml-filen använde en instans av typen allmänt bruk Standard_DS3_v2 och docker-avbildningen mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest utan GPU. För GPU-beräkning väljer du en GPU-beräkningstypversion och en GPU Docker-avbildning.
Se hanterade onlineslutpunkters SKU-lista för att få information om stöd för allmän användning och GPU-instanstyper. En lista över Azure Machine Learning CPU- och GPU-basavbildningar finns i Grundavbildningar för Azure Machine Learning.
Du kan ange typer och avbildningar för CPU- eller GPU-instanser i distributionskonfigurationen för både lokal distribution och distribution till Azure.
Tidigare konfigurerade du en distribution som använde en instans av generell typ Standard_DS3_v2 och en docker-avbildning mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latestsom inte är GPU. För GPU-beräkning väljer du en GPU-beräkningstypversion och en GPU Docker-avbildning.
Se hanterade onlineslutpunkters SKU-lista för att få information om stöd för allmän användning och GPU-instanstyper. En lista över Azure Machine Learning CPU- och GPU-basavbildningar finns i Grundavbildningar för Azure Machine Learning.
Föregående registrering av miljön specificerar en icke-GPU Docker-avbildning mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04 genom att överföra värdet till mallenenvironment-version.json med hjälp av parametern dockerImage. För en GPU-beräkning anger du ett värde för en GPU Docker-avbildning till mallen (använd parametern dockerImage ) och anger en GPU-beräkningstypversion till mallen online-endpoint-deployment.json (använd parametern skuName ).
Se hanterade onlineslutpunkters SKU-lista för att få information om stöd för allmän användning och GPU-instanstyper. En lista över Azure Machine Learning CPU- och GPU-basavbildningar finns i Grundavbildningar för Azure Machine Learning.
Distribuera sedan din onlineslutpunkt till Azure.
Distribuera till Azure
Skapa slutpunkten i Azure-molnet:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Skapa distributionen med namnet blue under slutpunkten:
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml --all-traffic
Det kan ta upp till 15 minuter att skapa distributionen, beroende på om den underliggande miljön eller avbildningen skapas för första gången. Efterföljande distributioner som använder samma miljö bearbetas snabbare.
Om du föredrar att inte blockera CLI-konsolen kan du lägga till flaggan --no-wait i kommandot. Det här alternativet stoppar dock den interaktiva visningen av distributionsstatusen.
Flaggan --all-traffic i koden az ml online-deployment create som används för att skapa distributionen allokerar 100 % av slutpunktstrafiken till den nyligen skapade blå distributionen. Att använda den här flaggan är användbart i utvecklings- och testsyfte, men för produktion kanske du vill dirigera trafik till den nya distributionen via ett explicit kommando. Använd till exempel az ml online-endpoint update -n $ENDPOINT_NAME --traffic "blue=100".
Skapa slutpunkten:
Genom att använda parametern endpoint som du definierade tidigare och parametern MLClient som du skapade tidigare kan du nu skapa slutpunkten på arbetsytan. Det här kommandot startar skapandet av slutpunkten och returnerar ett bekräftelsesvar medan skapandet av slutpunkten fortsätter.
ml_client.online_endpoints.begin_create_or_update(endpoint)
Skapa distributionen:
Genom att använda parametern blue_deployment_with_registered_assets som du definierade tidigare och parametern MLClient som du skapade tidigare kan du nu skapa distributionen på arbetsytan. Det här kommandot startar distributionen och returnerar ett bekräftelsesvar medan distributionen fortsätter.
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Om du föredrar att inte blockera Python-konsolen kan du lägga till flaggan no_wait=True i parametrarna. Det här alternativet stoppar dock den interaktiva visningen av distributionsstatusen.
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
Skapa en hanterad onlineslutpunkt och distribution
Använd studion för att skapa en hanterad onlineslutpunkt direkt i webbläsaren. När du skapar en hanterad onlineslutpunkt i studion måste du definiera en inledande distribution. Du kan inte skapa en tom hanterad onlineslutpunkt.
Ett sätt att skapa en hanterad onlineslutpunkt i studion är från sidan Modeller . Den här metoden ger också ett enkelt sätt att lägga till en modell i en befintlig hanterad onlinedistribution. Så här distribuerar du modellen med namnet model-1 som du registrerade tidigare i avsnittet Registrera din modell och miljö :
Gå till Azure Machine Learning-studio.
Välj sidan Modeller i den vänstra rutan.
Välj modellen med namnet model-1.
Välj Distribuera>realtidsslutpunkt.
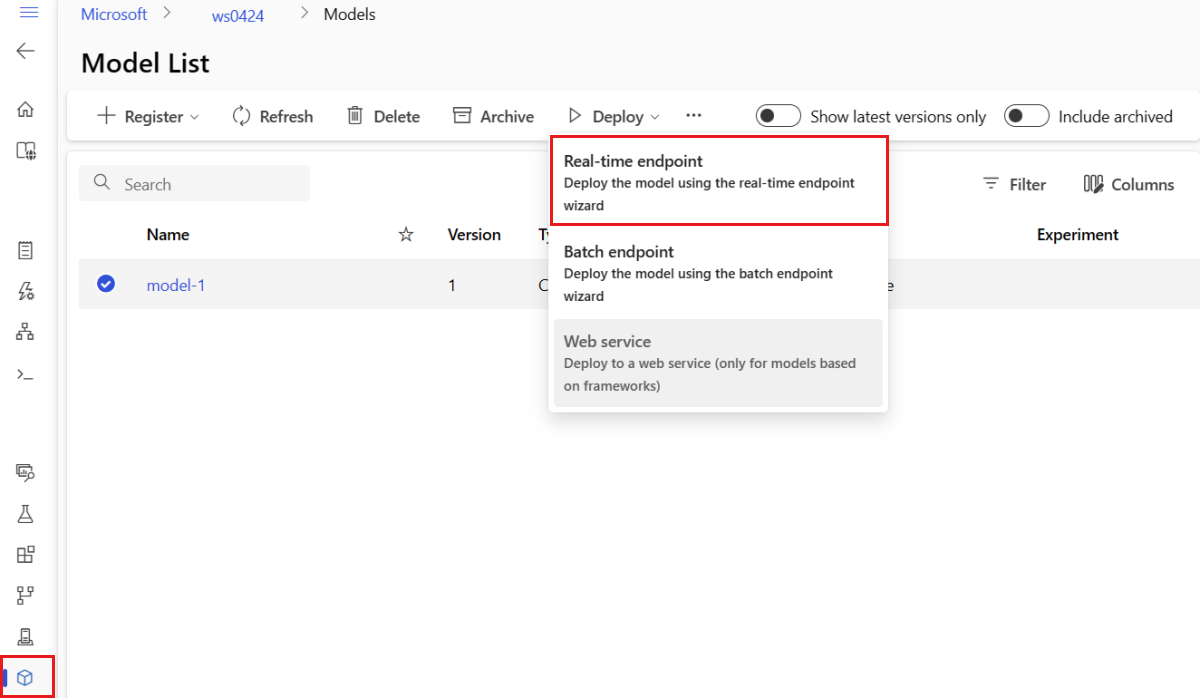
Den här åtgärden öppnar ett fönster där du kan ange information om slutpunkten.
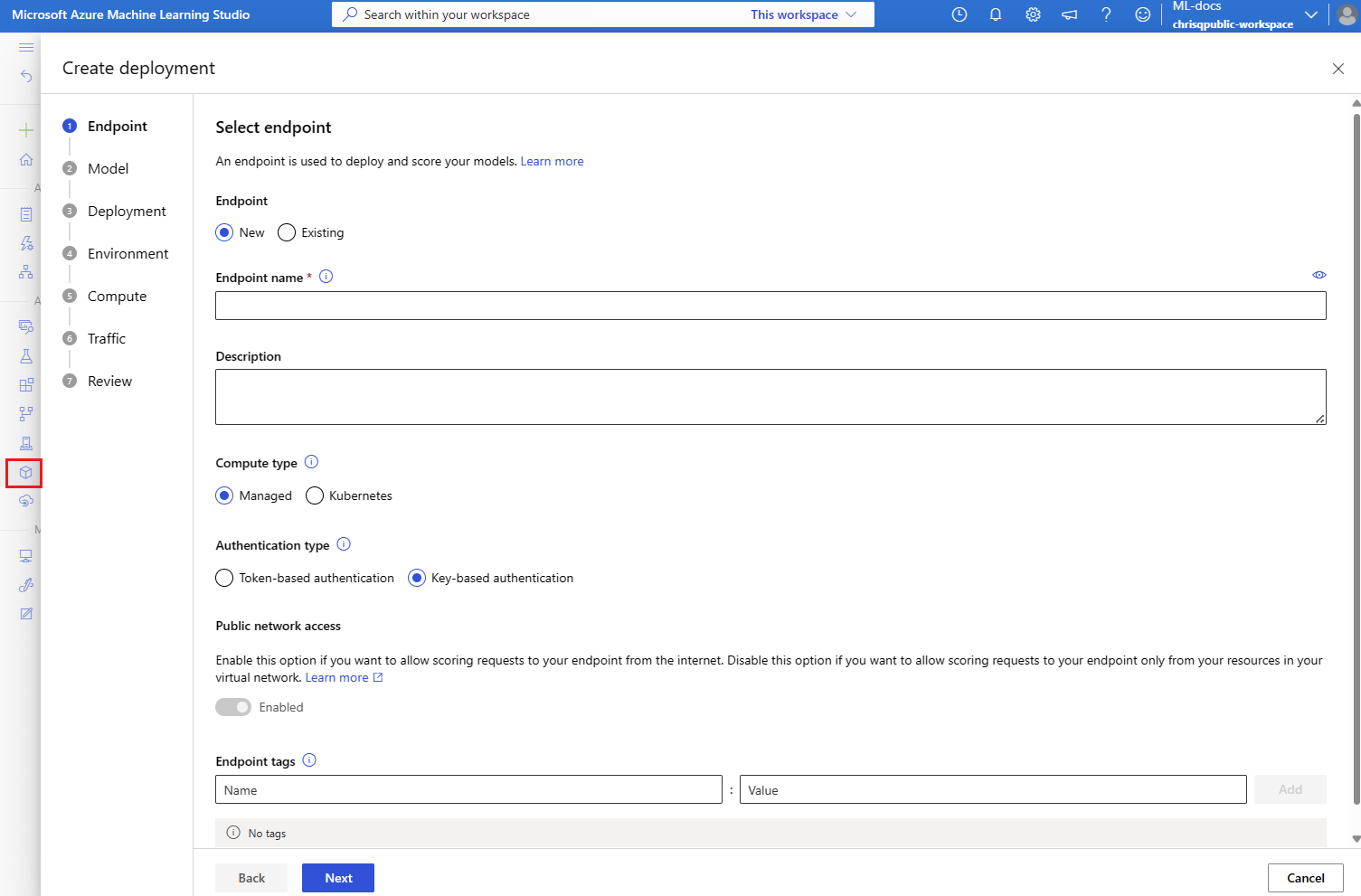
Ange ett slutpunktsnamn som är unikt i Azure-regionen. Mer information om namngivningsreglerna finns i Slutpunktsgränser.
Behåll standardvalet: Hanteras för beräkningstypen.
Behåll standardvalet: nyckelbaserad autentisering för autentiseringstypen. Mer information om autentisering finns i Autentisera klienter för onlineslutpunkter.
Välj Nästa tills du kommer till sidan Distribution . Växla Application Insights-diagnostik till Aktiverad så att du kan visa grafer över slutpunktens aktiviteter i studion senare och analysera mått och loggar med hjälp av Application Insights.
Välj Nästa för att gå till sidan Kod + miljö . Välj ett av följande alternativ:
-
Välj ett bedömningsskript för slutsatsdragning: Bläddra och välj filen \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py från lagringsplatsen som du klonade eller laddade ned tidigare.
-
Välj miljöavsnitt : Välj Anpassade miljöer och välj sedan den my-env:1-miljö som du skapade tidigare.
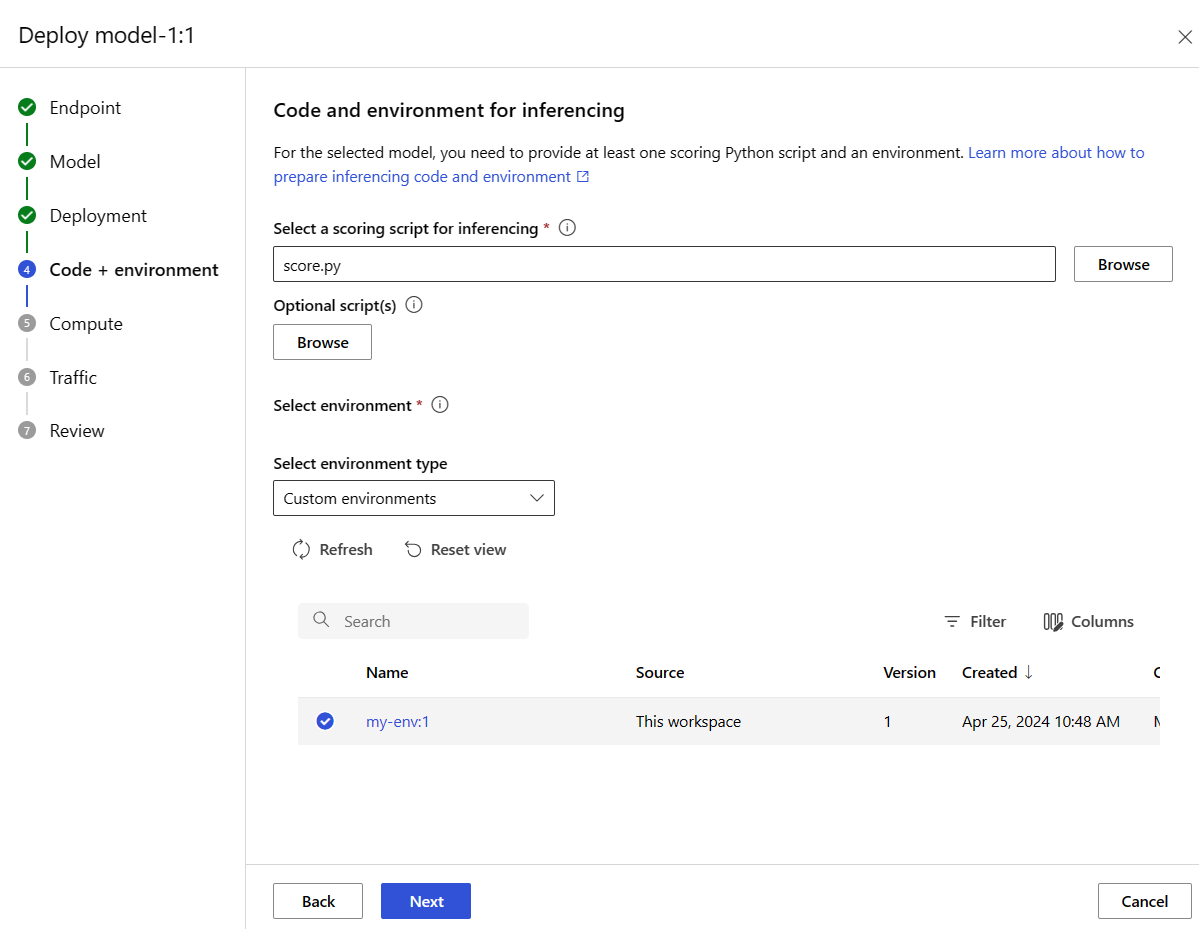
Välj Nästa och acceptera standardvärden tills du uppmanas att skapa distributionen.
Granska distributionsinställningarna och välj Skapa.
Du kan också skapa en hanterad onlineslutpunkt från sidan Slutpunkter i studion.
Gå till Azure Machine Learning-studio.
Välj sidan Slutpunkter i den vänstra rutan.
Välj + Skapa.
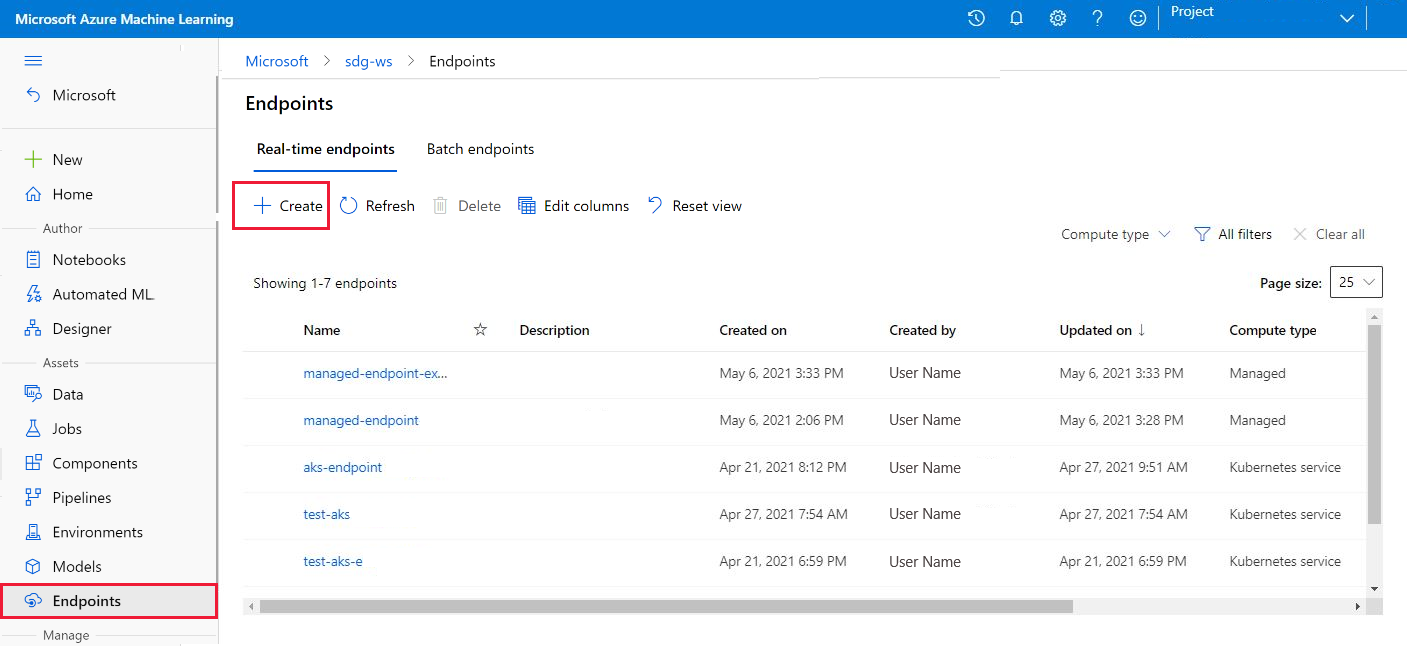
Den här åtgärden öppnar ett fönster där du kan välja din modell och ange information om slutpunkten och distributionen. Ange inställningar för slutpunkten och distributionen enligt beskrivningen tidigare och välj sedan Skapa för att skapa distributionen.
Använd mallen för att skapa en onlineslutpunkt:
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint.json \
--parameters \
workspaceName=$WORKSPACE \
onlineEndpointName=$ENDPOINT_NAME \
identityType=SystemAssigned \
authMode=AMLToken \
location=$LOCATION
Distribuera modellen till slutpunkten när slutpunkten har skapats:
resourceScope="/subscriptions/$SUBSCRIPTION_ID/resourceGroups/$RESOURCE_GROUP/providers/Microsoft.MachineLearningServices"
az deployment group create -g $RESOURCE_GROUP \
--template-file arm-templates/online-endpoint-deployment.json \
--parameters \
workspaceName=$WORKSPACE \
location=$LOCATION \
onlineEndpointName=$ENDPOINT_NAME \
onlineDeploymentName=blue \
codeId="$resourceScope/workspaces/$WORKSPACE/codes/score-sklearn/versions/1" \
scoringScript=score.py \
environmentId="$resourceScope/workspaces/$WORKSPACE/environments/sklearn-env/versions/$ENV_VERSION" \
model="$resourceScope/workspaces/$WORKSPACE/models/sklearn/versions/1" \
endpointComputeType=Managed \
skuName=Standard_F2s_v2 \
skuCapacity=1
Information om hur du felsöker fel i distributionen finns i Felsöka distributioner av onlineslutpunkter.
Kontrollera statusen för onlineslutpunkten
show Använd kommandot för att visa information i provisioning_state för slutpunkten och distributionen:
az ml online-endpoint show -n $ENDPOINT_NAME
Visa en lista över alla slutpunkter i arbetsytan i tabellformat med hjälp list av kommandot :
az ml online-endpoint list --output table
Kontrollera slutpunktens status för att se om modellen distribuerades utan fel:
ml_client.online_endpoints.get(name=endpoint_name)
Visa en lista över alla slutpunkter i arbetsytan i tabellformat med hjälp list av metoden:
for endpoint in ml_client.online_endpoints.list():
print(endpoint.name)
Metoden returnerar en lista (iterator) över ManagedOnlineEndpoint entiteter.
Du kan få mer information genom att ange fler parametrar. Du kan till exempel mata ut listan över slutpunkter som en tabell:
print("Kind\tLocation\tName")
print("-------\t----------\t------------------------")
for endpoint in ml_client.online_endpoints.list():
print(f"{endpoint.kind}\t{endpoint.location}\t{endpoint.name}")
Visa hanterade onlineslutpunkter
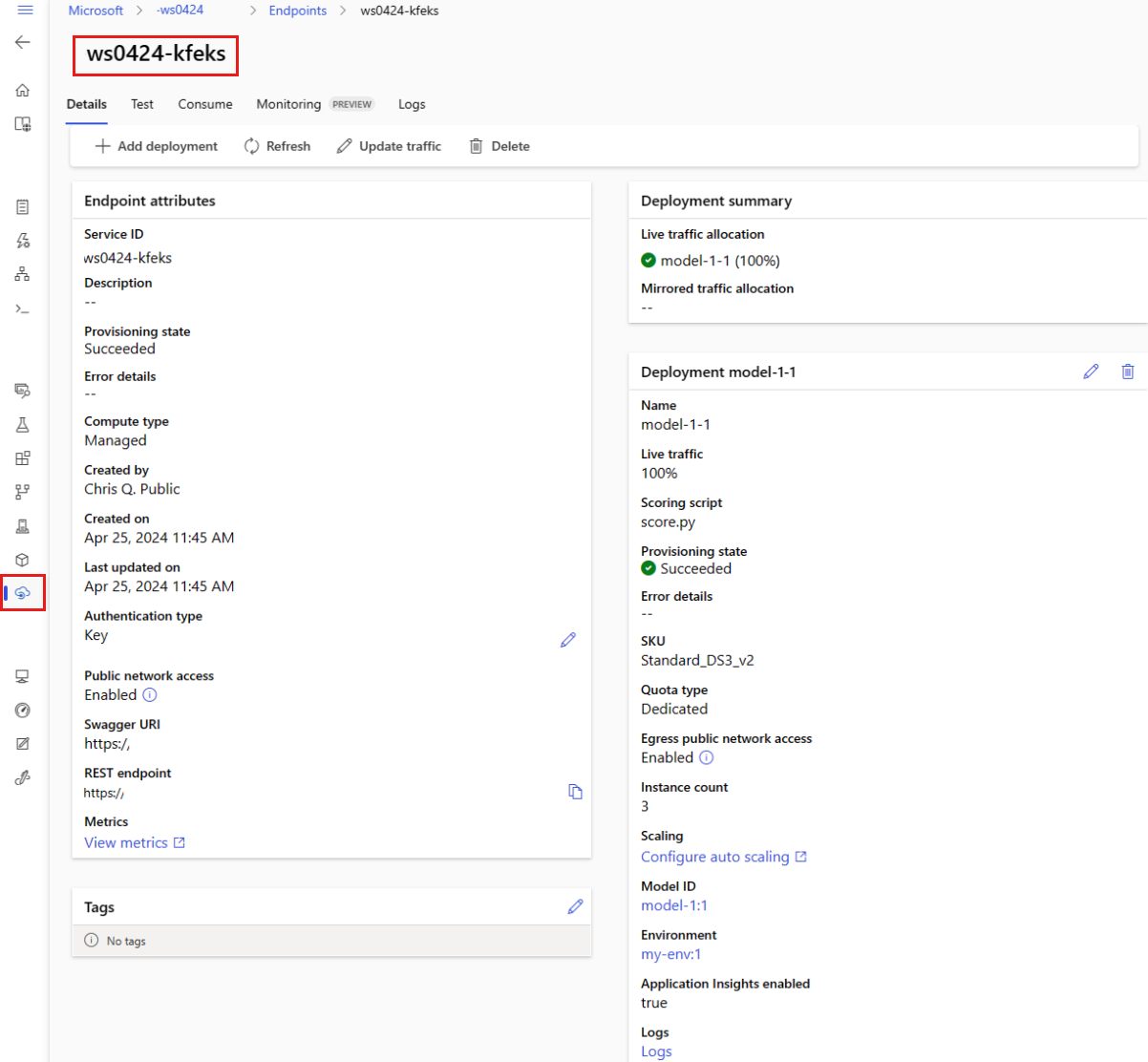
Du kan visa alla dina hanterade onlineslutpunkter på sidan Slutpunkter . Gå till slutpunktens informationssida för att hitta viktig information, till exempel slutpunkts-URI, status, testverktyg, aktivitetsövervakare, distributionsloggar och exempelförbrukningskod.
I den vänstra rutan väljer du Slutpunkter för att se en lista över alla slutpunkter i arbetsytan.
(Valfritt) Skapa ett filter för beräkningstyp för att endast visa hanterade beräkningstyper.
Välj ett slutpunktsnamn för att visa slutpunktens informationssida.
Mallar är användbara för att distribuera resurser, men du kan inte använda dem för att lista, visa eller anropa resurser. Använd Azure CLI, Python SDK eller studio för att utföra dessa åtgärder. Följande kod använder Azure CLI.
show Använd kommandot för att visa information i parametern provisioning_state för slutpunkten och distributionen:
az ml online-endpoint show -n $ENDPOINT_NAME
Visa en lista över alla slutpunkter i arbetsytan i tabellformat med hjälp list av kommandot :
az ml online-endpoint list --output table
Kontrollera statusen för onlinedistributionen
Kontrollera loggarna för att se om modellen distribuerades utan fel.
Om du vill se loggutdata från en container använder du följande CLI-kommando:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Som standard hämtas loggarna från inferensservercontainern. Om du vill se loggar från containern för lagringsinitieraren lägger du till --container storage-initializer flaggan. Mer information om distributionsloggar finns i Hämta containerloggar.
Du kan visa loggutdata med hjälp get_logs av metoden:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Som standard hämtas loggarna från inferensservercontainern. Lägg till container_type="storage-initializer" alternativet om du vill se loggar från containern för lagringsinitieraren. Mer information om distributionsloggar finns i Hämta containerloggar.
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50, container_type="storage-initializer"
)
Om du vill visa loggutdata väljer du fliken Loggar på slutpunktens sida. Om du har flera distributioner i slutpunkten använder du listrutan för att välja distributionen med den logg som du vill se.
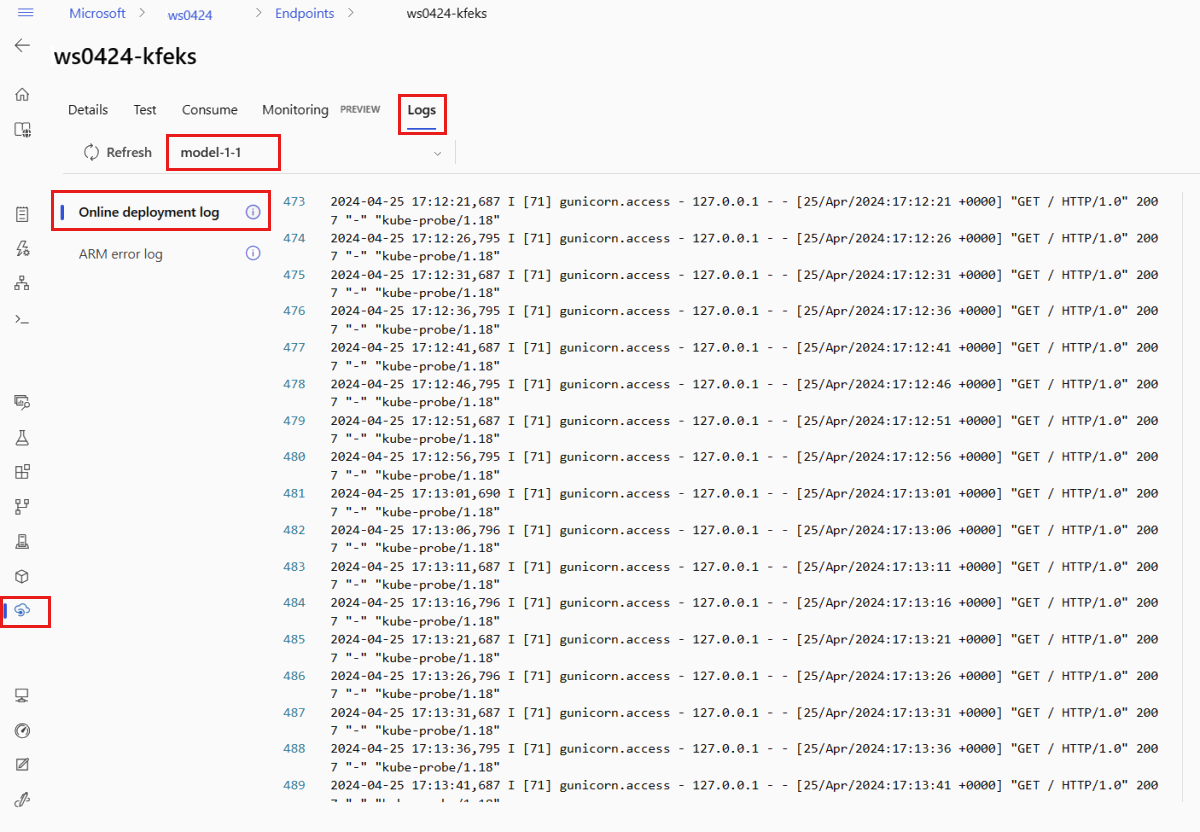
Som standard hämtas loggar från slutsatsdragningsservern. Om du vill se loggar från containern för lagringsinitiering använder du Azure CLI eller Python SDK (se varje flik för mer information). Loggar från containern för lagringsinitieraren innehåller information om huruvida kod- och modelldata har laddats ned till containern. Mer information om distributionsloggar finns i Hämta containerloggar.
Mallar är användbara för att distribuera resurser, men du kan inte använda dem för att lista, visa eller anropa resurser. Använd Azure CLI, Python SDK eller studio för att utföra dessa åtgärder. Följande kod använder Azure CLI.
Om du vill se loggutdata från en container använder du följande CLI-kommando:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Som standard hämtas loggarna från inferensservercontainern. Om du vill se loggar från containern för lagringsinitieraren lägger du till --container storage-initializer flaggan. Mer information om distributionsloggar finns i Hämta containerloggar.
Anropa slutpunkten för att poängsätta data med hjälp av din modell
Använd antingen kommandot invoke eller valfri REST-klient för att anropa slutpunkten och poängsätta vissa data:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Hämta nyckeln som används för att autentisera till slutpunkten:
Du kan styra vilka Microsoft Entra-säkerhetsobjekt som kan hämta autentiseringsnyckeln genom att tilldela dem till en anpassad roll som tillåter Microsoft.MachineLearningServices/workspaces/onlineEndpoints/token/action och Microsoft.MachineLearningServices/workspaces/onlineEndpoints/listkeys/action. Mer information om hur du hanterar auktorisering till arbetsytor finns i Hantera åtkomst till en Azure Machine Learning-arbetsyta.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME -o tsv --query primaryKey)
Använd curl för att poängsätta data.
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @endpoints/online/model-1/sample-request.json
Observera att du använder show och get-credentials kommandon för att hämta autentiseringsuppgifterna. Observera också att du använder --query flaggan för att endast filtrera de attribut som behövs. Mer information om flaggan finns i --query Fråga azure CLI-kommandoutdata.
Om du vill se anropsloggarna kör du get-logs igen.
Med hjälp av parametern MLClient som du skapade tidigare får du en referens till slutpunkten. Du kan sedan anropa slutpunkten med invoke-kommandot med följande parametrar:
-
endpoint_name: Namnet på slutpunkten.
-
request_file: Fil med begärandedata.
-
deployment_name: Namnet på den specifika distribution som ska testas i en slutpunkt.
Skicka en exempelbegäran med hjälp av en JSON-fil .
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
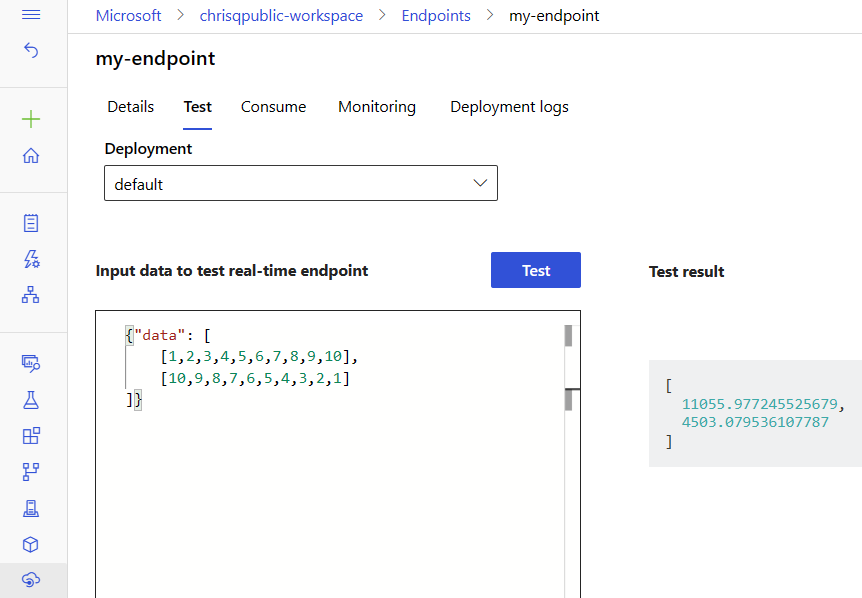
Använd fliken Test på slutpunktens informationssida för att testa din hanterade onlinedistribution. Ange exempelindata och visa resultatet.
Välj fliken Test på slutpunktens informationssida.
Använd listrutan för att välja den distribution som du vill testa.
Ange exempelindata.
Välj Testa.
Mallar är användbara för att distribuera resurser, men du kan inte använda dem för att lista, visa eller anropa resurser. Använd Azure CLI, Python SDK eller studio för att utföra dessa åtgärder. Följande kod använder Azure CLI.
Använd antingen kommandot invoke eller valfri REST-klient för att anropa slutpunkten och poängsätta vissa data:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file cli/endpoints/online/model-1/sample-request.json
(Valfritt) Uppdatera distributionen
Om du vill uppdatera koden, modellen eller miljön uppdaterar du YAML-filen.
az ml online-endpoint update Kör sedan kommandot .
Om du uppdaterar antalet instanser (för att skala distributionen) tillsammans med andra modellinställningar (till exempel kod, modell eller miljö) i ett enda update kommando utförs skalningsåtgärden först. De andra uppdateringarna tillämpas härnäst. Det är en bra idé att utföra dessa åtgärder separat i en produktionsmiljö.
Så här förstår du hur update det fungerar:
Öppna filen online/model-1/onlinescoring/score.py.
Ändra den sista raden i init() funktionen: Efter logging.info("Init complete")lägger du till logging.info("Updated successfully").
Spara filen.
Kör följande kommando:
az ml online-deployment update -n blue --endpoint $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment-with-registered-assets.yml
Det är deklarativt att uppdatera med YAML. Det vill säga ändringar i YAML återspeglas i de underliggande Resource Manager-resurserna (slutpunkter och distributioner). En deklarativ metod underlättar GitOps: Alla ändringar av slutpunkter och distributioner (till och med instance_count) går igenom YAML.
Du kan använda allmänna uppdateringsparametrar, till exempel parametern --set , med CLI-kommandot update för att åsidosätta attribut i YAML eller för att ange specifika attribut utan att skicka dem i YAML-filen. Användning för --set enkla attribut är särskilt värdefullt i utvecklings- och testscenarier. Om du till exempel vill skala upp instance_count värdet för den första distributionen kan du använda --set instance_count=2 flaggan. Men eftersom YAML inte uppdateras underlättar inte den här tekniken GitOps.
Det är inte obligatoriskt att ange YAML-filen. Om du till exempel vill testa olika samtidighetsinställningar för en viss distribution kan du prova något i stil med az ml online-deployment update -n blue -e my-endpoint --set request_settings.max_concurrent_requests_per_instance=4 environment_variables.WORKER_COUNT=4. Den här metoden behåller all befintlig konfiguration men uppdaterar endast de angivna parametrarna.
Eftersom du har ändrat init() funktionen, som körs när slutpunkten skapas eller uppdateras, visas meddelandet Updated successfully i loggarna. Hämta loggarna genom att köra:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Kommandot update fungerar också med lokala distributioner. Använd samma az ml online-deployment update kommando med --local flaggan.
Om du vill uppdatera koden, modellen eller miljön uppdaterar du konfigurationen och kör MLClientonline_deployments.begin_create_or_update sedan -metoden för att skapa eller uppdatera en distribution.
Om du uppdaterar instansantalet (för att skala distributionen) tillsammans med andra modellinställningar (till exempel kod, modell eller miljö) i en enda begin_create_or_update metod utförs skalningsåtgärden först. Sedan tillämpas de andra uppdateringarna. Det är en bra idé att utföra dessa åtgärder separat i en produktionsmiljö.
Så här förstår du hur begin_create_or_update det fungerar:
Öppna filen online/model-1/onlinescoring/score.py.
Ändra den sista raden i init() funktionen: Efter logging.info("Init complete")lägger du till logging.info("Updated successfully").
Spara filen.
Kör metoden:
ml_client.online_deployments.begin_create_or_update(blue_deployment_with_registered_assets)
Eftersom du har ändrat init() funktionen, som körs när slutpunkten skapas eller uppdateras, visas meddelandet Updated successfully i loggarna. Hämta loggarna genom att köra:
ml_client.online_deployments.get_logs(
name="blue", endpoint_name=endpoint_name, lines=50
)
Metoden begin_create_or_update fungerar också med lokala distributioner. Använd samma metod med local=True flaggan.
För närvarande kan du bara göra uppdateringar av instansantalet för en distribution. Använd följande instruktioner för att skala upp eller ned en enskild distribution genom att justera antalet instanser:
- Öppna sidan Information för slutpunkten och leta reda på kortet för den distribution som du vill uppdatera.
- Välj redigeringsikonen (pennikonen) bredvid distributionens namn.
- Uppdatera antalet instanser som är associerade med distributionen. Välj mellan Standard eller Målanvändning för distributionsskalningstyp.
- Om du väljer Standard kan du också ange ett numeriskt värde för antal instanser.
- Om du väljer Målanvändning kan du ange värden som ska användas för parametrar när du skalar distributionen automatiskt.
- Välj Uppdatera för att slutföra uppdateringen av antalet instanser för distributionen.
Det finns för närvarande inget alternativ för att uppdatera distributionen med hjälp av en ARM-mall.
Kommentar
Uppdateringen av distributionen i det här avsnittet är ett exempel på en löpande uppdatering på plats.
- För en hanterad onlineslutpunkt uppdateras distributionen till den nya konfigurationen med 20% av noderna i taget. Om distributionen har 10 noder uppdateras alltså 2 noder åt gången.
- För en Kubernetes online-slutpunkt skapar systemet iterativt en ny distributionsinstans med den nya konfigurationen och tar bort den gamla.
- För produktionsanvändning bör du överväga blågrön distribution, vilket är ett säkrare alternativ för att uppdatera en webbtjänst.
Med autoskalning körs automatiskt rätt mängd resurser för att hantera arbetsbelastningen i appen. Hanterade onlineslutpunkter stöder automatisk skalning genom integrering med autoskalningsfunktionen i Azure Monitor. Information om hur du konfigurerar autoskalning finns i Autoskalning av onlineslutpunkter.
(Valfritt) Övervaka serviceavtal med hjälp av Azure Monitor
Om du vill visa mått och ange aviseringar baserat på ditt serviceavtal följer du stegen som beskrivs i Övervaka onlineslutpunkter.
(Valfritt) Integrera med Log Analytics
Kommandot get-logs för CLI eller get_logs -metoden för SDK:t innehåller endast de senaste hundra raderna med loggar från en automatiskt vald instans. Log Analytics är dock ett sätt att lagra och analysera loggar på ett korrekt sätt. Mer information om hur du använder loggning finns i Använda loggar.
Ta bort slutpunkten och distributionen
Använd följande kommando för att ta bort slutpunkten och alla dess underliggande distributioner:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Använd följande kommando för att ta bort slutpunkten och alla dess underliggande distributioner:
ml_client.online_endpoints.begin_delete(name=endpoint_name)
Om du inte ska använda slutpunkten och distributionen tar du bort dem. Genom att ta bort slutpunkten tar du också bort alla dess underliggande distributioner.
- Gå till Azure Machine Learning-studio.
- Välj sidan Slutpunkter i den vänstra rutan.
- Välj en slutpunkt.
- Välj Ta bort.
Du kan också ta bort en hanterad onlineslutpunkt direkt genom att välja ikonen Ta bort på sidan med slutpunktsinformation.
Använd följande kommando för att ta bort slutpunkten och alla dess underliggande distributioner:
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Relaterat innehåll









